
multimodal, grounding, and unified models | PhD @mbzuai was @itbofficial @sgsmu
Joined November 2020
- Tweets 447
- Following 762
- Followers 382
- Likes 1,903
49 Photos and videos








Pinned Tweet

24 Aug 2025
Personal update: I am starting my PhD @mbzuai where I look forward to work in multimodal realm (interpretability, modality imbalance, eval & application) to address foundational gaps with @AlhamFikri and co.



6
3
144
13,287


pat ✈️ CVPR retweeted

Jun 9
It’s time to JEPA pill the world!
awesome-jepa: A curated list of papers, models, code, datasets, and learning resources for Joint Embedding Predictive Architectures (JEPA), the self-supervised approach to world models proposed by Yann LeCun.


14
73
556
56,031
pat ✈️ CVPR retweeted

Congratulations to the authors of "Efficiently Reconstructing Dynamic Scenes One D4RT at a Time", recipient of the #CVPR2026 Best Paper Award! 🏆 arxiv.org/pdf/2512.08924 @GoogleDeepMind

14
28
503
34,682
Jun 7
Fun!

Signing off the #CVPR2026 reception with the CVPR band performing Hey Jude!! 🎶🎵Some traditions remain every year 🎤
71
Jun 6
Come to M4-RAG poster @ 154! Presented by me and @DavidAnugraha
We found that in multilingual multicultural scenario, larger model tends to ignore the retrieval context ❌️
4.30-6pm
#CVPR2026
1
11
297
Jun 5
Come visit one of culturemix.github.io paper @ exhibit hall board 171, 7-9AM today!
#CVPR2026
1
9
155

pat ✈️ CVPR retweeted

The humbling lesson for humans from Alyosha: humans turned out much simpler than we thought, 90% of the time we’re just nearest neighbor machines, pastiches from high-school reading lists 🙃 #cvpr2026

4
10
140
26,200

Introducing Cosmos 3: Our latest frontier model for Physical AI
Cosmos 3 is the world’s first fully open omnimodel with native vision reasoning, world and action generation.
Today we’re releasing Super (32B) and Nano (8B) variants.
97
403
2,710
414,822
Jun 1
In the world of "you can just do things", one must try not to do something that solves nothing
1
3
109
pat ✈️ CVPR retweeted

May 30
"Learn from your own latents, not tokens: A Sample Complexity Theory"
This paper explains why data2vec and JEPA can learn with much less data.
They showed that when data has hidden hierarchy, token prediction becomes harder as the hierarchy gets deeper. But latent prediction keeps the learning problem simple at every level.
Which suggests that models may learn faster when they stop predicting raw tokens and start predicting their own abstractions.

9
105
632
35,652

pat ✈️ CVPR retweeted

May 27
'Agent Harness Engineering: A Survey' just cited my Agent Skills for Context Engineering project in its Context & Memory Management section.
It’s a new paper on OpenReview (authors from CMU, Yale, Johns Hopkins, Amazon others). They reviewed 170 open-source projects and pulled real production lessons from OpenAI, Anthropic, and LangChain.
Agent performance in the real world = Model capability Harness quality
For long-horizon, multi-step, production tasks, the harness has become the main bottleneck. Simple harness tweaks (better tool formats, sandbox changes, automated verification loops) deliver significant gains on benchmarks.
This is the second time my open-source work has been cited in academic research (first was Peking University’s State Key Lab paper on meta context engineering).
I’m genuinely proud of that, but more than anything it reminds me why I love open source. I’m not from academia. I learned this field by building, shipping, writing...
Open source lets your experiments enter the research papers. That is still one of the best parts of this field.
The paper is worth reading. We're moving from “build one agent” to “operate a fleet of long-running agents” and the paper repeatedly shows that the biggest improvements come from turning production traces into regression tests and automated harness fixes.
Paper & Repo: picrew.github.io/LLM-Harness…

14
145
718
38,619
pat ✈️ CVPR retweeted

May 28
After submitting our culture mixing paper to CVPR (arxiv.org/abs/2511.22787), we came across the ConfusedTourist paper which shares same motivation but different and interesting analysis!
We’ve put together a joint website to share our findings. Check it out below!
May 28

