
Jun 13
I really like the timeline you put from ReAct to CodeAct to Subagents to RLM.. we just formalized RAH and evaluated them against other LM-based approaches. Check it out! arxiv.org/abs/2606.13643
4
85

Jun 12
Voyager, MemGPT, LLMCompiler, CodeAct, Rubric-as-Rewards, soon to be RLMs
4
185

Jun 11
Layer 3: ReAct CodeAct. Structured reasoning loops, sandboxed code execution. Agents that think before they act.
Layer 4: Multi-agent orchestration. Workflow scheduling, error handling, coordination.
1
8

Jun 11
Microsoft just open-sourced FIDES — a deterministic security layer for AI agents that makes prompt injection mathematically impossible instead of just harder.
Prompt injection is #1 on the OWASP LLM Top 10. Most agents in production defend against it with a system prompt or a hand-rolled allowlist. Neither is deterministic. Both fail silently the day someone slips a line into an issue body, an email, or a tool result.
FIDES (Flow Integrity Deterministic Enforcement System) is different. Every piece of content carries an integrity label (trusted/untrusted) and a confidentiality label (public/private). Labels propagate automatically through the agent's entire execution graph. If untrusted content tries to reach a privileged action, the middleware blocks it at the framework level — not the prompt level.
This is part of Microsoft Agent Framework (MAF), which hit 1.0 GA on April 2, 2026. BUILD 2026 just shipped Agent Harness, Hosted Agents, and CodeAct support.
The stack: chat clients, tools, MCP integrations, context providers, middleware, multi-step workflows. Same APIs across .NET and Python. All open-source.
Why this matters: agent security has been a game of whack-a-mole. FIDES makes it structural. If you're building agents for production, this is the first framework that treats security as a first-class middleware concern rather than a prompt engineering problem.
devblogs.microsoft.com/agent…
26

Jun 11
Microsoft Agent Framework at BUILD 2026: Agent Harness, Hosted Agents, CodeAct, and more | Microsoft Agent Framework share.google/3Z4c6g6Pd0YQ8tC…
4

Jun 9
The slowest part of your agent is not the tools. It is the turns.
Microsoft just shipped CodeAct at BUILD 2026 (2026-06-03). Instead of the model emitting one JSON tool-call per step, it writes ONE Python block that calls many tools, loops, and parses results inline in a sandbox.
Why it saves so much: every JSON tool-call replays the whole growing conversation to the model. Step 8 re-pays for steps 1 through 7. One code block kills that re-read.
The numbers, same task:
- Latency: 27.81s down to 13.23s (52.4% faster)
- Tokens: 6,890 down to 2,489 (63.9% fewer)
When it wins:
- Many sequential or looping tool calls
- Data transformed between calls
- Fan-out to N tools, then aggregate
When it does not pay:
- Single-tool, single-shot tasks (the sandbox overhead never amortizes)
The non-negotiable: run each call in a real per-call sandbox (Microsoft uses Hyperlight micro-VMs). Never execute model code in your app process.
The caveat: agent-framework-hyperlight is alpha, Python only, Linux and Windows. Trial it on a non-critical path.
DM me CODEACT for the JSON-vs-CodeAct decision checklist plus the sandbox setup card.
Follow for daily insights - where blockchain meets AI, one satisfying swipe at a time.
#AIAgents #AgenticAI #CodeAct #LLM #AIEngineering #MachineLearning #Python #MicrosoftBuild #AgentFramework #DevTools #AIArchitecture #PromptEngineering #ToolCalling #LLMOps #SoftwareEngineering #AIInfra #BuildInPublic
1
94


