
If you're building autonomous agents that need to plan, reflect, and recover from failures, you need more than just an in-memory saver. We show how you can handle heavy read/write checkpointing without breaking a sweat. ow.ly/nSwb50YLan2
#ScyllaDB

1
184

The agent loop framing is right but incomplete.
Most agent failures aren't the model — they're the tooling layer.
Error recovery, checkpointing, context budget allocation.
Fix the orchestration first, then the model choice matters less.
Ships > demos.
8


7/7 💡 Core engineering takeaways from the Netflix team:
1️⃣ Reduce surface area first—explore simpler solutions and deploy incrementally.
2️⃣ Operational confidence is everything. Invest heavily in testing and checkpointing to survive partial read failures during splits.
1
49


Each one taught me what the others couldn't.
Next: adding tools conditional edges memory checkpointing.
The deeper you go into agentic AI, the more LangGraph makes sense.
🔗: github.com/Charlie-Charlie01…
#LangGraph #AgenticAI #Python #LLM #OpenAI
1
18



Jun 13
Why India Needs Its Own Claude-Class LLM — And How We Can Build It Together
Artificial Intelligence is no longer just a software trend.
It is becoming the new infrastructure of the world.
The countries that control powerful AI models will control the next generation of education, healthcare, defence, governance, finance, agriculture, research, automation, robotics, and digital public services.
Today, the most powerful Large Language Models are being built by a few global companies such as OpenAI, Anthropic, Google DeepMind, Meta, and xAI. These models are extremely powerful, but they are not built primarily for India’s languages, India’s culture, India’s governance needs, India’s enterprises, or India’s long-term strategic independence.
That is why India needs its own Claude-class frontier LLM.
Not a copy of Claude.
Not just another chatbot.
India needs a sovereign, multilingual, reasoning-first, secure, scalable AI model built for 1.4 billion Indians and for the world.
This is not only a technology goal.
This is a national mission.
Tagging leaders, policymakers, builders, and companies who can help shape this mission:
@Narendra Modi @Ashwini Vaishnaw @MeitY @IndiaAI @Digital India @NASSCOM @Nandan Nilekani @Mukesh Ambani @Reliance Industries Limited @Jio Platforms Limited @N. Chandrasekaran @Tata Group @Tata Consultancy Services @Infosys @Salil Parekh @Wipro @Rishad Premji @HCLTech @C Vijayakumar @Tech Mahindra @Anand Mahindra @Sridhar Vembu @Zoho @Bhavish Aggarwal @Ola Krutrim @Vivek Raghavan @Pratyush Kumar @Sarvam AI @Kris Gopalakrishnan @Gautam Adani @Adani Group @Sunil Bharti Mittal @Airtel @Yotta Data Services @E2E Networks
Why India Needs Its Own LLM
1. AI Sovereignty
If India depends only on foreign AI models, we risk depending on foreign infrastructure for our future intelligence systems.
AI will be used in courts, hospitals, classrooms, defence research, government services, banking, cyber security, agriculture, customer support, and software development.
If access, pricing, policies, or restrictions are controlled outside India, our digital future becomes vulnerable.
A sovereign Indian LLM gives India control over:
Data
Model behaviour
Security
Cost
Language support
Deployment
Compliance
Strategic independence
India built UPI.
India built Aadhaar.
India built ONDC.
India built ISRO.
India can also build a world-class AI foundation model.
2. India’s Language Problem Cannot Be Solved by English-First Models
India is not an English-only country.
India has Hindi, Punjabi, Tamil, Telugu, Bengali, Marathi, Gujarati, Kannada, Malayalam, Odia, Assamese, Urdu, Sanskrit, and many more languages and dialects.
A true Indian LLM must understand:
Regional languages
Code-mixed Hinglish
Local idioms
Cultural context
Indian law
Indian education system
Indian agriculture
Indian healthcare realities
Indian business language
Voice-first usage
For hundreds of millions of Indians, AI will not be typed in perfect English. It will be spoken in local languages.
That is why India’s AI model should be voice-first, multilingual, and culturally intelligent from day one.
3. Economic Growth and Job Creation
A strong Indian LLM can create a new AI economy.
Startups can build AI agents.
MSMEs can automate support and sales.
Students can learn in their own language.
Doctors can get clinical assistance.
Farmers can receive crop advisory.
Lawyers can search Indian case law.
Government departments can automate citizen services.
Indian SaaS companies can build global AI products.
Instead of paying billions of dollars every year to foreign AI APIs, India can build domestic AI infrastructure and keep value creation inside the country.
