
Day 4/30 of LLM Inference
Today's focus: Batching - how we stop wasting GPU cycles
Yesterday we covered KV Cache. Today is about how we serve multiple users without burning money.
The problem with serving one request at a time:
A single inference request rarely saturates your GPU. The GPU is sitting mostly idle between requests. You're paying for a Ferrari and driving it in a school zone.
What batching does:
Instead of processing one request at a time, we group multiple requests together and run them through the model in a single forward pass.
More requests per forward pass = better GPU utilization = lower cost per token.
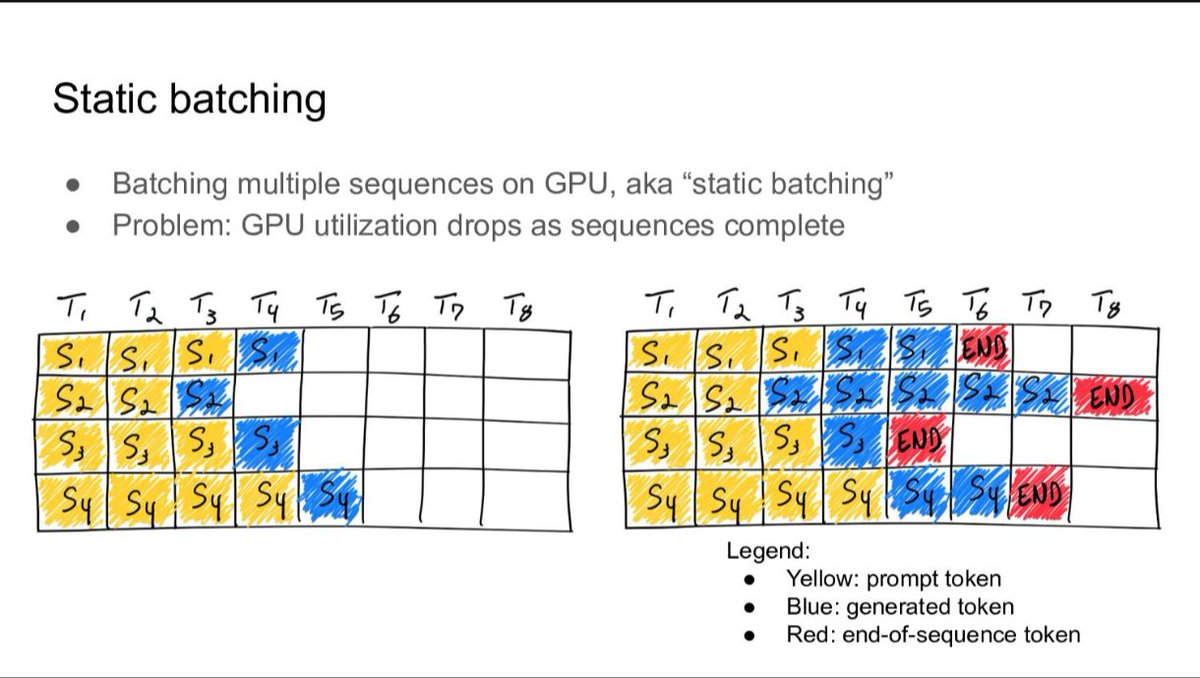
Static batching:
Oldest approach. Wait until you have N requests then process them together. Simple but painful. Requests that finish early sit idle waiting for the slowest one in the batch to complete. Wasted compute.