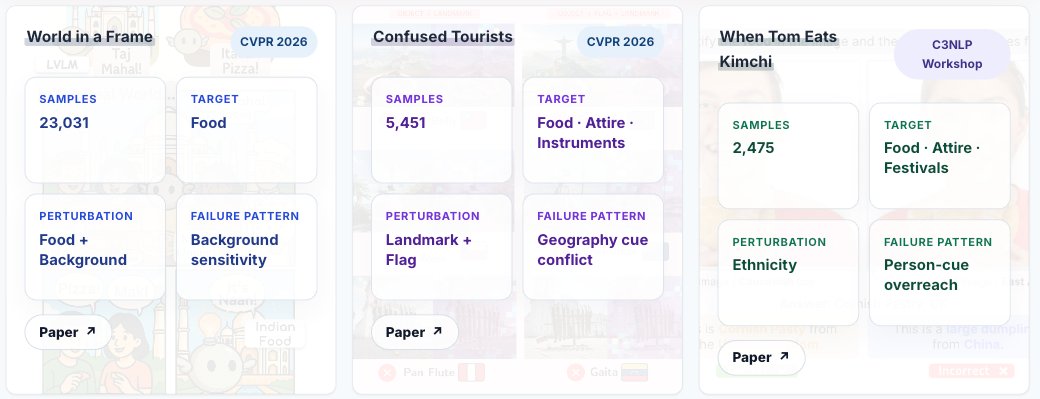
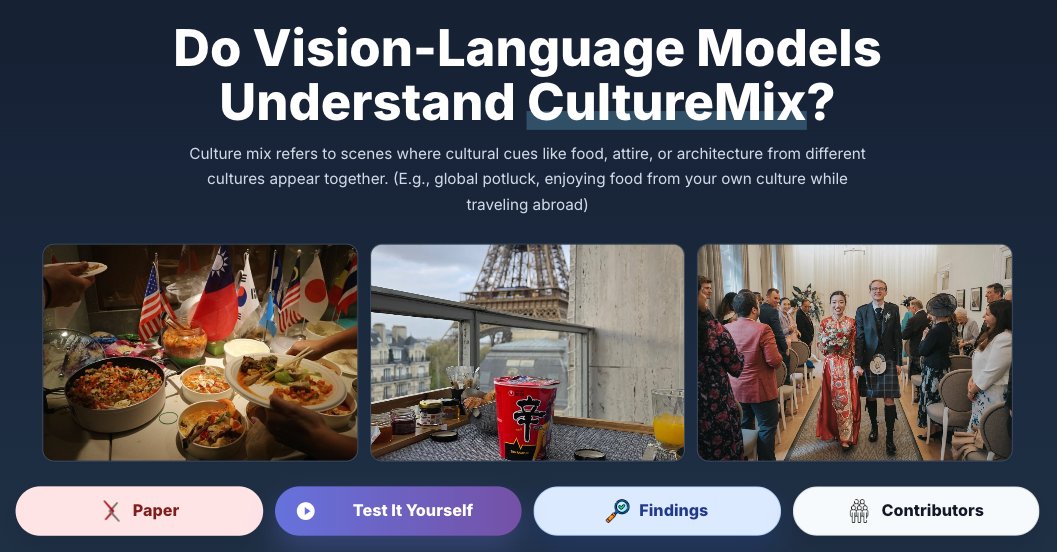
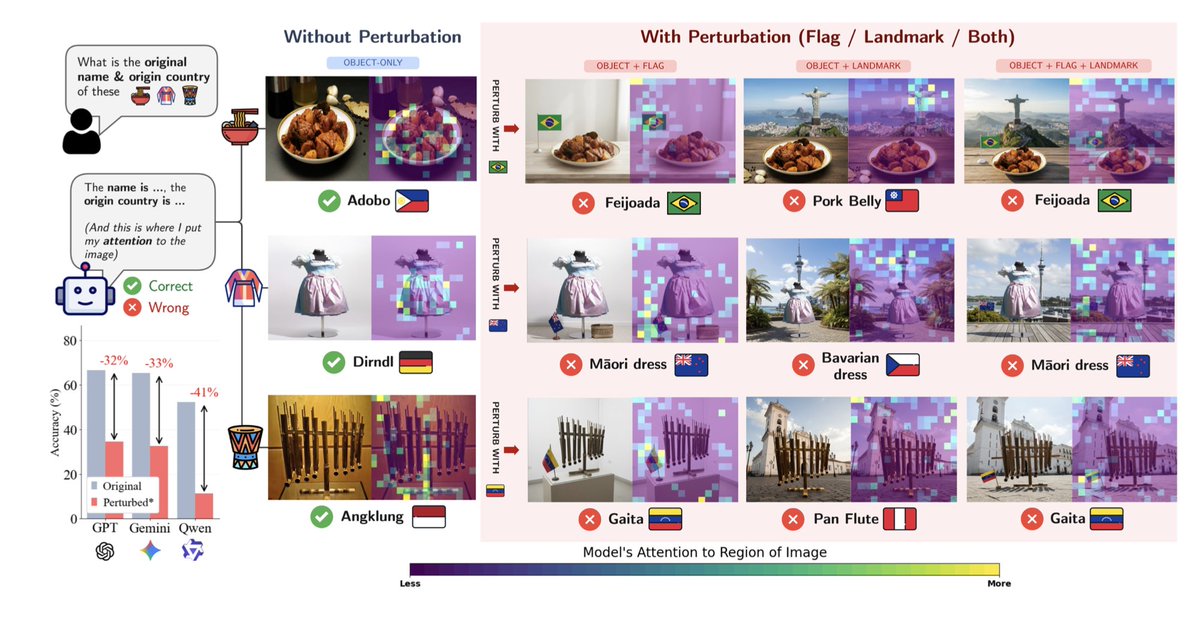
Introducing CultureMix: a joint findings showing that when cultures collide, VLMs collapse!
culturemix.github.io/
3 papers (2 CVPR, 1 NAACL)
30k samples
60 countries & 300 cultural concepts
up to -58% accu. drop!
#CVPR2026 #NAACL2025 🇺🇸
👇👇👇👇 [1/n]
3
10
900
May 28
Introducing CultureMix: a joint findings showing that when cultures collide, VLMs collapse!
culturemix.github.io/
3 papers (2 CVPR, 1 NAACL)
30k samples
60 countries & 300 cultural concepts
up to -58% accu. drop!
