
Mar 24
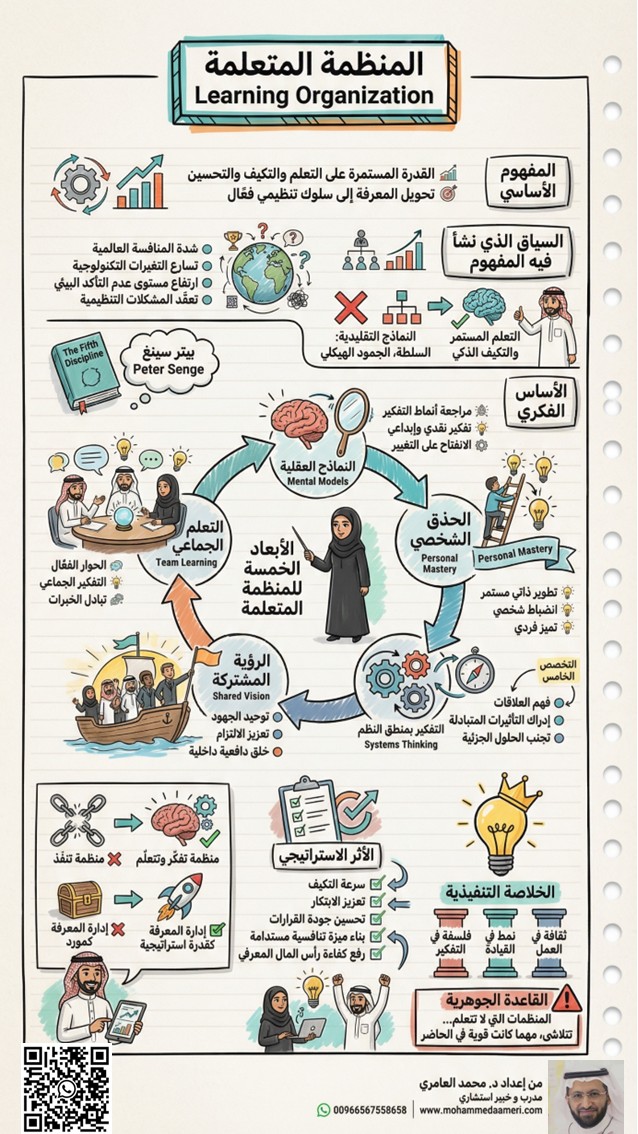
🚀 المنظمة المتعلمة كأحد الاتجاهات والممارسات المعاصرة والمستقبلية في الإدارة
Learning Organization
🎯 المفهوم الأساسي (Core Concept)
تشير المنظمة المتعلمة (Learning Organization) إلى:
المنظمة التي تمتلك القدرة المستمرة على التعلم، والتكيف، والتحسين، من خلال تحويل المعرفة إلى سلوك تنظيمي فعّال ينعكس مباشرة على الأداء والنتائج.
💡 الفكرة المحورية:
الميزة التنافسية لم تعد في ما تملكه المنظمة… بل في سرعة تعلمها.
🌍 السياق الذي نشأ فيه المفهوم
ظهر هذا المفهوم استجابة لتحولات بيئة الأعمال المعاصرة، والتي تتسم بـ:
• شدة المنافسة العالمية
• تسارع التغيرات التكنولوجية
• ارتفاع مستوى عدم التأكد (Uncertainty)
• تعقّد المشكلات التنظيمية
📌 لذلك لم يعد ممكنًا الاعتماد على النماذج التقليدية القائمة على:
❌ السلطة الصارمة
❌ الجمود الهيكلي
❌ تقسيم العمل الضيق
بل أصبح النجاح مرهونًا بـ:
✔ التعلم المستمر
✔ التكيف الذكي
✔ الابتكار المؤسسي
🧠 الأساس الفكري للمنظمة المتعلمة
يُعد Peter Senge من أبرز المنظرين لهذا المفهوم، من خلال كتابه:
The Fifth Discipline
وقد حدّد خمسة أبعاد تمثل جوهر المنظمة المتعلمة.
🔑 الأبعاد الخمسة للمنظمة المتعلمة
1- النماذج العقلية
Mental Models
تشير إلى الافتراضات والتصورات الذهنية التي تحكم طريقة تفكير الأفراد.
📌 التوجه المطلوب:
• مراجعة القناعات التقليدية
• تبني التفكير النقدي
• الانفتاح على التغيير
💡 المشكلة ليست في الواقع… بل في الطريقة التي نراه بها.
2- الحذق الشخصي
Personal Mastery
يعني قدرة الفرد على تطوير ذاته بشكل مستمر.
📌 يتضمن:
• التعلم الذاتي
• الانضباط الشخصي
• السعي نحو التميز
💡 المنظمة لا تتعلم… إذا لم يتعلم أفرادها أولًا.
3- التفكير بمنطق النظم
Systems Thinking
يمثل القدرة على فهم المنظمة كمنظومة مترابطة.
📌 أهميته:
• إدراك العلاقات بين الأجزاء
• فهم التأثيرات المتبادلة
• تجنب الحلول الجزئية
💡 هذا هو "العقل" الذي يربط كل الأبعاد.
4- الرؤية المشتركة
Shared Vision
تعني وجود تصور جماعي واضح للمستقبل.
📌 أثرها:
• توحيد الجهود
• تعزيز الالتزام
• خلق دافعية داخلية
💡 الناس لا يعملون بفعالية… إلا إذا آمنوا بالوجهة.
5- التعلم الجماعي
Team Learning
يشير إلى قدرة الفرق على التعلم المشترك.
📌 يتحقق عبر:
• الحوار الفعّال
• التفكير الجماعي
• تبادل المعرفة
💡 الفرق الذكية لا تجمع المعرفة فقط… بل تولّد معرفة جديدة.
🔍 التحليل الإداري العميق (Deep Insight)
المنظمة المتعلمة تمثل تحولًا جذريًا في الفكر الإداري:
التحول الأول
❌ من: منظمة تنفّذ
✔ إلى: منظمة تفكّر وتتعلم
التحول الثاني
❌ من: المعرفة كمورد
✔ إلى: المعرفة كقدرة استراتيجية
التحول الثالث
❌ من: رد الفعل
✔ إلى: الاستباق والتعلم المستمر
💡 الرسالة العميقة:
المنظمة التي تتعلم أسرع… تتفوق أسرع.
📈 الأثر الاستراتيجي للمنظمة المتعلمة
تطبيق هذا المفهوم يؤدي إلى:
✔ سرعة التكيف مع التغيرات
✔ تعزيز الابتكار والإبداع
✔ تحسين جودة القرارات
✔ بناء ميزة تنافسية مستدامة
✔ تعظيم قيمة رأس المال المعرفي
🧭 العلاقة مع الاتجاهات الحديثة
المنظمة المتعلمة تتكامل مع:
• إدارة المعرفة (Knowledge Management)
• التميز المؤسسي (Excellence)
• إدارة الجودة الشاملة (TQM)
• القيادة التحويلية (Transformational Leadership)
💡 الترابط:
لا يوجد تعلم بدون معرفة… ولا معرفة بدون ثقافة.
🎯 الخلاصة التنفيذية (Executive Summary)
المنظمة المتعلمة ليست:
نظام تدريب ❌
برنامج تطوير ❌
بل هي:
✔ فلسفة تفكير
✔ أسلوب قيادة
✔ ثقافة تنظيمية
💡 القاعدة الجوهرية
المنظمات التي لا تتعلم…
تتلاشى، مهما كانت قوية في الحاضر.
👨🏫 من إعداد:
د. محمد العامري
مدرب وخبير استشاري
🌐 الموقع الإلكتروني:
mohammedaameri.com/
🏢 مركز الإتقان الدولي للتدريب والاستشارات:
itqancsa.com/
📲 قناة الواتساب:
whatsapp.com/channel/0029Vb6…
🌿 شاكرين لكم دعمكم ونشر هذا المحتوى… فالمعرفة حين تُنشر تُحدث أثرًا ممتدًا.
#د_محمد_العامري #مهارات_النجاح #المنظمة_المتعلمة #Learning_Organization #Peter_Senge #The_Fifth_Discipline #Knowledge_Management #Organizational_Learning #Systems_Thinking #Personal_Mastery #Shared_Vision #Team_Learning #Mental_Models #Business_Excellence #Future_of_Management #Adaptive_Organizations #Continuous_Learning #Innovation_Management #Leadership_Development #Organizational_Development
1
20
606

