
Joined December 2011
- Tweets 1,925
- Following 4,175
- Followers 129
- Likes 7,122
4 Photos and videos
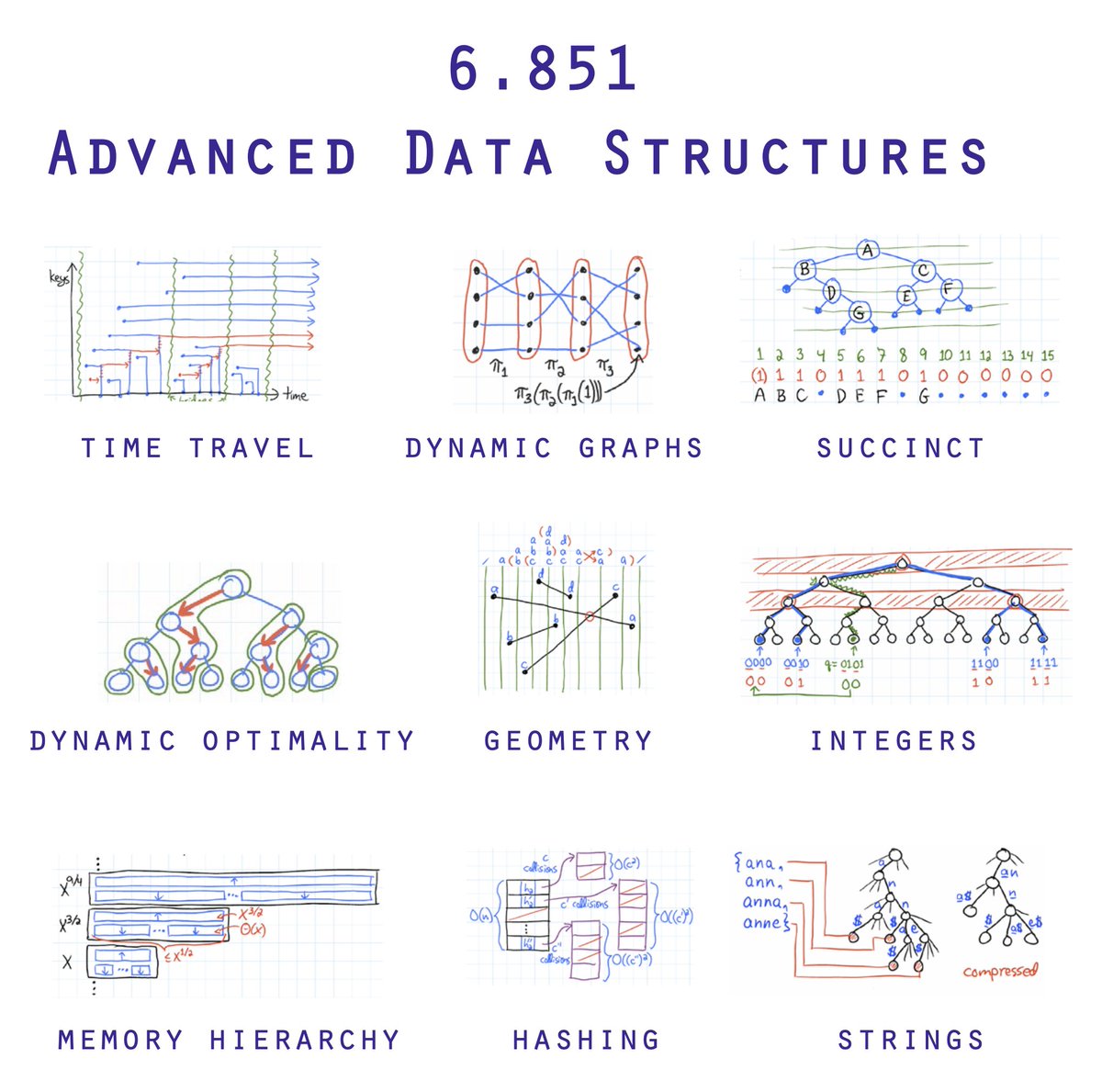
Stefan Bachhofner retweeted

Jun 10
One of the finest
courses.csail.mit.edu/6.851/…
6
193
1,637
54,816
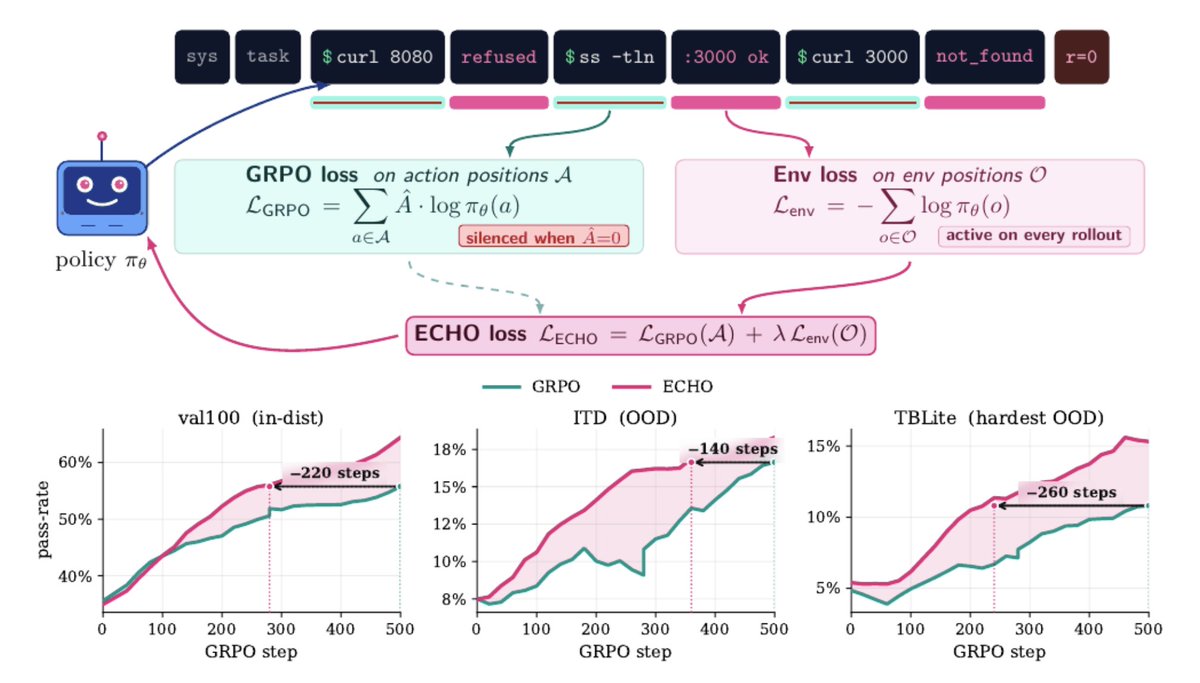
Stefan Bachhofner retweeted

