
Jun 13
Claude Fable 5 (Anthropic, released June 9, 2026) generally outperforms GPT-5.5 (OpenAI) across most of these benchmarks, with particularly large leads in coding, agentic software engineering, and complex reasoning tasks. The gap widens on harder/“frontier” subsets.
Fable 5 (the generally available version with safeguards) performs very close to the internal Mythos 5 preview in non-sensitive areas. Scores can vary slightly by harness, effort level (e.g., max/xhigh reasoning), and safeguards (which sometimes cause fallback to Opus 4.8 on cyber/biology-related tasks). Data comes from Anthropic’s launch materials, Epoch AI, Artificial Analysis, Vals AI, and third-party comparisons (as of mid-June 2026).
Here’s a benchmark-by-benchmark breakdown:
Math & Reasoning
•1. FrontierMath Tier 4 (research-level): Fable 5 ~87.8–88% (Epoch AI) vs GPT-5.5 ~72%. Strong Fable lead.
•2. FrontierMath Tier 1-3: Fable 5 ~87% vs GPT-5.5 ~85%. Slight Fable edge.
Coding & Software Engineering (Fable’s biggest strength)
•3. SWE-Bench Pro: Fable 5 80.3% vs GPT-5.5 58.6% ( 21.7 points). Massive win for Fable.
•4. FrontierCode Diamond (hardest production-quality subset): Fable 5 29.3% vs GPT-5.5 5.7%. Huge lead (more than 5x).
•5. FrontierCode Main: Fable 5 ~46.3% vs GPT-5.5 ~25.5%. Clear Fable advantage.
•6. TerminalBench (2.1): Fable 5 84.3–88.0% (Mythos higher; Fable has some safety refusals) vs GPT-5.5 83.4%. Slight-to-moderate Fable edge.
•7. KernelBench Hard: Limited public head-to-head data. Fable excels on complex coding/agentic tasks overall; expect Fable advantage based on patterns in similar benchmarks.
•31. LiveCodeBench: Fable 5 ~89.8% (top-ranked on Vals) — strong lead expected over GPT-5.5.
•34. IOI: Fable 5 72.25% (top on Vals).
•36. VibeCode: Fable 5 90.35% (top-ranked).
Agentic & Real-World Tasks
•9. Humanity’s Last Exam (No Tools): Fable 5 59.0% vs GPT-5.5 ~41–50% (sources vary slightly).
•10. Humanity’s Last Exam (Tools): Fable 5 64.5% vs GPT-5.5 52.2%. Solid Fable win.
•15. AutomationBench: Fable 5 17.4% vs GPT-5.5 12.9%.
•16. OSWorld: Fable 5 85.0% vs GPT-5.5 78.7%.
•20. GDPval-AA: Fable 5 1932 vs GPT-5.5 1769. Clear Fable lead.
•21. GDPpdf (visual document reasoning, no tools): Fable 5 29.8% vs GPT-5.5 24.9%.
•22. Legal Agent Benchmark: Fable 5 13.3% vs GPT-5.5 2.1%. Very large Fable win.
•23. HealthBench (Professional variant): Fable/Mythos ~62.7–66%; GPT-5.5 trails in available comparisons.
•27. ALE-Bench (Agents’ Last Exam): GPT-5.5 has a slight edge in some harnesses (e.g., ~24% vs Fable ~22%). One of the few where GPT-5.5 competes or leads.
•28. Agent Arena: Fable leads in coding/research/document tasks per available reports.
Broader Indices & Knowledge
•11. AAI Index (Artificial Analysis Intelligence Index): Fable 5 ~65 / 64.9 (often #1) vs GPT-5.5 60.
•29. Vals Index: Fable 5 75.14% (#1).
•30. Vals Multimodal: Fable 5 74.15% (#1).
•32. MMLU Pro: Fable 5 91.50% (#1 on Vals).
•33. MMMU: Fable 5 89.31% (#1 on Vals).
•35. CorpFin: Fable 5 71.83% (#1 on Vals).
•37. ProofBench: Fable 5 77.00% (#1 on Vals).
Other / Niche Benchmarks
•8. GBAEval, 12–13. WeirdML / Reliability, 14. PencilPuzzleBench, 17. Stagehand Agent Evals, 18. PACT Negotiation, 19. Debate Benchmark, 24. ExploitBench, 25. Cyber ECI, 26. FrogsGame, 38. Public Benefits Bench: Limited or no direct public head-to-head scores yet (Fable 5 is very new). Fable generally leads on related agentic/cyber/coding tasks where data exists (e.g., strong on ExploitBench for Mythos variant; safeguards can affect Fable on pure cyber). Expect Fable advantage on most technical ones based on patterns.
Overall verdict:
Claude Fable 5 is the stronger model on the vast majority of these benchmarks (especially anything involving long-horizon coding, production-quality software engineering, complex agentic workflows, or hard reasoning). The leads are often substantial on the hardest subsets (e.g., FrontierCod
2
241
Jun 13
@grok how does fable do against 5.5 in the following benchmarks
1. FrontierMath Tier 4
2. FrontierMath Tier 1-3
3. SWE-Bench Pro
4. FrontierCode Diamond
5. FrontierCode Main
6. TerminalBench
7. KernelBench Hard
8. GBAEval
9. Humanity’s Last Exam (No Tools)
10. Humanity’s Last Exam (Tools)
11. AAI Index
12. WeirdML
13. WeirdML Reliability
14. PencilPuzzleBench
15. AutomationBench
16. OSWorld
17. Stagehand Agent Evals
18. PACT Negotiation
19. Debate Benchmark
20. GDPval-AA
21. GDPpdf
22. Legal Agent Benchmark
23. HealthBench
24. ExploitBench
25. Cyber ECI
26. FrogsGame
27. ALE-Bench
28. Agent Arena
29. Vals Index
30. Vals Multimodal
31. LiveCodeBench
32. MMLU Pro
33. MMMU
34. IOI
35. CorpFin
36. VibeCode
37. ProofBench
38. Public Benefits Bench
1
83