800× menos custo de API. 4× menos latência. E apenas 3,2 pontos percentuais abaixo do melhor modelo cloud disponível.
O OpenJarvis acabou de tornar a dependência de nuvem para IA pessoal um problema opcional.
O framework foi publicado por pesquisadores de Stanford e Lambda Labs. Não é um modelo — é uma arquitetura que compõe qualquer modelo suportado com uma stack configurável de agentes, memória e aprendizado, tudo rodando inteiramente no dispositivo.
𝗢 𝗾𝘂𝗲 𝗺𝘂𝗱𝗮 𝗮𝗾𝘂𝗶
A maioria dos frameworks de agentes assume que você vai chamar uma API cloud em cada query. Latência de rede, custo por token, dados saindo da sua máquina — tudo aceito como custo de operação.
O OpenJarvis inverte essa premissa.
A pesquisa por trás do framework parte de um dado concreto: modelos locais já lidam com 88,7% das queries de chat e raciocínio com latência interativa. Esse número vem do estudo anterior da equipe, o Intelligence Per Watt, que também registrou uma melhoria de 5,3× em eficiência de inteligência entre 2023 e 2025.
O problema nunca foi o modelo local. Foi a falta de uma stack que o fizesse operar com a mesma qualidade sistêmica de um setup cloud.
𝗢𝘀 𝗰𝗶𝗻𝗰𝗼 𝗽𝗿𝗶𝗺𝗶𝘁𝗶𝘃𝗼𝘀
O OpenJarvis decompõe um sistema de IA pessoal em cinco camadas tipadas, compostas por um único objeto de configuração declarativo — um arquivo TOML chamado spec:
- 𝗜𝗻𝘁𝗲𝗹𝗹𝗶𝗴𝗲𝗻𝗰𝗲 — modelo, pesos, parâmetros de geração, formato de quantização.
- 𝗘𝗻𝗴𝗶𝗻𝗲 — runtime de inferência (Ollama, vLLM, SGLang, entre outros), batching, configurações de KV-cache.
- 𝗔𝗴𝗲𝗻𝘁𝘀 — loop de raciocínio (ReAct ou CodeAct), system prompts, política de uso de ferramentas.
- 𝗧𝗼𝗼𝗹𝘀 & 𝗠𝗲𝗺𝗼𝗿𝘆 — interfaces externas, 25 conectores de dados, 32 canais de mensagem, suporte nativo a MCP, backends de memória intercambiáveis.
- 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 — otimizador que atualiza a spec a partir de traces. Aceita LoRA, DSPy, GEPA ou busca de spec guiada por LLM.
Cada primitivo é independentemente substituível. Dois specs podem compartilhar a mesma configuração de agente e ferramenta e diferir apenas no modelo e engine — o mesmo comportamento roda num Mac Mini e numa workstation sem reescrever um prompt.
𝗔 𝗽𝗮𝗿𝘁𝗲 𝘁𝗲́𝗰𝗻𝗶𝗰𝗮 𝗾𝘂𝗲 𝗿𝗲𝗮𝗹𝗺𝗲𝗻𝘁𝗲 𝗶𝗺𝗽𝗼𝗿𝘁𝗮
O diferencial não é a modularidade em si. É o que chamam de LLM-guided spec search.
A ideia: um modelo cloud frontier atua como professor na fase de busca. Ele lê traces, diagnostica clusters de falha e propõe edições coordenadas across Intelligence, Engine, Agents e Tools & Memory. Uma edição só é aceita se melhora o cluster alvo sem causar regressões relevantes nas demais métricas — o paper chama isso de gate, com tolerância padrão de 1%.
O spec otimizado roda inteiramente on-device na inferência. Zero chamadas cloud depois da otimização.
O custo amortizado do professor cai abaixo de US$ 0,001 por query em seis meses a 100 queries por dia.
Por que isso importa? Otimizadores anteriores — GEPA, DSPy, LoRA — trabalham um primitivo por vez. Otimizadores de prompt isolados recuperam cerca de 5 pontos percentuais do gap cloud-local. A busca guiada por LLM recupera 13 a 32 pp porque edita múltiplos primitivos de forma coordenada, a um custo de otimização 7 a 11× menor que os baselines de primitivo único.
𝗢𝘀 𝗻𝘂́𝗺𝗲𝗿𝗼𝘀 𝗱𝗼𝘀 𝗯𝗲𝗻𝗰𝗵𝗺𝗮𝗿𝗸𝘀
O framework foi avaliado em 8 benchmarks cobrindo 508 tarefas — tool calling, workflows agentic, coding, atendimento ao cliente, pesquisa profunda.
O teste de portabilidade revela o problema que o OpenJarvis resolve: substituir o modelo cloud por Qwen3.5-9B em frameworks existentes (OpenClaw, Hermes Agent) derruba a acurácia em 25 a 39 pp. Com o mesmo modelo sob um spec OpenJarvis, a queda residual encolhe para 5,6 a 16,5 pp — recuperando 56 a 77% da perda de portabilidade.
O melhor modelo local testado, Qwen3.5-122B, chega a 80,3% de acurácia média versus 83,5% do Claude Opus 4.6 — gap de 3,2 pp. Em 4 dos 8 benchmarks, os specs locais igualam ou superam o cloud: ToolCall-15, PinchBench, LiveCodeBench e τ-Bench V2.
O Qwen3.5-122B entrega seus 80,3% a aproximadamente um milésimo de centavo por query, contra US$ 0,009 por query do Claude Opus 4.6 — vantagem de custo marginal de ~800×.
𝗢 𝗾𝘂𝗲 𝗷𝗮́ 𝗳𝘂𝗻𝗰𝗶𝗼𝗻𝗮 𝗻𝗮 𝗽𝗿𝗮́𝘁𝗶𝗰𝗮
Instalação é um comando só (macOS, Linux ou WSL2).
O instalador provisiona o ambiente, Ollama e um modelo starter em cerca de três minutos. Presets prontos cobrem briefings matinais com TTS, pesquisa multi-hop com citações, agente de código com acesso a shell, e agente com estado em schedule.
O framework já conecta a 25 fontes de dados (Gmail, Calendar, iMessage, Notion, Obsidian, Slack, GitHub) e expõe agentes por 32 canais de mensagem (WhatsApp, Telegram, Discord, iMessage, Signal). Skills importáveis de catálogos externos — cerca de 150 do Hermes Agent e cerca de 13.700 da comunidade OpenClaw — seguem a especificação agentskills.io.
𝗢 𝗾𝘂𝗲 𝗶𝘀𝘀𝗼 𝗱𝗲𝘀𝗹𝗼𝗰𝗮
A lógica atual de IA pessoal é pay-per-thought. Cada query tem custo variável, latência de rede e dados transitando por servidores externos. O modelo de negócio dos grandes provedores depende disso.
O OpenJarvis não é um produto competindo com o Claude ou o GPT. É uma infraestrutura que torna a escolha entre cloud e local uma decisão racional baseada em custo-benefício, não uma imposição técnica.
Quando 88,7% das queries do dia a dia já rodam bem localmente, e a pesquisa mostra que um spec bem otimizado chega a 3,2 pp do topo do cloud — a pergunta muda de "será que modelo local resolve?" para "por que ainda estou pagando por query nessas tarefas?"
A resposta, cada vez mais, é: conveniência. E conveniência tem prazo de validade quando a alternativa custa 800× menos e responde 4× mais rápido.