Very rarely you stumble on a method that's simple, obvious in hindsight, free, and touches on every problem you care about: CLI agents, continual learning, self-improvement, world models.
ECHO is one of those

10
49
573
78,733
Stefan Bachhofner retweeted

May 18
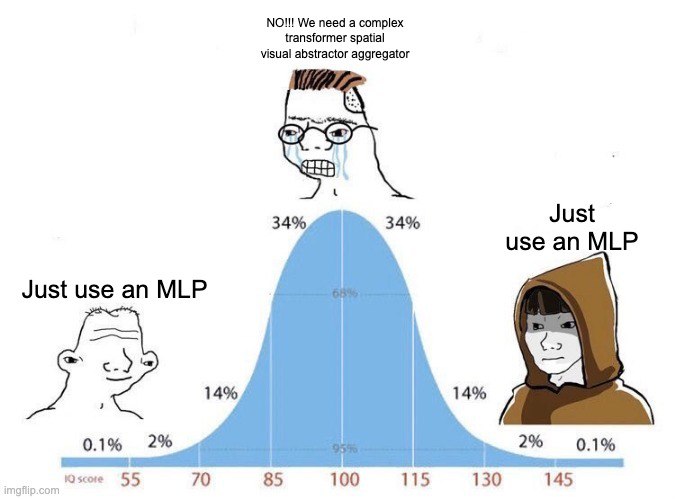
And the trend continues with Gemma 4, simplicity wins again!

20 Apr 2025

Many VLM papers propose new connectors claiming improved performance, but then every follow-up paper just replaces it with a super simple MLP (1 or 2 layers)
Simplicity wins again
10
66
989
90,126
Stefan Bachhofner retweeted

May 17
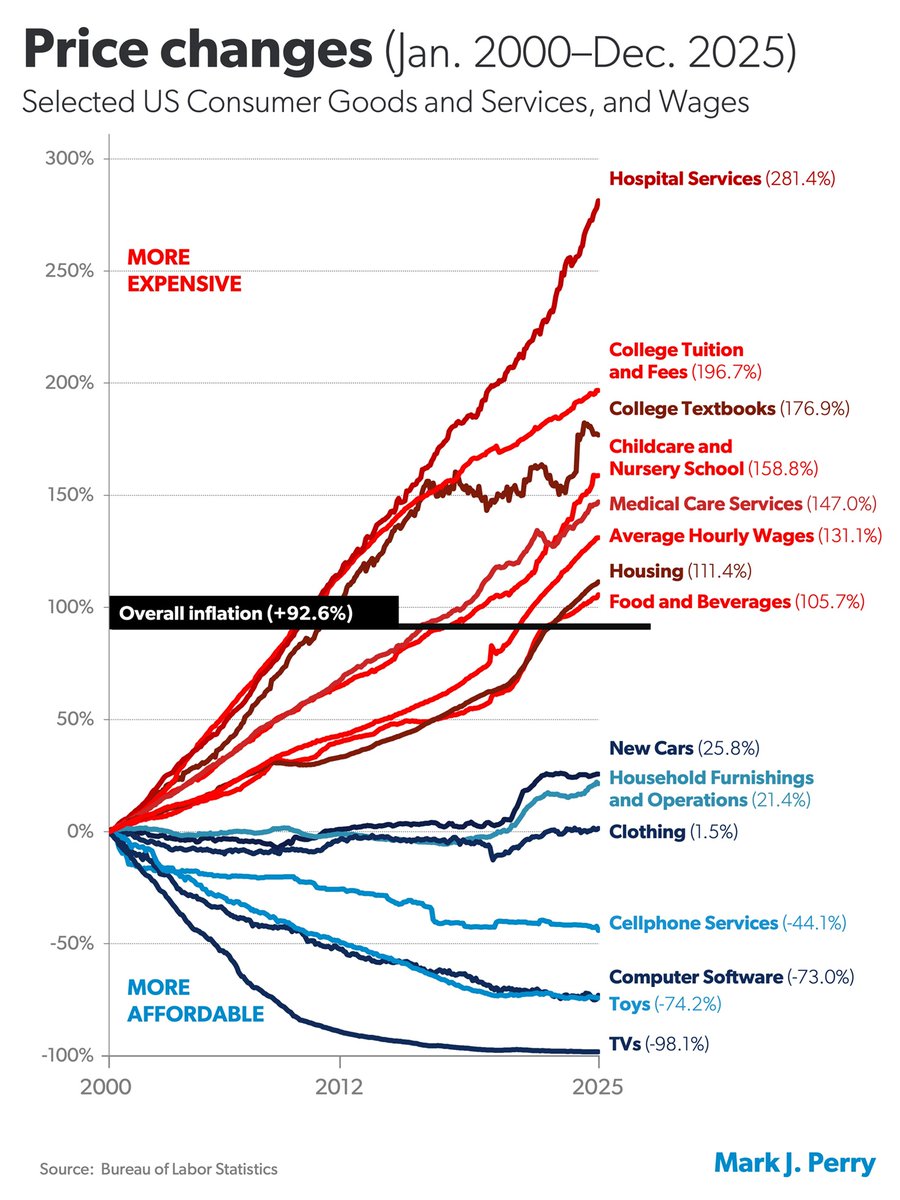
Interesting.

