
building @protzilla. (ᴅʀᴜɢs, ᴘʀᴏᴛᴇɪɴs) × ᴍʟ. bioinformatics @TU_Muenchen. researcher @rostlab. prev @iGEM_Munich & steineggerlab. 🇺🇸🇩🇪.
Joined August 2023
- Tweets 246
- Following 1,976
- Followers 268
- Likes 2,492
13 Photos and videos








Finn retweeted

Protein Language Modeling Beyond Static Folds Reveals Sequence-Encoded Flexibility
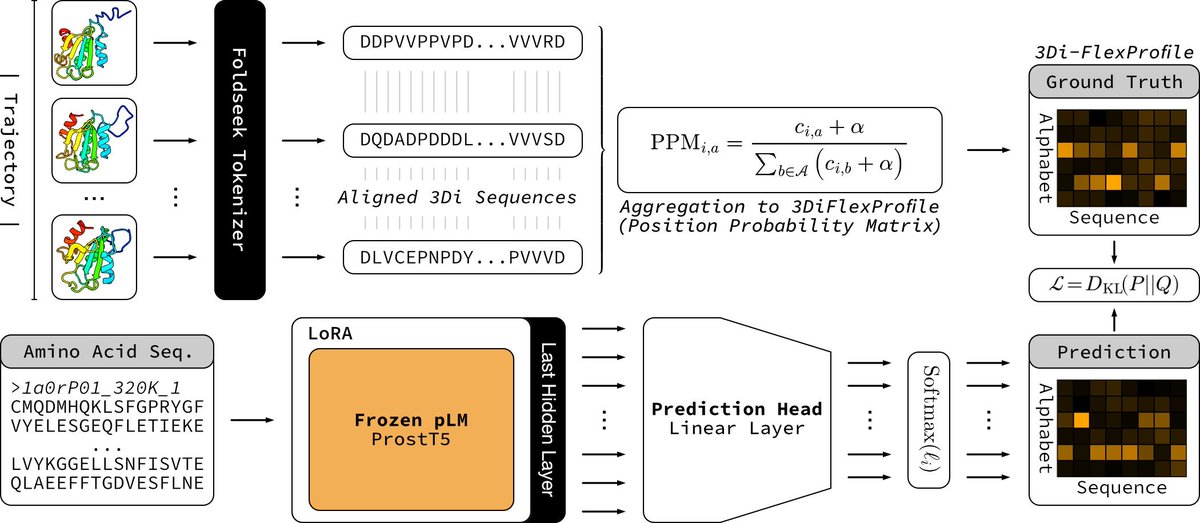
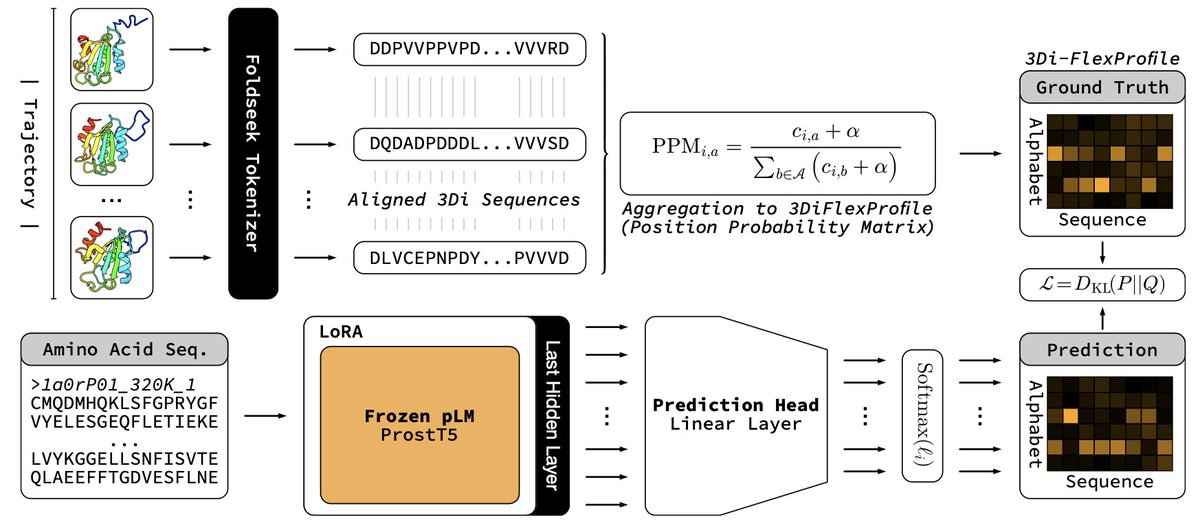
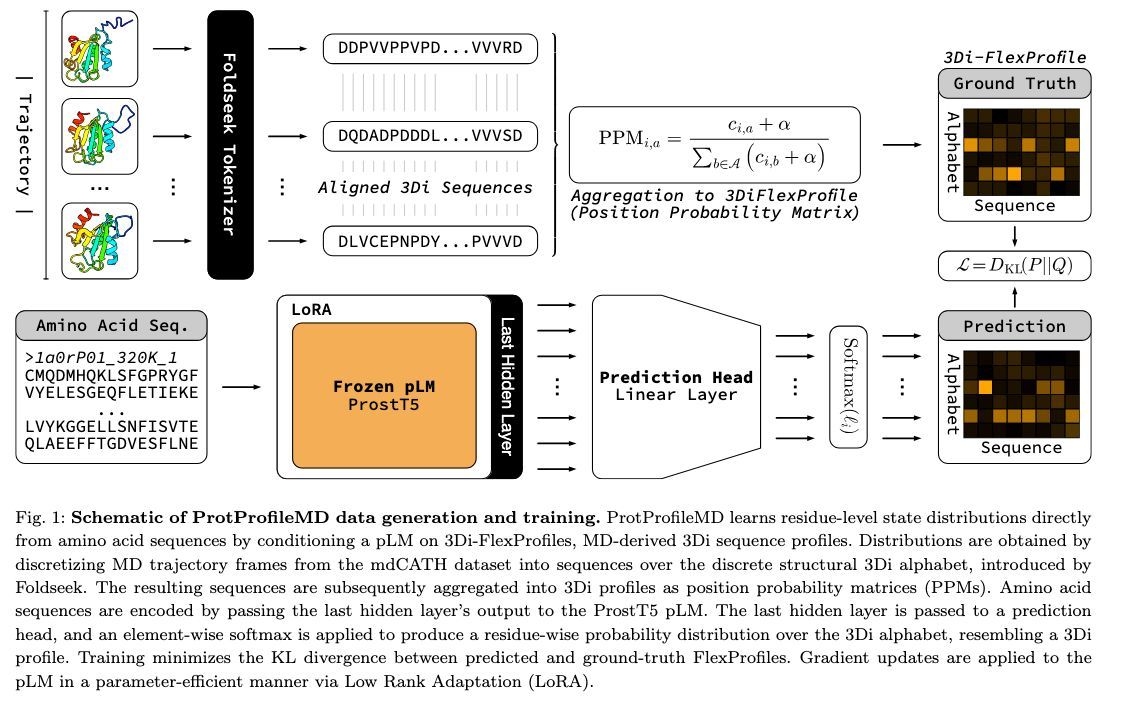
1 ProtProfileMD translates a single amino-acid sequence into a per-residue probability profile over 3Di structural tokens, capturing how often each local conformation is visited during MD without running any simulation at query time.
2 The model distills 5 398 CATH domains’ 320 K trajectories into a 3Di “FlexProfile”; entropy of the predicted profile correlates with RMSF at PCC 0.60, flagging flexible or disordered segments genome-wide in seconds.
3 Supervised LoRA fine-tuning of ProstT5 (only 2.2 M trainable params) lets the pLM learn an implicit energy-weighted ensemble, bypassing costly all-atom ensemble generation while staying proteome-scalable (~0.1 s/protein).
4 Remote homology detection benchmarked on SCOPe shows ROC-AUC gains at Family, Superfamily and Fold levels over standard 3Di search, proving that dynamics fingerprints boost sensitivity beyond static structure tokens.
5 Framework is alphabet-agnostic: any structural vocabulary (PB, DSSP, internal coords) or experimental ensemble (cryo-EM, NMR) can replace 3Di, making FlexProfiles a generic route to encode motion inside language models.
💻Code: github.com/finnlueth/ProtPro…
📜Paper: biorxiv.org/content/10.64898…
#proteindynamics #proteinlanguageModel #computationalBiology #bioinformatics #mdSimulation #structuralAlphabet #homologyDetection
6
31
2,026
Finn retweeted

