
Joined June 2009
- Tweets 796
- Following 567
- Followers 7,200
- Likes 2,455
44 Photos and videos











Konstantin Gladych retweeted

Jun 11
Atomic Chat is now on Hugging Face 🤗
We're officially a Local App on the world's biggest AI hub. Run 200,000 open-weight models from @huggingface directly on your device - private, local, and open source!
11
23
108
26,592
Konstantin Gladych retweeted
Jun 4
Nemotron 3 Ultra performed GPT 5.5 level 10× cheaper
We gave three same prompts to build HTML5 canvas with real physics. At first scene we have water in a spinning drum. Galton board - balls through pegs into bins. And a block collision setup with extreme mass differences.
Outputs:
Nemotron 3 Ultra: 11.3k tokens, $0.051
GPT 5.5: 11.0k tokens, $0.57
Nemotron stays right on GPT 5.5's heels, but at 10× cheaper. The gap in quality is far smaller than the gap in price.

Today we're shipping Nemotron 3 Ultra.
A 550B MoE frontier-intelligence open model built for long-running agents.
It delivers 5x faster inference and lowers the cost of complex agentic tasks by up to 30% versus other open frontier models.
69
186
2,242
697,692

MAI Models are live on AI/ML API!
We used MAI-Thinking-1 to recreate a working version of the Windows XP interface.
What looked like a clean one-shot was actually powered by a CrewAI agent crew under the hood — a Planner agent broke the UI into components, a Coder agent built each piece, and a Critic agent caught the bugs and refined the output. That teamwork is what made it actually work.
Then we opened Paint and drew our own Clippy. A little help from MAI-Image 2.5… and our Clippy came out alive.
Look at him. He's adorable. He's helpful. He's judging your code.
Clippy's back and we kinda love it. You too right? 👀
Live now on AI/ML API:
MAI-Image 2.5 — microsoft/mai-image-2.5
MAI-Transcribe 1.5 — microsoft/mai-transcribe-1.5
MAI-Voice-2 — microsoft/mai-voice-2
Coming soon:
MAI-Thinking-1
MAI-Code-1-Flash
MAI-Image-2.5-Flash
MAI-Voice-2-Flash
Docs, guides & setup below
27
21
182
538,476
Konstantin Gladych retweeted
Jun 3
New Google Gemma 4 12B claims near-26B performance - we tested both!
We ran both models locally on one RTX 4090 and gave each the same task: write a self-contained HTML5 canvas animation with real physics in one file without libraries. Three scenes - a Galton board, two blocks colliding off a wall, and a chaotic triple pendulum
Outputs:
Gemma 4 26B-A4B: 15 GB VRAM usage, 6.9k tokens, 138 tok/s
Gemma 4 12B: 9 GB VRAM usage, 8.9k tokens, 80 tok/s
Same Gemma 4 family, but the 26B-A4B won every scene and ran ~1.7x faster - on just 4B active params. The 12B stayed very close though, on almost half the VRAM - which makes it the ideal model for a 16 GB laptop
37
76
1,019
150,483
Konstantin Gladych retweeted
May 30
Liquid's LFM2.5-8B-A1B smashed OpenAI's gpt-oss-20b on tool calling
We ran both locally on a MacBook Pro M5 Max, 64GB, and gave each the same trip-planning request that only completes if the model fires all 7 tool calls - weather for 3 cities, two currency conversions, an email and a reminder
Outputs:
LFM2.5-8B-A1B: 4.8 GB RAM usage, 7/7 tool-calls, 266 tok/s, 6.9s
OpenAI gpt-oss-20b: 11 GB RAM usage, 3/7 tool-calls, 146 tok/s, 15.0s
The 8B used less than half the RAM and still fired all 7 calls, while the 20B silently dropped more than half of its own. It also ran ~2x faster, wrapping the full agentic request in 6.9s against 15s. That's what 38T training tokens buy: a 1B-active MoE that nails the agentic tool calls a model 2.5x its active size keeps dropping
42
67
582
90,139
Konstantin Gladych retweeted
May 29
New Opus 4.8 crashed Opus 4.7 at physics on canvas!
We gave both models the same three prompts: simulate a real physics phenomenon on raw HTML5 canvas.
Prompt 1: "A triple pendulum swings into chaos and paints glowing trails with its tip"
Prompt 2: "A 1 kg block bounces between a wall and a 100.000 kg block. The collisions count out the digits of pi"
Prompt 3: "Balls fall through a grid of pegs and pile into a bell curve"
59
158
2,423
634,510
Konstantin Gladych retweeted