57
104
877
114,494
Stefan Bachhofner retweeted

May 18
This applies to many other fields too, computing and data science in particular...

Terence Tao says AI is forcing mathematics to rethink graduate education
Many problems used to train young mathematicians now overlap with what AI can plausibly solve, which creates a cultural challenge
"it's hard to define the shift clearly, but we need to address it soon"
2
23
161
26,373
Stefan Bachhofner retweeted
The co-inventor of Looped Transformers defended her PhD thesis yesterday and is heading to an incredible new role soon :) congratulations @AngelikiGiannou 🥳 🎉🎈

13
27
673
56,598
Stefan Bachhofner retweeted

May 5
Counterpoint: Capitalism does a far better job than socialism of feeding people.
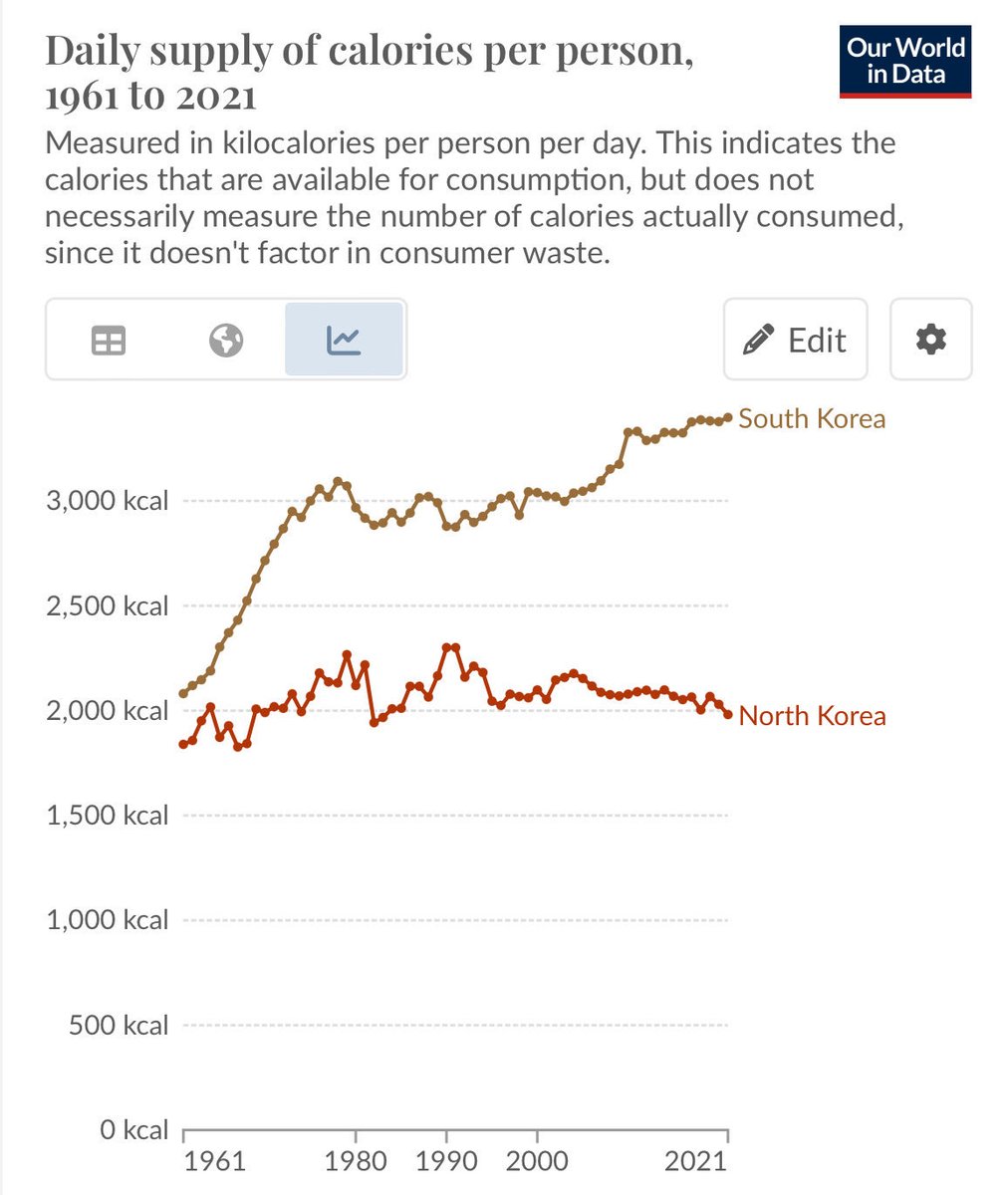

A reminder that we produce enough food for 1.5x the Earth’s population. Capitalism prevents hungry people from eating it
86
192
1,294
27,765
Stefan Bachhofner retweeted
Apr 20
Counterpoint:

Apr 20

🇨🇺 Fidel Castro: «Porque ¿qué ha resuelto el capitalismo? No ha resuelto ningún problema. Ha saqueado el mundo. Ha dejado toda esta pobreza.»
10
38
409
8,833
Stefan Bachhofner retweeted

Apr 11
Bono was right and the anti-capitalists are wrong.



