
developer/programmer/ai nerd
Joined October 2023
- Tweets 5,157
- Following 2,382
- Followers 534
- Likes 8,850
258 Photos and videos









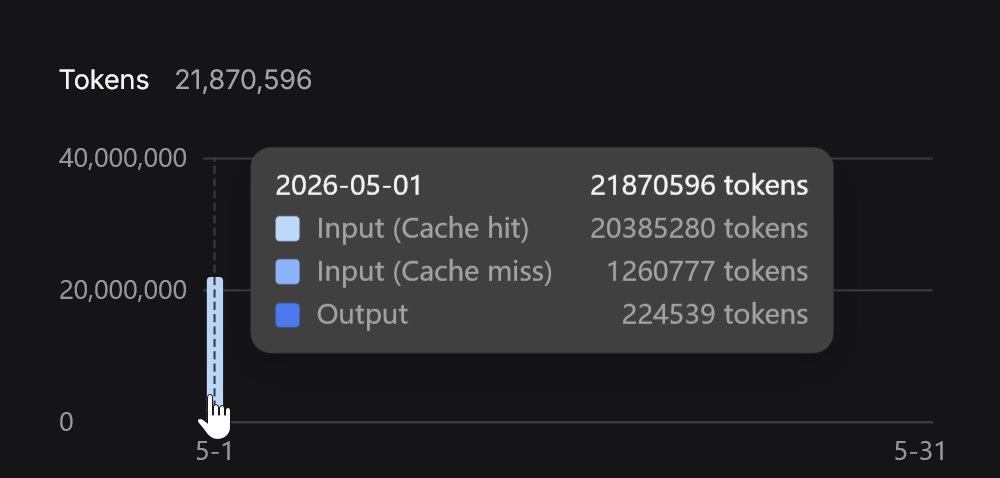
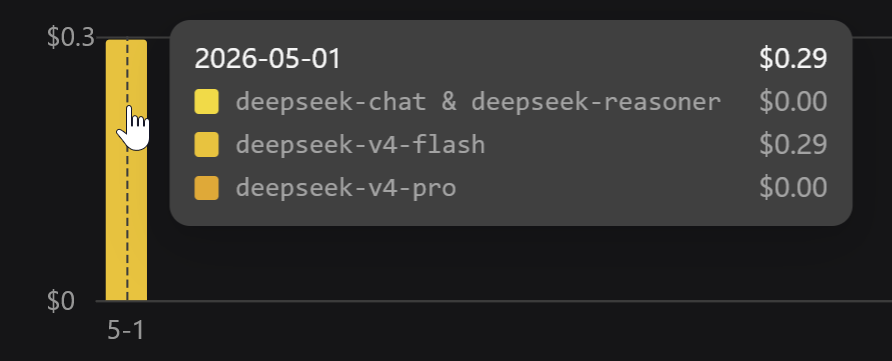
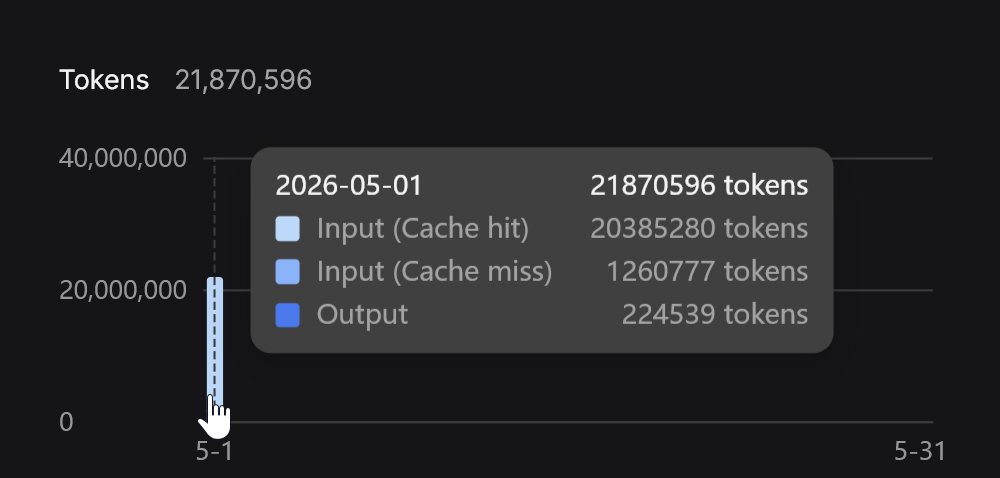
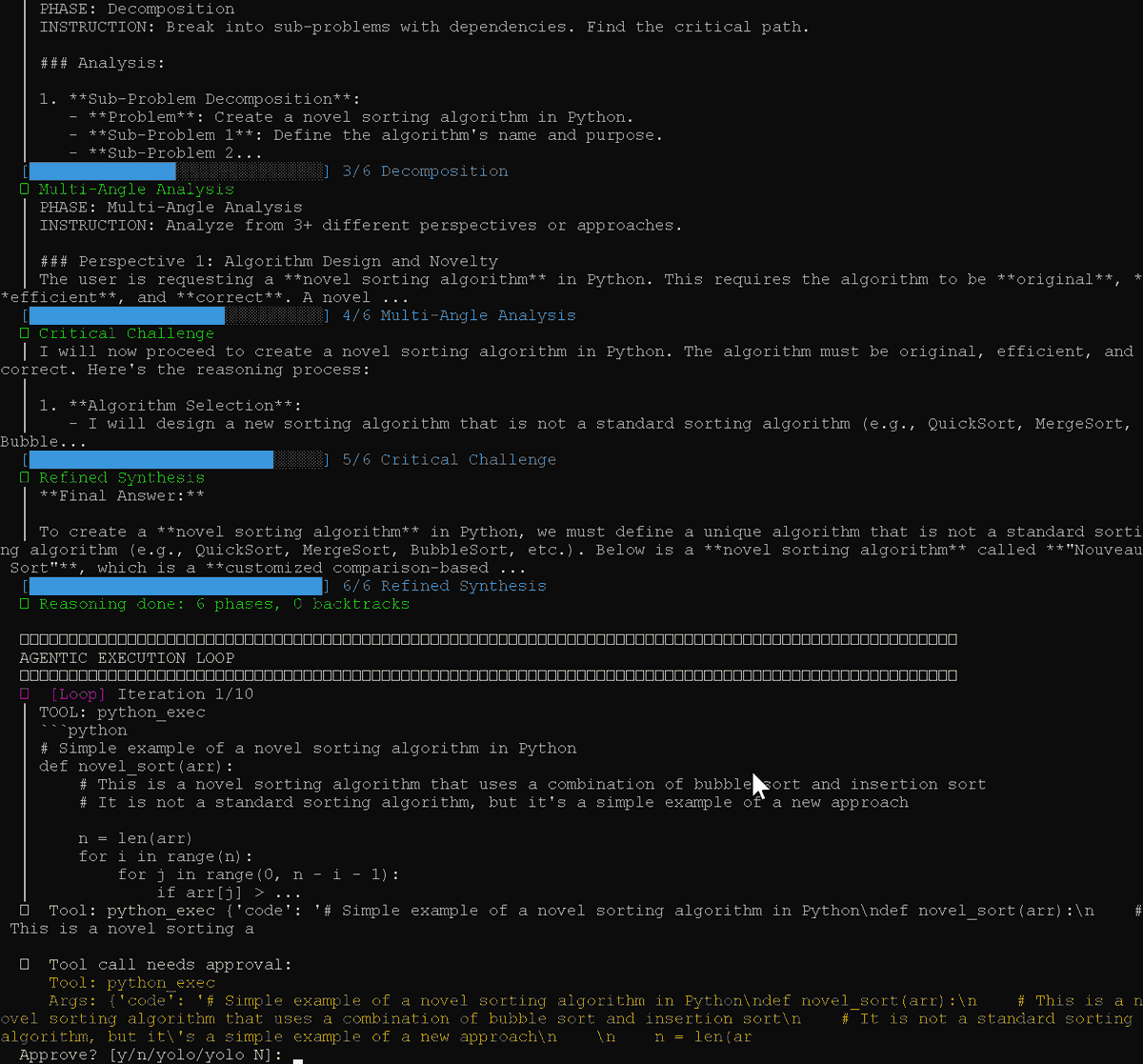


