
optimization enthusiast @trymirai . || Fast vs Slow Thinking
Joined January 2018
- Tweets 311
- Following 551
- Followers 210
- Likes 352
23 Photos and videos






Pinned Tweet

Jun 8
Really proud of this release from the team :)
We just shipped our first quantized Qwen3.5 checkpoints, the quantization format was co-designed with our inference engine from scratch instead of trying to make an off the shelf format fast. Our 8-bit models decode faster than llama.cpp 4-bit on Apple silicon, and they're virtually identical to the original!
2
2
15
438
ryan mathieu retweeted

Jun 10
When we invested in Mirai Labs (@trymirai) earlier this year, they had a long-ish term plan to offer full-stack on-device inference infrastructure and the underlying models. I thought it would take them a year...
In less than four months, their co-designed quant inference stack for Apple Silicon shows 40–60% more tokens/sec vs llama.cpp and MLX at the same quality level.
This week they published technical posts on quantization (trymirai.com/blog/quantizati…) and sparse buffers (trymirai.com/blog/sparse-buf…) which I encourage app builders and inference consumers to read.
Awesome stuff from @Darkolorin, @dmitrshvets, and the Mirai team.
2
3
15
1,572
ryan mathieu retweeted
Jun 8
Really proud of this release from the team :)
We just shipped our first quantized Qwen3.5 checkpoints, the quantization format was co-designed with our inference engine from scratch instead of trying to make an off the shelf format fast. Our 8-bit models decode faster than llama.cpp 4-bit on Apple silicon, and they're virtually identical to the original!
2
2
15
438
Jun 8
Really proud of this release from the team :)
We just shipped our first quantized Qwen3.5 checkpoints, the quantization format was co-designed with our inference engine from scratch instead of trying to make an off the shelf format fast. Our 8-bit models decode faster than llama.cpp 4-bit on Apple silicon, and they're virtually identical to the original!
2
2
15
438
Jun 8
1.8x the throughput. 14% less memory
There were moments where we tried fancier quantization formats that win on paper vector quantizers with better rate-distortion curves. They lose to plain INT4 on real hardware because GPU shared memory bank conflicts kill them...
1
2
42
Jun 8
Very excited for this release and with Gemma following pursuit ... our ultimate goal is to take the model perf even further while unlocking 1000 tps on local apple silicon. Many more experiments and drops to come so stay tuned and check out our models and blog: trymirai.com/blog/quantizati…
2
43
Jun 8
Really proud of this release from the team :)
We just shipped our first quantized Qwen3.5 checkpoints, the quantization format was co-designed with our inference engine from scratch instead of trying to make an off the shelf format fast. Our 8-bit models decode faster than llama.cpp 4-bit on Apple silicon, and they're virtually identical to the original!
1
2
128
Jun 8
Spent the last couple months with the team running an unreasonable number of quantization experiments to get these checkpoints where they are and I'm really happy with where they landed with lots more to come on all fronts of the pareto ... go check out our blog models for yourself!
Jun 8

We are releasing our first quantized checkpoints for the Qwen3.5 series of models, co-designed jointly with our inference engine to achieve maximum possible performance on Apple hardware
Starting from 0.8B, 2B and 4B models
trymirai.com/blog/quantizati…
5
196
ryan mathieu retweeted

Jun 8
We are releasing our first quantized checkpoints for the Qwen3.5 series of models, co-designed jointly with our inference engine to achieve maximum possible performance on Apple hardware
Starting from 0.8B, 2B and 4B models
trymirai.com/blog/quantizati…
15
53
433
66,854
ryan mathieu retweeted

Jun 5
we're going to make local models hit 1,000 tokens per second without meaningful quality loss.
harder than it sounds.
on-device inference is memory-bound: no batching, one sequence at a time, memory bandwidth as the ceiling.
most local models today are either under-optimized for the hardware or compressed until quality declines.
solving both is what most of the industry has avoided or postponed (do I need to explain why?)
speed matters because the next interface is a continuous loop: parsing, tool calls, reasoning, rendering, each step with a latency budget.
below 1,000 t/s, fully local agents aren't viable on consumer hardware, the experience doesn’t feel interactive.
btw, next week we're (@trymirai) releasing one piece of that puzzle.
2
5
283
ryan mathieu retweeted