55
457
3,762
159,147
Stefan Bachhofner retweeted

Apr 7
Why I got back into research a decade ago: I read the 2015 “neural nets = spin glasses” paper by @ylecun, "The Loss Surfaces of Multilayer Networks". 𝐓𝐡𝐢𝐬 𝐢𝐬 𝐭𝐡𝐞 𝐰𝐨𝐫𝐬𝐭 𝐀𝐈 𝐭𝐡𝐞𝐨𝐫𝐲 𝐩𝐚𝐩𝐞𝐫 𝐢𝐧 𝐡𝐢𝐬𝐭𝐨𝐫𝐲.
It’s bad enough to not properly cite @SchmidhuberAI ; JEPA might actually be useful.
This work has misled the field for a decade.
Back in 2015, I was having coffee with my late PhD advisor Karl Freed (postdoc with Sam Edwards, who invented spin glasses!) while he was visiting SF. Karl was advising John Jumper at the time, who, less than 10 years later, won the Nobel Prize for AlphaFold in 2024.
We were discussing John's thesis work, and some of the early, overly simplistic generalized spin glass models of protein folding.
Karl remarked to me how Edwards was actually disappointed that no one followed his other work, and that so many people used spin-glasses in totally inappropriate ways. And that’s putting it kindly.
So what’s so bad about this 2015 spin-glass paper by LeCun ?
The paper naively modeled a toy feedforward net as a Gaussian spin glass. Specifically, a Gaussian p-spin spherical spin glass Hamiltonian (via the CLT on randomized , etc.). They just assumed independence uniformity redundancy, then forced the loss to look like what felt like a good story.
But it never checked the core assumptions. And anyone who actually knows start mech also knows that there are a wide range of spin glass models. Small changes in the disorder distribution (Gaussian vs heavy-tailed Lévy couplings) completely alter the landscape, critical points, and minima structure.
Importantly, strongly correlated systems can live in a completely different universality class from random Gaussian objects! This is elementary disordered systems physics (Bouchaud, Galluccio et al., late 90s).
The paper skipped that homework entirely. It told a good story. But it was more politics than science.
It’s one thing to be a misinformed idiot (his words, not mine)....It’s far worse to slap your name on a paper outside your depth, promote it as serious theory, and make the whole field dumber.
I guess I should thank @ylecun. Back then, I was a scientific advisor to Larry Page’s family and had some free cycles.
I realized I could do better work than this in my spare time, and with no funding. Science self-corrects slowly.
Stay tuned while I explain the difference between @ylecun politicking and the actual theory behind why AI works.
2
8
65
31,593
Stefan Bachhofner retweeted

Apr 7
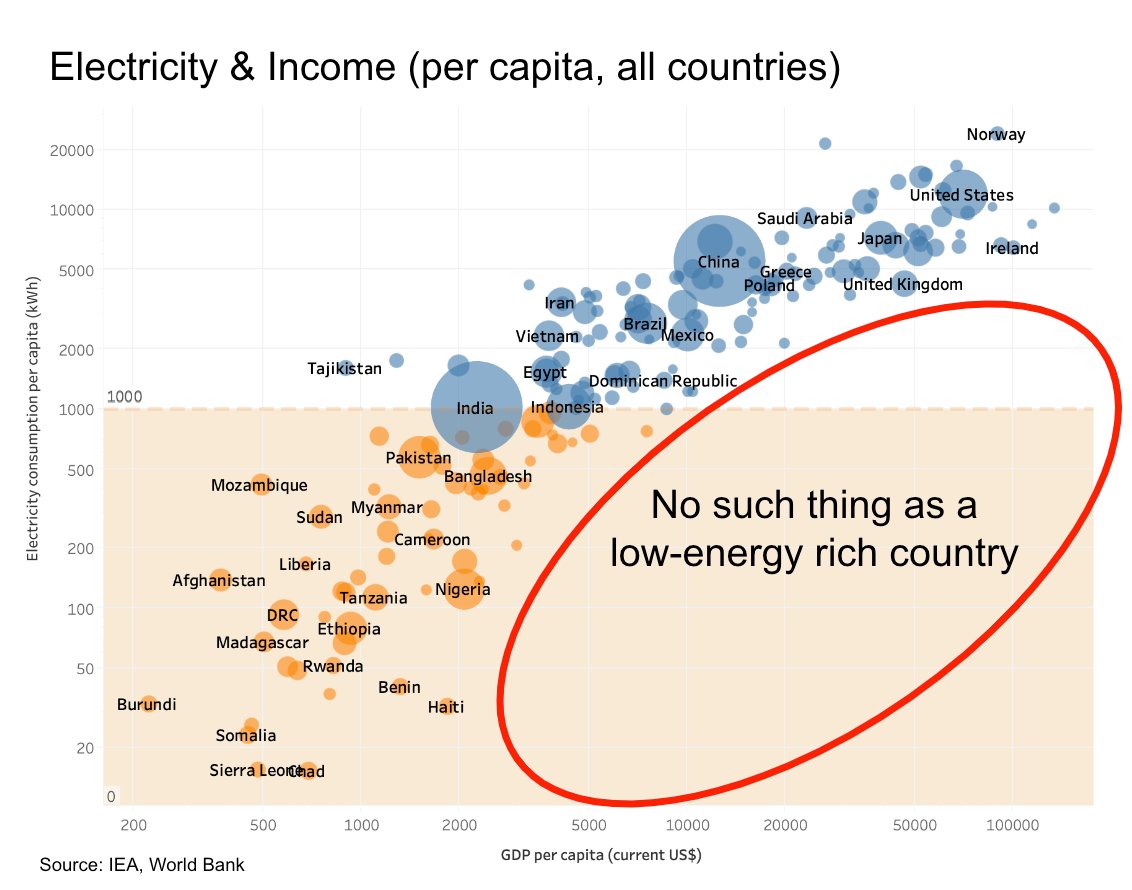
a great day to share this graph
133
2,158
13,682
627,677
Stefan Bachhofner retweeted