5
653


Jun 2
That’s what we are thinking.
It’s codeact time now!
Jun 1

Introducing Search as Code, our new search architecture for AI agents.
It writes Python that calls our search stack directly, instead of looping through function calls one at a time.
Available in the Perplexity Agent API, and now default in Computer.
research.perplexity.ai/artic…

3
10
1,816

What if memory retrieval weren't a pipeline at all, but a program the agent writes on the spot?
In Scroll, the agent's history lives in the environment as an append-only log object — the single source of truth, no longer bounded by the context window. The agent reads it with Python in a CodeAct loop, the way it reads a file or queries a DB — so retrieval becomes whatever that code computes, not something fixed in advance. (inspired by @a1zhang's RLM Anthropic's managed agents.)
Early results, but encouraging:
📊 91.8% LongMemEval_s @ 0.8–2.8K tok/query
📊 0.950 vs 0.683 (compaction) on business-analytics probes over a 180-day vending-machine sim — answers it has to compute from months of accumulated history
Blog: niceirene.github.io/posts/Sc…
3
88

May 31
Thanks for the historical context! I slightly disagree on the interpretation though, I think the TerminalTool is essentially still CodeAct. It gives the agent the ability to write code and perform tasks which is the essence of CodeAct.
1
4
1,091

Great read. @OpenHandsDev had CodeAct, added tool calling to it at the end of 2024, and gave up the CodeAct side in 2025.
Usability was a concern, and also performance, because LLMs post-trained with tool calling got way too good comparatively
May 31