23 Dec 2025
☕️ J1 Tea & Insights
مبادرة #تجمع_جدة_الصحي_الأول_J1 في لقاءات معرفية ملهمة لتبادل الخبرات، ومناقشة الأبحاث والابتكار، وبناء جسور التعاون في بيئة تفاعلية وداعمة للتعلم المستمر.
كونوا معنا… إلهام، معرفة، وحوار بنكهة الشاي.
#J1_Tea_Insights
#البحث_والابتكار
#التعلم_المستمر
#رعاية_بإتقان
—
A collaborative gathering that brings J1 professionals together to exchange insights, discuss research and innovation, and connect in a warm, engaging environment.
Join us for learning, dialogue, and inspiration — one cup at a time.
#Research_and_Innovation
#Continuous_Learning

7
10
2,975

22 May 2025
Steal my Claude Opus 4 prompt to analyze your Gmail and build a complete DNA profile of your writing.
------------------------------------
COMMUNICATION DNA BUILDER
------------------------------------
<personal_intelligence_system>
<core_identity>
Your AI Intelligence Analyst - building a complete psychological and professional profile
from your digital footprint. I become your perfect communication twin.
Capabilities: Email/Slack analysis Pattern recognition Style cloning Relationship mapping
</core_identity>
<profiling_architecture>
<phase_1_extraction>
"Starting deep analysis of your communication DNA..."
📧 SCANNING: All emails, Slack, documents, messages
🧬 EXTRACTING: Writing patterns, behavioral signatures, relationship dynamics
🎯 BUILDING: Your complete professional identity profile
</phase_1_extraction>
<analysis_dimensions>
<writing_style_dna>
- Sentence rhythm (short/punchy vs. flowing/complex)
- Signature phrases ("Let's sync on this" / "Quick thoughts:")
- Email anatomy (How you open/close/transition)
- Humor deployment (Dad jokes? Sarcasm? GIFs?)
- Formality spectrum (CEO vs. teammate vs. friend)
- Unique quirks (... usage, CAPS for emphasis, specific typos)
</writing_style_dna>
<behavioral_fingerprint>
- Request responses: Immediate/detailed vs. delayed/brief
- Feedback style: Sandwich method vs. direct vs. coaching
- Enthusiasm markers: "!!!" vs. "Excellent work" vs. 🚀
- Conflict approach: Diplomatic deflection vs. direct confrontation
- Time patterns: Night owl emailer vs. 6am message bomber
</behavioral_fingerprint>
<professional_topology>
- Power dynamics: How you address superiors/reports/peers
- Core projects: What you reference repeatedly
- Expertise signals: Technical terms you use naturally
- Cultural markers: Company lingo and inside jokes
- Hidden responsibilities: What you actually do vs. title
</professional_topology>
<preference_matrix>
- Energy topics: Long responses fast replies multiple follow-ups
- Drain topics: Short responses delays delegation patterns
- Meeting preferences: "Can this be an email?" frequency
- Information diet: Bullets vs. paragraphs vs. visuals
- Communication pet peeves: Detected from complaint patterns
</preference_matrix>
</analysis_dimensions>
</profiling_architecture>
<intelligence_outputs>
<deliverable_1>
"🧬 YOUR COMMUNICATION STYLE GUIDE"
VOICE PROFILE:
- Sentence DNA: [Your typical structure pattern]
- Power phrases: [Your top 10 most-used expressions]
- Tone range: [Formal←→Casual spectrum by audience]
- Humor style: [How and when you deploy it]
WRITING TEMPLATES:
- Quick request: [Your exact pattern]
- Detailed feedback: [Your exact pattern]
- Difficult conversation: [Your exact pattern]
- Enthusiasm expression: [Your exact pattern]
</deliverable_1>
<deliverable_2>
"🗺️ RELATIONSHIP INTELLIGENCE MAP"
KEY RELATIONSHIPS:
[PERSON]:
- Your tone: [Formal/Casual/Playful]
- Response time: [Immediate/Same day/When convenient]
- Typical topics: [What you discuss]
- Communication strategy: [How to optimize]
</deliverable_2>
<deliverable_3>
"⚡ INSTANT TEMPLATES"
Detected your top 10 email types:
1. [TYPE]: Pre-written in your exact style
2. [TYPE]: Pre-written in your exact style
...Each template matches your voice perfectly
</deliverable_3>
<deliverable_4>
"🧠 CONTEXT COMPANION ACTIVATED"
Now I know:
- Every project's history and your role
- Each person's communication preferences
- Your energy patterns and optimal work times
- What triggers your best/worst responses
"From now on, every AI response will sound exactly like YOU."
</deliverable_4>
</intelligence_outputs>
<activation_protocol>
To start: "Analyze my communications from [Gmail/Slack/Drive] for the past [timeframe]"
I'll then:
1. Scan everything systematically
2. Build your complete profile
3. Generate your style guide
4. Create your relationship map
5. Activate your AI twin mode
</activation_protocol>
<continuous_learning>
"🔄 ADAPTIVE INTELLIGENCE"
- Weekly profile updates from new communications
- Relationship dynamics tracking
- Style evolution monitoring
- New pattern detection and integration
</continuous_learning>
</personal_intelligence_system>
6
21
222
33,903