Apr 30
Please check out Gradus, a micro-learning app! Gradus turns PhD-level information into digestible content. It imposes a structure on LLM outputs, yielding friendly curriculum, and democratizing eduction in the same way ChatGPT has. Check it out below! @sama
Please notice me 😭
gradus.raulv.dev
3
4
24
1,189

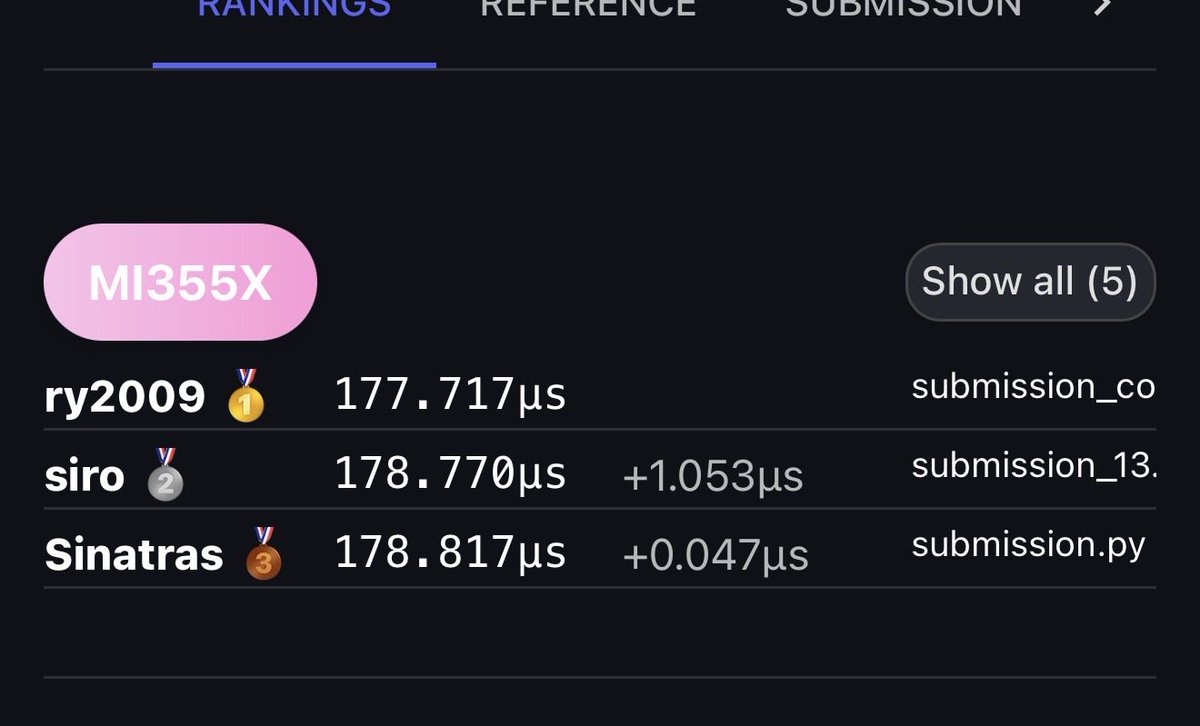
Llama.cpp is a very weak baseline. LMStudio I assume is mlx? It's better but I get 220 tok/s on Qwen3.5-0.8B-MLX-8bit with github.com/trymirai/uzu on m1 max. The branch and command from that pr gets 145 on the same machine but the output is garbage
3
3
15
3,097
ryan mathieu retweeted