a cute diagram on the small but important differences that I think is easy to understand :) it also brings back the debate of CodeAct vs. ReAct, which ill expand on below:
btw, it's worth mentioning for those who say RLMs were a "common engineering trick" in industry pre-October 2025, I want to be clear that doing RLM-style things at the time (and even now, in May 2026) was a pretty poor design decision for a production agent stack and likely was just worse than doing standard tool calls (although the more probable answer is that they were implementing something different anyways). it's kind of a moot point I haven't really interacted much with because it's a bit of a cop out "I can't show you, but it existed, trust me bro", but I do think it's worth talking about a bit
RLMs, like most harness designs we've been interested in since 2022, are super simple. but like the diagram below points out, it changes quite a bit about what we want the language models themselves to be doing (both conditioning on, and outputting) to get them to work well. as we've seen with the latest products in AI, model-harness codesign is extremely important
it's why something like having the community accept ideas like ReAct is a big deal, because while the idea is simple, whether we choose to accept ReAct as the standard has ripple effects on the models and infra we design in the future. it's kind of like the whole MITO vs. TITO debate going on now; they're both "easy to implement", but what we as a community accept has long-term effects and potentially technical debt on the infra we build in the future
one of the goals of this entire "programmatic sub-agent and tool-calling" discourse that RLMs push for dates back to the ReAct vs. CodeAct debate and whether tool calls are JSON tool calls or functions in code. CodeAct kind of lost out to ReAct in 2024-2026, and for the past few years a lot of harnesses we've built out the models underpinning them assume the JSON-like tool calling structure. if we were to continue along this route in the limit as a community, RLMs would basically never really work despite the idea being so simple
in this sense, RLMs are pushing for the CodeAct-style "programmatic tool calling" (PTC), but with an emphasis on context as an object and sub-calls as a function that always exists. the paper itself shows that this style of workflow has sparks of potential on frontier models doing long-context tasks, but it's why we've been so interested in pushing for this style of harness
so yeah, deferring to your LM to make decisions in code with sub-calls and context offloading is a simple idea. if you implemented this in your production agents, im sorry, but it probably wasn't and still isn't a good idea just yet. it takes time, and formalizing the idea is important to justifying why we should push further in this direction. there's a lot of work to be done, both on the infra side (guardrails, sandboxing, training, etc.) and the model training side (getting a model that actually is good at this style of thinking!!!) that are completely non-trivial and will take a lot of time to get right.
1
2
15
6,637

May 31
It still baffles me why CodeAct lost to ReAct… would easily top the list of the costliest mistake in the field’s history…
All those monstrous API JSON dumped into context and the current MCP design…
CodeAct/RLM clearly is more expressive and elegant as primitive.
But what do I know… code as data is clearly good idea but Lisp-family languages are rare breed now.
Some time the history of computing kinda reads like a tragedy
2
8
580

May 31
a cute diagram on the small but important differences that I think is easy to understand :) it also brings back the debate of CodeAct vs. ReAct, which ill expand on below:
btw, it's worth mentioning for those who say RLMs were a "common engineering trick" in industry pre-October 2025, I want to be clear that doing RLM-style things at the time (and even now, in May 2026) was a pretty poor design decision for a production agent stack and likely was just worse than doing standard tool calls (although the more probable answer is that they were implementing something different anyways). it's kind of a moot point I haven't really interacted much with because it's a bit of a cop out "I can't show you, but it existed, trust me bro", but I do think it's worth talking about a bit
RLMs, like most harness designs we've been interested in since 2022, are super simple. but like the diagram below points out, it changes quite a bit about what we want the language models themselves to be doing (both conditioning on, and outputting) to get them to work well. as we've seen with the latest products in AI, model-harness codesign is extremely important
it's why something like having the community accept ideas like ReAct is a big deal, because while the idea is simple, whether we choose to accept ReAct as the standard has ripple effects on the models and infra we design in the future. it's kind of like the whole MITO vs. TITO debate going on now; they're both "easy to implement", but what we as a community accept has long-term effects and potentially technical debt on the infra we build in the future
one of the goals of this entire "programmatic sub-agent and tool-calling" discourse that RLMs push for dates back to the ReAct vs. CodeAct debate and whether tool calls are JSON tool calls or functions in code. CodeAct kind of lost out to ReAct in 2024-2026, and for the past few years a lot of harnesses we've built out the models underpinning them assume the JSON-like tool calling structure. if we were to continue along this route in the limit as a community, RLMs would basically never really work despite the idea being so simple
in this sense, RLMs are pushing for the CodeAct-style "programmatic tool calling" (PTC), but with an emphasis on context as an object and sub-calls as a function that always exists. the paper itself shows that this style of workflow has sparks of potential on frontier models doing long-context tasks, but it's why we've been so interested in pushing for this style of harness
so yeah, deferring to your LM to make decisions in code with sub-calls and context offloading is a simple idea. if you implemented this in your production agents, im sorry, but it probably wasn't and still isn't a good idea just yet. it takes time, and formalizing the idea is important to justifying why we should push further in this direction. there's a lot of work to be done, both on the infra side (guardrails, sandboxing, training, etc.) and the model training side (getting a model that actually is good at this style of thinking!!!) that are completely non-trivial and will take a lot of time to get right.
May 30