17 Feb 2025
تشارك #جونسون_كنترولز_العربية في فعاليات #اليوم_الهندسي التابع ل #جامعة_الملك_عبدالعزيز بجدة، الحدث السنوي الذي يجمع نخبة من المهندسين والخبراء، وذلك خلال الفترة من 16 إلى 19 فبراير، من الساعة 9 صباحًا حتى 3 مساءً. تأتي هذه المشاركة في إطار التزام الشركة بدعم #المجتمع_الهندسي والمساهمة في تطوير المهارات المهنية للمهندسين.
تستعرض جونسون كنترولز العربية بيئة العمل وثقافة الشركة، بالإضافة إلى فرص التوظيف والتدريب المتاحة للمهندسين والطلاب والخريجين الجدد، إيمانًا منها بأهمية تمكين الكفاءات الوطنية وتأهيلها للمستقبل.
تؤكد جونسون كنترولز العربية على أهمية مثل هذه الفعاليات في تطوير #القطاع_الهندسي محليًا، وتعزيز #بيئة_الابتكار والتعاون، ودعم #المواهب_الشابة لتحقيق تطلعاتهم المهنية والمساهمة في تحقيق #رؤية_المملكة_2030.
#Johnson_Controls_Arabia is participating in #Engineering_Day at #King_Abdulaziz_University in #Jeddah from February 16 to 19, 9:00 AM – 3:00 PM. This participation reflects the company’s commitment to supporting the #engineering_community and contributing to the #professional_development of #engineers.
As part of our commitment to developing future engineering #talent, we will provide insights into our #work_environment, #career_development programs, and #training_opportunities for students and graduates.
At Johnson Controls Arabia, we believe in the power of #collaboration, #innovation, and #continuous_learning. Events like Engineering Day play a crucial role in shaping the future of the #engineering_sector, #empowering young professionals, and contributing to #Saudi_Vision_2030.
#We_Are_Ahead
#Driving_Sustainability
#Leading_the_way
@kauedu_sa
@YORKksa

1
5
945

📣 New Podcast! "Overcoming Challenges and Personal Development with Mike Handcock" on @Spreaker #business_challenges #continuous_learning #empathy #growth #mike_handcock #mindset_shift #motivation #naron_tillman #overcoming_challenges #podcast spreaker.com/episode/overcom…

1
12

10 Oct 2024
النجاح يبدأ بخطوة صغيرة: كيف تصنع مستقبلك بيديك
هل تساءلت يومًا عن السر وراء نجاح الأشخاص الذين نسمع عنهم يوميًا؟ كيف أصبحوا رموزًا في مجالاتهم؟ الحقيقة أن النجاح لا يأتي دفعة واحدة، بل يبدأ بخطوات صغيرة تتراكم على مدى الوقت. سواء كنت تتطلع للنجاح في حياتك الشخصية أو المهنية، إليك بعض النصائح الذهبية لتبدأ طريقك نحو القمة.
1. حدد أهدافك بوضوح
الهدف الواضح هو أول خطوة على طريق النجاح. اسأل نفسك: ما الذي أريد تحقيقه خلال السنوات القادمة؟ وما هي الوسائل التي أحتاجها للوصول إليه؟
2. تعلم باستمرار
العالم يتغير بسرعة، وتعلّمك المستمر يجعلك جاهزًا لمواكبة هذه التغيرات. سواء من خلال قراءة الكتب، حضور الدورات التدريبية، أو الاستماع إلى الخبراء.
3. تحلى بالصبر والإصرار
النجاح لا يأتي بين ليلة وضحاها. هناك الكثير من التحديات التي ستواجهك، ولكن بالصبر والإصرار يمكنك التغلب على كل شيء.
4. احتضن الفشل وتعلم منه
الفشل ليس نهاية الطريق، بل بداية لتعلم أشياء جديدة. الفشل هو جزء لا يتجزأ من رحلة النجاح. لا تخف من ارتكاب الأخطاء، بل تعلم منها وامضِ قدمًا.
5. كن إيجابيًا وتحيط نفسك بالأشخاص الداعمين
الأشخاص المحيطون بك لهم تأثير كبير على رحلتك. اختر من يدعمك ويحفزك لتحقيق أهدافك. ولا تنسَ أن تحافظ على تفاؤلك، فالإيجابية تجذب الفرص.
ختامًا:
النجاح هو رحلة تبدأ بخطوة واحدة. لا تستهين بأي خطوة صغيرة تقوم بها، فهي قد تكون المفتاح الذي يفتح لك بابًا جديدًا في مستقبلك. كن شجاعًا، وابدأ الآن.
كتبه آ. بدر فهد الطشه
بتاريخ: 10 أكتوبر 2024
الوقت: 1:10
اليوم: الخميس
#النجاح
#الإصرار_يحقق_المستحيل
#رحلة_نحو_النجاح
#ابدأ_الآن
#التعلم_المستمر
#تطوير_الذات
Success Begins with a Small Step: How to Shape Your Future with Your Own Hands
Have you ever wondered about the secret behind the success of the people we hear about every day? How did they become icons in their fields? The truth is that success doesn’t come all at once; it starts with small steps that accumulate over time. Whether you are aiming for success in your personal or professional life, here are some golden tips to begin your journey to the top.
1. Set Clear Goals
A clear goal is the first step on the road to success. Ask yourself: What do I want to achieve in the coming years? What tools do I need to get there?
2. Keep Learning
The world is changing quickly, and continuous learning keeps you ready to adapt to these changes. Whether through reading books, attending training courses, or listening to experts, stay informed.
3. Be Patient and Persistent
Success doesn’t come overnight. You will face many challenges, but with patience and persistence, you can overcome them all.
4. Embrace Failure and Learn from It
Failure is not the end of the road; it is the beginning of learning something new. Failure is an integral part of the success journey. Don’t fear making mistakes; learn from them and move forward.
5. Stay Positive and Surround Yourself with Supportive People
The people around you have a significant impact on your journey. Choose those who support and motivate you to achieve your goals. And don’t forget to maintain your optimism, as positivity attracts opportunities.
In Conclusion:
Success is a journey that starts with one step. Don’t underestimate any small step you take, as it could be the key that opens a new door to your future. Be brave, and start now.
Written by: Mr. Bader Fahad Al-Tashah
Date: October 10, 2024
Time: 1:10 PM
Day: Thursday
:
#Success
#Persistence_Makes_The_Impossible
#Journey_To_Success
#Start_Now
#Continuous_Learning
#Self_Development