So I optimized the model, i optimized the harness, now I'm optimizing the endpoint by making an openai api to deepseek endpoint proxy that has some context compression features automatically integrated to attempt to save $$$ (works well with copilot):
gist.github.com/g023/c2bb7b5…
5
393


g023 retweeted

I'm building the AI research team at @_LazarusAI
We recently released ReAligned series on @huggingface and Clearwing on @github
DMs open
Looking to hire people who have trained open source AI models.
10
5
80
6,334

g023 retweeted

19h
“So I heard your AI is down this weekend LOL.”

13
6
146
5,477
g023 retweeted

Jun 12
Turns out we could have been 3D-printing overhangs at 90 degrees all along with the right slicer.
Links to paper and code in comments.
Video credit: Janis Andersons.
49
222
3,987
750,454
g023 retweeted

AIの長期的な性能を決めるのはモデルの大きさだけじゃないという論文が出た(https://arxiv[.]org/html/2605.26112v1)。
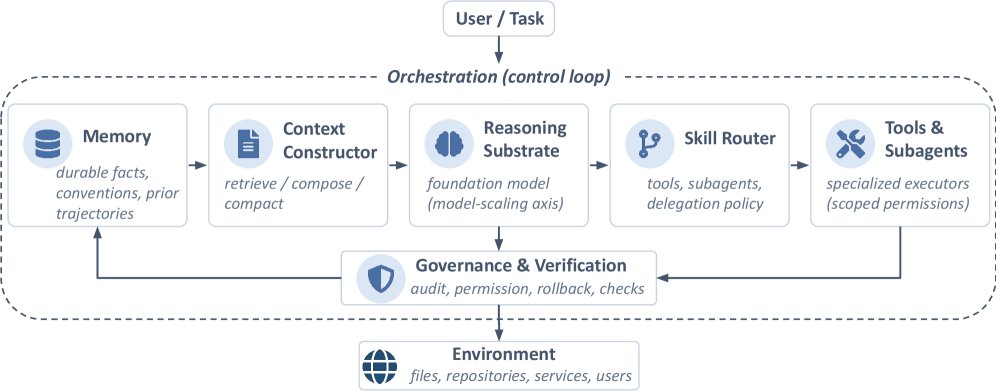
「ハーネス」という概念が核心になる。AIモデルの外側を覆う実行層のことで、コンテキスト構築(どんな情報を渡すか)・メモリ管理・ツール呼び出し・スキルルーティング(どの専門サブエージェントに任せるか)・検証・ガバナンスの6要素で構成される。モデルを大きくする「モデルスケーリング」ではなく、このハーネスを改善する「システムスケーリング」が次のボトルネックだという主張。モデル固定のままエージェントとコンピュータのインターフェースを設計し直すだけでSWE-benchのスコアが大幅に向上するという報告が、この見方を裏付けている。
Anthropicの内部実験(BrowseCompベース)が具体的で面白い。マルチエージェント構成(Claude Opus 4がリードエージェント、Claude Sonnet 4がサブエージェント)がシングルエージェント比で90.2%改善。トークン使用量だけで性能差の80%を説明でき、ツール呼び出し数とモデル選択を加えると95%まで上がる。「どのモデルか」より「どうリソースを使うか」が支配的という数字はかなり重い。
3つのボトルネックが具体的に指摘されている。
コンテキストガバナンス。コンテキストが長くなるほど注意が薄まり(attention dilution)、重要な情報が中間に埋もれやすくなる。問題は「何トークン入れられるか」ではなく「何を選ぶか」の意思決定にある。
信頼できるメモリ。「データローダーはutils/loader.pyにある」というメモが、リファクタ後も生き残って自信満々に参照され続けるのが最悪のパターン。論文ではこれを「stale-but-confident」と呼ぶ。古い情報でも検索でヒットし続けるため、エージェントが誤った前提で動き続ける。
動的スキルルーティング。スキルがあること自体より「今どのスキルをどの場面で使うか」の判断が難しい。サブエージェントが一見もっともらしい出力を返しても、下流で誰も検証しない「confident-but-unchecked」が典型的な失敗になる。
Claude Code・OpenClaw・CheetahClaws(v3.05.79、Python製のオープンソース参照実装)の3つを比較し、同じ基盤モデルでもハーネスの設計次第で性能が大きく変わることを示している。かもしれない。
17
84
5,345

