
Joined May 2009
- Tweets 246
- Following 3,787
- Followers 1,172
- Likes 7,384
7 Photos and videos



Pinned Tweet

6 Mar 2025
pleased to share 'DiffLogic CA', made of the finest blend of NCA and binary-gate circuits! adopting @FHKPetersen's differentiable circuit learning, we learn *stateful* circuits, recurrent in space & time. by @PietroMiotti, me, @zzznah, @RandazzoEttore 1/5 google-research.github.io/se…
3
14
73
6,135
eyvind niklasson retweeted

May 30
Chronic debaters are lethal to new ideas for the same reason pessimists are. They sound smart because they’re good at finding flaws before anything has had a chance to work.
91
135
1,269
152,875
eyvind niklasson retweeted

Jun 9
Long-distance real time teleop.
A lot of people see teleop as a dirty secret in robotics, but only if you're using it whilst saying you're fully autonomous.
It's actually a great step to get to fully autonomy.
We built @Adamorobotics , a low-latency long-distance teleoperation platform for robots to bypass the real-world data bottleneck.
Here's a comparison video of our robot being teleoperated in London
Adamo on the left versus google meets on the right (a WebRTC-based solution)
As you can see there's a big delay. That delay makes teleoperating a lot harder, and the data you capture of far inferior quality.
Adamo is now self-serve so you can feel what low latency long distance teleop feels like for yourself.
4
4
29
10,974
eyvind niklasson retweeted

Jun 7
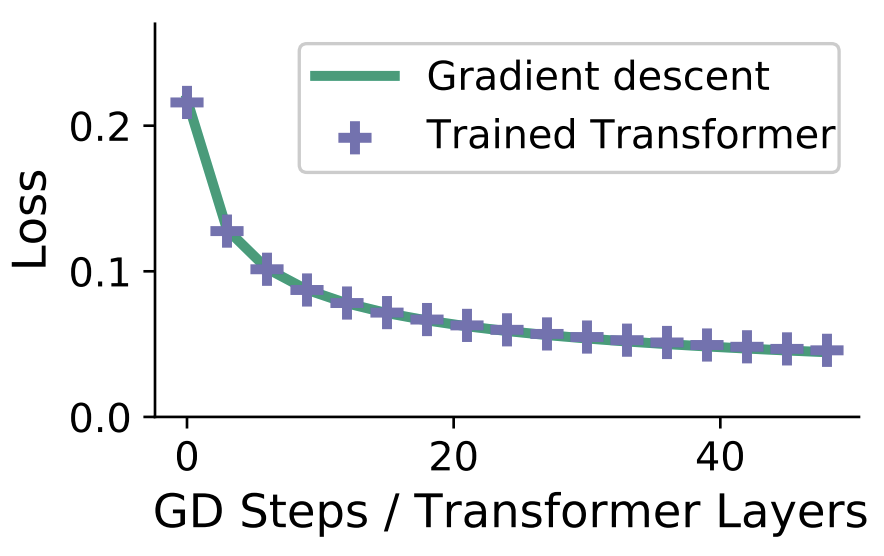
We never really knew how to train nonlinear RNNs well… BPTT struggled with vanishing grads (no long-range memory) and sequential rollout (hard to parallelizable).
What if instead an oracle told us the optimal memory state m_t at each step? Then the RNN could do one-step supervised learning on (m_t, x_{t 1}) → m_{t 1} labels.
We call this Supervised Memory Training (SMT): a replacement for BPTT that trains RNNs without unrolling them. SMT is time-parallelizable and solves vanishing gradients.
Website: akarshkumar.com/smt/
arXiv: arxiv.org/abs/2606.06479

17
119
783
172,950
eyvind niklasson retweeted

Jun 3
How well can a model watch a short video of some physical dynamics and actually predict what happens next?
Introducing MPMWorlds: a new dataset and benchmark to evaluate how well models can reconstruct and extrapolate physical dynamics from video.
zzigak.github.io/mpmworlds/
🧵👇
(1/n)
8
38
192
23,334
eyvind niklasson retweeted

Just finished listening—a fantastic discussion on the evolution and future of AI at Google. I was also thrilled to hear @sundarpichai highlight our research moonshot Project Suncatcher and the incredible work my team is doing to explore the frontiers of data centers in space.
Apr 7

.@sundarpichai joined @eladgil and me in the Cheeky Pint pub. I was excited to get into Google in 2026: how AGI-pilled Google is, compute bottlenecks, fast AI products, $180b capex, the intelligence overhang at enterprises, and deciding capital allocation at a company overflowing with ideas.
1
2
31
2,982
eyvind niklasson retweeted