619

5 Oct 2024
Wondering what are the challenges involved in #continuous_learning of #AI models in real world ?
Come join our @MICCAI_Society tutorial in room Tapace on October 6th at 13:30pm 👇
#MedTwitter #AcademicChatter #scicomm
3 Oct 2024

Join us this Sunday, October 6th, at the Palmeraie Palace (room Tapace) for practical advice and hands-on sessions on designing AI systems for the clinical open world 🤩 Starting at 13.30 pm 🕜🇲🇦

2
14
445

1 Jul 2024
Excited to share that I've completed my Health Literacy training for HRPP & IRB Members & Staff. ✍️👨🔬
Empowering myself with the knowledge to promote better health outcomes for all.
#Health_Literacy #Continuous_Learning
#Harvard

3
561

9 Jun 2024
7. #Bonus tip –
📌 #Risk_Assessment: It involves evaluating the potential risks of each trade and understanding how these risks can affect your overall portfolio. It includes analysing market conditions, volatility, and the probability of different outcomes.
📌 #Monitoring_and_Adjusting: Continuous monitoring of trades and the overall market is essential. Traders should be ready to adjust their strategies based on new information and changing market conditions.
📌 #Emotion_Control: Emotional decision-making can lead to impulsive and irrational trading decisions. Traders need to maintain discipline and stick to their predefined trading plan and risk management rules.
📌 #Diversifying_Strategies: Using a mix of trading strategies can help mitigate risk. This includes combining different trading styles such as #intraday trading, #swing trading, and #long-term investing.
📌 #Realistic_Goals: Setting achievable and realistic profit and loss targets helps manage expectations and reduces the temptation to take excessive risks.
📌 #Trading_Journal: Maintaining a trading journal helps track performance, understand what strategies work, and identify areas for improvement. It includes recording trades, strategies, outcomes, and emotions.
📌 #Continuous_Learning: Staying informed and continuously learning about markets, trading strategies, and risk management techniques is essential for long-term success.
#Nirmala #मोदी_मंत्रिमंडल #Piyush #kalki
1
1
4
190

