Srinivasan Ramasamy retweeted

Strengthening Pan India FFMA 2030 Together: CoDesign Workshop with Fishers, 12/6/26, insightful suggestions to upgrade features to enhance livelihood, safety & resource use. App function in 8 languages, adapted 56 revisions, with community feedback-since 2007 @mssrf @incoismoes



1
1
6

Hardware Software = The future of AI optimization. While kernel design is the new hype, @imec_int AI Labs is uniquely positioned to innovate across both.
Discover our work on kernel codesign & silicon photonics: ailabs.imecai.com/blog.html

1
3
264


Xiaomi's new AI model generates 1,000 tokens per second on standard GPUs.
@OpenAI's GPT-4 isn't close to that throughput at comparable hardware cost.
The method is called model-system codesign — building the model and the inference stack together instead of bolting optimization onto an architecture designed for something else.
Why it matters: real-time AI (live translation, robotics, on-device assistants) has always been throttled by generation speed. 1,000 tokens/sec isn't an incremental improvement. It moves the bottleneck somewhere else entirely.
stork.ai/blog/xiaomis-ai-is-…

4

people have been pointing this out since like jan this year. @cursor_ai does not get enough credit for optimizing their harness so well.
as someone who's built coding agents and done tons of harness engineering, openai does a much better job at model harness codesign vs anthropic
Jun 12

want to point out a few really interesting things here
1. Claude Code is actually the worst performing harness when using the same model, significantly behind opencode and cursor cli
this is the core reason i've been against the LLM companies focusing their business on locking people into their harness
what they are good at is making great models. they suck at making good harness products, just like how power plants won't make the best dishwashers, and how internet providers won't make the best phones
if anthropic wants to do what's best for their users, they should let people use their subscriptions in whatever harness they choose, not locked into claude code alone
2. fable 5 max is only 1pt above gpt 5.5 xhigh (77 vs 76)
this matches my experience so far - fable 5 does have the big model smell and it's pretty good, but it's not a massive jump forward like their marketing suggested, at least not on building software
this is actually alarming for anthropic because it's very unlikely people will want to pay 2x higher cost for the 1pt difference. my speculation would be that in enterprises people will be restricted to adopt fable & mythos only on some mission critical tasks, not used at scale

21

assemble diverse,small teams with specific focus. go back to first principles. only world models. not llms or multimodal. full stack hw sw codesign; lisp fpga arrays;edge to super clusters. funds no limit. total access to any central r&d or testing facility. mission mode.
1
3
165
Bonnie Allan retweeted

Jun 12
🌟🙏🏻🌷 on the mark! Go carefully slowly with #NDIS changes #Codesign #LivedExperience #Nothingaboutuswithoutus. #Disability @AlboMP @Mark_Butler_MP
 dixy
dixy
2
4
4
247
앙냐냥 retweeted

May 22
🎨 Open CoDesign: 프롬프트 하나로 프로토타입을 만드는 오픈소스 AI 디자인 도구
opencoworkai.github.io/open-…
오픈소스 좋은 대안이 여기에 있어요!
Open CoDesign은 프롬프트만으로 랜딩 페이지, 대시보드, 슬라이드 덱, 프라이싱 페이지 등을 생성할 수 있는 로컬 퍼스트 AI 디자인 툴이에요.
디자인, 프롬프트, 설정 모두 로컬 디스크에 저장됩니다. 기본적으로 텔레메트리 없고, 강제 계정 가입 없음..!
여기에 12가지 빌트인 디자인 스킬도 있어요.
대시보드, 랜딩 페이지, 슬라이드 덱, 프라이싱 페이지, 채팅 UI, 달력, 에디토리얼 타이포그래피 등... 👍🏻
코멘트로 부분 수정도 되고, AI 슬라이더로 바로바로 미세조정 가능합니다!
이걸 HTML, PDF, PPTX, ZIP, Markdown 내보내기도 가능해요~
최신 v0.2 에서는 Agentic Design 도입되었는데 각 디자인 세션이 실제 워크스페이스와 연결된 장기 세션으로 동작해요.
한번 또 써보시면 좋아요!
참고로 ChatGPT 구독자는 API 키 없이 로그인만으로 사용 가능해요!
macOS / Windows / Linux 모두 지원해요!