Synergy guidance boosts announcement reactions but often fails to materialise. Disclosers show more goodwill impairments, weaker performance, and lower long‑run returns. External verification (UK Rule 28) improves credibility. spkl.io/601678Zna #CorpFin
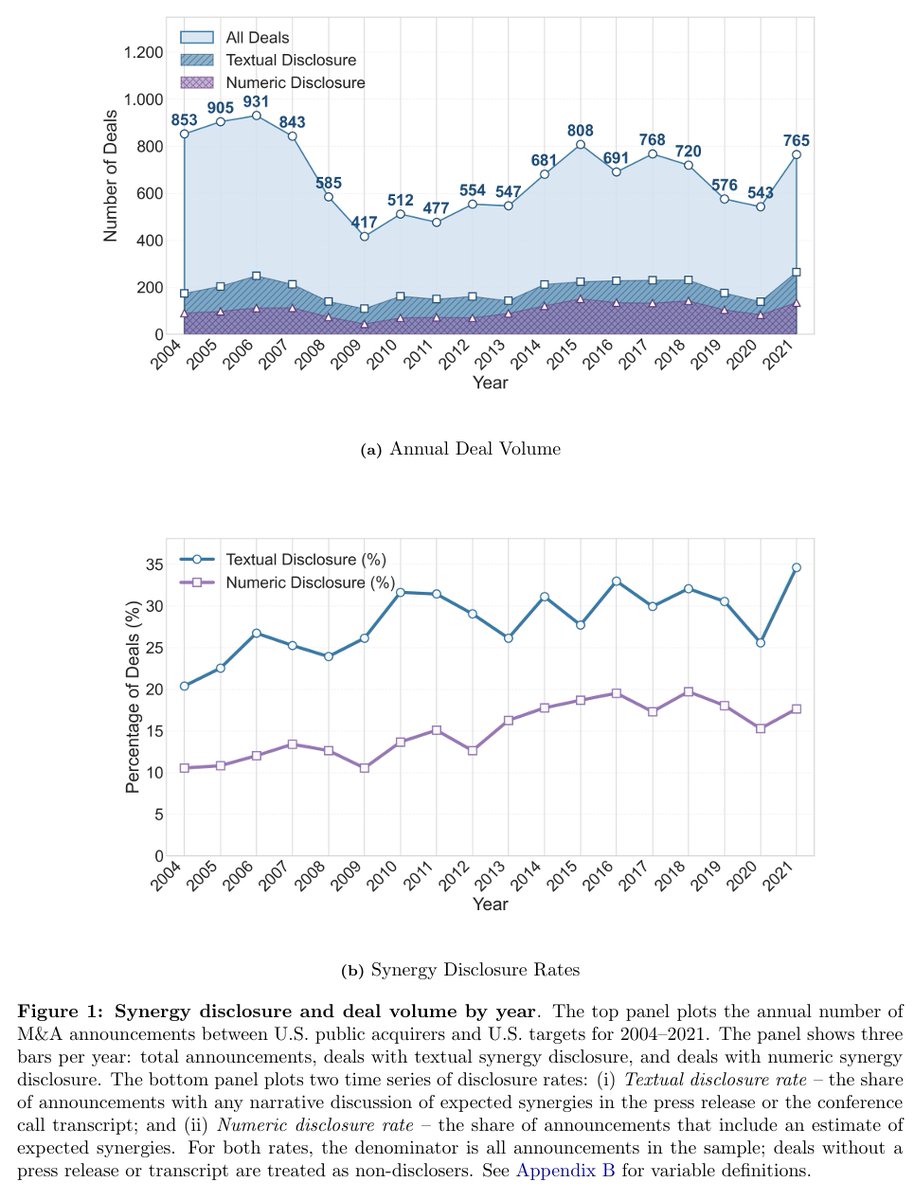
169



Jun 6
Warner Bros/Paramount - from CTFN, May 11, 2026: Hammer raised but not yet swung by state AGs
“ … the states’ core antitrust argument is both simple and solid: the merger reduces the number of major movie studios from five to four. Those five studios currently account for roughly 91% of all box office revenue — a share they have maintained for decades.
The comparison being drawn is to the Simon & Schuster publishing case, in which five publishers controlled approximately 90% of the market and a five-to-four combination was successfully challenged.
A five-to-four merger is seen as a significant antitrust risk, particularly under US and international regulations, as it drastically increases market concentration and the likelihood of reduced competition. Such a transaction is considered a ‘high-concentration’ move that likely violates guidelines aimed at preventing a substantial lessening of competition or the creation of a monopoly.
The theory extends into labor markets.”
Visit ctfn.news or write to info@ctfn.news for more information.
$WBD $PSKY #mergers #antitrust #entertainment #corpfin

3
5
572

Jun 3
• tinystat — CFA Level II Quant Methods (55 testes, F=t² etc.)
• corpfin-lab — CFA Level II Corp Finance (81 testes, MM, DuPont, M&A)
136 testes combinados, todos verificando IDENTIDADES algébricas
github.com/sauloduttra/tinys…
github.com/sauloduttra/corpf…
#cfa #python #quant #finance #fromscratch
2
3
41

May 31
Sudahkah kamu akses modul terbaru di website finansiologi? Ada concept guide dan practice quiz yg biasa dipakai di rekrutmen financial consultant/ advisory (partly CFA Lv 1).
Bisa jg diaplikasikan utk karier analyst, banker, FPnA/ CorpFin, dll.