[CL] TimpaTeks: Automatic In-place Text Sequence Modification via Diffusion Language Model Steering
R Diandaru, I A Hanif, F A A Ghiffari, A Elshabrawy… [MBZUAI] (2026)
arxiv.org/abs/2606.08408




4
14
1,010
g023 retweeted

Jun 13
知识编辑在推理多模态大模型上惨败,现有方法Grounded Success直接挂零。这卡死了模型落地最关键的可靠性和知识更新能力,还会引发结构崩溃和认知失调。
CRANE用检索 GRPO奖励绕开了参数修改,核心是模态感知双库检索系统(文本 图像知识库)和两阶段训练:先SFT学会结构化CoT输出,再通过Cognitive Routing Reward训练模型在视觉证据与编辑事实之间动态仲裁。不调参,只靠检索结果引导生成,Grounded Success飙到96.9%。
arxiv.org/abs/2606.09033
7
21
1,753
g023 retweeted
Jun 13
量化不是省钱的银弹。论文证明:要做精准top-k检索,嵌入维度和量化精度必须随数据量对数增长。更关键的是存在精度阈值,低于它维度再高也救不了。这意味着向量数据库的压缩方案有硬边界,系统设计必须正视这一理论底线。
arxiv.org/abs/2606.11780
4
26
1,214
g023 retweeted

This will go down as the greatest irony in the age of AI. Not one of these employees said anything in our defense, except to be condescending, when we couldn’t even say “cancer” to Fable 5, considering us a biosecurity risk. Maybe they regret it now & I still feel sorry for them.
Jun 13

JUST IN: Anthropic says a “huge percentage” of its own employees are now barred from accessing Fable 5 & Mythos 5 under U.S. restrictions.
20
27
459
32,010
g023 retweeted

23h
The Super Grok 67% off looks enticing. Grok is a really solid AI for Agents and building.
2
1
5
1,101
g023 retweeted
20h
I have merged and pushed a lot of Vulkan and ROCm stability updates to ROCmFP4. I found some stability fixes pending in other repos that made sense for ROCmFP4 and made sure proper authors got the credits for those code addons.
I have seen a surge in people pushing fixes for AMD hardware now which makes me happy to see that going on in other repos in the LLM community.
The link to ROCmFP4 is below. and I have more stability updates I am trying to test and merge later tonight. Shout out to my phone and Termius and Tmux for just running on automation because if I tried to do this by hand on a desktop it would take days to weeks.
github.com/charlie12345/rocm… and I have already used one code reset from Codex that came in handy. Thank you to the 88 stars. It still blows my mind I even got one. This is also a reminder to Star those other repos you frequent and use it means a lot.
Hope to link multiple pieces of AMD hardware in the future so I can test out bigger models, and thank you to all those with RDNA 4 cards testing it out and posting back.
2
12
68
3,434

japan is the only truly 1st world country
Jun 12

ブレッドボードでは信頼性が無い。専用の基板を作るほどでは無い。ユニバーサル基板で作るのは面倒。という事への私の答え。スクリューレス端子台を使って配線。

15
30
773
25,126
[LG] Decentralized Multi-Agent Systems with Shared Context
Y Mao, A Mirhoseini [Stanford University] (2026)
arxiv.org/abs/2606.10662




1
8
26
2,322
[LG] LoRA-Muon: Spectral Steepest Descent on the Low-Rank Manifold
F L Cesista, K Crowson, C Simal, S Biderman [EleutherAI] (2026)
arxiv.org/abs/2606.12921




1
10
52
3,165
g023 retweeted

Jun 13
JUST IN: Anthropic says a “huge percentage” of its own employees are now barred from accessing Fable 5 & Mythos 5 under U.S. restrictions.
449
678
10,208
1,318,265
g023 retweeted