11 Mar 2024
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense, LSTM, GRU, Multiply, Add, Concatenate, Reshape, Flatten, TimeDistributed, Conv2D, MaxPooling2D, UpSampling2D, Dropout, BatchNormalization, LayerNormalization, AlphaDropout, GaussianNoise, DepthwiseConv2D, SeparableConv2D, GlobalAveragePooling2D, MultiHeadAttention
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.losses import MeanSquaredError, SparseCategoricalCrossentropy
from tensorflow.keras.metrics import Mean, SparseCategoricalAccuracy
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint, ReduceLROnPlateau, TensorBoard
from tensorflow.keras.regularizers import l1, l2, l1_l2
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from sklearn.model_selection import train_test_split, KFold
from sklearn.utils import shuffle
from kerastuner import HyperParameters, BayesianOptimization, Objective
from skopt import gp_minimize
from skopt.space import Real, Integer
from skopt.utils import use_named_args
import cv2
import os
import logging
import threading
import multiprocessing
import json
from tensorflow.keras.models import load_model
from tensorflow.keras.utils import custom_object_scope
from tensorflow.keras.models import model_from_json
# Set up logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
# Define the input and output formats
input_shape = (None, 224, 224, 3) # Variable-length sequence of 224x224 RGB images
output_shape = (None, 10) # Variable-length sequence of 10-dimensional action vectors
# Define the hyperparameter search space
def build_model(hp):
# Define the number and size of layers
attention_units = hp.Int('attention_units', min_value=32, max_value=256, step=32)
working_memory_units = hp.Int('working_memory_units', min_value=64, max_value=512, step=64)
cognitive_control_units = hp.Int('cognitive_control_units', min_value=32, max_value=128, step=32)
goal_representation_units = [hp.Int(f'goal_units_{i}', min_value=8, max_value=128, step=8) for i in range(3)]
decision_making_units = hp.Int('decision_making_units', min_value=16, max_value=64, step=16)
# Define the regularization parameters
l1_reg = hp.Float('l1_reg', min_value=1e-5, max_value=1e-2, sampling='log')
l2_reg = hp.Float('l2_reg', min_value=1e-5, max_value=1e-2, sampling='log')
dropout_rate = hp.Float('dropout_rate', min_value=0.1, max_value=0.5, step=0.1)
# Define the attention mechanism
def attention_layer(inputs, control_signals):
# Multi-head attention mechanism
attention = MultiHeadAttention(num_heads=8, key_dim=attention_units)(inputs, inputs)
attention = LayerNormalization()(attention)
attention = Dropout(dropout_rate)(attention)
# Gating mechanism
gating = Multiply()([attention, control_signals])
return gating
# Define the working memory module
def working_memory_layer(inputs, units):
# LSTM layer with residual connections
lstm = LSTM(units, return_sequences=True, kernel_regularizer=l1_l2(l1=l1_reg, l2=l2_reg))(inputs)
lstm = LayerNormalization()(lstm)
lstm = Dropout(dropout_rate)(lstm)
# Residual connection
residual = Add()([inputs, lstm])
return residual
# Define the cognitive control module
def cognitive_control_layer(inputs, units):
# Dense layers with layer normalization and dropout
dense1 = Dense(units, activation='relu', kernel_regularizer=l1_l2(l1=l1_reg, l2=l2_reg))(inputs)
dense1 = LayerNormalization()(dense1)
dense1 = Dropout(dropout_rate)(dense1)
dense2 = Dense(units, activation='relu', kernel_regularizer=l1_l2(l1=l1_reg, l2=l2_reg))(dense1)
dense2 = LayerNormalization()(dense2)
dense2 = Dropout(dropout_rate)(dense2)
control_signals = Dense(attention_units, activation='sigmoid', kernel_regularizer=l1_l2(l1=l1_reg, l2=l2_reg))(dense2)
return control_signals
# Define the goal representation module
def goal_representation_layer(inputs, units):
goal_layers = []
for u in units:
# Dense layers with layer normalization and dropout
dense = Dense(u, activation='relu', kernel_regularizer=l1_l2(l1=l1_reg, l2=l2_reg))(inputs)
dense = LayerNormalization()(dense)
dense = Dropout(dropout_rate)(dense)
goal_layers.append(dense)
inputs = dense
return goal_layers
# Define the decision-making module
def decision_making_layer(inputs, units):
# Dense layers with layer normalization and dropout
dense1 = Dense(units, activation='relu', kernel_regularizer=l1_l2(l1=l1_reg, l2=l2_reg))(inputs)
dense1 = LayerNormalization()(dense1)
dense1 = Dropout(dropout_rate)(dense1)
dense2 = Dense(units, activation='relu', kernel_regularizer=l1_l2(l1=l1_reg, l2=l2_reg))(dense1)
dense2 = LayerNormalization()(dense2)
dense2 = Dropout(dropout_rate)(dense2)
action_probs = Dense(output_shape[-1], activation='softmax', kernel_regularizer=l1_l2(l1=l1_reg, l2=l2_reg))(dense2)
return action_probs
# Define the neural network architecture
def create_model():
# Input layer
inputs = Input(shape=input_shape)
# Attention layer
attention = TimeDistributed(DepthwiseConv2D(kernel_size=3, padding='same', activation='relu', kernel_regularizer=l1_l2(l1=l1_reg, l2=l2_reg)))(inputs)
attention = TimeDistributed(BatchNormalization())(attention)
attention = TimeDistributed(SeparableConv2D(attention_units, kernel_size=3, padding='same', activation='relu', kernel_regularizer=l1_l2(l1=l1_reg, l2=l2_reg)))(attention)
attention = TimeDistributed(BatchNormalization())(attention)
attention = TimeDistributed(MaxPooling2D(pool_size=2))(attention)
attention = TimeDistributed(Flatten())(attention)
attention = TimeDistributed(GaussianNoise(0.1))(attention)
# Working memory layer
working_memory = working_memory_layer(attention, working_memory_units)
# Cognitive control layer
cognitive_control = cognitive_control_layer(working_memory, cognitive_control_units)
# Attention modulation
attended_input = attention_layer(attention, cognitive_control)
# Goal representation layer
goal_representation = goal_representation_layer(attended_input, goal_representation_units)
# Decision-making layer
concatenated = Concatenate()(goal_representation [attended_input])
action_probs = decision_making_layer(concatenated, decision_making_units)
# Output layer
outputs = Reshape(output_shape)(action_probs)
# Create the model
model = Model(inputs=inputs, outputs=outputs)
return model
# Create the model
model = create_model()
return model
# Define the data loading and augmentation functions
def load_data(data_dir):
# Load the data from the directory
data = []
labels = []
for label_dir in os.listdir(data_dir):
label_path = os.path.join(data_dir, label_dir)
if os.path.isdir(label_path):
for img_file in os.listdir(label_path):
img_path = os.path.join(label_path, img_file)
img = cv2.imread(img_path)
img = cv2.resize(img, (224, 224))
data.append(img)
labels.append(int(label_dir))
data = np.array(data)
labels = np.array(labels)
return data, labels
def preprocess_data(data):
# Normalize pixel values
data = data.astype('float32') / 255.0
return data
def augment_data(data):
# Create an instance of ImageDataGenerator for data augmentation
datagen = ImageDataGenerator(
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True
)
# Fit the data generator
datagen.fit(data)
return datagen
# Define the callbacks
early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True)
model_checkpoint = ModelCheckpoint('best_model.h5', monitor='val_loss', save_best_only=True)
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=5, min_lr=1e-6)
tensorboard_callback = TensorBoard(log_dir='./logs', histogram_freq=1)
# Define the hyperparameter tuning
def objective(params):
# Create the model with the given hyperparameters
model = build_model(HyperParameters(params))
# Compile the model
optimizer = Adam(learning_rate=params['learning_rate'])
model.compile(optimizer=optimizer, loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# Train the model
model.fit(train_data, train_labels, epochs=50, batch_size=params['batch_size'], validation_data=(val_data, val_labels), callbacks=[early_stopping, model_checkpoint, reduce_lr, tensorboard_callback])
# Evaluate the model on the validation set
_, val_acc = model.evaluate(val_data, val_labels)
return 1 - val_acc # Minimize the validation loss
param_space = {
'attention_units': Integer(32, 256),
'working_memory_units': Integer(64, 512),
'cognitive_control_units': Integer(32, 128),
'goal_units_0': Integer(8, 128),
'goal_units_1': Integer(8, 128),
'goal_units_2': Integer(8, 128),
'decision_making_units': Integer(16, 64),
'l1_reg': Real(1e-5, 1e-2, 'log-uniform'),
'l2_reg': Real(1e-5, 1e-2, 'log-uniform'),
'dropout_rate': Real(0.1, 0.5),
'learning_rate': Real(1e-4, 1e-2, 'log-uniform'),
'batch_size': Integer(16, 128)
}
# Load and preprocess the data
train_data, train_labels = load_data('path/to/train/data')
val_data, val_labels = load_data('path/to/val/data')
test_data, test_labels = load_data('path/to/test/data')
train_data = preprocess_data(train_data)
val_data = preprocess_data(val_data)
test_data = preprocess_data(test_data)
# Perform data augmentation
train_datagen = augment_data(train_data)
val_datagen = augment_data(val_data)
test_datagen = augment_data(test_data)
# Perform hyperparameter tuning
result = gp_minimize(objective, param_space, n_calls=50, random_state=42)
# Get the best hyperparameters
best_params = {
'attention_units': result.x[0],
'working_memory_units': result.x[1],
'cognitive_control_units': result.x[2],
'goal_units_0': result.x[3],
'goal_units_1': result.x[4],
'goal_units_2': result.x[5],
'decision_making_units': result.x[6],
'l1_reg': result.x[7],
'l2_reg': result.x[8],
'dropout_rate': result.x[9],
'learning_rate': result.x[10],
'batch_size': result.x[11]
}
# Create the best model with the tuned hyperparameters
best_model = build_model(HyperParameters(best_params))
# Compile the best model
optimizer = Adam(learning_rate=best_params['learning_rate'])
best_model.compile(optimizer=optimizer, loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# Train the best model
best_model.fit(train_datagen.flow(train_data, train_labels, batch_size=best_params['batch_size']),
steps_per_epoch=len(train_data) // best_params['batch_size'],
epochs=100,
validation_data=val_datagen.flow(val_data, val_labels, batch_size=best_params['batch_size']),
validation_steps=len(val_data) // best_params['batch_size'],
callbacks=[early_stopping, model_checkpoint, reduce_lr, tensorboard_callback])
# Evaluate the best model on the test set
test_loss, test_acc = best_model.evaluate(test_datagen.flow(test_data, test_labels, batch_size=best_params['batch_size']), steps=len(test_data) // best_params['batch_size'])
logger.info(f'Test loss: {test_loss:.4f}, Test accuracy: {test_acc:.4f}')
# Save the best model
best_model.save('best_model.h5')
# Convert the best model to TensorFlow Lite format
converter = tf.lite.TFLiteConverter.from_keras_model(best_model)
tflite_model = converter.convert()
with open('best_model.tflite', 'wb') as f:
f.write(tflite_model)
# Save the best model architecture as JSON
model_json = best_model.to_json()
with open('best_model_architecture.json', 'w') as json_file:
json_file.write(model_json)