15
69
3,598

Jun 12
>shows math
>it's even cheaper than that in reality due to model cluster codesign
>"NOOOOO research and training hurt wallet"
>ROFL
training money is basically a donation pre 2024 every investor to openAI was clearly told that he will not see a return on his money.
3
119

Jun 12
I'm on an Apple Silicon Mac running macOS 27 beta 1 (Apple Intelligence enabled) with a local LLM serving an OpenAI-compatible API via llama.cpp/Ollama. Build me an "on-device reflex layer":
A Swift app exposing Apple's Foundation Models framework as an OpenAI-compatible server on localhost (/v1/chat/completions, /v1/models, /health, /stats). Compile with swiftc directly targeting macOS 27 (SwiftPM may be broken under Command Line Tools), assemble a .app bundle with usage strings, ad-hoc codesign with a stable bundle identifier so TCC permissions persist, bind explicitly to 127.0.0.1 (NWListener defaults to IPv6), and run it as a LaunchAgent.
A cascade model id "auto": try the on-device model first, auto-escalate to my local LLM when the prompt exceeds the 4096-token context, the model errors or guardrail-refuses, or the output fails validation (empty, or invalid JSON when JSON was requested). Log escalations as JSONL training pairs.
A device-agent model id: the on-device model parses requests into a JSON action protocol (don't use @Generable macros — they need full Xcode) and Swift executes via EventKit (create/list calendar events reminders), Contacts, and the shortcuts CLI. Inject a precomputed weekday→date table into the instructions — small models fail at calendar math, give them the answers.
Vision in 3 tiers: Vision-framework OCR first for text-heavy images (it's digit-exact, generative vision isn't), native ImageAttachment multimodal second, escalate to my local vision model as the floor.
Keep the model warm with session.prewarm() every 4 minutes — macOS evicts it when idle.
Wire my agent's lightweight tasks (triage, classification, titles, casual replies) to the bridge and keep heavy reasoning on my local LLM.
Verify each piece end-to-end with curl before moving on, and clean up any test calendar entries you create.
That prompt encodes every pothole we hit so you don't have to. Have fun. 🍏🤝🦙
1
67

Jun 12
1. Locked Computer Use runtime failure:
Computer Use works while the Mac is unlocked. After locking the Mac, list_apps still works, which means the helper is reachable, but get_app_state("Finder") hangs and times out after 120 seconds. So the locked-screen app/window reading path is failing.
2. Install / authorization verification issue:
The lock-screen component appears to be in an inconsistent state. The installer/status check has at times reported not-installed even though the SecurityAgent plugin bundle exists, and the installed authorization plugin fails codesign verification with “invalid signature.” So the system may not be reliably proving that the lock-screen authorization component is correctly installed, trusted, or activated.
1
1
86

Jun 12
Do you think routing transformer can come back we codesign it? Or parts in msa already
1
7
2,026

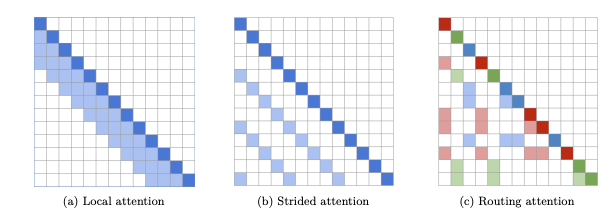
Nice to see MiniMax and others pushing content based sparse attention forward. Back in 2020 the field was exploding with several efficient attention variants:
- Local/Sliding window attention
- Fixed sparsity patterns
- Strided attention
- Recurrence ( T-XL, compressive transformers)
- Chunked attention
- Linear attention and SSMs
The right prior which has stood the test of time is a combination of:
a) local attention for modeling local context and
b) a top-k content based sparsity to route queries to the most relevant keys (blocks of keys).
What has changed in the last 6 years is better hardware-algorithm codesign.
Jun 11

Hey everyone — our high-performance MSA kernel library is now open-source. The M3 weights are expected to drop this Friday. Thanks for waiting!
Github: github.com/MiniMax-AI/MSA
Paper:github.com/MiniMax-AI/MSA/bl…

4
13
120
21,839

Jun 11
that being said their engineering is still top notch as their throughput is strong. But it can always be stronger through codesign with the arch and devices you run on.
2
5
161

Jun 11
I think they’re relevant, most importantly the partners attemtping to build the plane think they’re relevant.
All of this comes back to my main point, France should just do their own thing, make their own design choices, and the results are pretty good
But not codesign
12