This can create thousands of high-value jobs in:
AI research
GPU infrastructure
Data engineering
Cybersecurity
Model safety
AI chips
Cloud computing
Robotics
Enterprise automation
AI education
4. National Security
AI will become deeply connected with cyber defence, intelligence analysis, drones, satellites, autonomous systems, misinformation detection, and critical infrastructure protection.
India cannot depend fully on external black-box models for sensitive national use cases.
A sovereign Indian model can be deployed inside secure government and defence environments, with full control over data, inference, logging, model updates, and safety.
What Kind of Model Should India Build?
India should not think small.
We need a multi-layer AI stack:
Small models for mobile and edge devices
Medium models for enterprises and startups
Large reasoning models for advanced research and government use
Multimodal models for text, voice, image, video, documents, and code
Domain-specific models for law, healthcare, education, agriculture, finance, defence, and governance
The final goal should be:
An Indian Claude-class AI system that can reason, speak Indian languages, write code, understand documents, operate as an AI agent, follow safety rules, and serve population-scale use cases.
How Such a Model Can Be Trained
Building a frontier LLM is not magic. It is a disciplined engineering process.
Step 1: Data Collection
The model needs massive high-quality data:
Indian language text
Government documents
Educational books
Research papers
Legal judgments
Code repositories
Public domain literature
Speech data
Translation datasets
Image-text data
Domain-specific datasets
Synthetic reasoning data
But quality matters more than quantity.
Bad data creates bad models.
India must create a national AI data pipeline where government, academia, publishers, startups, enterprises, and research labs can contribute clean, licensed, high-quality datasets.
Step 2: Tokenizer for Indian Languages
Most global models are not optimized for Indian languages.
India needs a tokenizer designed for:
Devanagari
Gurmukhi
Tamil
Telugu
Bengali
Gujarati
Kannada
Malayalam
Urdu
Roman Hindi
Hinglish
Code-mixed language
A better tokenizer reduces cost, improves accuracy, and makes Indian language AI faster.
Step 3: Pre-training
This is where the base model learns language, knowledge, patterns, reasoning, and structure.
Training requires:
Thousands of GPUs
High-speed networking
Distributed training systems
Massive storage
Data filtering pipelines
Experiment tracking
Model checkpointing
Failure recovery
Energy-efficient data centres
India should train multiple model sizes, not only one big model.
Example roadmap:
7B model for research and mobile use
30B model for startups and enterprises
70B model for advanced reasoning
100B model or Mixture-of-Experts model for frontier capability
Step 4: Post-training and Alignment
A raw base model is not enough.
It must be trained to become useful, safe, and instruction-following.
This includes:
Supervised fine-tuning
Human feedback
AI feedback
Constitutional safety rules
Indian legal and cultural alignment
Red-teaming
Bias testing
Safety evaluation
Jailbreak resistance
Enterprise compliance
This is where the model becomes helpful like ChatGPT or Claude.
Step 5: Evaluation
India needs its own AI benchmarks.
Current global benchmarks are often English-centric.
We need benchmarks for:
Indian languages
Indian exams
Indian law
Indian medicine
Indian agriculture
Indian governance
Indian coding tasks
Indian cultural reasoning
Voice conversations
Multilingual translation
Safety and misinformation
If we do not create our own benchmarks, we will keep measuring Indian AI with foreign standards.
Step 6: Deployment
Training is only half the battle.
The model must be deployed at scale with:
Cloud APIs
Government cloud
Enterprise private deployment
Mobile SDKs
Voice APIs
Agent APIs
Developer tools
Fine-tuning tools
Safety monitoring
Low-cost inference
Indian data residency
The goal should be simple:
Every Indian startup, student, developer, business, and government department should be able to use Indian AI at affordable cost.
Cost Analysis
A serious Indian LLM mission will need different budget levels.
Phase 1: Foundation Stack
Estimated cost: ₹500 crore to ₹1,500 crore
This includes:
Data pipeline
Research team
Tokenizer
7B to 30B models
Evaluation benchmarks
Initial compute
Open-source developer tools
Timeline: 6 to 12 months
Goal: Build strong Indian language models and developer ecosystem.
Phase 2: National-Scale Model
Estimated cost: ₹2,000 crore to ₹5,000 crore
This includes:
30B to 70B models
Voice-first capabilities