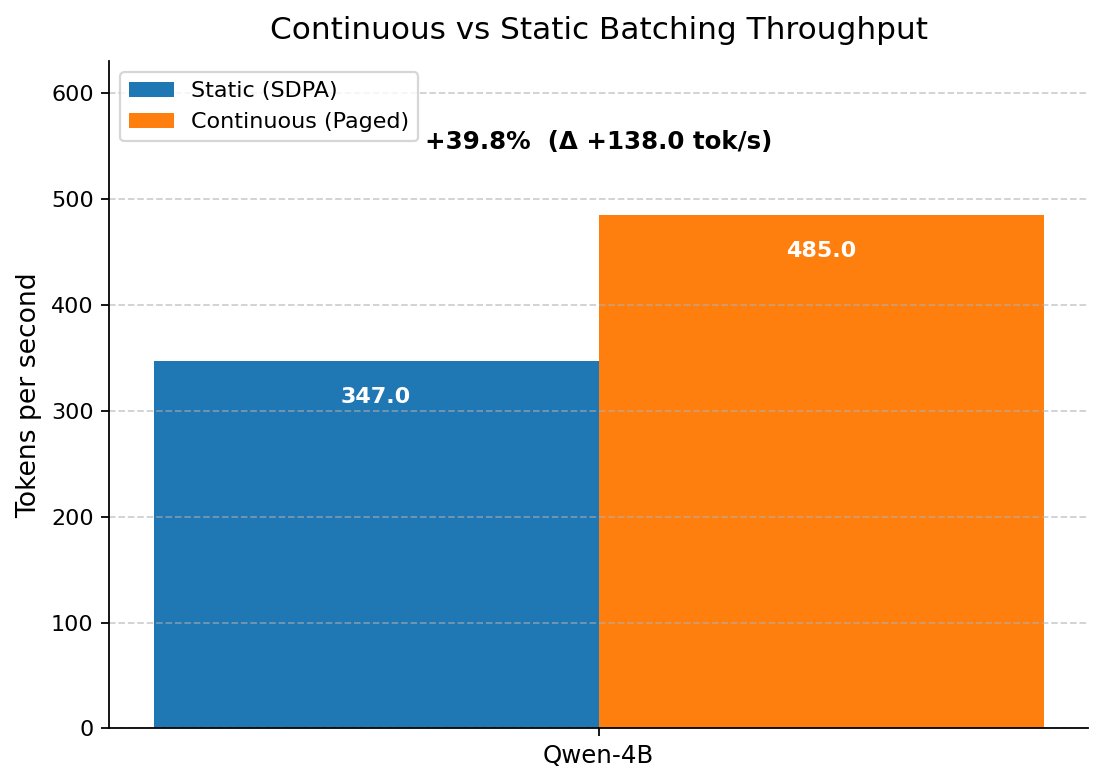
Continuous batching:
The real unlock. Instead of waiting for the entire batch to finish, new requests are inserted into the batch the moment a slot opens up.
No waiting. No idle slots. Near constant GPU utilization.
This is what production inference servers like vLLM use under the hood today.
The tradeoffs:
→ Larger batches = higher throughput but higher latency per request
→ Smaller batches = lower latency but underutilized GPU
→ Finding the right batch size is a tuning problem not a solved one
Throughput and latency are always in tension. How you batch determines which side you optimize for.
Day 5 tomorrow: PagedAttention and how vLLM changed everything 🚀
#LLMInference #Batching #ContinuousBatching #MachineLearning #GenAI #GPU #LLM #AIEngineering #MLOps #vLLM



Day 3/30 of LLM Inference
Today's focus: KV Cache - why it exists and what it actually does
Yesterday we covered prefill vs decoding. Today is about the thing that makes decoding not completely terrible.
The problem without KV Cache:
Every time the model generates a new token, it would need to recompute attention over every single previous token from scratch. For a 2000 token context, that's 2000 recomputations per new token. Pure waste.