Absolutely great work by my bachelor student @finnlueth: we tried to make proteins searchable not by sequence or structure but dynamics. For this, we built profiles from Foldseek's 3Di alphabet not using homologous structures but different conformations: x.com/i/status/2015205866883…
Jan 24

My bachelor's thesis (Protein Language Modeling beyond static folds reveals sequence-encoded flexibility) is now a preprint. ProtProfileMD is a fine-tune of ProstT5 that learned per-residue 3Di probability profiles generated from mdCATH molecular dynamics trajectories. The probability profiles recovered flexibility signals and boosted remote homology detection.
Thanks to my supervisors, advisors, and collaborators @HeinzingerM @BurkhardRost, Steinegger Lab, and @rostlab for making it possible.
1
1
14
1,270

Jan 24
My bachelor's thesis (Protein Language Modeling beyond static folds reveals sequence-encoded flexibility) is now a preprint. ProtProfileMD is a fine-tune of ProstT5 that learned per-residue 3Di probability profiles generated from mdCATH molecular dynamics trajectories. The probability profiles recovered flexibility signals and boosted remote homology detection.
Thanks to my supervisors, advisors, and collaborators @HeinzingerM @BurkhardRost, Steinegger Lab, and @rostlab for making it possible.
4
5
65
4,352
Jan 24
Code: github.com/finnlueth/ProtPro…
Model: huggingface.co/finnlueth/Pro…
Data: huggingface.co/datasets/finn…
1
276
Finn retweeted

Protein Language Modeling beyond static folds reveals sequence-encoded flexibility biorxiv.org/content/10.64898… 🧬💻🧪 github.com/finnlueth/protpro…
2
10
92
4,466
Finn retweeted

Jan 22
Quite pleased to hear that one of my submitted proteins placed #5 out of 1200 that were tested in this lovely competition. The approach: pure rational design. Nice to see that human Microsoft Word is still competitive with state-of-the-art AI methods 🙂

Jan 22

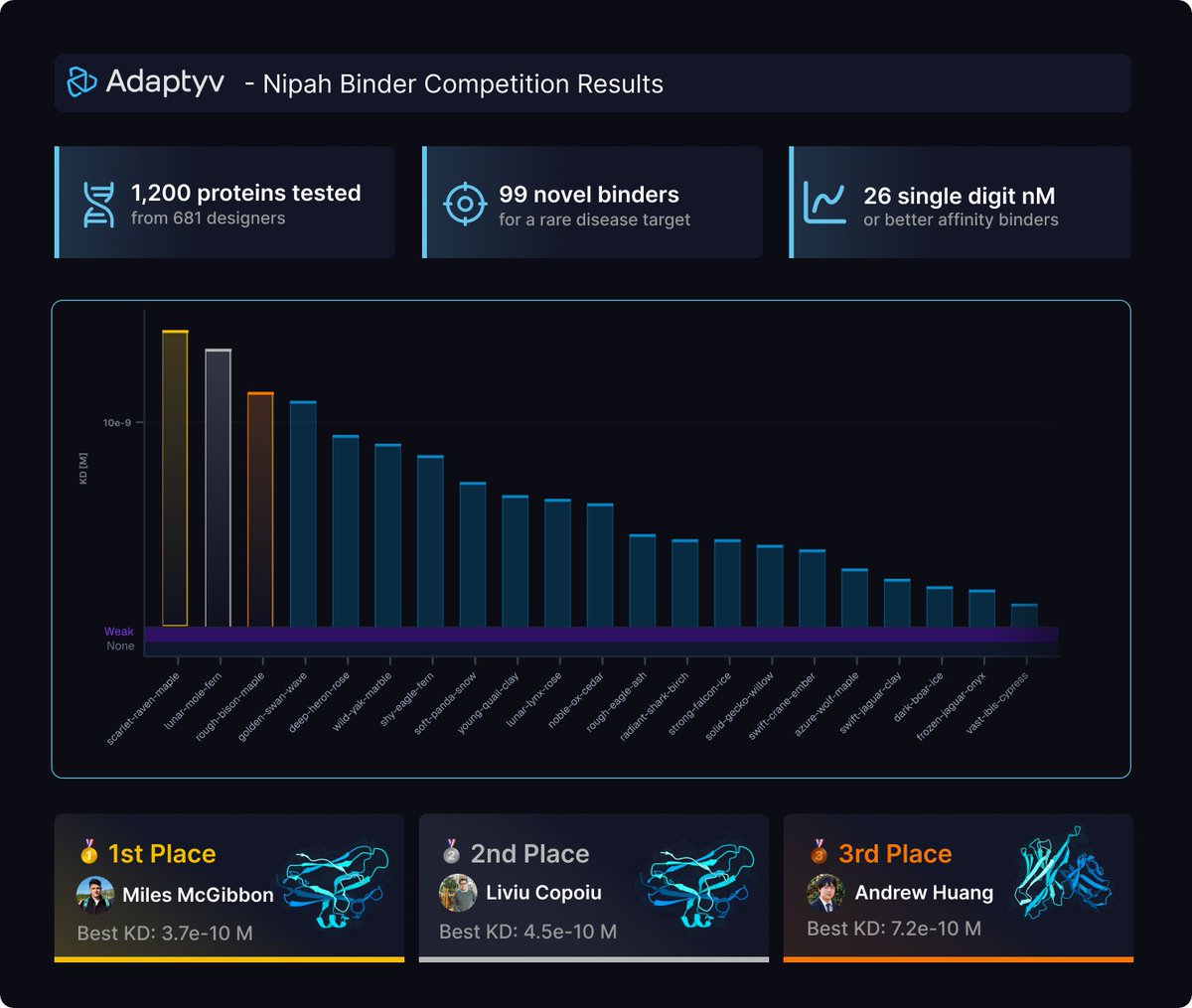
The results of the Nipah Protein Design Competition are out!
🧬 1200 proteins experimentally validated (3x more than last year)
📈 99 novel binders against the target protein (a challenging tetramer with little prior work)
💪 26 single digit nM or better binders, with the best ones at single-digit picomolar affinity!
All data now available open-source on Proteinbase!
Let's take a look at the results ⬇️
18
74
780
171,435