Multimodal training
Enterprise APIs
Government deployment
Safety labs
Domain models
Timeline: 12 to 24 months
Goal: Build a reliable Indian AI model for enterprise, education, governance, and startups.
Phase 3: Claude-Class Frontier Model
Estimated cost: ₹8,000 crore to ₹20,000 crore
This includes:
100B models
Mixture-of-Experts architecture
Reasoning models
Multimodal models
AI agents
Large-scale reinforcement learning
Secure national inference cloud
AI chip and hardware partnerships
24/7 model operations
Timeline: 24 to 48 months
Goal: Build a globally competitive Indian frontier AI system.
This may sound expensive, but compared to the size of India’s economy and the future value of AI, this is a strategic investment.
India does not need to do everything alone in one lab.
India needs a national AI consortium.
Setup Required
India needs five major layers.
1. Compute Layer
GPU clusters, AI cloud, data centres, high-speed interconnects, energy planning, and sovereign cloud infrastructure.
2. Data Layer
Licensed Indian datasets, public datasets, domain data, multilingual data, voice data, and synthetic reasoning data.
3. Research Layer
IITs, IISc, IIITs, private labs, startups, and corporate AI teams working together.
4. Product Layer
APIs, apps, AI agents, enterprise tools, government services, developer SDKs, and startup access.
5. Safety and Governance Layer
Responsible AI standards, audit systems, privacy rules, cybersecurity, red-teaming, and public-interest safeguards.
Role of the Indian Government
The government should not only regulate AI.
The government should actively enable AI.
Its role should include:
Funding national compute infrastructure
Creating public-private AI clusters
Opening non-sensitive government datasets
Supporting Indian language data creation
Providing grants for AI startups
Building national AI benchmarks
Creating AI safety standards
Supporting semiconductor and GPU infrastructure
Making AI affordable for students and startups
Using Indian AI in public services
The government can play the same role in AI that it played in digital public infrastructure.
It can create the platform, standards, incentives, and mission direction.
Role of Indian Private Sector
This mission cannot be achieved by government alone.
India’s largest companies must participate.
Reliance Jio can support cloud, telecom, data centres, and consumer-scale AI deployment.
Tata Group and TCS can support enterprise AI, cloud, infrastructure, and global services.
Infosys, Wipro, HCLTech, and Tech Mahindra can build enterprise AI solutions for the world.
Zoho can help build privacy-first Indian SaaS AI.
Ola Krutrim and Sarvam AI can contribute foundational model research.
Airtel can help with voice AI and connectivity.
Adani, Yotta, E2E Networks, and other infrastructure players can support data centres and compute.
Indian universities can produce talent and research.
Indian startups can build thousands of applications on top of the model.
This should not be a competition between government and private companies.
This should be a national collaboration.
Why This Goal Is Achievable
India has the talent.
India has the developers.
India has the data.
India has the language diversity.
India has the startup ecosystem.
India has the digital public infrastructure experience.
India has the market size.
India has the ambition.
What we need now is coordination.
If government, private companies, universities, startups, and investors come together, India can build a world-class AI model faster than most people imagine.
The AI revolution is still in its early stage.
The winners have not been permanently decided.
India should not enter this race as a customer.
India should enter as a creator.
India should not only use AI.
India should build AI.
India should not only consume foreign models.
India should create models for Bharat and for the world.
Final Thought
The next global superpower will not only be the country with the biggest army or the biggest economy.
It will be the country with the strongest intelligence infrastructure.
AI is that infrastructure.
If India builds its own Claude-class sovereign LLM, we can transform education, healthcare, governance, startups, agriculture, defence, and enterprise productivity at a scale no other country can match.
This is India’s moment.
If the Indian government and India’s biggest private players collaborate seriously, fund boldly, build openly, and execute fast, we can win the AI revolution race.
Not someday.
Starting now.
#IndiaAI #SovereignAI #ArtificialIntelligence #LLM #GenerativeAI #MadeInIndia #DigitalIndia #AIForIndia #BharatAI #IndianStartups #AIRevolution #FutureOfIndia #TechForBharat