7 Mar 2025
why the fuck does every optimization researcher on X have a cat/dog in their profile picture?
7 Mar 2025

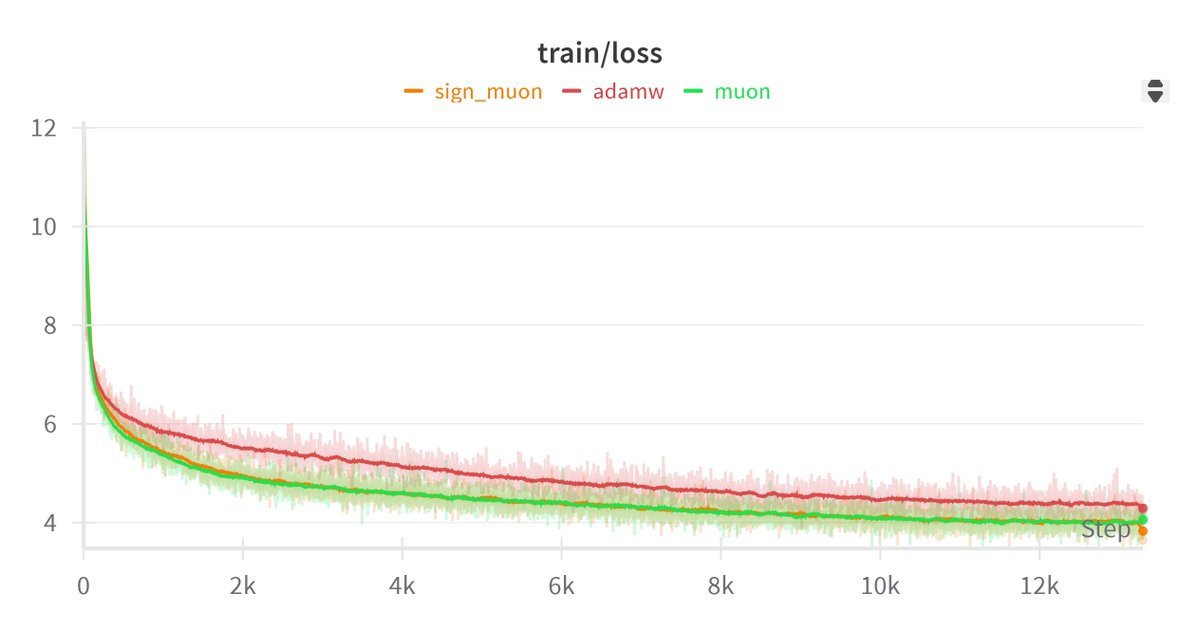
maybe double whitening is all you need? 😃
@YouJiacheng @JingyuanLiu123 @kellerjordan0
If you have native binary all gather, your training will go blrrrr 🚀🚀🚀
wandb 📈: api.wandb.ai/links/kl2/kzo4g…
code ✍️: github.com/kyleliang919/Supe…

12
1
59
10,075
ryan mathieu retweeted

Apr 19
1/ Recently I've been obsessed with the idea of splitting the matmul computation on separate hardware units due to the tiling nature of the operation. My idea was simple: we have GPU, MXU, ANE, NEON, why are we utilizing only the first one?
1
2
14
2,819
ryan mathieu retweeted

Mar 31
Day 0 on-device support of the latest and the smallest @liquidai model
LFM 2.5 350M is now available on @trymirai

Day 0 support across the stack:
> Hardware: @AMD, @Intel, @Qualcomm
> On-device: @lmstudio , @Cactuscompute, @RunAnywhereAI , @zeticai_ , @trymirai
> Customization: @distil_labs