Apr 7
Die Washington Post, sicherlich nicht der unkritischen Miliei-Verehrung verdächtig, zieht ein bemerkenswertes Zwischenfazit zu Mileis Kurs:
- Armutsquote gon 53% auf 28% gefallen. Durch echtes Wirtschaftswachstum von 4,4% im letzten Jahr.
- erster StaatsbudgetÜBERSCHUSS IN 123 Jahren
- Inflation von 200% auf 33% gesunken (und weiter fallend)
- Abschaffung von 14000 Gesetzen und Regulierungen, um die Freiheit des Markts wirken zu lassen.
Fazit: „Argentina’s rapid transformation from nearly a century of socialism to free market capitalism continues to prove the superiority of the latter. It is rare that we get to witness such a radical experiment in real time. It is no surprise, however, that it’s working.“
washingtonpost.com/opinions/…
111
1,180
5,016
227,576
Stefan Bachhofner retweeted
Apr 7
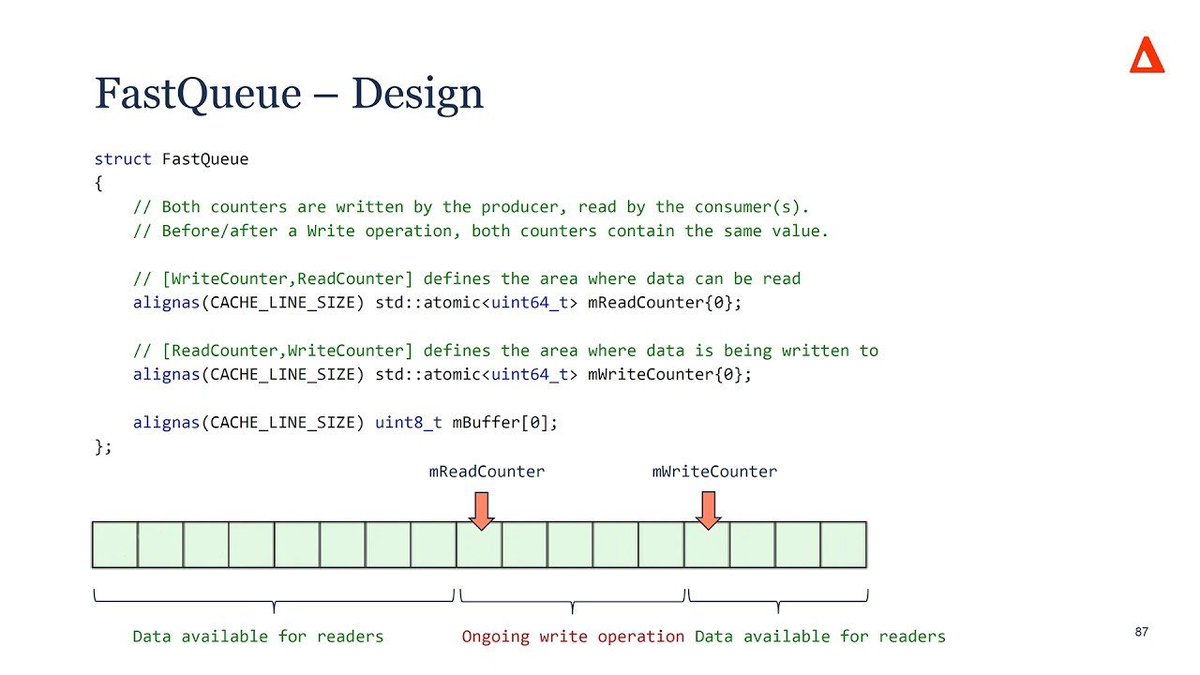
C design patterns for low-latency applications, including HFT.
Mostly perf optimizations familiar from advanced compilers/OS courses - still a good intro if you're trying to build intuition around performance.
arxiv.org/pdf/2309.04259

Apr 6

Ultrafast Trading Systems in C by David Gross
"While low-latency programming is sometimes seen under the umbrella of 'code optimization', the truth is that most of the work needed to achieve such latency is done upfront, at the design phase."
isocpp.org/blog/2025/05/cppc…
2
75
818
46,323
Stefan Bachhofner retweeted

Apr 6
Crazy idea: Let's split a country in socialist and capitalist halves and check in on them in 75 years.

1,278
5,273
30,694
2,912,048
Stefan Bachhofner retweeted
Apr 6
Ultrafast Trading Systems in C by David Gross