“The Zoomers are so much better than the Millennials”
@pmarca on the AI-native Zoomers who learned tech from YouTube and have a burning desire to build something great:
“2015 to 2024... was a very, very strange period. And a lot of just things got really weird.
And the Zoomers are the generation that basically was on the receiving end of that.”
“And they're not walking around feeling guilty about everything all the time. They're not feeling like they have to deny that they want to be successful.”
“They've seen a thousand hours of YouTube videos from all the great people in tech talking about how to do everything. They just know so much more than previous generations of founders did.”
“They're all AI native. They all basically learn AI from scratch and in college. They're coming out, and they totally understand it.”
“They wear their heart on their sleeve. They're gonna build something great. And they're completely unapologetic about it.”

In Packy McCormick's recent deep dive on a16z, he writes, “What a16z aims to do is provide legitimacy and power [for startups]”.
a16z cofounders Marc Andreessen and Ben Horowitz have been building the venture firm to provide entrepreneurs with legitimacy and power for almost two decades.
In this conversation, they join Packy and a16z GP Erik Torenberg to cover how they did it and the worldview behind a16z, including:
- How a16z compounds reputation
- How the media ecosystem has changed since a16z began & how a16z has adapted
- How a16z is structured to put entrepreneurs first and enable them to win
- a16z's culture document and how written culture shapes people's actions
- How to size markets that will grow exponentially because of technology
- Why there are so many great Zoomer founders
and much more.
0:00 Introduction
00:46 How the media ecosystem is changing
4:20 Substack
6:28 Supply-driven markets and new content creation
10:09 Databricks
13:58 Demand for great content
18:49 Market sizing
22:37 Turning inventors into confident CEOs
27:29 Building dreams
30:46 Compounding reputation
40:39 a16z team structure
46:01 Why intangibles matter more than ever
48:17 Original thinkers with charisma
50:06 Zoomers
@pmarca @bhorowitz @packyM @eriktorenberg
Not an offer or solicitation. None of the information herein should be taken as investment advice; Some of the companies mentioned are portfolio companies of a16z. Please see a16z.com/disclosures/ for more information. A list of investments made by a16z is available at a16z.com/portfolio.
36
43
604
132,870