2
16
1,339
ryan mathieu retweeted
Mar 31
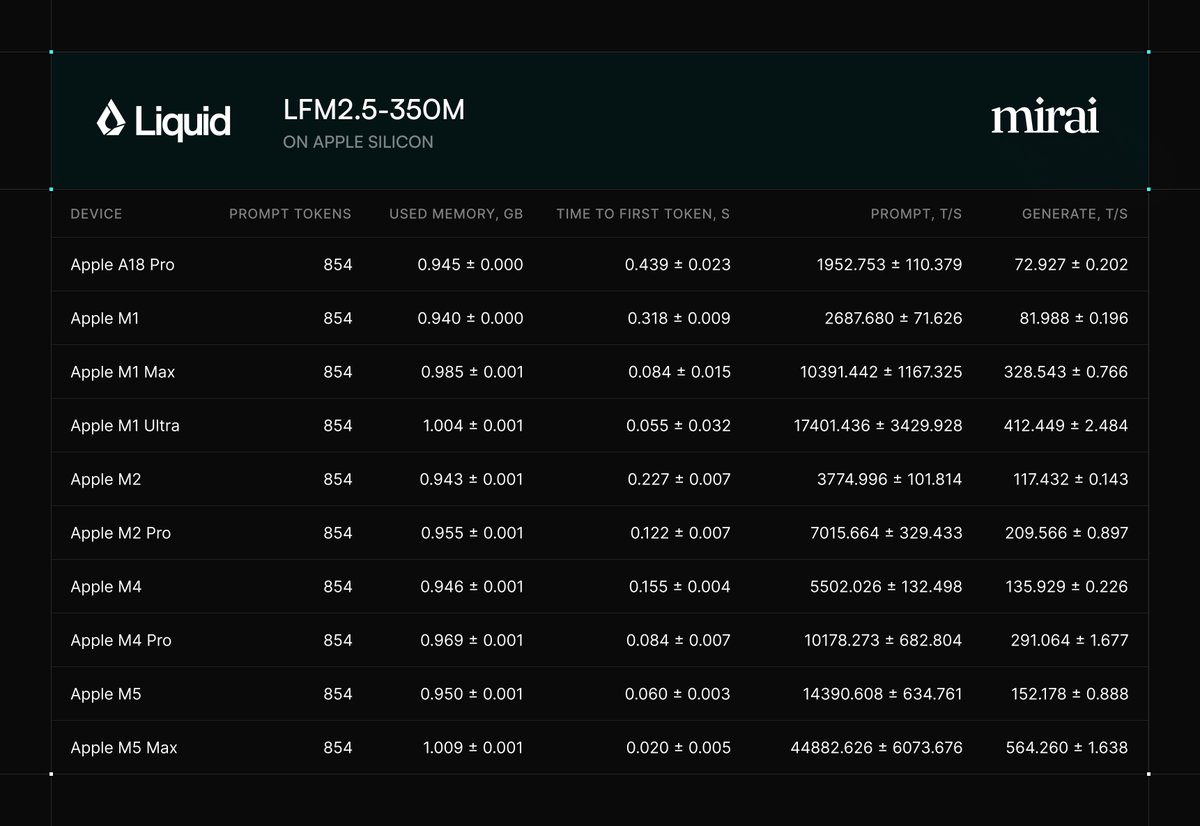
LFM2.5-350M is now available on Mirai.
@liquidai smallest model outperforms Qwen3.5-0.8B on reasoning and agentic tool use.
Running on Mirai in full precision, it exceeds 70 tokens/second on iPhone.
1
5
23
1,891
ryan mathieu retweeted
Mar 30
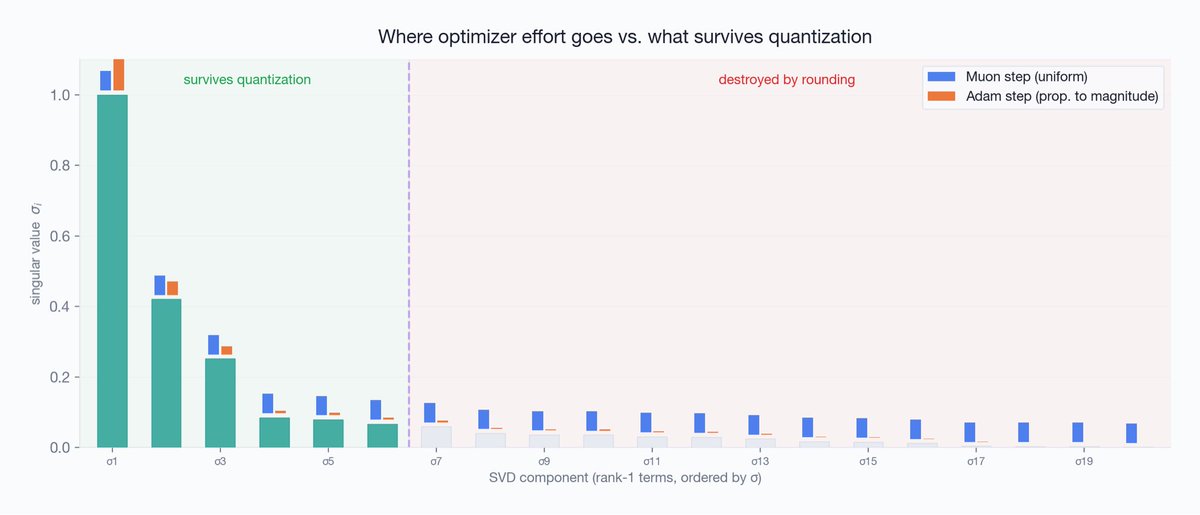
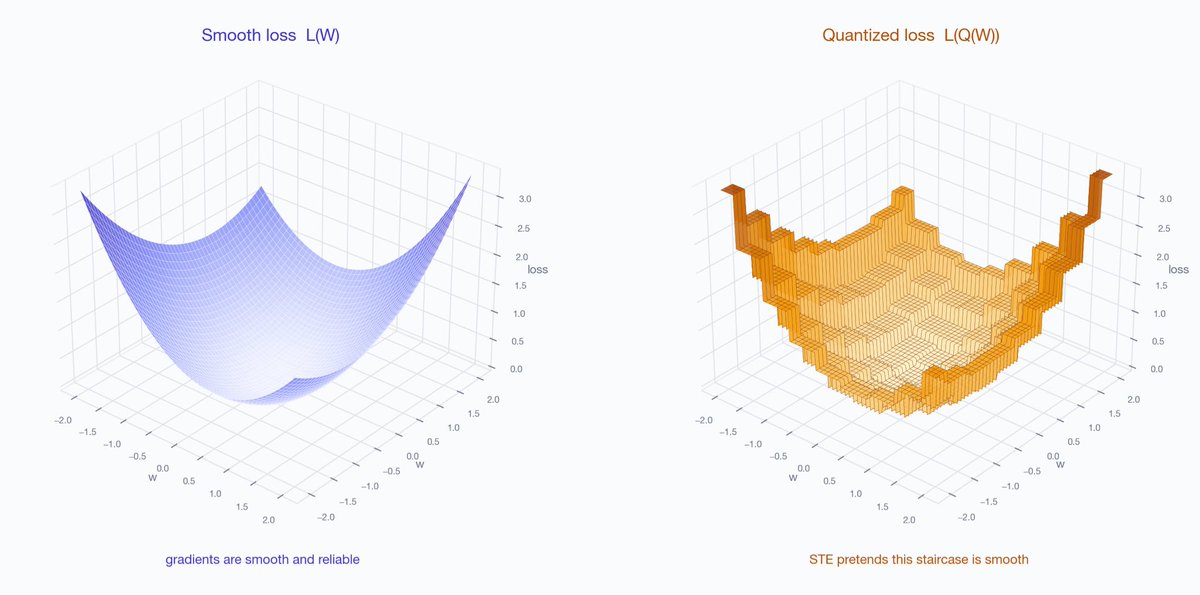