6
5
720

Jun 13
Anthropic now lets you build cloud-hosted agents with sandboxed execution, checkpointing, and scoped permissions out of the box. The "how do I deploy my agent" question just got a lot shorter.
helpnetsecurity.com/2026/04/…
5

7/12
$SNDK is a different but related thesis.
It is not an HBM company.
But AI infrastructure does not end at GPU memory.
Training creates data.
Inference creates data.
Retrieval, checkpointing, model storage, and agentic workloads all create persistent data.
1
2
214

For production systems, this implementation is basic. Missing dropout, limited hyperparameter tuning, and lack of checkpointing are noticeable gaps.
github.com/thekingslee/build…
@AbdvllxhMvjxhid @theKingslee
1
10
Javier Hernández retweeted

Jun 11
The Managed Deep Agents runtime supports:
✅ Durable threads
✅ Streaming runs
✅ Checkpointing
✅ Human-in-the-loop workflows
You can also use the API to create agents, update their configuration, create threads, and stream runs from your own product or platform workflow.
6
8
34
4,913



Jun 12
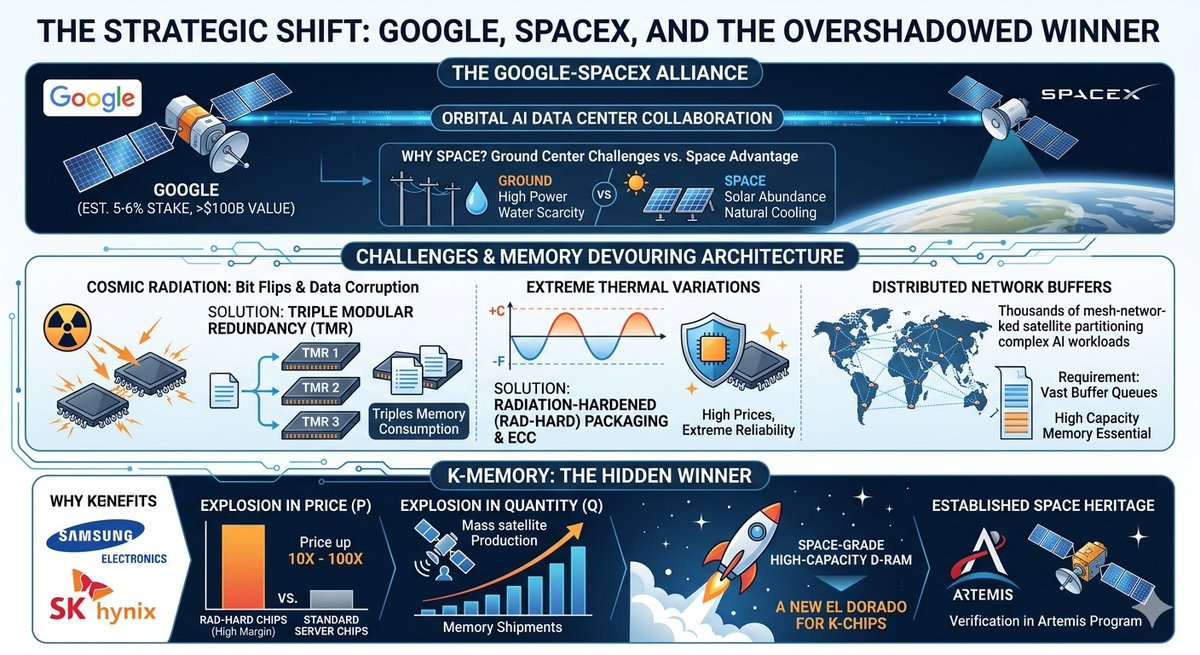
[Google and SpaceX Space Data Center Alliance, The Real Hidden Winner is K-Memory]
Big Tech is officially looking beyond Earth. News that Google, holding an estimated 5 to 6 percent stake in SpaceX, and SpaceX are collaborating to deploy Space-based AI Data Centers in Low Earth Orbit is sending shockwaves through the global tech industry. While space data centers are hailed as the ultimate breakthrough to solve Earth's power grids and cooling water shortages, looking deeper into this orbital shift reveals an unexpected winner poised for a mega jackpot, South Korea’s memory semiconductor giants, Samsung Electronics and SK Hynix.
The extreme environment of space drives a memory devouring architecture. A space data center is not just a terrestrial server strapped to a satellite. Outside the atmosphere lies a cosmic radiation hellscape capable of causing catastrophic Bit Flips. To survive, orbital servers must adopt aggressive redundancy strategies.
First is Triple Modular Redundancy. To prevent data corruption, identical operations are written to three separate memory zones simultaneously, using a majority-vote system to self-correct. This triples memory consumption relative to actual usable capacity.
Second is Aggressive Error Correction. Heavy parity bits and constant snapshot checkpointing permanently occupy massive chunks of memory. Third is Distributed Network Buffers. Thousands of mesh-networked satellites partitioning complex AI workloads require vast buffer queues to manage latency and intermittent connectivity.
This memory-hungry architecture directly translates into an explosion in both Price and Quantity, creating a new El Dorado for K-Chips. Radiation-hardened memory chips engineered with specialized shielding and high-reliability enterprise server architectures command prices up to tens of times higher than standard commercial silicon. Combined with SpaceX’s mass-satellite production capabilities, the 3x memory overhead required for TMR creates an exponential surge in the absolute volume of memory chips needed.
With Korean memory chips already securing space heritage through projects like NASA’s Artemis program, a massive high-margin blue ocean is unfolding. Following the HBM boom, the next frontier is Space-Grade High-Capacity D-RAM. The true fruits of the space race might just be harvested right on the semiconductor lines in South Korea.
#Google #SpaceX #SpaceDataCenter #Samsung #SKHynix #Semiconductor #AI
#구글 #스페이스X #우주데이터센터 #삼성전자 #SK하이닉스 #국제경제 #반도체
1
211

