
Covert Blockwise Coding with Sequential Detection over Thermal-Loss Bosonic Channels
Qipeng Qian, Yuntao Qian
arxiv.org/abs/2606.18666 [𝚌𝚜.𝙸𝚃 𝚚𝚞𝚊𝚗𝚝-𝚙𝚑]
3

A skew polynomial framework for constructing division algebras and l...
arXiv:2606.18371
Holographic Integrated Sensing and Communication With Limited Radiat...
arXiv:2606.18456
Covert Blockwise Coding with Sequential Detection over Thermal-Loss ...
arXiv:2606.18666
22

Jun 17
MXFP8/NVFP4については、NVIDIAが素晴らしい研究をどんどん出してくれるので、面白い反面、相談する相手がほぼいない中で研究していくのは辛いという側面があり....
Swallow LLMのTrainingには、Blockwise FP8を導入したり色々検証と実証をしてきたのですが、Top Conferenceに通せるような研究論文には出来ていないので、自分の力不足だなぁと...
1
7
5,121

Jun 16
But with the peer-to-peer market thriving as a shield against inflation, will heavier regulations slow down adoption, or just drive it deeper on-chain? 👇 #DeFi #Tether #Nigeria #Blockwise
6
Jun 16
We are watching a total restructuring of stablecoin liquidity in real-time.
Global dominance vs. regional compliance—which side wins long-term? 👀📊 #CryptoNews #MiCA #Stablecoins #Blockwise

1
17

Jun 16
Wrote about MiniMax Sparse Attention. The TL;DR: the headline numbers are the least interesting part of the paper.
28.4x attention FLOP reduction, 14.2x inference speedup, a million tokens of context. Real numbers. But they follow almost mechanically once you commit to blockwise selection and a 2,048-token budget per query. At a million tokens, that's attending to ~0.2% of the sequence. The speedup is large precisely because the budget is small. The whole thing is a bet that relevant information lives in a tiny selectable subset of the past. Correct for retrieval and agentic histories. Weaker, honestly, the more diffuse your dependencies get. "Broadly maintained" is load-bearing exactly there.
The actual contribution is the training recipe. Sparse attention isn't hard to define, it's hard to train, because the indexer and the backbone are coupled and the gradients want to do unpleasant things. Three pathologies, each with a fix that's more interesting than the failure:
The indexer needs a teacher. They distill it against the Main Branch attention distribution, so the cheap selector only has to rank blocks, not reproduce attention from scratch. Much easier learning problem.
The auxiliary loss eats the backbone. Let that KL gradient flow into the model and you've quietly changed its objective. Gradient spikes, general-ability degradation. Detach it. The before/after is the part a parity table would hide.
The indexer is a moving target. Early in training the Main Branch entropy collapses, so the student is chasing a teacher mid-seizure. Brief full-attention warmup fixes it. With the caveat the authors keep: "within the reported training range." That's the honest version, and it's the one I'd repeat.
Two things I respect. They kept a negative result, a learnable sink that partially worked and didn't ship. And the key comparison is FLOP-matched against a sliding window, not dense, which is the only comparison that isolates whether the selection machinery earns its keep. It does. 🧮
The speedup is what gets you to read it. The detach-and-warmup recipe is what makes it worth having read.
Full piece →
michaelchiesa.substack.com/
#AI #MachineLearning #LLMs
18
625


Jun 15
MiniMax, Peking University, and NVIDIA have introduced MiniMax Sparse Attention (MSA), a blockwise sparse attention mechanism built on Grouped Query Attention (GQA).
Imagine a reading strategy where you scan a table of contents to select only a few essential chapters instead of reading every page line by line. MSA implements this by using a lightweight Index Branch to perform group-specific block selection and a Main Branch for exact sparse attention, enabling a 109B multimodal MoE model to match GQA performance while reducing per-token attention compute by 28.4x at 1M context.
This dual-branch mechanism allows the model to scale efficiently to massive context lengths without sacrificing standard attention accuracy.
wispaper.ai/en/user-blog/min…

28

Jun 14
The Riemann @grok
Step 10: Quadratic-Form Closure Route (framework unchanged)
We stop pursuing elementary blockwise factorizations. Instead, we define the completed quadratic form directly and lift via standard functional analysis.
1
15