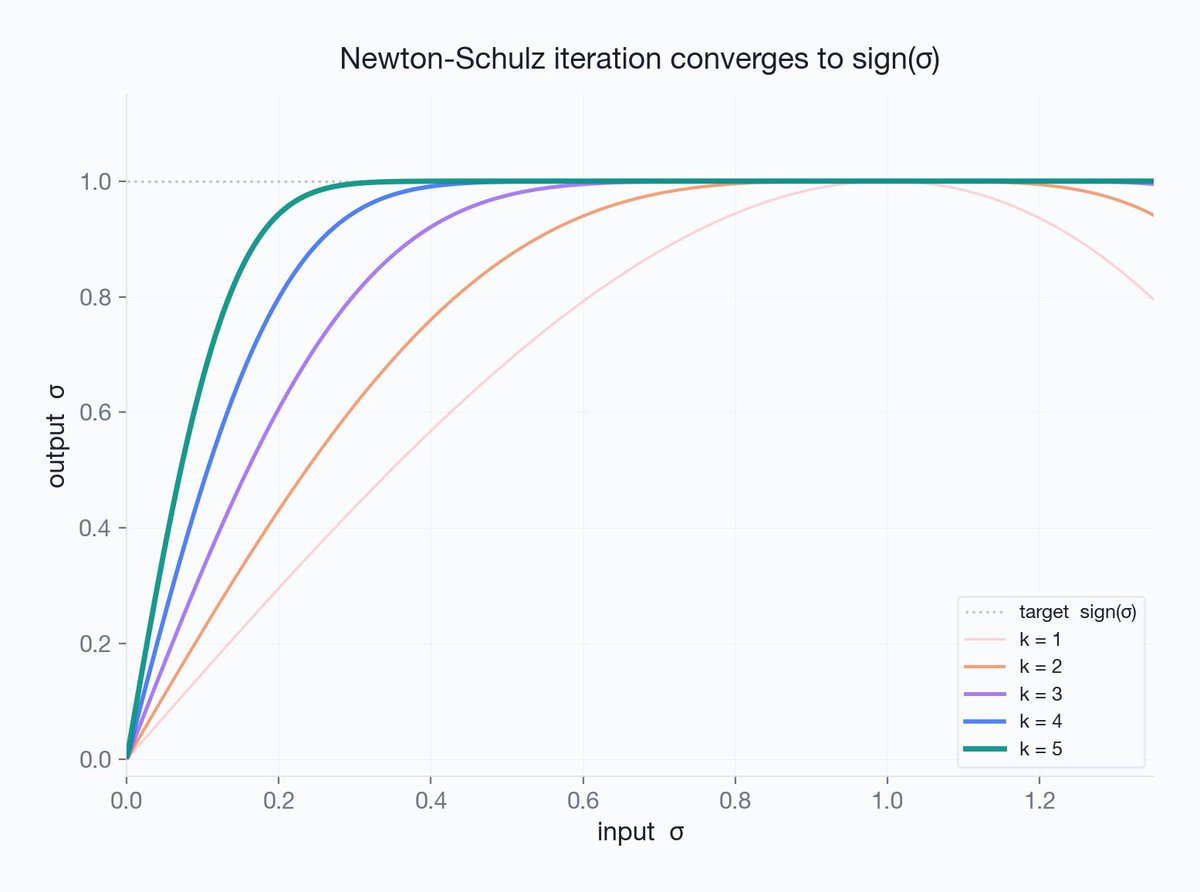
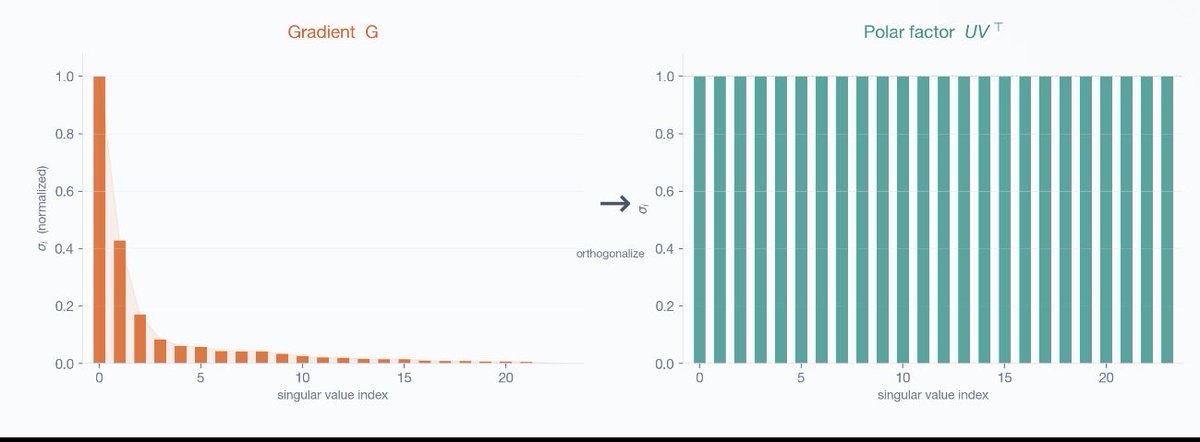
LLM activations have outliers. A few channels spike 100x past the rest, every token. Standard INT8 wastes almost all its precision covering them.
The fix: rotate the weight space so outliers disappear before quantization. It's why QuaRot and TurboQuant work.
Here's how we implemented it:
trymirai.com/blog/why-activa…
2
16
1,064