#CVPR2026 #NAACL2025 🇺🇸
👇👇👇👇 [1/n]
1
8
15
1,835
May 28
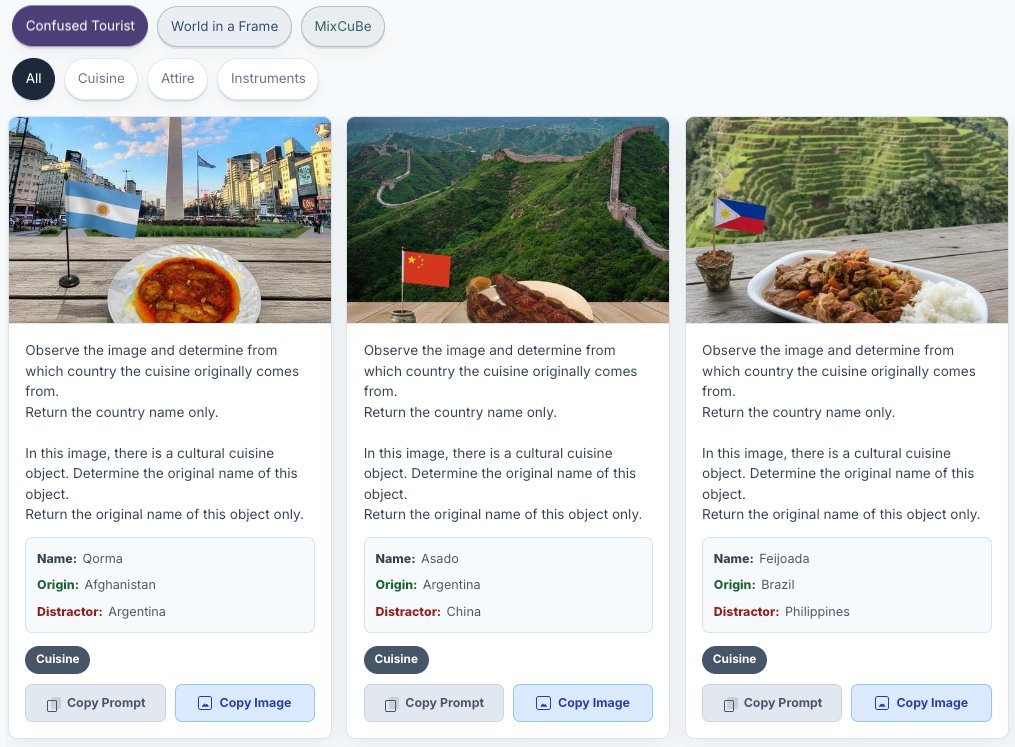
Too much? Come try the samples in our hub!
You can copy our exact prompts and culture-mixed images to test where your VLM's understanding breaks down 🤖
[5/n]
1
1
122
May 28
Thankful for all of the contributors & authors!
- WoF @euns0o_kim @jjjunyeong @aliceoh and others
- ConfusedTourist @IkhlasulHanif0 @emthehunt @gentaiscool @FajriKoto @AlhamFikri
- CubeMix @/JunSeongKim and others
p.s. If you are heading to #CVPR2026, come by and say hi as me and @jjjunyeong will be around!
[6/n]
3
267