My contribution to the RLM discourse: LLMs are eating their harness.
Currently, the “agentic paradigm” involves running an LLM in a tool-calling harness like so:
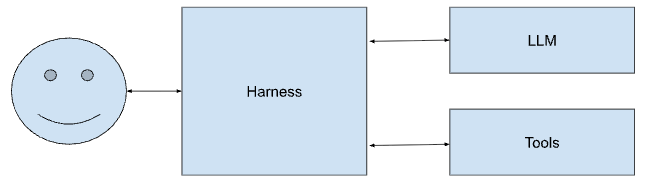
7
14
226
31,456

Which local LLM best drives an agent?
I built a benchmark for pairing models with Hermes Agent (@NousResearch) - a CodeAct agent that writes Python to call its tools, not JSON function calls.
4 models, RTX 5090, tested under Hermes's real system prompt.
~~ here is the final leaderboard:
🥇 Qwopus-18B — 92.7
🥈 Qwen3.6-27B — 92.4
🥉 Nemotron-Cascade-2-30B — 90.5
4️⃣ Hermes-4.3-36B — 84.3
~~ no model wins all four axes:
- Qwen 27B = perfect multi-step loops instruction-following, but weakest long-context recall (~70%)
- Nemotron Qwopus = flawless long-context (100%) but worst at multi-step (50%)
- Hermes 36B = solid, but OOMs at 64K context on 32GB → that 0 tanks its score
the "best agent model" genuinely depends on your workload.
~~ methodology
most "function-calling" benchmarks score JSON tool calls. Hermes is code-as-action, which means that the model writes Python.
I tested that, under the real ~3.5K-token agent prompt.
19
5
60
5,002
May 30
cool, you can triple down on this and that's fine, but in line with your own phrase "just trying to have a net-positive effect on the world" let's have an actual discussion about this instead of ragebaiting on my feed. again, whether anthropic was inspired or not is all speculative and I agree with you I can't make that claim.
> the authors themselves decided to grandly establish a new label 'RLM' — for LLMs that are prompted with big text files search/call tools
it's ironic because you somehow still don't get it despite you genuinely being right that it's a super simple concept. I'm not masking the fact that it's a simple concept either, it's been stated countless times in my own writing. the paper itself, if you've read it, is about experimentally why such a system is useful and how out-of-the-box it does very well on long context tasks. and by the way, Claude Code could handle big text files with search / call tools before dynamic workflows, so I'm not really sure what your point is.
it's code. it's giving an LLM unfiltered access to code where sub-LLM calls are available as functions in code, and everything, including the prompt, is an object in code. there's a one sentence summary of how simple it is, you could've filled that into your monologue instead. you can also call it "CodeAct with sub-LLM calls and explicit context offloading" if that makes you happy, it's even ablated in this way in the paper
and by the way, the naming comes from the fact that such a system lends itself well to acting as a "language model" around neural LMs calling themselves. it was originally meant to be treated as a "language model", that centers around using sub-calling at arbitrary levels of recursion to handle arbitrarily long tasks. you can hate the name, but don't act like "naming" formalizations of concepts isn't normal in both academia and industry. are you going to throw a fit at anthropic for calling their feature "dynamic workflows"?
> except for the subject of concern is, i kid you not, just 'treating long prompts as an environment and letting the LLM programmatically search, split up, and call itself over snippets of the prompt'
...and?
Chain-of-thought is just asking the LM to think before it acts. yet the paper was insightful in its experiments and showcasing that it works
ReAct is just applying CoT and saying "act" to a for loop. same deal.
CodeAct is just making code the only tool for an LM and implementing all tools in code. again, same deal.
GRPO is just PPO but with shittier estimates.
there's a giant list of industry and academic papers that are of this form, don't act like this is a bad thing or out of place. I'm not implying that RLMs are as impactful as any of these ideas, but you can at least acknowledge prior coding agents are clearly not RLMs and cannot perform the same set of actions, but dynamic workflows can. it's a simple idea, and it seems to work in many applications
> and they are receiving the attention that comes with that declaration
LMAO bro it's you and a guy who embarrassingly said RLMs claimed to invent sub-agents. it's totally fine if you just don't like the idea and think it's useless and I wouldn't have responded otherwise, but of course I'm going to respond if you reduce it down to the paper is saying nothing
2
63
1,914

May 29
to me, @AnthropicAI's description of this feature seems to be much closer to the original DisCIPL framework than the multi-step notebook-style orchestration of CodeAct or RLMs... hence the cheeky tweet
1
3
218