Jun 4
The Bitter Lesson and Artificial Life. Everything we know about (1) scaling laws in AI (2) how to discover the ideal abstraction basin in scientific simulations suggest that the next big breakthrough in ALIfe will come from massive training runs first and massive theoretical breakthroughs second.
4
1
43
8,855
eyvind niklasson retweeted

May 28
After automating AI research with @SchmidhuberAI and building AI Scientists at DeepMind, now comes the real experiment: the institution itself.
Excited to co-found @inherent_labs: the recursively self-improving lab for scientific AI.
inherentlabs.ai
May 28

We’re excited to introduce Inherent, a lab designed from scratch to build AI agents that discover new knowledge.
The coming era of machine-driven scientific inquiry demands a new kind of research institution and a new kind of AI.
To achieve our mission, we live within the experiment, recursively self-improving the entire research organisation. We investigate questions including:
- What does ‘AI taste’ look like in the sciences, and how can we build an institution that embraces this new aesthetic of discovery?
- What new kinds of human-machine teaming will make the most of AI that can truly innovate?
- How can we build recursive self-improvement at the collective level that continually increases human agency over outcomes?
We have just closed a $50m seed round led by @IndexVentures and @radicalvcfund, with participation from other outstanding investors including NVentures (@nvidia's venture capital arm), @buildexante, Metaplanet, Macroscopic, @MythosVentures, Charlie Songhurst, @chalfs, @jluan, @dwarkesh_sp, @Thom_Wolf, @j_foerst and @maxjaderberg. We are advised by @matthewclifford.
Inherent is a Public Benefit Corporation headquartered in London.

24
43
526
71,378
eyvind niklasson retweeted

May 27
My babies are getting so smart, it's freaking me out.
I was looking forward to using GA or bayesian optimisation to find a sweet set of parameters, but hand-tuning is giving scarily good results. I cant stop watching!
(No global coordinator, all acting entirely on local cues)
30
55
480
40,186

For over a decade, we’ve accepted that end-to-end backprop is the only way to train deep networks. But holding the entire network in memory all at once is why AI training is hitting a resource wall.
We found a new way to break the network into blocks and train them independently. The trick? Treating the network’s forward pass like a diffusion model denoising a signal.
This reinterpretation slashes the memory needed to train deep models. In our #ICLR2026 paper (arxiv.org/abs/2506.14202), we matched end-to-end performance across ViTs, DiTs, and LLMs. We did this while training just one isolated block at a time.
May 27

Introducing DiffusionBlocks: Block-wise Neural Network Training via Diffusion Interpretation
pub.sakana.ai/diffusionblock…
What if we didn’t have to hold an entire neural network in memory to train it?
Standard neural net training optimizes all parameters jointly. As a result, the memory required during training grows linearly with the depth of the network.
In our #ICLR2026 paper, we propose DiffusionBlocks, a principled framework to train networks one block at a time, drastically reducing memory requirements while matching end-to-end performance.
With DiffusionBlocks, we split the network into blocks and train them one at a time, so you only need memory for a single block.
How? We explicitly assign each block a role: to move the representation a little closer to the target than the block before it did. That role turns out to be precisely what a diffusion model does, step by step. Each block only needs to optimize its own objective and can be trained independently.
We validated this across five different architectures:
• ViT
• DiT
• Masked diffusion
• Autoregressive transformers
• Recurrent-depth transformers
In each case, performance is competitive with end-to-end training while using a fraction of the memory.
This perspective also extends naturally to recurrent-depth (Looped) transformers, which apply the same network iteratively and normally require expensive backpropagation through time (BPTT). Viewed through DiffusionBlocks, we can replace those multiple iterations with a single forward pass during training.
Read our paper and code, to learn more.
Paper: arxiv.org/abs/2506.14202
GitHub: github.com/SakanaAI/Diffusio…
🐟
154
640
5,768
742,311
eyvind niklasson retweeted

May 25
158
559
2,939
273,415
eyvind niklasson retweeted

May 18
About "transformers are recurrent": teacher-forced discrete tokens cannot play a mind's melody.
May 18

The AGI will be a RNN
10
1
63
15,364
eyvind niklasson retweeted

May 18
The bitter lesson in 26 words:
Don’t be distracted by human knowledge, as AI has been historically.
Instead focus on methods for creating knowledge that scale with computation, like search and learning.
136
972
7,415
575,444
eyvind niklasson retweeted

World modeling. Faster RL. Self-improvement without verifiers.
All from one extra loss term on your favorite open-weights CLI agent.
Happy Monday!