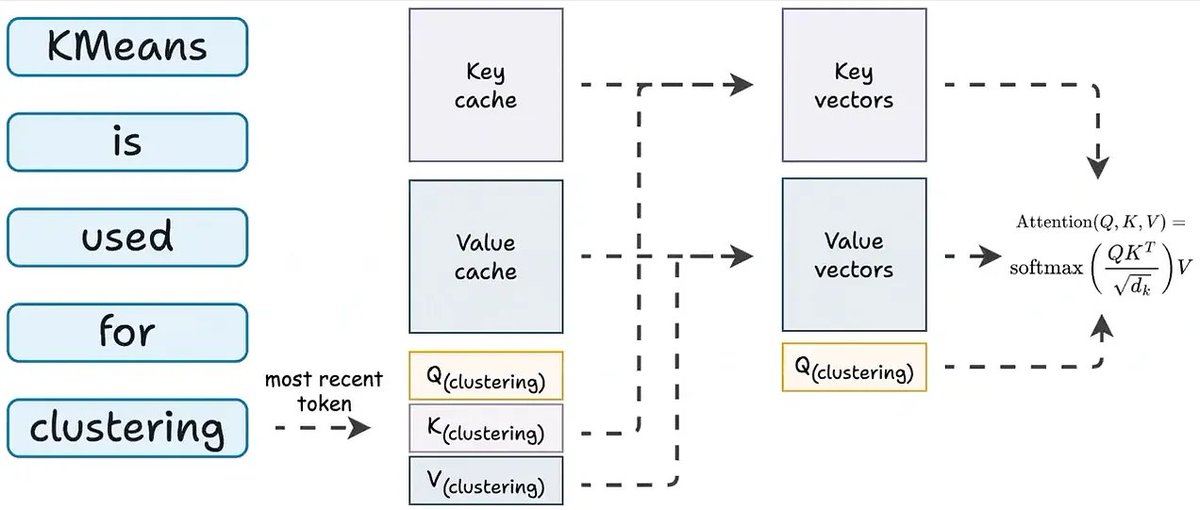
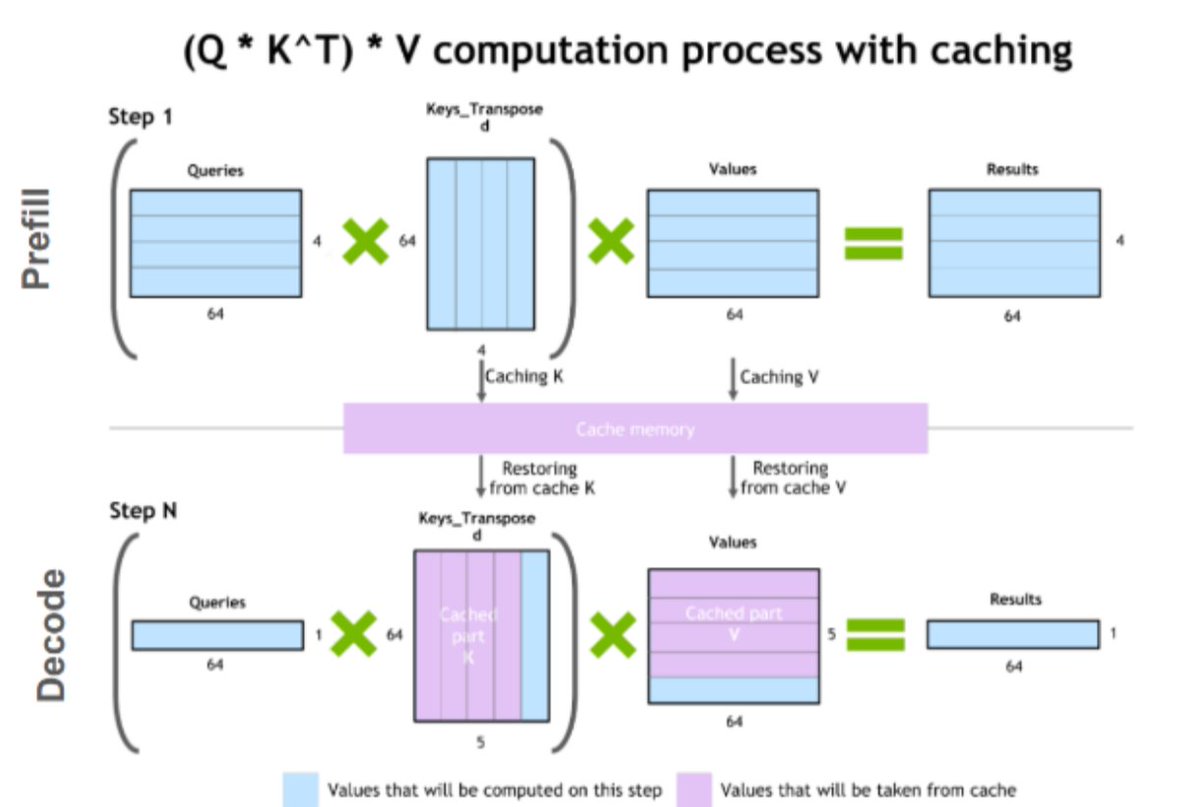
What KV Cache does:
During prefill, the model computes Key and Value matrices for every token in your prompt. Instead of throwing them away, we store them in GPU memory.
During decoding, each new token only computes its own K and V, then reuses everything already cached.
No recomputation. Just a memory lookup.
The tradeoff:
KV Cache trades compute for memory. The cache grows with every new token generated. For long contexts and large batches this blows up fast.
This is exactly why:
→ Context length is expensive
→ Batch size has limits
→ vLLM's PagedAttention was a big deal (Day 5)
KV Cache is the single most important optimization in LLM inference today. Everything else builds on top of it.
Day 4 tomorrow: Batching and throughput 📦
#LLMInference #KVCache #MachineLearning #GenAI #GPU #LLM #AIEngineering #MLOps #Transformers


1
1
1
127

22 Jun 2023
📢 Must Read! how continuous batching can enable 23x throughput in LLM inference while reducing p50 latency! 🚀🔬 #LLM #inference #continuousbatching #GPU #AI
anyscale.com/blog/continuous… cc: @edacih

2
92