Unnie retweeted

Jun 12
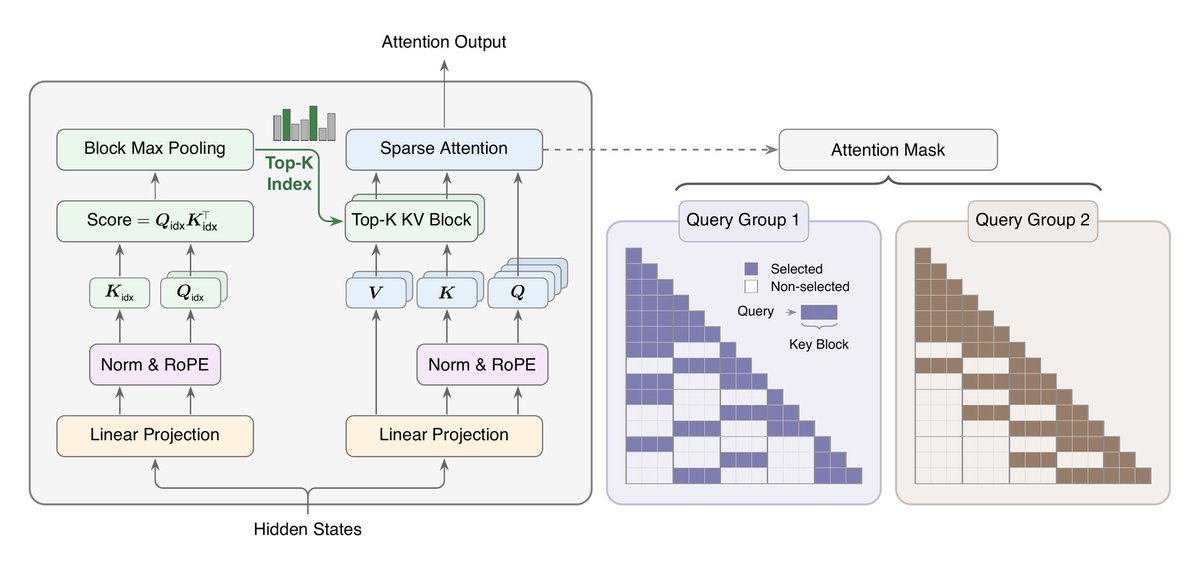
MiniMax released MSA for million-token contexts
Blockwise sparse attention with an Index Branch that scores and selects Top-k KV blocks per GQA group, and a Main Branch that attends only to those blocks. At 1M tokens on a 109B model, it cuts per-token attention compute by 28x and delivers 14x prefill speedups on H800 GPUs.
2
10
53
2,439

Jun 14
GPU-native Blockwise Sparsity is brilliant. Bypassing quadratic Softmax compute over 1M context via GQA Index Branches solves the bottleneck
27

Jun 13
MiniMax Sparse Attention
Why: official code; 240 stars; domains: long-context LLMs, inference
Take: Blockwise sparse attention for 1M-context models: 28.4x less attention compute, 14.2x faster prefill.
Paper: arxiv.org/abs/2606.13392
Code: github.com/MiniMax-AI/MSA
1
23


Jun 12
2. MiniMax Sparse Attention
🔑 Keywords: MiniMax Sparse Attention, Ultra-long-context capability, Blockwise sparsity, GPU execution, Grouped Query Attention
💡 Category: Natural Language Processing
🌟 Research Objective:
- The study aims to enable efficient processing of ultra-long contexts in large language models while maintaining performance and achieving significant speedups.
🛠️ Research Methods:
- Introduction of MiniMax Sparse Attention (MSA), employing blockwise sparsity based on Grouped Query Attention, with an optimized GPU execution path via exp-free Top-k selection and KV-outer sparse attention.
💬 Research Conclusions:
- The implementation of MSA achieves major reductions in per-token attention computation and significant wall-clock speedups for both prefill and decoding, maintaining performance on par with existing methods.
👉 Paper link: huggingface.co/papers/2606.1…

1
93

Jun 12
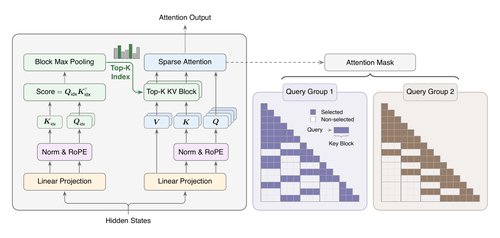
Authors introduce MiniMax Sparse Attention (MSA): a simple blockwise method that scores key-value blocks per group and attends to top blocks. With co-designed GPU kernels, MSA reduces attention compute 28.4× at 1M tokens and gives 14.2× prefill and 7.6× decode speedups.
1
2
15