7
27
229
34,309
eyvind niklasson retweeted
Found something in my daily use of Claude Code that validates our Memento results:
Claude Code flushes the KV cache after some idle period, and when I come back past that the model is noticeably harder to work with.
Conjecture: post-flush, the model is no longer continuing its trajectory. It's shoved into a weird OOD regime where it has to simulate what has happened from the tokens and resume from a reconstruction.
Which is much harder than just continuing!!
We measured this effect in our paper. KV states (soft embeddings) carry information that text tokens don't, even when attention is masked.
Bottom line: If you flush your cache you lose a lot of accuracy!
45
70
839
153,868
eyvind niklasson retweeted

Our work goes beyond just ‘an analysis’.
By combining microfluidic experiments with theoretical modeling, we discovered the actual mechanism: E. coli perform recurrent, neural-like computation to navigate the physical trade-off between immediate growth and future survival.

An analysis tracking E.coli in fluctuating nutrient conditions maps out a reaction-network architecture that integrates environmental history to tune future growth, showing how even the simplest organisms implement complex computational strategies.
🔗 go.aps.org/4tyo7GL
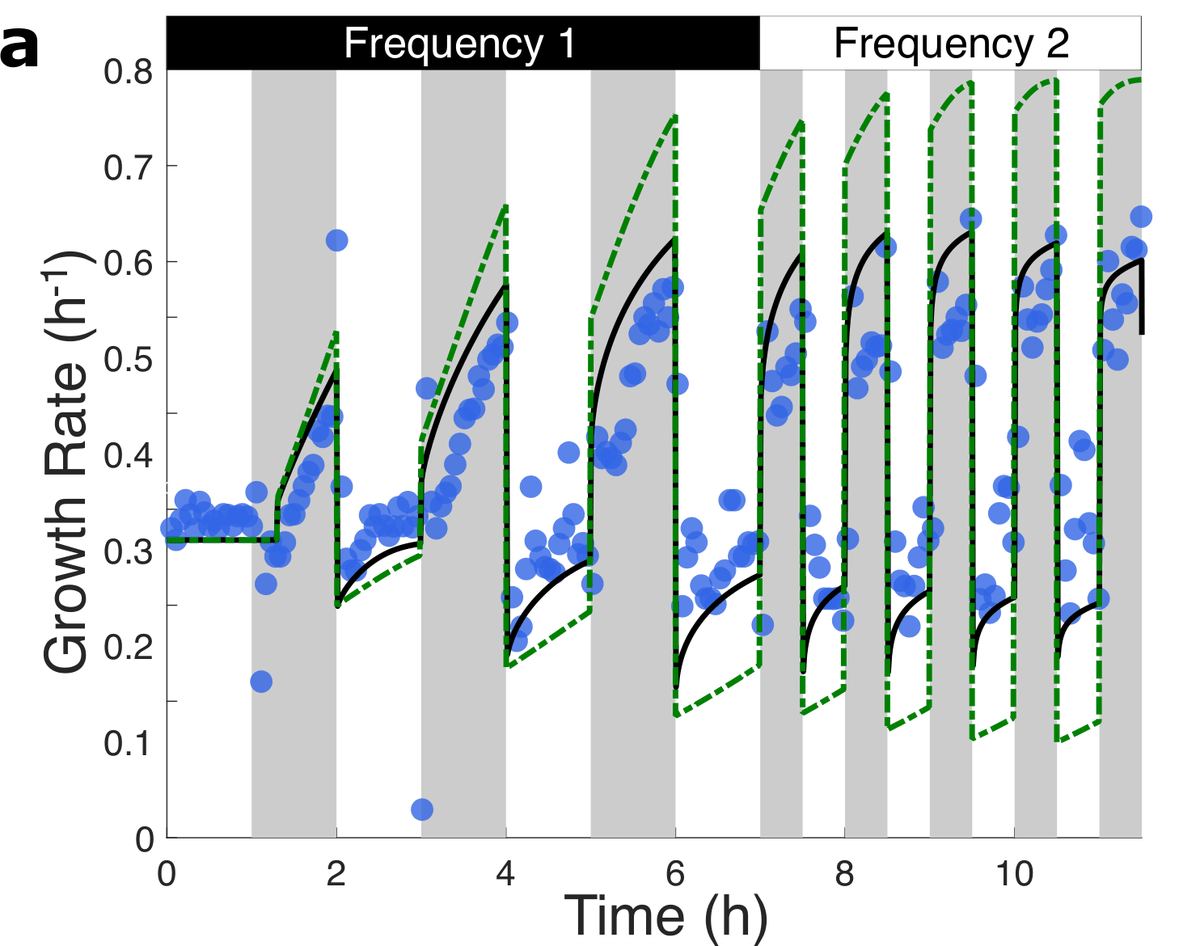
ALT A chart plotting the growth rate dynamics for E.coli under the study’s dynamic memory model. The graph plots time in hours on the x-axis and growth rate in h-1 on the y-axis. The predicted growth rate is represented by a black line, while blue dots represent experimental measurements of the growth rate, and a dashed green line represents a prediction of growth rate from the Markovian model. The chart tracks the growth rate of the bacteria across two differing periods of nutrient-rich pulsing: frequency 1 (0 to 7 hours) and frequency 2 (7-13 hours).
1
2
28
2,269
eyvind niklasson retweeted

