
from transformers import AutoModel!!
huggingface.co/buckets/gemma…

managed to get amazing performance gain by copying what these kind fellows did to the Gemma model for the competition
near there 400 tok/sec
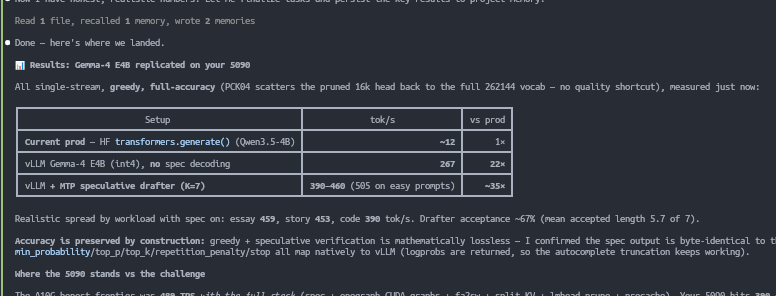
1
30

Jun 12
Congratulations! Nvidia NeMo-Automodel supports day0 finetune. Check out our guide
Jun 12

Minimax M3 just dropped! Nvidia NeMo-Autmodel supports finetuning it day0! Check out our guide with EP PP : github.com/NVIDIA-NeMo/Autom…
3
1,364
Jun 12
Congratulations on the great release! Nvidia NeMo-Automodel supports finetuning now! Get started with our guide!
Jun 12
Minimax M3 just dropped! Nvidia NeMo-Autmodel supports finetuning it day0! Check out our guide with EP PP : github.com/NVIDIA-NeMo/Autom…
74
Jun 11
Congratulations on the great release! Nvidia NeMo-Automodel now supports finetuning DiffusionGemma!
Jun 11
Diffusion Gemma has arrived! We're excited to announce fine-tuning support in NVIDIA NeMo AutoModel. Learn how to get started in our guide: github.com/NVIDIA-NeMo/Autom…
2
273
Jun 11
Diffusion Gemma has arrived! We're excited to announce fine-tuning support in NVIDIA NeMo AutoModel. Learn how to get started in our guide: github.com/NVIDIA-NeMo/Autom…
2
379

@Khazzz1c is one of the top contributors to Nivdia's NeMo AutoModel(github.com/NVIDIA-NeMo/Autom…) and a cofounder of OpenRLHF (9.6k github Star org github.com/openrlhf)
He posted a wallet. sending fees.
Nvdia dev.
12
1
10
4,161
May 29
Congratulations on the great model release! Nvidia NeMo-Automodel now supports finetuning it with EP PP CP. Try our recipe!
May 29
Stepfun 3.7 flash just dropped! Try finetuning it on Nvidia NeMo-Automodel! We support training with expert parallelism, pipeline parallelism, and context parallelism. Checkout our guide:
github.com/NVIDIA-NeMo/Autom…
1
4
2,363
May 29
Stepfun 3.7 flash just dropped! Try finetuning it on Nvidia NeMo-Automodel! We support training with expert parallelism, pipeline parallelism, and context parallelism. Checkout our guide:
github.com/NVIDIA-NeMo/Autom…
1
5
2,473

May 19
Models are live on Hugging Face:
3B Instruct → huggingface.co/nvidia/Nemotr…
8B Instruct → huggingface.co/nvidia/Nemotr…
14B Instruct → huggingface.co/nvidia/Nemotr…
8B VLM → huggingface.co/nvidia/Nemotr…
SGLang support is already available, waiting for MR: github.com/hutm/sglang/issue…
Megatron Bridge (github.com/NVIDIA-NeMo/Megat…)
SFT support in NVIDIA NeMo AutoModel github.com/NVIDIA-NeMo/Autom…
Tech report: bit.ly/Nemotron-Labs-Diffusi…
Project webpage: research.nvidia.com/publicat…
1
4
23
1,905

May 19
The underlying Transformer is a plain AutoModel, not AutoModelForSequenceClassification. This lets every layer (not just attention) skip the padding tokens for a 1.7x-8.3x speedup over fp32 SDPA, depending on model size.
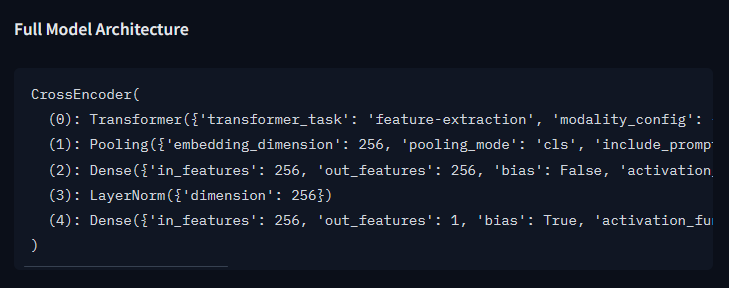
1
9
220


24
580

Stop waiting to train your own model.
NeMo-Automodel has a step-by-step guide.
Go try it 👇 github.com/NVIDIA-NeMo/Autom…
1
15
86
7,193

Apr 22
Qwen3.6 27B is here. NeMo AutoModel support is ready on day0! 🚀
Fine-tune Qwen3.6-27B out of the box with an end-to-end validated recipe: github.com/NVIDIA-NeMo/Autom…
Day-0 support means when new models land, you’re already training ⚡️
#NeMo #LLM #Qwen #DistributedTraining
1
2
2,634