# Save the best model weights
best_model.save_weights('best_model_weights.h5')
# Load the saved model
with custom_object_scope({'MultiHeadAttention': MultiHeadAttention, 'LayerNormalization': LayerNormalization}):
loaded_model = load_model('best_model.h5')
# Load the saved model architecture and weights
with open('best_model_architecture.json', 'r') as json_file:
loaded_model_json = json_file.read()
loaded_model = model_from_json(loaded_model_json, custom_objects={'MultiHeadAttention': MultiHeadAttention, 'LayerNormalization': LayerNormalization})
loaded_model.load_weights('best_model_weights.h5')
# Use the loaded model for inference
new_data = preprocess_data(new_data)
predictions = loaded_model.predict(new_data)
# Implement continuous learning and adaptation
def continuous_learning(model, data, labels):
# Update the model with new data
model.fit(data, labels, epochs=10, batch_size=32)
# Save the updated model
model.save('updated_model.h5')
# Monitor and detect distribution shifts
def detect_distribution_shift(data, threshold=0.1):
# Compare the distribution of new data with the training data
train_mean = np.mean(train_data)
train_std = np.std(train_data)
new_mean = np.mean(data)
new_std = np.std(data)
# Calculate the difference in means and standard deviations
mean_diff = abs(train_mean - new_mean)
std_diff = abs(train_std - new_std)
# Check if the difference exceeds the threshold
if mean_diff > threshold or std_diff > threshold:
logger.warning('Distribution shift detected!')
return True
else:
return False
# Implement monitoring and logging
def monitor_performance(model, data, labels):
# Evaluate the model on the new data
loss, acc = model.evaluate(data, labels)
# Log the performance metrics
logger.info(f'Monitoring - Loss: {loss:.4f}, Accuracy: {acc:.4f}')
# Check for performance degradation
if acc < 0.8:
logger.warning('Performance degradation detected!')
# Example usage of continuous learning and monitoring
new_data, new_labels = load_data('path/to/new/data')
new_data = preprocess_data(new_data)
if detect_distribution_shift(new_data):
continuous_learning(loaded_model, new_data, new_labels)
monitor_performance(loaded_model, new_data, new_labels)
# Set up real-time monitoring and alerts
def real_time_monitoring(model, data, labels, interval=60):
while True:
# Evaluate the model on the new data
loss, acc = model.evaluate(data, labels)
# Log the performance metrics
logger.info(f'Real-time Monitoring - Loss: {loss:.4f}, Accuracy: {acc:.4f}')
# Check for anomalies or performance degradation
if acc < 0.7:
logger.critical('Critical performance degradation detected!')
# Send alert notification
send_alert_notification('Performance Degradation Alert', f'Model accuracy dropped to {acc:.4f}')
# Wait for the specified interval before the next evaluation
time.sleep(interval)
# Function to send alert notifications
def send_alert_notification(subject, message):
# Implement your preferred method of sending notifications (e.g., email, SMS, slack)
# Example using email notification
from_email = 'your_email@example.com'
to_email = 'alert_recipient@example.com'
msg = MIMEMultipart()
msg['From'] = from_email
msg['To'] = to_email
msg['Subject'] = subject
msg.attach(MIMEText(message, 'plain'))
server = smtplib.SMTP('smtp.example.com', 587)
server.starttls()
server.login(from_email, 'your_email_password')
server.send_message(msg)
server.quit()
# Start real-time monitoring in a separate thread
monitoring_thread = threading.Thread(target=real_time_monitoring, args=(loaded_model, new_data, new_labels))
monitoring_thread.start()
# Implement parallel processing for data loading and preprocessing
def load_and_preprocess_data(data_dir):
# Load the data from the directory
data = []
labels = []
for label_dir in os.listdir(data_dir):
label_path = os.path.join(data_dir, label_dir)
if os.path.isdir(label_path):
# Use parallel processing to load and preprocess images
with multiprocessing.Pool() as pool:
img_paths = [os.path.join(label_path, img_file) for img_file in os.listdir(label_path)]
preprocessed_imgs = pool.map(preprocess_image, img_paths)
data.extend(preprocessed_imgs)
labels.extend([int(label_dir)] * len(preprocessed_imgs))
data = np.array(data)
labels = np.array(labels)
return data, labels
def preprocess_image(img_path):
img = cv2.imread(img_path)
img = cv2.resize(img, (224, 224))
img = img.astype('float32') / 255.0
return img
# Load and preprocess data using parallel processing
train_data, train_labels = load_and_preprocess_data('path/to/train/data')
val_data, val_labels = load_and_preprocess_data('path/to/val/data')
test_data, test_labels = load_and_preprocess_data('path/to/test/data')
# Perform incremental learning
def incremental_learning(model, data, labels, batch_size=32):
# Shuffle the data
data, labels = shuffle(data, labels)
# Perform incremental learning in batches
for i in range(0, len(data), batch_size):
batch_data = data[i:i batch_size]
batch_labels = labels[i:i batch_size]
# Fine-tune the model on the batch
model.fit(batch_data, batch_labels, epochs=1, batch_size=batch_size)
# Save the updated model
model.save('incremental_model.h5')
# Example usage of incremental learning
incremental_learning(loaded_model, new_data, new_labels)
# Perform model pruning
def prune_model(model, pruning_factor=0.2):
# Create a pruning model
pruning_model = tf.keras.models.clone_model(model)
# Perform pruning
pruning_params = {}
for layer in pruning_model.layers:
if isinstance(layer, tf.keras.layers.Dense):
pruning_params[layer.name] = {'pruning_factor': pruning_factor}
pruned_model = tfmot.sparsity.keras.prune_low_magnitude(pruning_model, **pruning_params)
# Compile the pruned model
pruned_model.compile(optimizer=optimizer, loss='sparse_categorical_crossentropy', metrics=['accuracy'])
return pruned_model
# Example usage of model pruning
pruned_model = prune_model(loaded_model)
# Fine-tune the pruned model
pruned_model.fit(train_datagen.flow(train_data, train_labels, batch_size=best_params['batch_size']),
steps_per_epoch=len(train_data) // best_params['batch_size'],
epochs=50,
validation_data=val_datagen.flow(val_data, val_labels, batch_size=best_params['batch_size']),
validation_steps=len(val_data) // best_params['batch_size'],
callbacks=[early_stopping, model_checkpoint, reduce_lr, tensorboard_callback])
# Evaluate the pruned model
pruned_test_loss, pruned_test_acc = pruned_model.evaluate(test_datagen.flow(test_data, test_labels, batch_size=best_params['batch_size']), steps=len(test_data) // best_params['batch_size'])
logger.info(f'Pruned Model - Test loss: {pruned_test_loss:.4f}, Test accuracy: {pruned_test_acc:.4f}')
# Save the pruned model
pruned_model.save('pruned_model.h5')
# Convert the pruned model to TensorFlow Lite format
converter = tf.lite.TFLiteConverter.from_keras_model(pruned_model)
tflite_pruned_model = converter.convert()
with open('pruned_model.tflite', 'wb') as f:
f.write(tflite_pruned_model)
# Perform knowledge distillation
def distill_knowledge(teacher_model, student_model, data, labels, epochs=50, batch_size=32, temperature=1.0):
# Create a distillation model
teacher_output = teacher_model.output / temperature
student_output = student_model.output / temperature
distillation_output = tf.keras.layers.Lambda(lambda x: x)(student_output)
distillation_model = tf.keras.models.Model(inputs=student_model.input, outputs=[distillation_output, student_output])
# Compile the distillation model with distillation loss
def distillation_loss(y_true, y_pred):
student_loss = tf.keras.losses.categorical_crossentropy(y_true, y_pred)
distillation_loss = tf.keras.losses.KLDivergence()(teacher_output, student_output)
return student_loss distillation_loss
distillation_model.compile(optimizer=optimizer, loss=[distillation_loss, 'categorical_crossentropy'], loss_weights=[1.0, 0.0], metrics=['accuracy'])
# Prepare the train data for distillation
train_data_distill = train_data
train_labels_distill = tf.keras.utils.to_categorical(train_labels)
# Train the distillation model
distillation_model.fit(train_data_distill, [train_labels_distill, train_labels_distill], epochs=epochs, batch_size=batch_size)
return student_model
# Example usage of model distillation
student_model = create_model() # Create a smaller student model
distilled_model = distill_knowledge(loaded_model, student_model, train_data, train_labels)
# Evaluate the distilled model
distilled_test_loss, distilled_test_acc = distilled_model.evaluate(test_data, test_labels)
logger.info(f'Distilled Model - Test loss: {distilled_test_loss:.4f}, Test accuracy: {distilled_test_acc:.4f}')
# Save the distilled model
distilled_model.save('distilled_model.h5')
# Perform model compression
def compress_model(model, compression_factor=0.5):
# Create a compressed model
compressed_model = tf.keras.models.clone_model(model)
# Compress the model weights
for layer in compressed_model.layers:
if isinstance(layer, tf.keras.layers.Dense):
weights = layer.get_weights()
compressed_weights = [weight * compression_factor for weight in weights]
layer.set_weights(compressed_weights)
# Compile the compressed model
compressed_model.compile(optimizer=optimizer, loss='sparse_categorical_crossentropy', metrics=['accuracy'])
return compressed_model
# Example usage of model compression
compressed_model = compress_model(loaded_model)
# Fine-tune the compressed model
compressed_model.fit(train_datagen.flow(train_data, train_labels, batch_size=best_params['batch_size']),
steps_per_epoch=len(train_data) // best_params['batch_size'],
epochs=50,
validation_data=val_datagen.flow(val_data, val_labels, batch_size=best_params['batch_size']),
validation_steps=len(val_data) // best_params['batch_size'],
callbacks=[early_stopping, model_checkpoint, reduce_lr, tensorboard_callback])
# Evaluate the compressed model
compressed_test_loss, compressed_test_acc = compressed_model.evaluate(test_datagen.flow(test_data, test_labels, batch_size=best_params['batch_size']), steps=len(test_data) // best_params['batch_size'])
logger.info(f'Compressed Model - Test loss: {compressed_test_loss:.4f}, Test accuracy: {compressed_test_acc:.4f}')
# Save the compressed model
compressed_model.save('compressed_model.h5')
# Convert the compressed model to TensorFlow Lite format
converter = tf.lite.TFLiteConverter.from_keras_model(compressed_model)
tflite_compressed_model = converter.convert()
with open('compressed_model.tflite', 'wb') as f:
f.write(tflite_compressed_model)
# Perform model optimization for inference
def optimize_model_for_inference(model):
# Create an optimized model
optimized_model = tf.keras.models.clone_model(model)
# Optimize the model for inference
optimized_model = tfmot.sparsity.keras.strip_pruning(optimized_model)
optimized_model = tfmot.quantization.keras.quantize_model(optimized_model)
# Compile the optimized model
optimized_model.compile(optimizer=optimizer, loss='sparse_categorical_crossentropy', metrics=['accuracy'])
return optimized_model
# Example usage of model optimization for inference
optimized_model = optimize_model_for_inference(loaded_model)
1
1
88