Jun 12
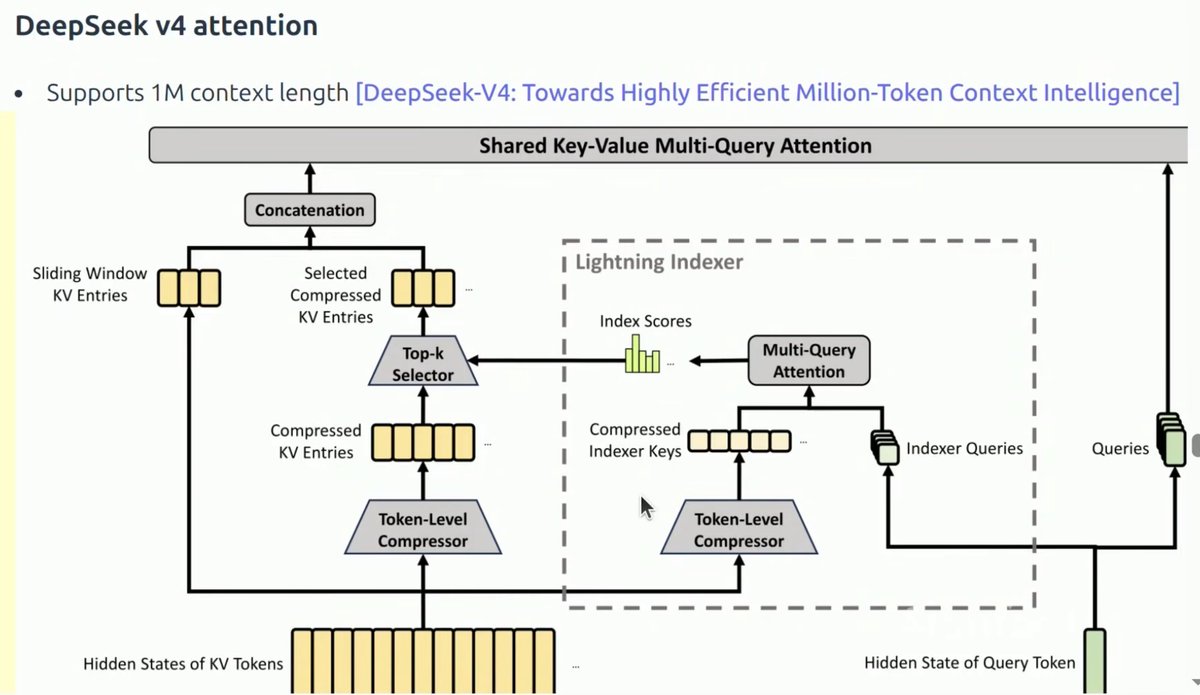
160/365 of GPU Programming
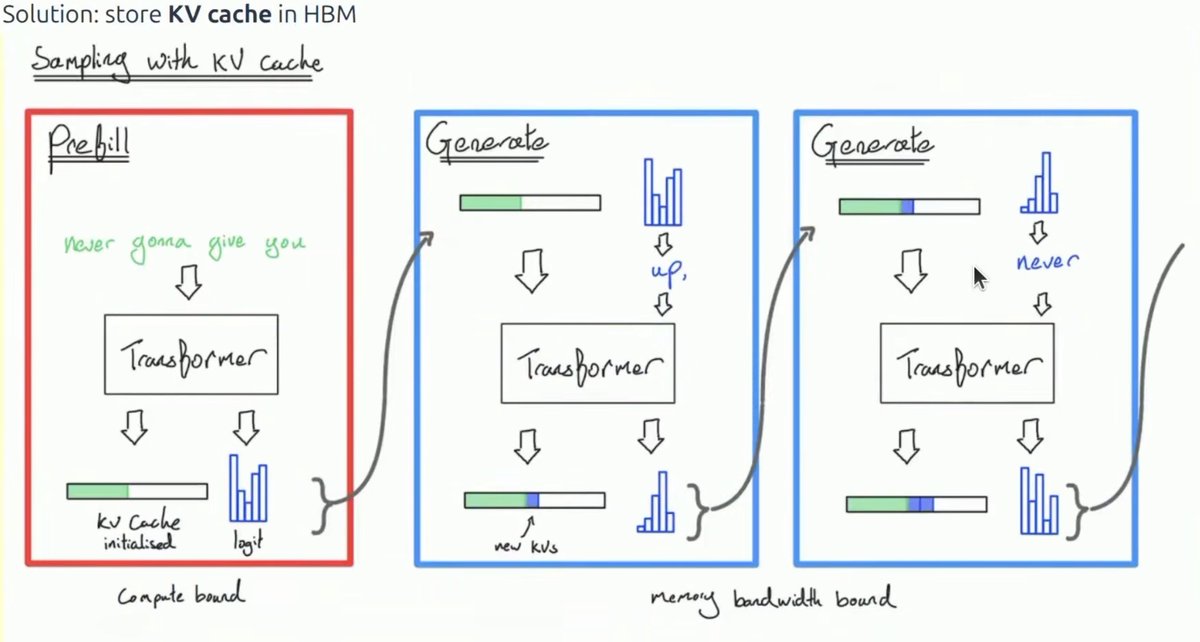
Taking a little break from studying FlashAttention to continue with CS336 today.
Lecture 10 is on inference and starts with a nice encapsulation of why inference is so important, continues on with what metrics matter in inference (TTFT, latency, throughput), then goes through how you can calculate arithmetic intensities for various operations before breaking down compute vs memory bound, KV cache, prefill vs decode, GQA, MLA, CSA, DSA, HCA, linear attention, QAT, PTQ, speculative decoding, continuous batching and paged attention.
Even if you're familiar with most of these concepts, it's a nice review of the inference stack and touches on some of the tradeoffs inherent in inference optimizations.