Dear teman finansiologi, kami baru saja update materi baru buat yg mau berkarier sebagai konsultan/ advisor, analyst, banker, dan FPnA.
Materi ini dpt kamu akses secara GRATIS di website kami. Cobain quiznya dan share hasilnya di X dan Linkedin😃
Link di komentar
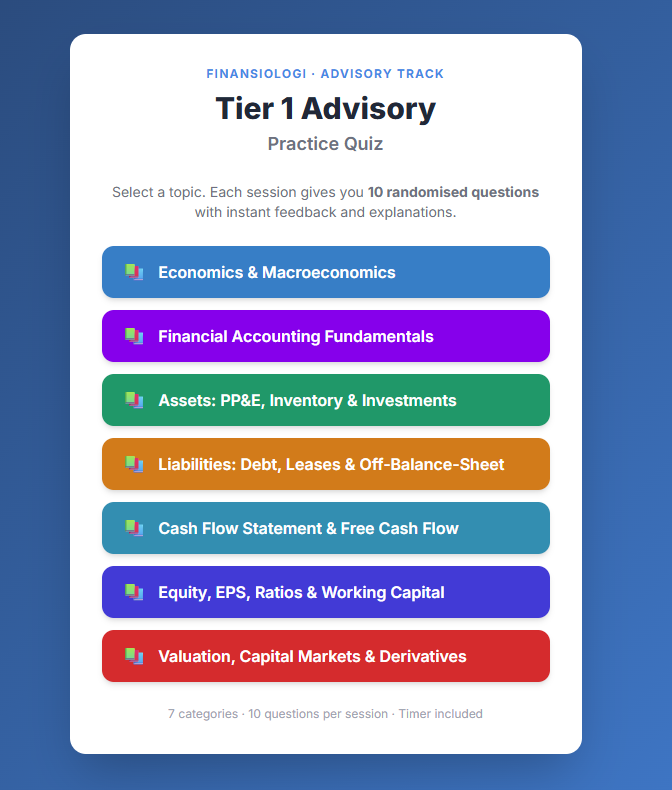
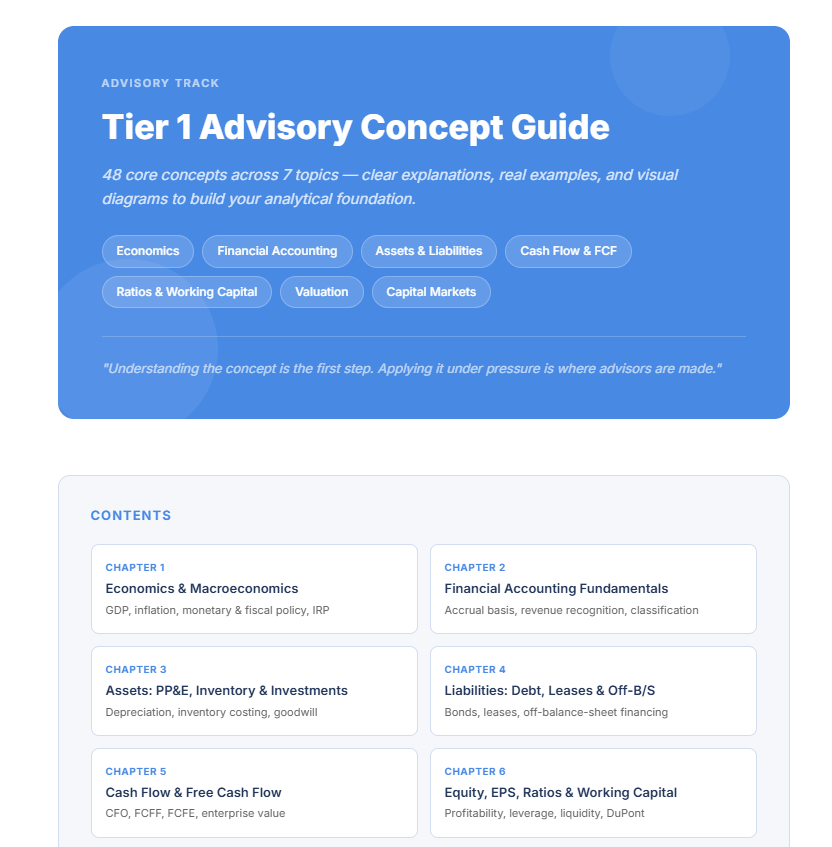
2
11
892

Average latency is 1,778s on the Vals Index, driven by agentic tasks (VCB 6,683s; IOI 4,380s). Non-agentic benchmarks are much faster (GPQA 127s, MMLU-Pro 29s, CorpFin 20s). At $5.30/test, it's more expensive than Qwen 3.6 Plus ($1.43) but has substantially better agentic capability.
1
2
245
SWE-bench remains competitive with frontier models. On knowledge benchmarks, Qwen 3.7 Max is near the top: GPQA (90%), MMLU-Pro (89%), LCB (87%), and LegalBench (84.9%). It also scores well on domain-specific tasks like TaxEval v2 (7/133), CorpFin v2 23/107, and MedScribe 21/59.
1
2
678

May 21
Yang 2.9Bn nopang yang total 12 Bn complex nya. Tapi dr yg 2.9 itu berapa yang strategic (collateralized) berapa yang public traded (inflated float capitalization, skrg kena geprek). Ketika yg public - strategic nya kena unwind, ratio Equity to Debt masuk zona breach covenant?. What would make of the whole Complex? CorpFin MasterClass Wreck In Motion
Mar 26