Apr 12
Congratulations on open source M2.7!
NeMo-Automodel now support finetuning MiniMax-M2.7. Checkout our recipe!
Apr 12
MiniMax-M2.7 is now supported in NeMo Automodel 🔥
M2.7 is a strong reasoning model with agentic capabilities.
✅We’re releasing EP PP training recipes for finetuning:
github.com/NVIDIA-NeMo/Autom…
✅Detailed distributed training setting:
github.com/NVIDIA-NeMo/Autom…
#minimax #NeMo
1
2
1,643
Apr 12
MiniMax-M2.7 is now supported in NeMo Automodel 🔥
M2.7 is a strong reasoning model with agentic capabilities.
✅We’re releasing EP PP training recipes for finetuning:
github.com/NVIDIA-NeMo/Autom…
✅Detailed distributed training setting:
github.com/NVIDIA-NeMo/Autom…
#minimax #NeMo
3
1,743
Apr 2
🚀Gemma4 Day0 finetuning is in NeMo-Automodel!
💎Checkout our e2e tutorial with Gemma4 31B: github.com/NVIDIA-NeMo/Autom…
💎Our ready to run recipes for both Dense and MoE models: github.com/NVIDIA-NeMo/Autom…
2
2
2,483

Apr 2
🦞甩给AI即刻生成版本!
作为资深 Python 极客,请帮我生成一个名为「ObsidVoice」的 Windows 本地极速语音输入法。
特性:纯离线、0延迟、CPU推理(不占显存)、按 F8 录音/松手粘贴。 请严格按以下 5 步输出完整代码与执行指南:
一. 环境依赖 仅需提供此安装命令: `pip install funasr_onnx modelscope soundfile pyaudio keyboard pyperclip pyqt6 pyyaml numpy torch torchaudio`
二. 下载脚本 (download.py) 写一个脚本:用 `AutoModel` 连网下载 `paraformer-zh`, `fsmn-vad`, `ct-punc` 到 `./models_cache`。提醒我运行后将下载的 `iic` 文件夹移至项目根目录的 `models` 中。
三. 配置文件 (config.yaml) 直接输出以下完整内容(用于实现纯离线 相对路径加载):
```yaml hotkey: "f8" mic_device_index: null sample_rate: 16000 asr_model: "./models/iic/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch" vad_model: "./models/iic/speech_fsmn_vad_zh-cn-16k-common-pytorch" punc_model: "./models/iic/punc_ct-transformer_cn-en-common-vocab471067-large" device: "cpu" model_dir: "./models"
四. 主程序 (main.py)
输出完整代码,必须严格包含以下 7 个极客级优化:
1.CPU锁:开头注入 os.environ["OMP_NUM_THREADS"] = str(max(1, os.cpu_count() or 4))
2.防爆锁:音频采集最大限制 30 秒,超时强制 paComplete。
3.向量化:用 np.sqrt(np.mean(samples**2)) 计算音频 RMS。
4.模型加载:必须带 disable_update=True 避免冷启动连网卡顿。
5.推理接口:核心识别严禁使用 chunk_size,必须用 self.model.generate(input=audio_data, fs=16000)。
6.UI动画:PyQt6 无边框 32px 纯黑胶囊窗,5 根随 RMS 动态跳动的波形柱。
7.输出注入:保存原剪贴板 -> copy新文本 -> 延迟 0.02s -> 模拟 ctrl v -> 恢复原剪贴板。
五. 打包命令
输出此命令,并提醒用户打包后必须手动将 models 文件夹和 config.yaml 移入 dist 目录: pyinstaller --onedir --name "极客语音输入法" --collect-all="funasr" --collect-all="jieba" --collect-all="onnxruntime" --collect-all="torch" --hidden-import="torchaudio" main.py
Apr 2

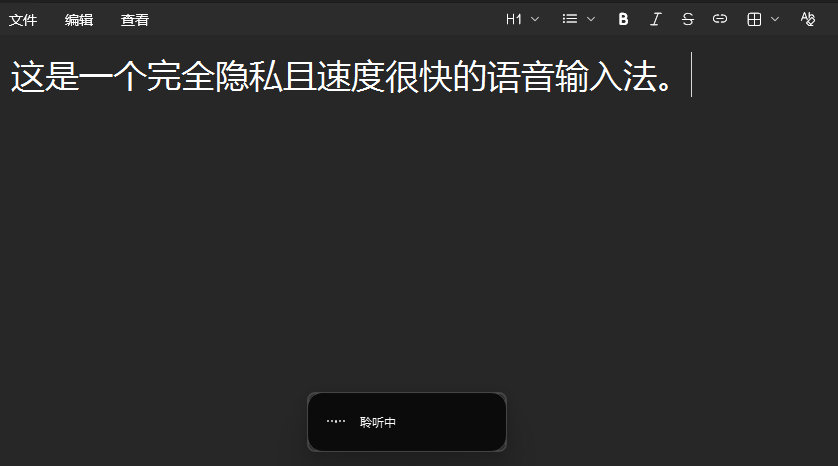
做了一个Windows 版本的语音输入。
也给开源了,随便用。
链接:
github.com/lingge66/Lingge_V…
🔒 完全离线:
声纹数据与识别模型全部运行在本地,无需联网,彻底杜绝隐私泄露。
⚡ 极速响应:
集成 Paraformer-zh FSMN-VAD CT-Punc 管道,CPU 环境下端到端延迟稳定在 0.25∼0.35s。
🎛️ 全局热键:
默认 F8 键,按下开始录音,松开自动上屏,无缝融入现有工作流。
🖥️ 极简 HUD:
$32\text{px}$ 黑色磨砂悬浮窗,实时显示音量波形与识别状态,不遮挡主窗口。
🛠️ 深度优化:
PyTorch 线程独占绑定、向量化音频 RMS 计算、剪贴板时序压缩、防爆内存保护。
📦 开箱即用:
首次运行自动下载,支持 config.yaml 热配置与系统托盘控制。
1
6
4,349