Everyone’s hyped about “AI for Science.” in 2025! At the end of the year, please allow me to share my unease and optimism, specifically about AI & biology.
After spending another year deep in biological foundation models, healthcare AI, and drug discovery, here are 3 lessons I learned in 2025.
1. Biology is not “just another modality.”
The biggest misconception I still see:
“Biology is text images graphs. Just scale transformers.”
No. Biology is causal, hierarchical, stochastic, and incomplete in ways that language and vision are not.
Tokens don’t correspond cleanly to reality.
Labels are sparse, biased, and often wrong.
Ground truth is conditional, context-dependent, and sometimes unknowable.
We’ve made real progress—single-cell, imaging, genomics, EHRs are finally being modeled jointly—but the hard truth is this:
Most biological signals are not supervised problems waiting for better loss functions.
They are intervention-driven problems. They demand perturbations, counterfactuals, and mechanisms, beyond just prediction.
Scaling obviously helps. But without causal structure, scaling mostly gives you sharper correlations.
2025 reinforced my belief that biological foundation models must be built around perturbation, uncertainty, and actionability, not just representation learning.
2. Benchmarks are holding biology back more than compute is.
Let’s be honest: Benchmarking in AI & biology is still broken.
Everyone reports SOTA. Everyone picks a different dataset slice.
Everyone tunes for a different metric. Everyone avoids prospective validation.
We’ve imported the worst habits of ML benchmarking into a domain where stakes are much higher. In biology and healthcare, a 1% gain that doesn’t transfer is worse than useless—it’s misleading.
What’s missing isn’t more benchmarks. It’s hard benchmarks:
•Prospective, not retrospective
•Perturbation-based, not static
•Multi-site, not single-lab
•Failure-aware, not leaderboard-optimized
If your model only works on the dataset that created it, it’s not a foundation model—it’s a dataset artifact.
In 2026, we need fewer flashy plots and more humility, rigor, and negative results.
3. “Reasoning” in biology is not chain-of-thought.
There’s a growing tendency to directly apply the word reasoning onto biological LLMs.
Let’s be careful.
Biological reasoning isn’t verbal fluency, longer context windows, or prettier explanations. Those are surface-level improvements. Real reasoning in biology shows up elsewhere: in forming hypotheses, deciding which experiments to run, updating beliefs when perturbations fail, and constantly trading off cost, risk, and uncertainty.
A model that explains a pathway beautifully but can’t decide which experiment to run next is not reasoning, it’s narrating.
2025 convinced me that the future lies in agentic biological AI:
systems that couple foundation models with experimentation, simulation, and decision-making loops.
Closing thought:
AI & biology is not lagging behind AI for code or language. It’s just playing a harder game.
The constraints are real. The data is messy. The feedback loops are slow. The consequences matter.
If 2025 clarified anything for me, it’s this:
We won’t make progress by treating biology like text. We’ll make progress by building AI that behaves more like a scientist : skeptical, iterative, and willing to be wrong.
Onward to 2026.

55
166
743
67,544
Finn retweeted
22 Dec 2025
Excited to announce the release of our open-source protein family language model, ProFam-1, designed to generate functional protein variants and predict fitness using in-context example sequences. 1/n
6
47
245
15,112
Finn retweeted

27 Nov 2025
Introducing INTELLECT-3: Scaling RL to a 100B MoE model on our end-to-end stack
Achieving state-of-the-art performance for its size across math, code and reasoning
Built using the same tools we put in your hands, from environments & evals, RL frameworks, sandboxes & more
137
322
2,273
1,136,253
Finn retweeted

26 Nov 2025
Do you notice how every few weeks someone announces that Al has finally "solved" biology?
Protein structure, drug discovery, gene regulation, evolution-pick a domain, and there's an arxiv/biorxiv preprint declaring victory. Yet when you dig one layer deeper, the real story is always the same: a clever model, a tidy benchmark, and huge biological claims, only a few validated.
The trouble is that biology isn't a clean dataset. LLM training sets are mostly stable, rule-governed records: tokens follow grammar, rows follow schemas. Biology gives you none of that. A transcriptome table may look like a CSV, but each entry is a readout of a nonlinear stochastic process running inside a cell. The variance isn't a measurement error, change one environmental variable and the entire joint distribution reorganizes.
But this mess is exactly where new scientific questions come from. Not from Kaggle-style competitions. These anomalies are invisible unless you have enough biological depth to know what should have happened. That's why bioml people are advised to touch a pipette, do some wet lab work to understand what goes into their models. With it, you start noticing the gaps- places where models fail because biology is doing something interesting, not because the architecture is weak. Those gaps are the new questions.
Better models make biological literacy more important, not less.
The next decade belongs to people who can think in both dialects: the abstractions of computation and the constraints of living matter. They're the ones who will recognize that a model's failure isn't noise-it's biology.
6
23
158
9,612