"While low-latency programming is sometimes seen under the umbrella of 'code optimization', the truth is that most of the work needed to achieve such latency is done upfront, at the design phase."
isocpp.org/blog/2025/05/cppc…

9
93
1,154
135,114
Stefan Bachhofner retweeted
Apr 6
Those who don't know, I was an NSF postdoc with @SchmidhuberAI PhD's advisor (Schulten) back in the 90s. 1 of 2 in the country. And my PhD groupmate recently won the Nobel prize for AlphaFold. So I have some qualifications here to say 𝐲𝐞𝐚𝐡 𝐭𝐡𝐢𝐬 𝐢𝐬 𝐩𝐫𝐞𝐭𝐭𝐲 𝐚𝐜𝐜𝐮𝐫𝐚𝐭𝐞.
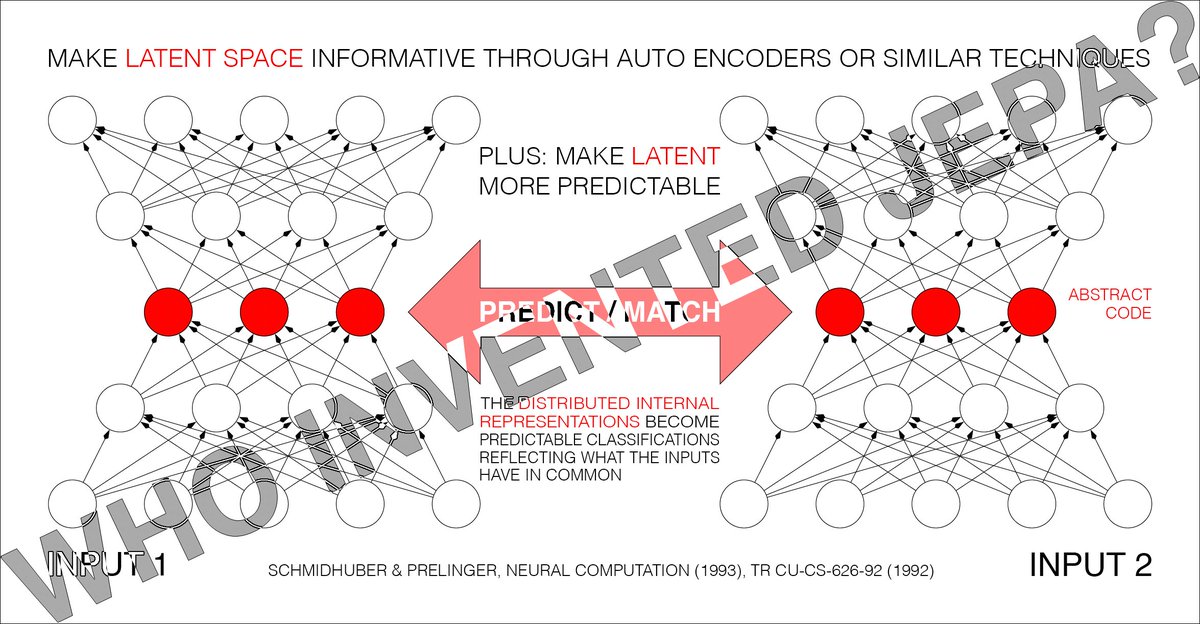
The core learning principle behind JEPA is predicting one representation from another in latent space. And this was already explicitly formulated in the early 1990s PMAX work. PMAX does not merely hint at this idea; it sets up the same structure: two related inputs are encoded, and a predictor learns to map one latent representation to the other, while the encoder is trained to make this prediction possible without collapsing the representation.
That is exactly the defining mechanism of JEPA. When you strip away modern terminology and architectures, both are instances of the same objective: learn representations by maximizing cross-view predictability under constraints that preserve information.
What JEPA adds is not a new theoretical framework. It's just larger models, better architectures, and scaling. Of course, we could not do that in the 90s.
In that sense, Jürgen Schmidhuber made the real and original conceptual breakthrough: non-generative, latent-to-latent predictive learning
This is typical of @ylecun 's work; it's mostly derivative of others' ideas, scaled up and promoted. In contrast, @SchmidhuberAI really did pioneer a lot of these ideas. The JEPA work should have cited him.
Politics >> Integrity.
Mar 31