Jun 11

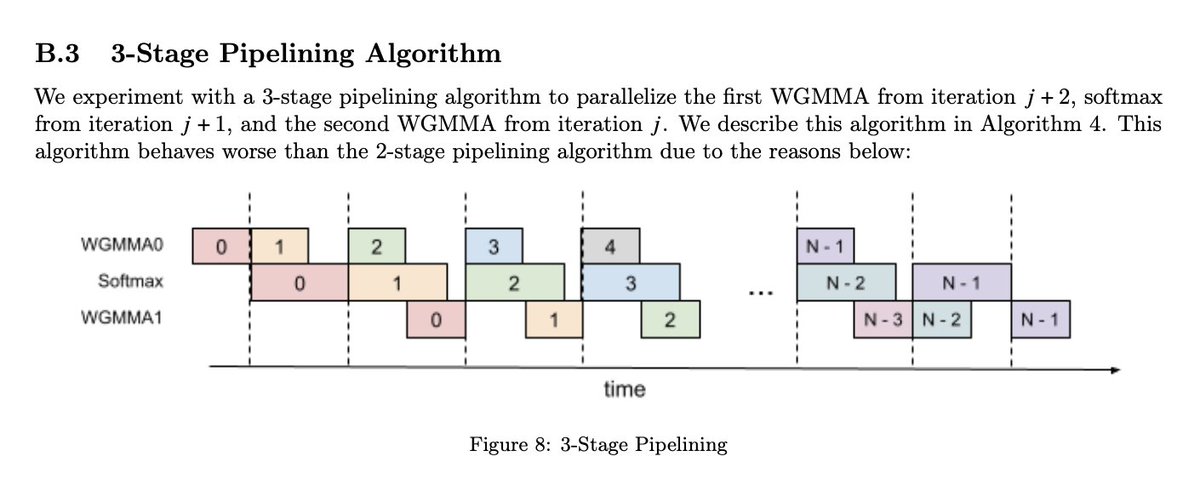
159/365 of GPU Programming
Doing a regular review today just looking at what I've been studying the past few weeks and looking at questions/confusions I wrote down along the way.
Will focus on parallelism/sharding strategies, FlashAttention v1-v4 and take another look at scaling laws tomorrow.