Finn retweeted

26 Oct 2025
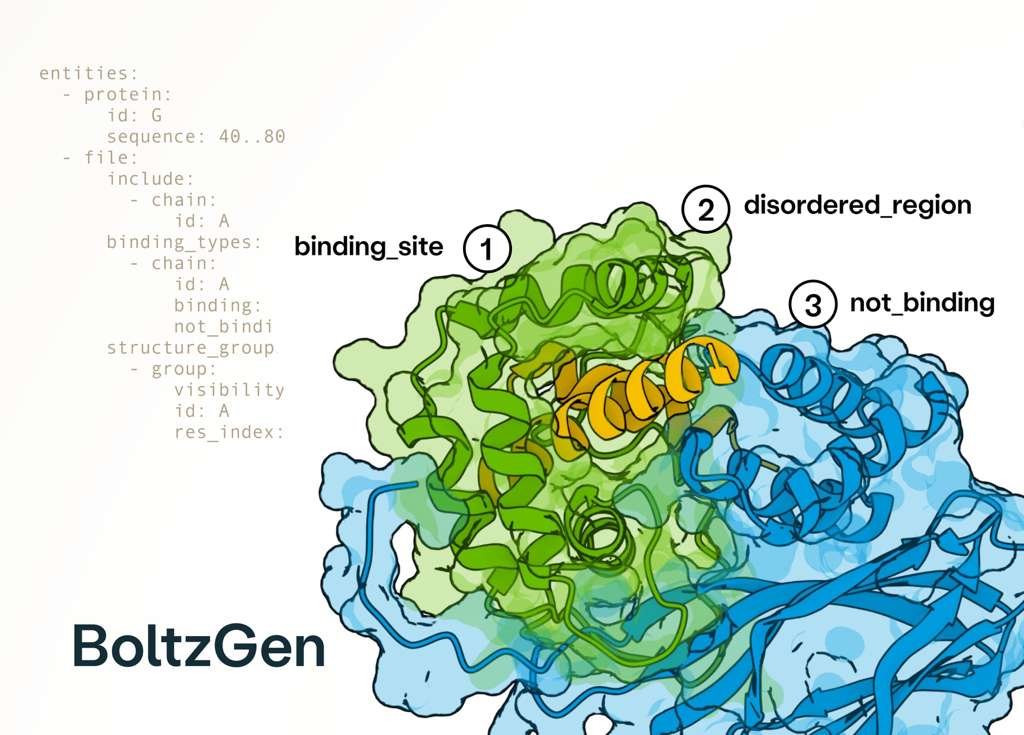
Excited to release BoltzGen which brings SOTA folding performance to binder design! The best part of this project has been collaborating with many leading biologists who tested BoltzGen at an unprecedented scale, showing success on many novel targets and pushing its limits! 🧵..
18
266
994
304,089
Finn retweeted

6 Oct 2025
why buy a sports car or a nice watch when you can buy industrial grade machinery to reindustrialize america

17
6
324
9,409
Finn retweeted

29 Sep 2025
Fell a bit through the cracks with the Boltz releases, but proud of this work! We show that when using ESM embeddings, the rest of the architecture can be simplified, offering 10x speedup. We also built a couple of triton kernels. Check it out at github.com/jwohlwend/minifol…
28 Sep 2025

There is lots of chat these days about simple/fast folding models. Few people know that more than a year ago, @jeremyWohlwend and @meteos_97 built MiniFold, a super fast folding method that actually approaches ESMFold accuracy while being >10x faster. Unfortunately, they never did any PR, so they never got enough credit for it. Go check it out: github.com/jwohlwend/minifol…

1
19
94
15,993
Finn retweeted

16 Sep 2025
Bet on (bio)tech
16 Sep 2025

It's crazy that we might have one-shotted obesity and auto fatalities in one decade.
2
4
70
5,981