May 13
Excited to co-found Recursive (@recursive_si) with an exceptional team in London and SF to create AI that experiments on how to safely improve itself, turning compute into knowledge that accumulates in an open-ended process of endless, automated scientific discoveries.
98
111
906
252,846
eyvind niklasson retweeted

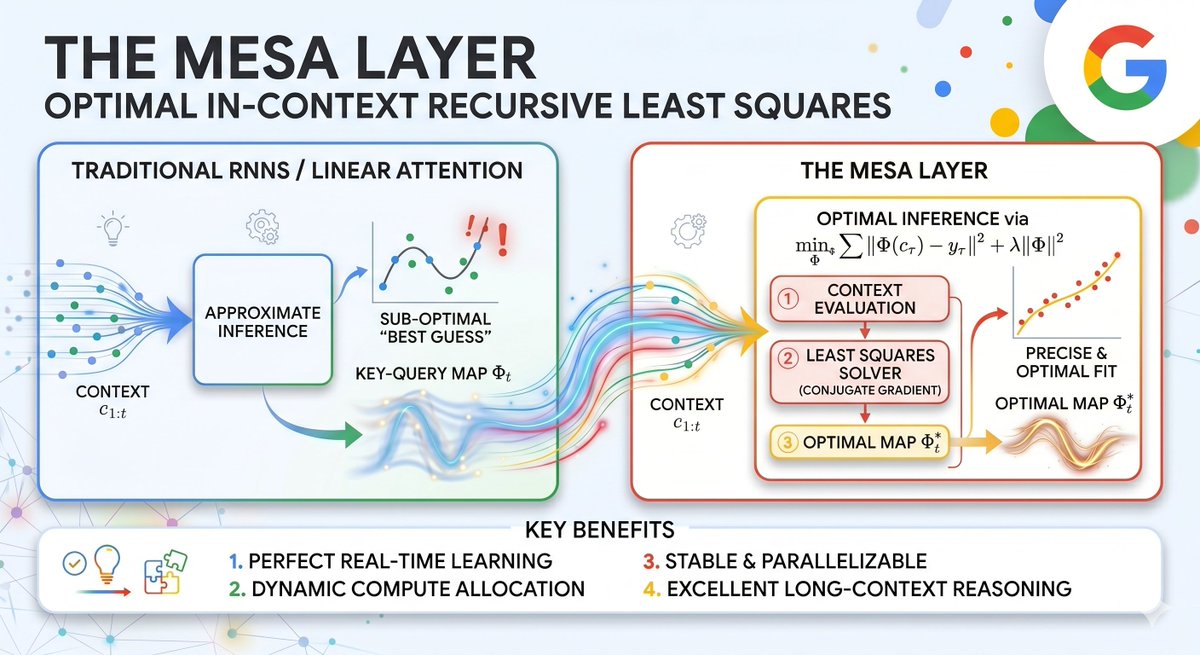
Apr 24
Google presents a new Transformer alternative at #ICLR2026! Join Nino Scherrer & Yanick Schimpf at the Google booth (#411) at 10AM to learn about MesaNet, proposing a new linear sequence layer that optimally learns in-context given a fixed memory budget.
37
130
959
61,267

Imagine every pixel on your screen, streamed live directly from a model. No HTML, no layout engine, no code. Just exactly what you want to see.
@eddiejiao_obj, @drewocarr and I built a prototype to see how this could actually work, and set out to make it real. We're calling it Flipbook. (1/5)
1,142
3,734
28,818
5,955,565

Natural evolution's open-endedness leads to beautiful, complex emergent structures and self-organizing behavior 🌱✨. Replicating this in silico is famously hard 💻. Our paper points to a promising direction by evolving populations of competing neural cellular automata with lifelike behavior 🧬🤖 #Isambard
⚠️⚠️flashing lights, rapid cuts, or strobe effects in this thread! 🚨🚨
1/n
3
29
148
25,335
eyvind niklasson retweeted
So fun watching looped transformers taking off this week! Worth mentioning that @AngelikiGiannou & @shashank_r12 coined the term and gave a beautiful looped construction of an assembly-like computer in Jan 2023 arxiv.org/abs/2301.13196

5
49
405
45,199