Dr. LeCun's heavily promoted Joint Embedding Predictive Architecture (JEPA, 2022) [5] is the heart of his new company. However, the core ideas are not original to LeCun. Instead, JEPA is essentially identical to our 1992 Predictability Maximization system (PMAX) [1][14].
Details in reference [19] which contains many additional references.
Motivation of PMAX [1][14]. Since details of inputs are often unpredictable from related inputs, two non-generative artificial neural networks interact as follows: one net tries to create a non-trivial, informative, latent representation of its own input that is predictable from the latent representation of the other net’s input.
PMAX [1][14] is actually a whole family of methods. Consider the simplest instance in Sec. 2.2 of [1]: an auto encoder net sees an input and represents it in its hidden units (its latent space). The other net sees a different but related input and learns to predict (from its own latent space) the auto encoder's latent representation, which in turn tries to become more predictable, without giving up too much information about its own input, to prevent what's now called “collapse." See illustration 5.2 in Sec. 5.5 of [14] on the "extraction of predictable concepts."
The 1992 PMAX paper [1] discusses not only auto encoders but also other techniques for encoding data. The experiments were conducted by my student Daniel Prelinger. The non-generative PMAX outperformed the generative IMAX [2] on a stereo vision task.
The 2020 BYOL [10] is also closely related to PMAX. In 2026, @misovalko, leader of the BYOL team, praised PMAX, and listed numerous similarities to much later work [19].
Note that the self-created “predictable classifications” in the title of [1] (and the so-called “outputs” of the entire system [1]) are typically INTERNAL "distributed representations” (like in the title of Sec. 4.2 of [1]).
The 1992 PMAX paper [1] considers both symmetric and asymmetric nets. In the symmetric case, both nets are constrained to emit "equal (and therefore mutually predictable)" representations [1]. Sec. 4.2 on “finding predictable distributed representations” has an experiment with 2 weight-sharing auto encoders which learn to represent in their latent space what their inputs have in common (see the cover image of this post).
Of course, back then compute was was a million times more expensive, but the fundamental insights of "JEPA" were present, and LeCun has simply repackaged old ideas without citing them [5,6,19].
This is hardly the first time LeCun (or others writing about him) have exaggerated LeCun's own significance by downplaying earlier work. He did NOT "co-invent deep learning" (as some know-nothing "AI influencers" have claimed) [11,13], and he did NOT invent convolutional neural nets (CNNs) [12,6,13], NOR was he even the first to combine CNNs with backpropagation [12,13]. While he got awards for the inventions of other researchers whom he did not cite [6], he did not invent ANY of the key algorithms that underpin modern AI [5,6,19].
LeCun's recent pitch: 1. LLMs such as ChatGPT are insufficient for AGI (which has been obvious to experts in AI & decision making, and is something he once derided @GaryMarcus for pointing out [17]). 2. Neural AIs need what I baptized a neural "world model" in 1990 [8][15] (earlier, less general neural nets of this kind, such as those by Paul Werbos (1987) and others [8], weren't called "world models," although the basic concept itself is ancient [8]). 3. The world model should learn to predict (in non-generative "JEPA" fashion [5]) higher-level predictable abstractions instead of raw pixels: that's the essence of our 1992 PMAX [1][14].
Astonishingly, PMAX or "JEPA" seems to be the unique selling proposition of LeCun's 2026 company on world model-based AI in the physical world, which is apparently based on what we published over 3 decades ago [1,5,6,7,8,13,14], and modeled after our 2014 company on world model-based AGI in the physical world [8].
In short, little if anything in JEPA is new [19]. But then the fact that LeCun would repackage old ideas and present them as his own clearly isn't new either [5,6,18,19].
FOOTNOTES
1. Note that PMAX is NOT the 1991 adversarial Predictability MINimization (PMIN) [3,4]. However, PMAX may use PMIN as a submodule to create informative latent representations [1](Sec. 2.4), and to prevent what's now called “collapse." See the illustration on page 9 of [1].
2. Note that the 1991 PMIN [3] also predicts parts of latent space from other parts. However, PMIN's goal is to REMOVE mutual predictability, to obtain maximally disentangled latent representations called factorial codes. PMIN by itself may use the auto encoder principle in addition to its latent space predictor [3].
3. Neither PMAX nor PMIN was my first non-generative method for predicting latent space, which was published in 1991 in the context of neural net distillation [9]. See also [5-8].
4. While the cognoscenti agree that LLMs are insufficient for AGI, JEPA is so, too. We should know: we have had it for over 3 decades under the name PMAX! Additional techniques are required to achieve AGI, e.g., meta learning, artificial curiosity and creativity, efficient planning with world models, and others [16].
REFERENCES (easy to find on the web):
[1] J. Schmidhuber (JS) & D. Prelinger (1993). Discovering predictable classifications. Neural Computation, 5(4):625-635. Based on TR CU-CS-626-92 (1992): people.idsia.ch/~juergen/pre…
[2] S. Becker, G. E. Hinton (1989). Spatial coherence as an internal teacher for a neural network. TR CRG-TR-89-7, Dept. of CS, U. Toronto.
[3] JS (1992). Learning factorial codes by predictability minimization. Neural Computation, 4(6):863-879. Based on TR CU-CS-565-91, 1991.
[4] JS, M. Eldracher, B. Foltin (1996). Semilinear predictability minimization produces well-known feature detectors. Neural Computation, 8(4):773-786.
[5] JS (2022-23). LeCun's 2022 paper on autonomous machine intelligence rehashes but does not cite essential work of 1990-2015.
[6] JS (2023-25). How 3 Turing awardees republished key methods and ideas whose creators they failed to credit. Technical Report IDSIA-23-23.
[7] JS (2026). Simple but powerful ways of using world models and their latent space. Opening keynote for the World Modeling Workshop, 4-6 Feb, 2026, Mila - Quebec AI Institute.
[8] JS (2026). The Neural World Model Boom. Technical Note IDSIA-2-26.
[9] JS (1991). Neural sequence chunkers. TR FKI-148-91, TUM, April 1991. (See also Technical Note IDSIA-12-25: who invented knowledge distillation with artificial neural networks?)
[10] J. Grill et al (2020). Bootstrap your own latent: A "new" approach to self-supervised Learning. arXiv:2006.07733
[11] JS (2025). Who invented deep learning? Technical Note IDSIA-16-25.
[12] JS (2025). Who invented convolutional neural networks? Technical Note IDSIA-17-25.
[13] JS (2022-25). Annotated History of Modern AI and Deep Learning. Technical Report IDSIA-22-22, arXiv:2212.11279
[14] JS (1993). Network architectures, objective functions, and chain rule. Habilitation Thesis, TUM. See Sec. 5.5 on "Vorhersagbarkeitsmaximierung" (Predictability Maximization).
[15] JS (1990). Making the world differentiable: On using fully recurrent self-supervised neural networks for dynamic reinforcement learning and planning in non-stationary environments. Technical Report FKI-126-90, TUM.
[16] JS (1990-2026). AI Blog.
[17] @GaryMarcus. Open letter responding to @ylecun. A memo for future intellectual historians. Substack, June 2024.
[18] G. Marcus. The False Glorification of @ylecun. Don’t believe everything you read. Substack, Nov 2025.
[19] J. Schmidhuber. Who invented JEPA? Technical Note IDSIA-3-22, IDSIA, Switzerland, March 2026. people.idsia.ch/~juergen/who…
17
82
774
150,023
Stefan Bachhofner retweeted