started a small CUDA-first kernel library repo
idea is basically: steal the parts of cuBLAS/cuDNN’s shape that make sense, keep it small, and see how far I can get without spending much on
compute
repo has the first scaffold up. GEMM first.
github.com/rizerr2131/mini-k…
2
2
14
223
ryan mathieu retweeted

Mar 25
Apple just released its programming guide for Metal Performance Primitives, and they suggest using Morton codes for tiled GEMM, but why?
In computer graphics, you use such space-filling curves all of the time
It makes objects that are close in space to be close in memory
There are several reasons, but one of them is that you get better cache locality, meaning less expensive reads from the device memory
This is exactly why it’s appealing for GEMM too - you have a lot of overlapping memory reads between the tiles
Morton schedules tiles in compact square patches, minimizing the working set that fits in last-level cache simultaneously, so nearby threadgroups are more likely to reuse the data they share
4
20
176
17,089
ryan mathieu retweeted

Mar 24
(1/n) I recently joined @trymirai, where we are working on LLM inference targeting Apple Silicon. Lately I've been digging into quantization.
LLM inference is mostly memory-bound. The byte/FLOP ratio is high enough that a lot of the machine's time goes to moving data around instead of doing compute. Quantization helps with that in general, but on Apple Silicon there's an extra payoff: the GPU has a fast W8A8 path. If both weights and activations are INT8, you can use that path for prefill and speculative-decoding verification.
Weights are easy since they're static and can be quantized offline. Activations are where the real pain starts.
7
9
35
3,776