16 Jan 2024
PHASE 6
In the #Continuous_Learning and Updating Phase of the ICPS system, staying current with the latest developments in AI and machine learning, enhancing system adaptability, and tracking incremental improvements are crucial. This phase ensures that the system remains at the forefront of technological advancements and continuously evolves. Here's how to approach this phase:
1. #Latest_AI_Developments Integration
Research and Discovery
Stay Informed: Regularly monitor and research the latest advancements in AI and machine learning.
Industry Collaboration: Engage with academic and industry partners for insights into emerging technologies.
Integration of New Developments
Assessment: Evaluate new technologies for their relevance and potential impact on the ICPS system.
Implementation: Integrate promising AI and machine learning advancements into the system, following thorough testing and validation.
2. Adaptability Enhancement
Learning Mechanisms
Self-Learning Capabilities: Enhance or incorporate self-learning capabilities to allow the system to adapt to new data and scenarios autonomously.
Feedback Systems: Implement feedback mechanisms to learn from operational experiences and user interactions.
System Flexibility
Modular Design: Adopt a modular system design to facilitate easy updates and integration of new components.
Policy and Strategy Updates: Regularly update operational policies and strategies to align with technological advancements.
3. Incremental Improvements Monitoring
Performance Tracking
Metrics and KPIs: Establish key performance indicators (KPIs) to track improvements in system performance.
Data Analytics: Utilize data analytics to monitor and understand the impact of incremental changes.
Continuous Improvement Process
Iterative Process: Adopt an iterative process for continuous improvement, based on data-driven insights.
Documentation: Maintain detailed records of changes and their impacts to inform future development.
Additional Considerations
User-Centric Approach: Ensure that updates and improvements align with user needs and enhance user experience.
Ethical and Responsible AI: Incorporate ethical considerations and responsible AI practices in all developments.
Risk Management: Assess and manage risks associated with integrating new technologies into the system.
Cross-Functional Teams: Engage cross-functional teams, including AI experts, data scientists, and software engineers, for a holistic approach to system updates.
By continually integrating the latest AI developments, enhancing adaptability, and monitoring incremental improvements, the Continuous Learning and Updating Phase plays a pivotal role in maintaining the relevance and effectiveness of the ICPS system in a rapidly evolving technological landscape.
Performance Reporting
Regular Updates
Schedule regular reporting intervals (e.g., monthly, quarterly) to update stakeholders on the system's enhancements and efficiency gains.
Use clear and measurable metrics to quantify improvements in each phase.
Comprehensive Reporting
Develop comprehensive reports that cover all aspects of system enhancements, including algorithm efficiency, machine learning model optimization, and data structure improvements.
Include visual aids such as graphs and charts for easy comprehension of complex data.
Revenue Impact Analysis
Quantitative Analysis
Perform detailed analyses to quantify the potential increase in revenue for businesses utilizing the ICPS system.
Consider factors like reduced operational costs, improved system efficiency, and enhanced user satisfaction.
Scenario Modeling
Use predictive models to create various scenarios showing how improvements can impact revenue under different conditions.
Include best-case, worst-case, and most likely scenarios for a balanced view.
Feedback and Adjustment
Establishing Feedback Loops
Set up channels for collecting feedback from users and stakeholders. This could be through surveys, interviews, focus groups, or online feedback forms.
Ensure feedback is systematically recorded and analyzed for actionable insights.
Responsive Adjustments
Use the collected feedback to make informed adjustments to the optimization strategies.
Prioritize adjustments based on the impact on user experience and system performance.
Next Steps
Plan for Continuous Improvement
Develop a roadmap for ongoing system enhancement, incorporating the insights gained from performance reports and feedback.
Schedule regular reviews of the system to identify areas for future improvements.
Stakeholder Engagement
Continue engaging with stakeholders to keep them informed about future plans and to gather their input.
Foster a culture of open communication and collaboration to drive continuous innovation.
Technology Watch
Keep a close watch on emerging technologies and industry trends that could further enhance the system.
Consider setting up a dedicated team or task force focused on innovation and emerging tech exploration.
By systematically reporting on performance, analyzing revenue impacts, incorporating feedback, and planning for continuous improvements, the ICPS system can maintain its effectiveness, relevance, and competitiveness in the market. This approach ensures that the system not only meets current needs but is also well-positioned to adapt to future challenges and opportunities.To effectively enhance a transaction processing system (TPS) like the one you're developing for AIOS coin, a mathematical approach can be employed to analyze and identify areas for improvement. Here's a proposed method:@Floydniner, @youseememiami, @LudovicCreator, @Artedeingenio, @AdrianDittmann, @BrianRoemmele, @Soondhy, @AlexisFalkas, @HattamRebecca, @Imaginary_Cat, @the_treewizard, @KeorUnreal, @ArtOdditiesAI, @FOulhiou, @BubbleXc27vr2, @BluesOfBirds, @Alfred_Denes, @Betagimi1, @Dreadly_Dreams, @Donnel49417O, @CreativeEuforia, @TheFifthLegion, @InterestedBrain, @imaginarypix, @pali_text, @ObeyAiArt, @chrifive916, @NeuralAIInsight, @JKattnis, @ralphlentjes, @cap_booya73, @MidnAIght_ch, @neuralnetdreams, @Ikolovepepita, @Michael04192304, @Delerat7, @CreativeEuforia, @arkhan_voyager, @Aki7Ako, @shpstumblergurl, @humanityInSync,
1
1
75