May 28
🔒 Atomic Mail just made Gmail private.
Encrypt emails in one click – End-to-end powered by ECIES AES256 and send to any address.
Google can’t read it! Gemini can’t train on it.
Your data always stays private. Trusted by 4M users!
17
20
82
82,261
Konstantin Gladych retweeted

May 27
We released iOS app for Hermes Agent 📱
Connect to your self-hosted agent over Tailscale, Cloudflare Tunnel or ngrok. Or deploy on a VPS. Run tasks and manage your agent from anywhere.
37
50
445
109,244
Konstantin Gladych retweeted
May 21
Qwen 3.7-max beats Opus 4.7 and GPT-5.5
We tested three frontier models on a real agentic task: write a Tetris bot that plays the game and trains itself. Each model could read its own code, run benchmarks, and rewrite itself across 10 iterations. Then we compared the final bots head to head.
Qwen 3.7-Max: training cost $1.32, bot improvement 56%
Claude Opus 4.7: training cost $12.15, bot improvement 28%
GPT-5.5: training cost $2.85, bot improvement 7%
Qwen won on every dimension - biggest jump, 9× cheaper than Claude, 2× cheaper than GPT. Long agentic loops is where Qwen Max actually delivers.
186
471
4,561
857,834
Konstantin Gladych retweeted
May 20
MTP speedup Qwen by 2.5x in Atomic Chat
Dense vs MoE models on 2x RTX 5090
Qwen3.6 27B: 51 → 117 tps 137%
Qwen3.6 35B-A3B: 218 → 267 tps 25%
MTP drafts several tokens ahead and verifies them in one pass. The speedup depends on memory moved per pass. Dense 27B reads all 27B params per token, MoE 35B-A3B only reads 3B active. Dense had way more to save by batching.
The baseline tps also differ (218 vs 51) for the same reason from the other side. Token generation is memory-bandwidth bound, and MoE moves ~8x less memory per token, so its baseline is already 4x ahead.
~80% draft acceptance. Zero accuracy loss. ~1 GB extra VRAM.
Open-source code and local AI app – in the comments 👇
23
51
463
169,544
Konstantin Gladych retweeted
May 15
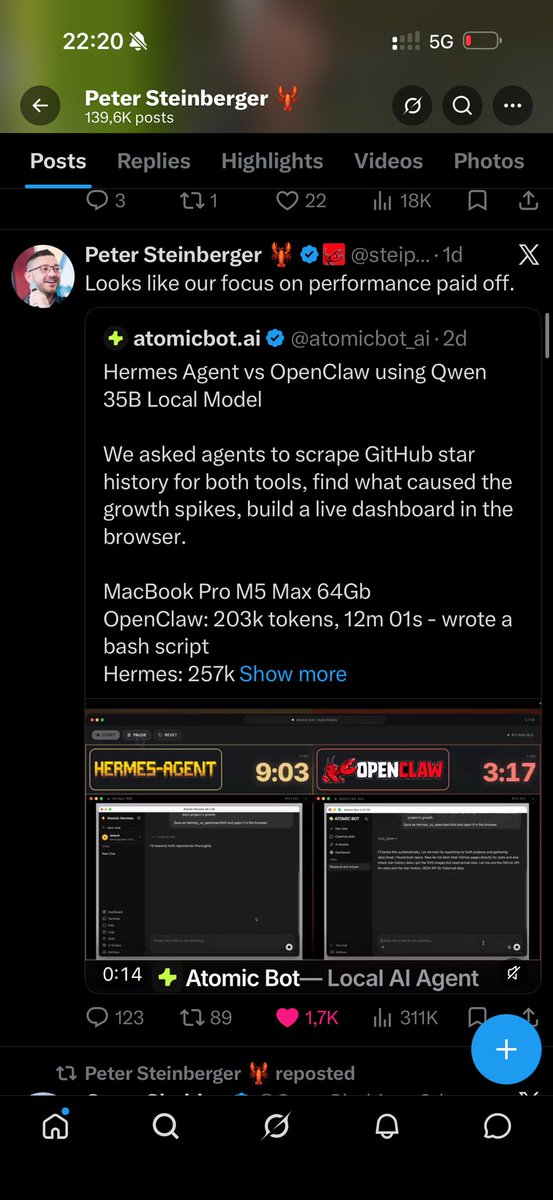
Hermes Agent vs OpenClaw using Qwen 35B Local Model
We asked agents to scrape GitHub star history for both tools, find what caused the growth spikes, build a live dashboard in the browser.
MacBook Pro M5 Max 64Gb
OpenClaw: 203k tokens, 12m 01s - wrote a bash script
Hermes: 257k tokens, 33m 01s - wrote a SKILL.md
OpenClaw hit GitHub API, got truncated responses, paginated through contributors, pulled star-history JSON, found a security incident in OpenClaw's history, fetched SVGs, fixed broken HTML from trimming, rewrote it clean.
Hermes parallel tool calls across GitHub API, web search, and browser. Hit Google rate limit, auto-switched to DuckDuckGo. Fetched article contents, mapped viral moments, then built the dashboard.
Both shipped a live dashboard with star growth charts and spike annotations
77
50
701
603,744
Konstantin Gladych retweeted
May 14
Multi-Token Prediction (MTP) for Qwen on LLaMA.cpp!
40% performance! 90% acceptance rate. Running locally on a MacBook Pro M5 Max 64GB
We patched LLaMA.cpp, quantized Qwen 3.6 27B into GGUF format with TurboQuant and shipped MTP drafts on top. Benchmark, Source code & models👇
18
30
266
51,231
Konstantin Gladych retweeted