Apr 4
tfw you ablate ... checks notes ... literally everything, and it still works!

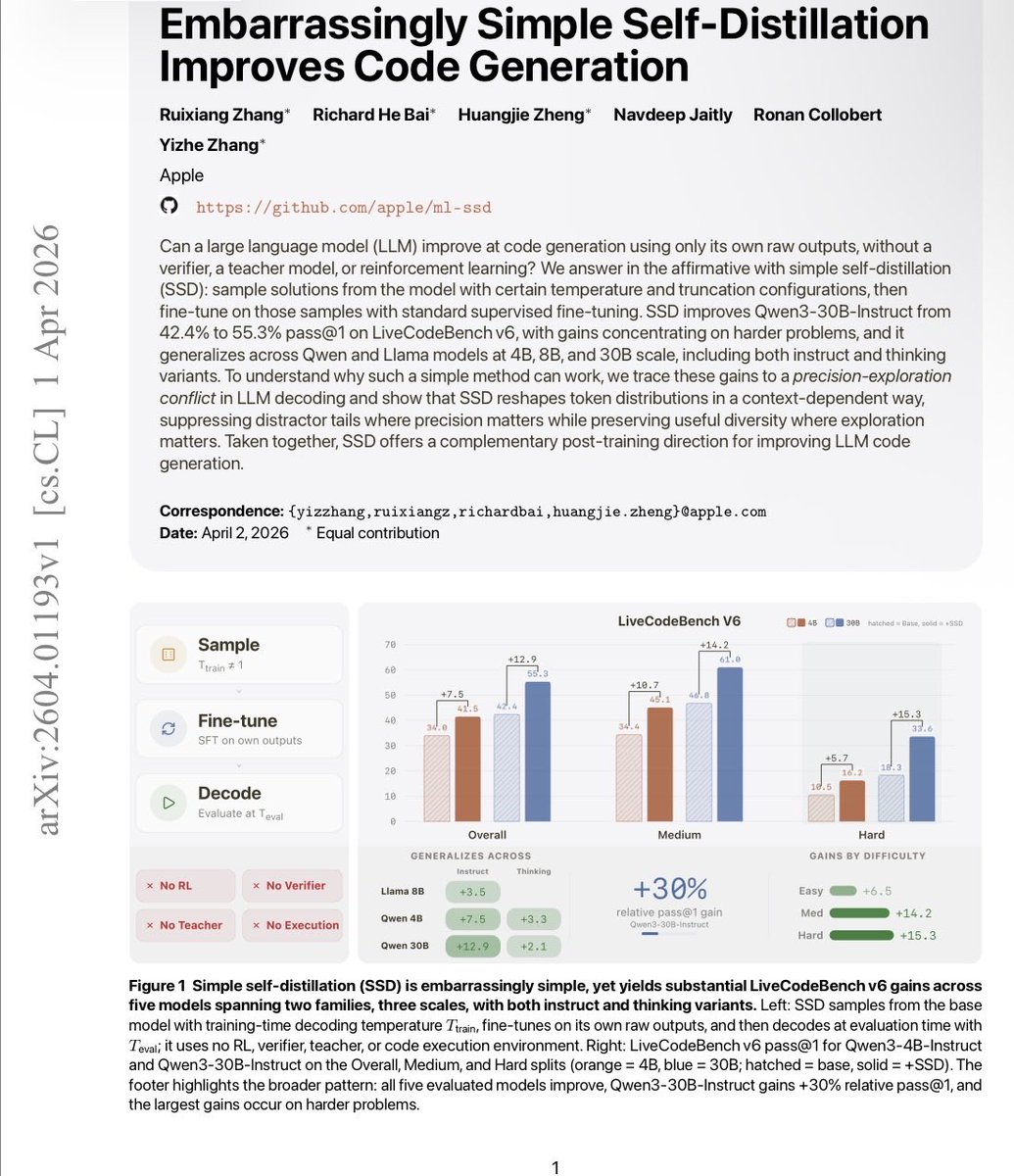
Apple Research just published something really interesting about post-training of coding models.
You don't need a better teacher. You don't need a verifier. You don't need RL.
A model can just… train on its own outputs. And get dramatically better.
Simple Self-Distillation (SSD): sample solutions from your model, don't filter them for correctness at all, fine-tune on the raw outputs. That's it.
Qwen3-30B-Instruct: 42.4% → 55.3% pass@1 on LiveCodeBench. 30% relative. On hard problems specifically, pass@5 goes from 31.1% → 54.1%.
Works across Qwen and Llama, at 4B, 8B, and 30B. One sample per prompt is enough. No execution environment. No reward model. No labels.
SSD sidesteps this by reshaping distributions in a context-dependent way — suppressing distractors at locks while keeping diversity alive at forks. The capability was already in the model. Fixed decoding just couldn't access it.
The implication: a lot of coding models are underperforming their own weights. Post-training on self-generated data isn't just a cheap trick — it's recovering latent capacity that greedy decoding leaves on the table.
paper: arxiv.org/abs/2604.01193
code: github.com/apple/ml-ssd
18
27
638
125,962
Stefan Bachhofner retweeted

Apr 3
This work from @voooooogel was pretty ground-breaking:
vgel.me/posts/representation…
Apr 2

We studied one of our recent models and found that it draws on emotion concepts learned from human text to inhabit its role as “Claude, the AI Assistant”. These representations influence its behavior the way emotions might influence a human.
Read more: anthropic.com/research/emoti…

18
64
560
80,244
Stefan Bachhofner retweeted

Mar 30
Oleksandr Yakovenko, the founder of TAF Industries, one of Ukraine's largest drone makers wrote a good response to @RheinmetallAG's Papperger's irritating statement. I used AI to translate it for you. It is worth reading in full.
"Dear Mr. Armin Papperger, CEO of Rheinmetall,
When you called Ukrainian drone manufacturers “Ukrainian housewives with 3D printers in their kitchens,” you demonstrated how deeply the European defense establishment still fails to understand the nature of modern warfare.
This is not about emоtions. This is about battlefield reality.
Here are the figures your industry refuses to acknowledge:
In 2025 alone, Ukrainian drones carried out 819,737 confirmed strikes. They accounted for 90% of all combat losses of the Russian army—more than all other types of weapons combined.
A single company, TAF Industries, produces up to 100,000 FPV drones per month. Over any given 90-day period, the products of my company alone have more confirmed hits than your entire fleet of equipment over its entire history of combat use across all conflicts. And most importantly—I built this company and achieved these results in two years, not fifty. Think about that.
Our drones achieve greater kinetic effect in three months than your flagship platforms have in half a century.
Why? Because the battlefield has changed, while your business model has not.
Russian electronic warfare has rendered GPS-guided Western munitions (Excalibur, GMLRS, etc.) almost ineffective.
Expensive and complex systems designed for wars with air superiority and conventional “peer-on-peer” conflict have become easy targets for drones costing $500–2,000 that attack them from above.
The cost-effectiveness ratio has been turned upside down: one 120mm Rheinmetall shell or one anti-tank missile costs more than a dozen of our drones—yet our drones still prevail.
This is not a “Lego game.” This is industrial Darwinism in real time. We iterate weekly. We lose factories to missile strikes and rebuild them within weeks. We print parts in basements and deploy 100,000 strike systems per month, while your engineers still require 3–5 years and hundreds of millions of euros to certify even minor upgrades.
The war in Ukraine is not a temporary anomaly. It is the first true drone-industrial war. And it has already proven that outdated European platforms—no matter how expensive or “serious”—are becoming increasingly irrelevant if they do not integrate the very technologies you are mocking.
So when you say “this is not innovation,” I hear something else: “We do not want to admit that the future is being written in Ukrainian workshops, not in Düsseldorf offices.”
The hashtag #MadeByHousewives is trending for a reason. Because these “housewives” destroy more enemy equipment every month than entire European armies do over full campaigns. And they do so while your industry continues to sell 20th-century solutions at 21st-century prices.
The invitation stands, Mr. Papperger. Stop laughing at the kitchen table. Come and learn how the war of tomorrow is actually fought. Because the next time someone asks, “Who needs tanks in the age of drones?”, the answer may be simpler than you think:
Those who still believe in 1979 will lose to those who are building in 2026.
With respect (but with facts),
Oleksandr Yakovenko
Founder of TAF Industries
One of those “Ukrainian housewives”"
pravda.com.ua/columns/2026/0…
177
1,899
5,222
408,938
Stefan Bachhofner retweeted

Mar 29
376
1,211
4,740
4,142,892