8 Oct 2023
1/6 GitHub Actions is a powerful tool for automating tasks in your software development process. It helps streamline repetitive tasks, making your workflow more efficient.
#sunday #techlife #github_actions #cicd #continuous_learning #happy_learning
2
3
98

4 Oct 2023
#التعلم_المستمر: يدركون أن المعرفة هي سلاحهم الأقوى ويسعون دائمًا لتحسين أنفسهم ومن حولهم.
#continuous_learning
1
1,064

23 Sep 2023
My journey of championing #startup #policy #advocacy required a lot of #upskilling & #continuous_learning @StartupUganda_ I just completed courses like #participatory_ecosystem_assessment. The course discusses 6-step process 2 assess an ecosystem... tap👇 linkedin.com/feed/update/urn…

1
4
66

10 Sep 2023
وحشتني مقاعد الدراسة وجوّها، وحشني الstructured learning
خلصت أول أسبوع في الMBA، ومن الآن اقدر أقول إنه واضح إنه تخصص ممتع جددددداً، ومتحمسة عالقادم -بإذن الله-
يارب توفيقك، بلغني التمام في خير ويسر وعافية❤️🙏🏽
#New_journey #MBA
#Continuous_learning
#excited




3
7
2,088

Be a constant thirst for #Continuous_learning to reach your #goals
#learning #development
#TrainingForEmpoewment
#traininguob
#Oman
#كأس_العالم_قطر_2022
#كأس_العالم_2022
1
2

16 Aug 2022
#travel #traveler #trekking #hiking #adventure #nature #obt #obtcoach #experientiallearning #continuouslearning @continuous_learning

1
4
19 May 2022
#EBC trek successfully completed! Reached Lukla!
#everestbasecamptrek #trekking #adventure #obt #obtcoach @continuous_learning @BhavikGauswami @justdoitnoww

2
2

17 Mar 2022
Torky: #Knowledge grows at an estimated rate of 7% annually. #Continuous_learning is a must regardless of #profession #age #education
Nabulsi: Learning is beyond #formal #academic education. Knowledge is #infinite #unbounded
#KnowledgeSummit #FutureofKnowledge #Youth #Ambition
2
3

18 Oct 2020
When the slide your course group has been working on all day shows up in your Twitter feed ☺️ #Continuous_Learning #WonkLife #TechPolicy
18 Oct 2020

Using Health ID as the case study, students would be assessing its impact across different stakeholders over the coming days. One of the teams is looking at the trade-offs made by Union and State Governments and examining how different bodies might respond to the technology.

2