$12Bn Stack Built Upon Public-Strategic Equity to Top the Cards, battle on 2 Front; Finance&Operational.Bulkbwere bet on TPIA's upsizing capacity-expansion.Given ME situation,scarcity on feedstock will impose downtime on production-while debt goes on. If im bbni i'd be on lookout

2
1
26
3,994

May 19
FFS at this point just bite the bullet & hire a couple former SEC CorpFin employees who handled these reviews in the past to look at it before submitting. Christ almighty 🤦♂️
1
1
12
715
May 12
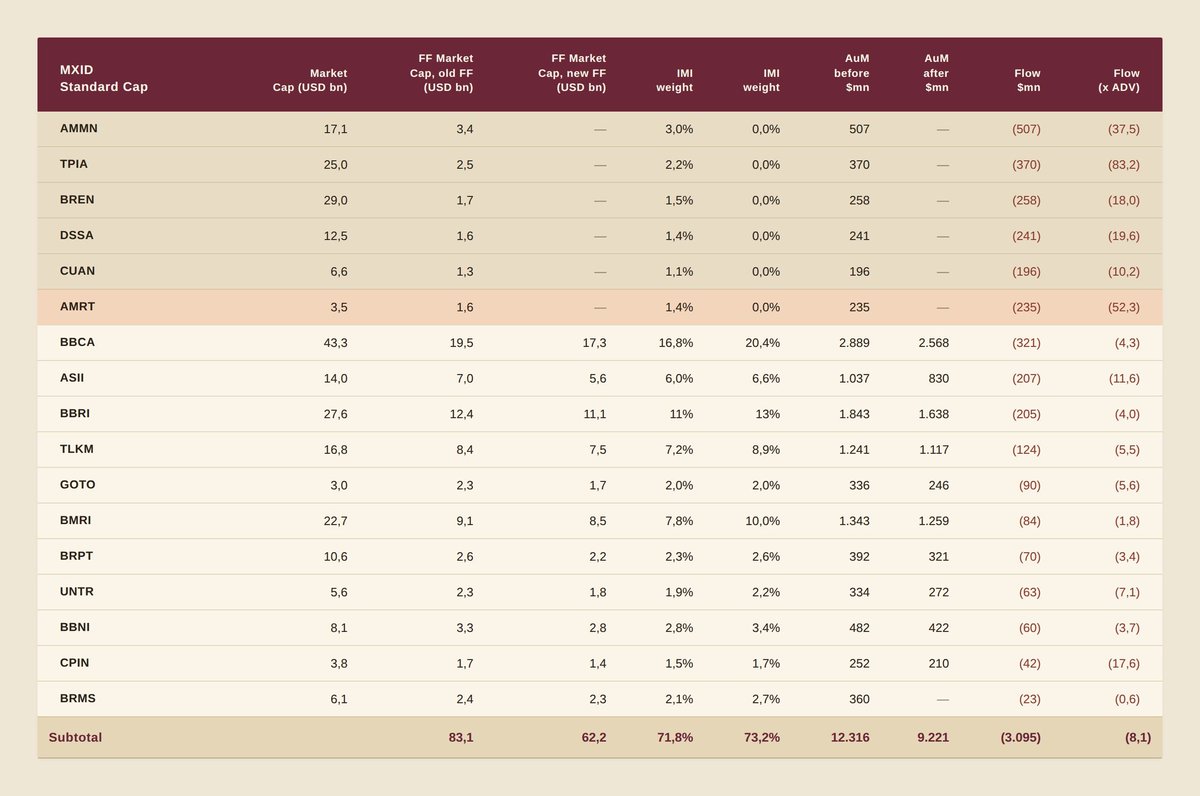
Event Horizon : Larger Downweight, Concentrated on The Scallywags. Shiver me Timber IDR Impact 😵💫
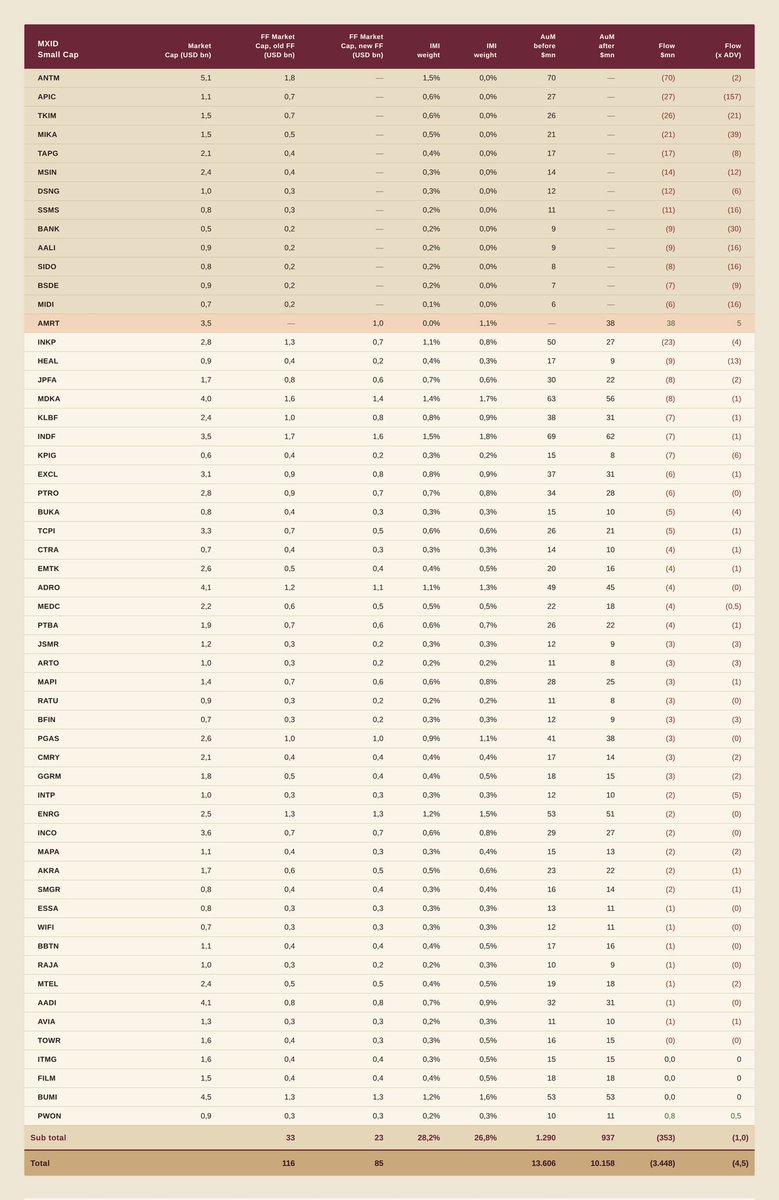
Verdict: Material negative impact. US$3.45bn aggregate passive outflow,
Est. outflow $3.45bn
Standard Cap $3.1bn
Small Cap $353mn
Est. Indonesia weight in MSCI EM IMI to decline from 0.86% to 0.63%
Concentrated in six Standard Cap deletions, with TPIA carrying outsized liquidity stress at 83x ADV.
Total estimated passive outflow lands at US$3,448mn Standard Cap drives US3,095mn (90%), Small Cap contributes US353mn. AuM tracking Indonesian equities via MSCI Indonesia IMI compresses from US13.6bn to US10.2bn, a 25% decline in passive footprint. no longer marginal rebalance; it is the largest single-event Indonesia outflow since I remember, at Rupiah vantage point no less.
Barito complex takes a combined almost US$ 1Bn hit, testing their mettle in midst of real business capex cycle. This is one open corpfin class to observe.
BBCA & BBRI, Reprieve. outflow under $500Mn each. MSCI surprisingly fair on these. Local Money (ReksaDana) has been playing underweight ahead, this posit for their imminent cover window so natural domestic Bid should clear absorbs.
AMRT, Net Inflow. Dang Everyone Were Ready to Catch the Knife, But Pa Joko count his luck parlay.
AMMN, the endearing bless in disguise. Rare occasion of revulsion entry at "near fair price level", operating leverage right before industry structural uplift.
Bottom line: this is a high impact, low ambiguity passive event. More FX Impactful than I thought before. Patience Capital Remain Deployable on Mechanical Flush Event but Position sizing and execution windows should be wiser. 4-5 Days Execution
invoke your inner templeton, jangan lupa sarapan pondasi!
3
20
76
5,986