Jun 12
5/6 Manual backfills work when the job is small on a single machine.
But model-backed features over huge multimodal datasets need batching, distributed execution, GPU placement, retries, checkpointing, and reproducibility.
That’s where Geneva, an Enterprise feature engineering package in @lancedb, comes in.
docs.lancedb.com/geneva
1
2
61

🚀 Designing & Training Deep Learning Models for Large-Scale Time-Series Cross-Sectional Prediction
In finance, retail, healthcare & IoT, we deal with massive datasets combining time-series (temporal dynamics) and cross-sectional features (static attributes). Classic models break at scale.
Here's how to build production-grade DL systems.
Architecture Choices:
- Use
Temporal Fusion Transformers (TFT) or Informer for long sequences variable selection.
- Hybrid: LSTM/GRU Attention TabNet-style cross-sectional encoders.
- For ultra-scale: N-BEATS, DeepAR, or modern TimeGPT -style foundation models.
Key Training Challenges & Solutions:
- Scale: Use distributed training (Horovod, DeepSpeed, FSDP). Mixed precision gradient checkpointing.
- Temporal dependencies: Sliding windows, dilated convolutions, or reversible architectures.
- Missing data & irregularity: Impute via SAITS or model directly with masking.
- Concept drift: Online learning continual fine-tuning.
Data Pipeline Tips:
- Feature stores (Feast) for real-time serving.
- Chunked loading with Dask/Ray for TB-scale data.
- Normalization per entity/group robust scaling (QuantileTransformer).
Evaluation & Production:
- Time-based CV, walk-forward validation.
- Metrics: MASE, CRPS, Quantile loss for uncertainty.
- Deploy with ONNX/TensorRT monitoring (drift detection via Alibi).
Building these systems powers accurate forecasting at billions of rows.
What domain are you applying this to? Drop your challenges below 👇
2
58


Jun 12
The node model follows the same logic.
Supervisor Nodes support epoch sealing, checkpointing, and synchronization.
Validator Nodes handle validation, block proposal, and protected transaction processing.
Light Nodes strengthen access, relay, and decentralization.
1
2