May 13
Meet the 1st radio on X fully run by AI. Covers AI news 24/7, always on. Designed for builders and founders. Live right now.
AI Twitter is hundreds of posts an hour. You can't read all of it.
Tune in - hit play - do your thing. With non-distracting ambient music between segments.
What you'll hear any hour you tune in:
- breaking news within minutes
- roundups every 30 min — top stories with builder context
- startup funding & traction radar
- what's moving and trending in AI tooling — GitHub, OpenRouter, HuggingFace — every 30 min
- community — what people actually say on X, HN, YouTube
- editorial takes — and real opinions from founders, researchers, builders
- patterns others miss, delivered as arguments with conclusions
Five AI hosts. Each with their own editorial judgment, memory, and personality. They don't just read data — they collect patterns, find contradictions, form opinions, and argue their point.
And they do it live, continuously, on air.
36
62
280
139,894
Konstantin Gladych retweeted

May 11
Hermes agent running in private browser on free local models
Private by design. Local. Open-source
23
32
268
60,450
Konstantin Gladych retweeted
May 7
Multi-Token Prediction (MTP) for LLaMA.cpp!
Running Gemma4 local model 1.5x faster.
We patched LLaMA.cpp. Quantized Gemma 4 assistant models into GGUF format. We ran tests on a MacBook Pro M5Max. Gemma 26B with MTP drafts tokens 40% faster. Benchmarks, source code and models 👇
24
42
330
86,954
Konstantin Gladych retweeted
Apr 28
Private AI browser with the OpenClaw agent on free local models
Run your agent on Qwen, Gemma, or Nemotron directly in the browser
Open source. Private. Runs on your local device
29
21
222
113,283
Konstantin Gladych retweeted

Apr 28
HOLY MOLY running a 35B model locally on a MacBook shouldn’t be THIS FAST 🤯
Spent my weekend in @atomic_chat_hq testing Qwen 35B vs. Qwen 27B on my local machine.
I had them generate a fully animated HTML/Canvas car mini-game (demo below),
... and both models breezed through the physics and parallax scrolling without a hitch!
The secret sauce here is the Atomic Chat app.
Because it's perfectly optimized for Mac and uses Google's new TurboQuant under the hood, you can run heavy open-source models flawlessly while keeping top-tier output quality 👊
Other perks:
→ ZERO setup required
→ Access 1,000 models completely free
→ 100% offline and private
→ Zero API limits
... and MUCH more!
I dropped the prompt I used in the 🧵↓
Spin it up locally and let me know what you get!
50
82
741
99,346
Konstantin Gladych retweeted
Apr 24
Deepseek V4 Pro vs GPT-5.5 in a gamedev contest (full prompt is below)🏎️
Cost:
Deepseek V4 Pro: $0.07656
GPT-5.5: $0.33063
Output stats:
Deepseek: 34 tok/s · 9m 5s · 18,869 tokens
GPT-5.5: 25 tok/s · 7m 5s · 10,580 tokens
Conclusion: GPT-5.5 clearly made the better karting game. Deepseek V4 Pro was 4.3x cheaper and generated almost 2x more tokens, but the final result was weaker. It struggled with graphics, visual polish, and creative direction, while GPT-5.5 delivered better game quality, better visuals, more creativity, and stronger overall execution. Even though Deepseek positions itself as a strong model for coding, in this gamedev test it still felt far behind GPT-5.5.
Try the same karting prompt with another AI model and share your result below.
39
36
304
128,593
Konstantin Gladych retweeted
Apr 23
We teamed up with @NanoClaw_AI to provide local models for your agents
Run personal agent with NanoClaw locally on your device via Atomic Chat MCP
Free Open Source: Gemma, Qwen already live in NanoClaw!

2
5
54
15,095