xAI is now shipping at lightspeed and just released a massive wave of updates that completely supercharges the Grok ecosystem
Here is everything you need to know:
Grok 4.3:
The best frontier intelligence-per-cost unit with massive 1M context window
It crushes in two brutal private “Vals AI” benchmarks, securing #1 in CaseLaw for complex Canadian legal reasoning and #1 in CorpFin for analyzing dense, long-context corporate finance agreements
Grok Voice Think Fast 1.0:
It's the most advanced voice AI built for the real world. It listens, reasons, and responds simultaneously with zero added latency
Currently Powering customer support and sales for Starlink - resolving 70% of support tickets and closing 20% of phone sales, fully autonomous. No human in the loop
Custom Voice & Voice Library:
A powerful new voice cloning suite. You can now clone a voice and deploy it instantly across Grok APIs for custom conversational agents
Grok Computer:
A fully autonomous desktop AI agent. It gets system-level CLI and file access, upgrading it from a chatbot to a true pair programmer that can directly read, write, run scripts, debug logs, refactor entire codebases, and generate visual assets
Grok Connectors:
Grok now natively integrates with your daily tools (Google Workspace, Notion, GitHub, Linear, Microsoft 365) right in the chat. You can also bring your own custom MCP servers to connect internal databases
Grok Imagine Quality Mode API:
A massive leap in visual realism. It solves AI text rendering with flawless multilingual typography, generates hyper-realistic textures, and offers precise brand control for enterprise marketing assets
Grok STT & TTS APIs:
Powerful standalone audio endpoints at disruptive pricing (TTS at $4.20/1M chars, STT at $0.10/hr). Features real-time WebSocket streaming, precise speaker diarization, smart inverse text normalization, and emotional speech tags like [laugh] or <whisper>