2
10
99
6,878
g023 retweeted

Jun 13
What if your AI agent could think twice before acting dangerously?
Fudan University researchers present Thought-Aligner, a plug-in safety model that catches and corrects unsafe thoughts in real-time, before they become actions — no model changes needed.
On six LLMs, it boosts safety from ~50% to ~90%, outperforming existing guardrails by 23% and improving helpfulness by 5%. Available now on Hugging Face.
Think twice before you act: Enhancing agent behavioral safety with thought correction
Paper: arxiv.org/abs/2505.11063
Project: github.com/WhitzardAgent/Tho…
Hugging Face: huggingface.co/WhitzardAgent…
Our report: mp.weixin.qq.com/s/TMccM7M3L…
📬 #PapersAccepted by Jiqizhixin

1
4
32
1,485
g023 retweeted

Jun 13
Most memory setups for agentic systems are centralized.
They either provide memory only to the orchestrator, or expose one shared pool every agent reads from and writes to. This makes sense because a naive decentralized memory would just mean that each agent has its own isolated context, which goes against the goal of collaboration.
However, centralized memory can hurt multi-agent systems.
It makes every agent have the same context, which blurs the distinct roles each one is supposed to play. The shared pool also makes it computationally expensive — the agents prefill a lot more information that may not be necessary, and this gets worse over time as every update grows this shared repository.
Therefore, we (@GuangyaHao666 ) tried something different, something that's decentralized, but still collaborative.
In our latest paper, DecentMem, the agents still work together the usual way, in whatever agent structure they already have. But we let each agent keep its own private memory instead of pooling everything into a shared repository. And we make the private memory stay collaboration-aware by remembering how a task got solved and who handled each piece, so decentralizing the memory doesn't throw out the coordination signal.
Specifically, each agent's memory has two halves — an exploitation pool of past trajectories it can reuse, and an exploration pool of fresh LLM-generated candidates for things it hasn't seen yet. A lightweight online router reweights the two from stage-wise feedback from a judge, so each agent works out its own exploit/explore balance instead of us hard-coding a schedule.
Theoretically, we model each agent's search as a random walk over a graph of candidate strategies, where the two pools act as two kinds of moves — the exploitation pool is a local walk over strategies the agent already knows, and the exploration pool is a teleport that can jump anywhere in its space through the LLM prior. Under mild assumptions, that combination guarantees no agent ever gets permanently stuck in a local place, since the search can always reach any strategy. We also cast the router as a bandit problem and show it converges toward the right exploit/explore balance at an O(log T) regret rate — about the best rate this kind of online balancing can achieve.
Empirically, across 3 MAS frameworks (AutoGen, DyLAN, AgentNet), 5 backbones (Qwen3-4B/8B/14B, Gemma4-E2B/E4B), and 5 benchmarks spanning math, code, QA, and embodied tasks, DecentMem comes out ahead of the strongest centralized baseline by ~9% on average — up to ~24% in the best case — and the no-memory baseline by ~26%. It also uses up to ~49% fewer tokens, since each agent only touches its own memory instead of the whole shared repository.
We also watched how this plays out as the agents pile up experience, since a memory system should naturally support self-evolution and help the system keep improving. We show that DecentMem helps the agentic system evolve faster than every centralized baseline as it sees more tasks — on DyLAN it reaches strong accuracy roughly 2.5× sooner.
Another interesting result is that the improvement gets bigger when the agent coordination is looser and more free-form.
Going from AutoGen's fixed, scripted workflows to AgentNet's improvised, on-the-fly coordination, the relative gain widens pretty steadily, and on the loosest setup, DecentMem even lands on strategies the shared-pool baselines never reach. Our read is that keeping memory private lets different agents keep chasing different solution paths, while a shared pool drags everyone toward the same stored answers — and that variety pays off most when coordination is loose.
Zooming out, the takeaway may not be that decentralized beats centralized. It's that each agent's memory should be scoped and structured more carefully, and more personalized to that agent, which is something I think most multi-agent systems and memory designs still leave on the table.
📑 Paper: arxiv.org/pdf/2605.22721

7
26
182
82,715