120
143
1,020
45,470

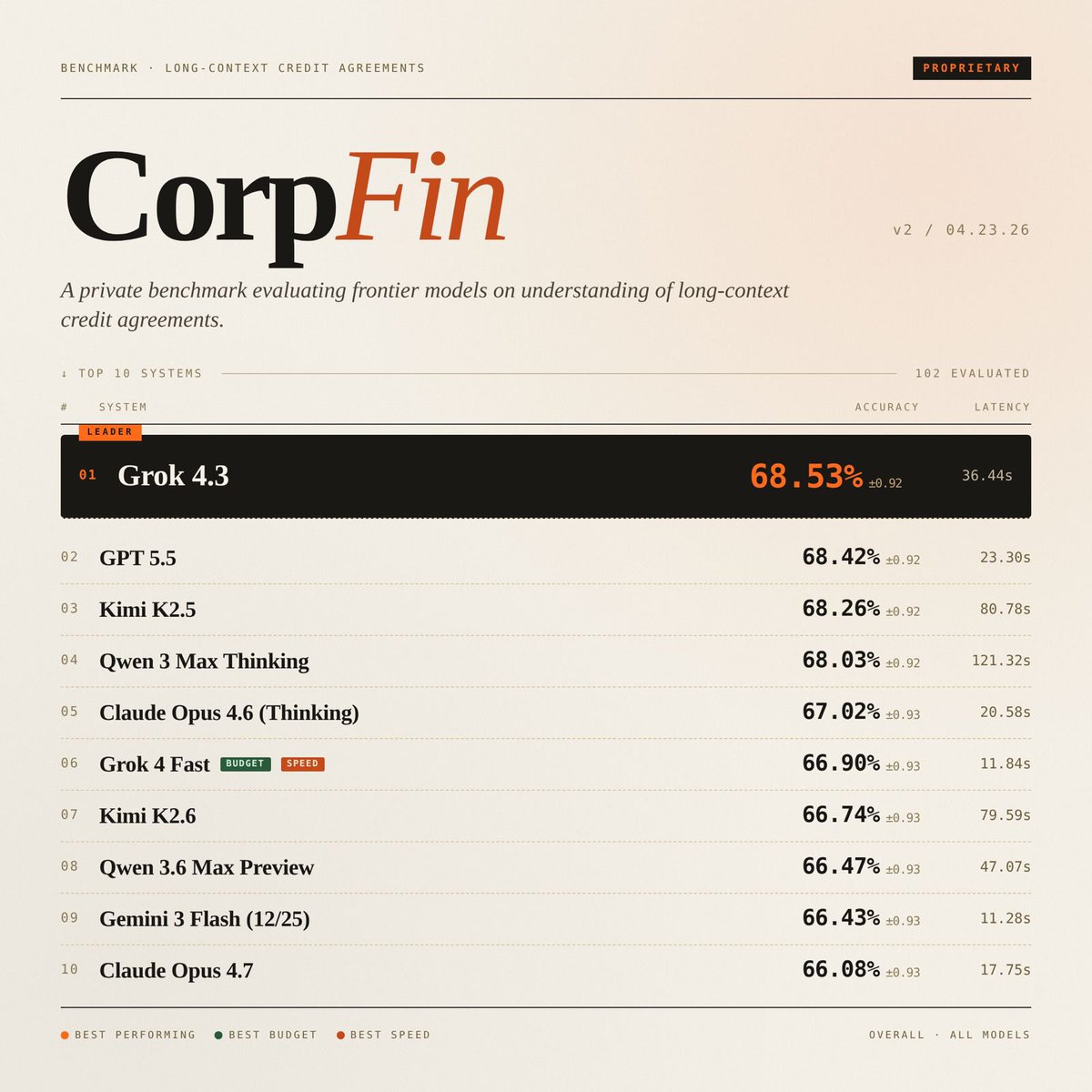
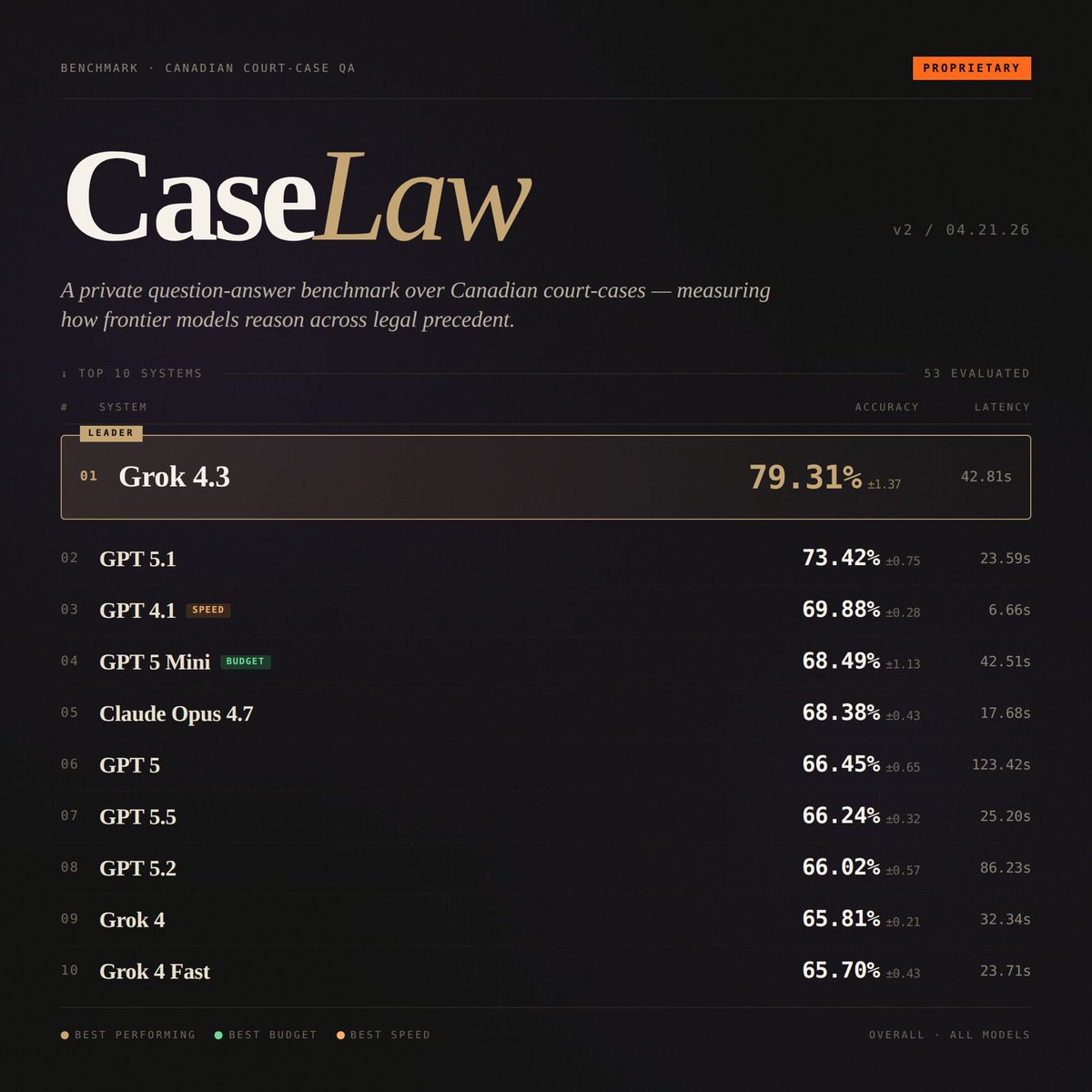
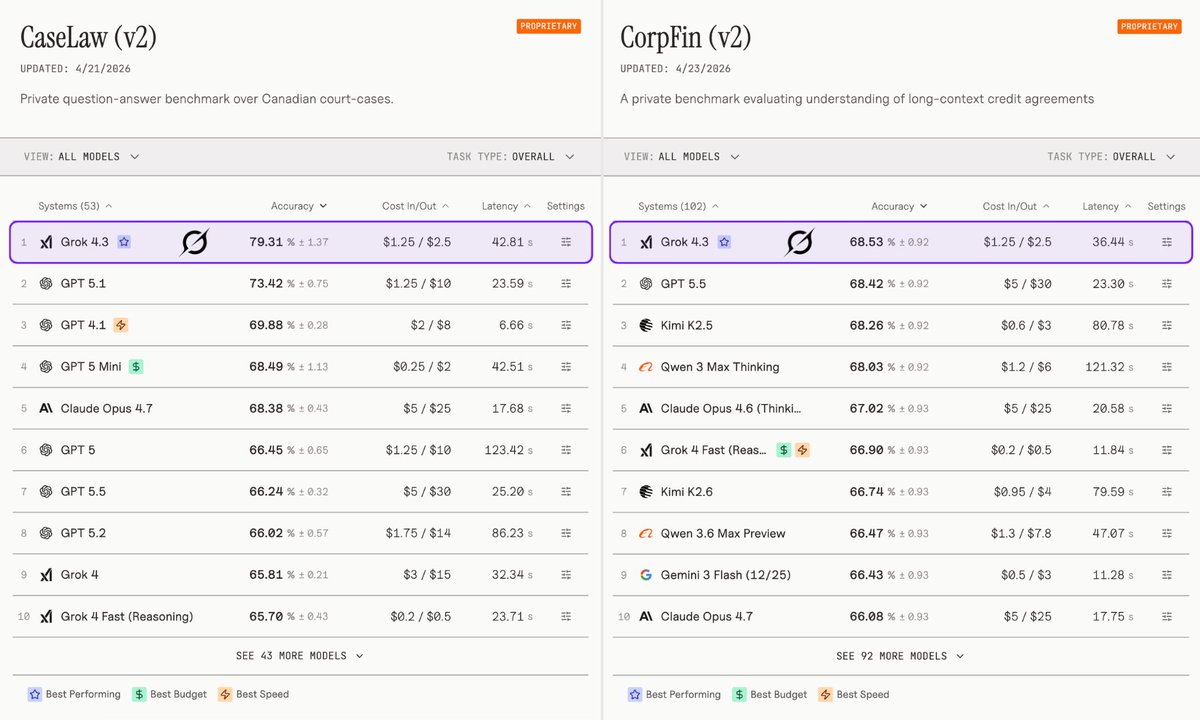
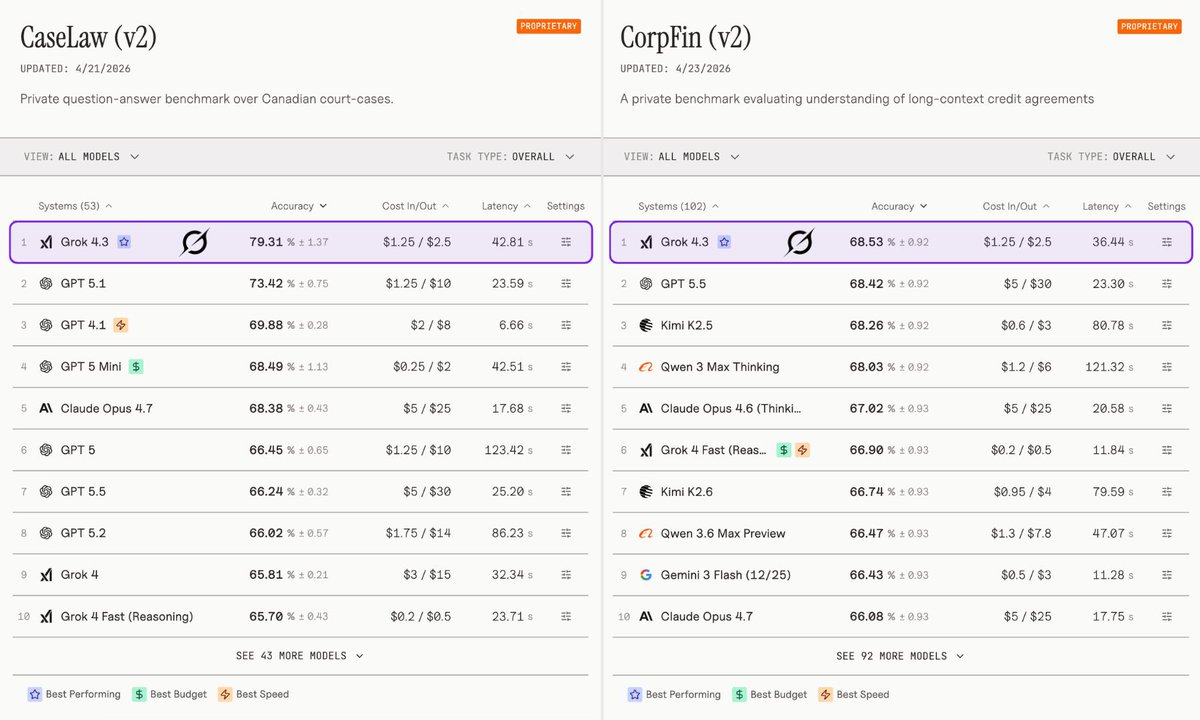
BREAKING: Grok 4.3 takes #1 on two specialized AI benchmarks for legal and financial reasoning.
It scored 79.3% on CaseLaw v2 (beating GPT 5.1 at 73.4%) and 68.5% on CorpFin v2 (edging GPT 5.5 at 68.4%), both private benchmarks run by Vals AI.
15
16
68
5,405
Grok 4.3 is now live on the xAI API
Built for precision, long-context reasoning, and elite instruction following
• Top-tier agentic tool calling
• Top-tier instruction following
• 1M token context window
• The best frontier intelligence-per-cost unit
It also took #1 on two brutal private “Vals AI” benchmarks:
• #1 CaseLaw (v2) - 79.31%
A real-world legal reasoning benchmark based on Canadian court cases, testing precedent understanding, judgment analysis, and answer precision
• #1 CorpFin (v2) - 68.53%
A long-context corporate finance benchmark testing understanding of dense credit agreements, clauses, obligations, and risk analysis
These are high-stakes reasoning evaluations - not simple benchmark tests
Grok 4.3 is proving itself on some of the hardest real-world legal and financial tasks
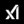
Grok 4.3 is now live on the xAI API. It’s our fastest, most intelligent model to date.
It tops the @ArtificialAnlys leaderboards in agentic tool calling and instruction following, and ranks #1 in @ValsAI enterprise domains like case law and corporate finance.
Grok 4.3 supports a 1 million token context window and is priced at $1.25/m input and $2.50/m output.
Create an API key and start building: console.x.ai/team/default/ap…

45
34
227
12,795

Grok 4.3은 법률과 돈으로 세계에서 가장 똑똑한 AI가 되었습니다.
🖕법률과 경제쪽,
특히 법률쪽은 일반인들이 대면했을때 가장 당황하는 분야 중에 하나입니다.
변호사 수임료도 적은 금액이 아니기 때문에 도움이 필요한 분야임은 확실합니다.
이 부분에서 신뢰할 수 있는 AI가 있다는 건 정말 큰 힘이 될 수 있습니다.
Grok이 1위를 했다니 반가운 소식이 아닐 수 없네요.
개인적으로 답변을 받은 뒤에,
"위 내용이 정확한 근거로 사실대로 잘 작성되었는지 확인하고, 잘 작성되었으면 근거자료를 표기해서 다시 한 번 작성해줘"
라는 프롬프트를 한 번 더 입력하시기를 추천 드립니다. 꼭이요!!
아래는 X Freeze가 작성한, 이 인용 게시물의 앞부분입니다.👇
----------
다른 어떤 모델도 "Vals AI" 벤치마크에서 이길 수 없는 두 가지 잔인한 비공개 테스트에서 1위를 차지했습니다
#1 판례 (v2) - 79.31% 정확도
실제 캐나다 법원 사건에 대한 비공개 Q&A 벤치마크. 깊은 법적 추론, 판례 이해, 복잡한 판결의 정확한 답변을 테스트합니다. (GPT-5.1을 73.42%로 압도함)
#1 CorpFin (v2) - 68.53% 정확도
장기 신용 계약에 대한 비공개 벤치마크. 모델이 밀집된 다단계 금융 계약, 용어, 위험 및 조항을 얼마나 잘 이해하는지 평가합니다
.
.

Grok 4.3 just became the smartest AI in the world at law and money
It took #1 on TWO brutal private tests no other model could win on “Vals AI” benchmarks
#1 CaseLaw (v2) - 79.31% accuracy
Private Q&A benchmark over real Canadian court cases. Tests deep legal reasoning, precedent understanding, and precise answers from complex judgments. (outranking GPT-5.1 at 73.42%)
#1 CorpFin (v2) - 68.53% accuracy
Private benchmark on long-context credit agreements. Evaluates how well models truly understand dense, multi-page financial contracts, terms, risks, and clauses
These are not just basic tests - they’re real-world, high-stakes legal financial reasoning challenges
Grok 4.3 leads in accuracy on both, proving it’s not just fast or cheap… it’s the smartest at the hardest real world tasks
xAI is building the reasoning engine the world needs
1
2
42

May 5
Grok 4.3 剛剛成為世界上最聰明的法律與金融 AI
它在「Vals AI」基準測試中拿下兩項殘酷的私人測試第一名,沒有一個其他模型能贏得這些測試
#1 CaseLaw (v2) - 79.31% 準確率
基於真實加拿大法院案例的私人問答基準測試。考驗深度法律推理、判例理解,以及從複雜判決中給出精確答案。(超越 GPT-5.1 的 73.42%)
#1 CorpFin (v2) - 68.53% 準確率
針對長篇上下文信用協議的私人基準測試。評估模型如何真正理解密集的多頁金融合約、條款、風險和子句
這些不只是基本測試 - 它們是現實世界、高風險的法律 金融推理挑戰
Grok 4.3 在兩者上都領先準確率,證明它不只是快或便宜…它是最聰明的,專精於最艱難的現實世界任務
xAI 正在打造世界所需的推理引擎
1
164