
20 Nov 2025
Data is the new raw material—refine it into durable decisions.
My textbook guides you from preprocessing to Power BI.
Available in New Zealand and Australia
Amazon AU: amazon.com.au/s?k=9789365892… | Booktopia: booktopia.com.au/search.ep?k… | Dymocks: dymocks.com.au/data-mining-a… | Angus & Robertson: angusrobertson.com.au/books/… | Fishpond: fishpond.co.nz/q/97893658922… | Abbeys: abbeys.com.au/book/data-mini… | Paper Plus: paperplus.co.nz/shop/books/n… | eBay AU: ebay.com.au/itm/146940629417
#Australia #NewZealand #datasciencetutorials #BPB
2
61

11 Nov 2025
A Coding Implementation to Build and Train Advanced Architectures with Residual Connections, Self-Attention, and Adaptive Optimization Using JAX, Flax, and Optax
In this tutorial, we explore how to build and train an advanced neural network using JAX, Flax, and Optax in an efficient and modular way. We begin by designing a deep architecture that integrates residual connections and self-attention mechanisms for expressive feature learning. As we progress, we implement sophisticated optimization strategies with learning rate scheduling, gradient clipping, and adaptive weight decay. Throughout the process, we leverage JAX transformations such as jit, grad, and vmap to accelerate computation and ensure smooth training performance across devices.
Check out the FULL CODES here: github.com/Marktechpost/AI-T…
Tutorial: marktechpost.com/2025/11/10/…
#machinelearningprojects #machinelearningtutorial #machinelearningcode #machinelearningforbeginners #DataScientist #datasciencetutorials

6
11
582

5 Nov 2025
Starting now! R/Pharma Keynote with @simonpcouch on Practical AI for #datasciencetutorials
events.zoom.us/ev/Ai-geyS63A…
#LLMs #GenAI #RStats #Python

ALT Simon (he/him), an R developer and data scientist. I build tools for data scientists at Posit PBC (formerly RStudio).🐛 focused on helping R users get the most out of LLMs: tidyverse/vitals: LLM evaluation posit-dev/mcptools: Model Context Protocol (MCP) servers and clients in R posit-dev/btw: easily provide context on R stuff to LLMs simonpcouch/gander: high-performance, low-friction chat for data science simonpcouch/chores: an extensible collection of LLM assistants simonpcouch/predictive: an agentic frontend for predictive modeling with tidymodels simonpcouch/kapa: RAG-based search via the kapa.ai API
1
452

1 Dec 2023
Free Data science Lessons - Only 5 people #datascience #datasciencetutorials #datasciencelessons #datasciencemajor #datascienceinterview #datasciencecareeradvice #datasciencecertification #datasciencetoday #ngurubretton #ngurutheguru #ngurubrett
2
1
75
2,264

15 Feb 2023
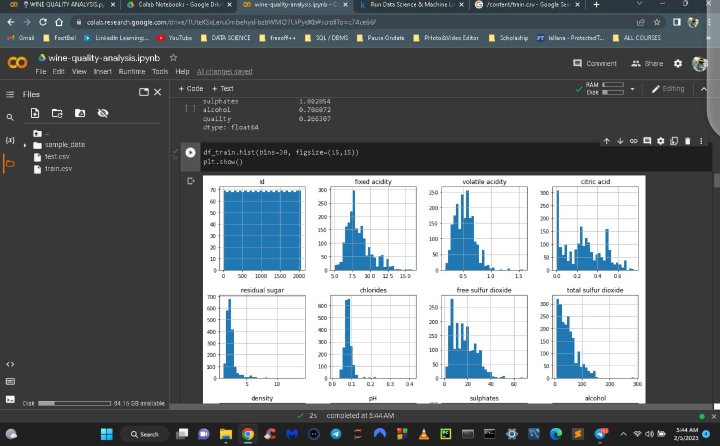
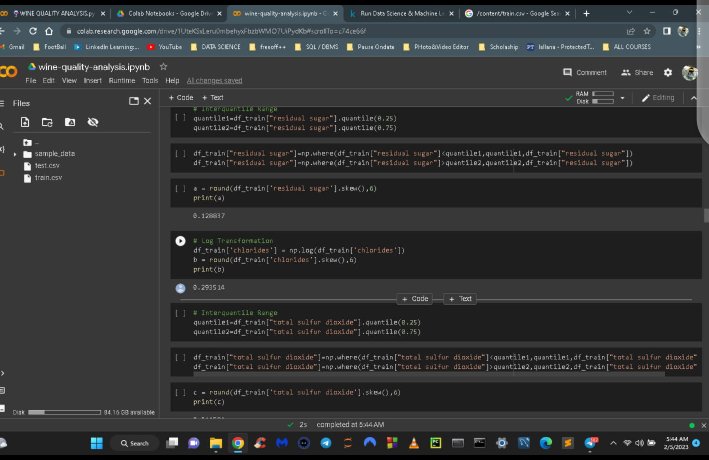
Testing 03
Visualisation 📈
#DataScience #DataAnalytics #DataScienceToolkit #DataScienceCommunity #DataScienceBlog #DataScienceMonth #DataScienceChallenge #DataScienceTutorials #DataScienceProject
1
9
180

30 Sep 2021
youtu.be/nazZi8VbR54
Divisive Hierarchical Clustering | Data Science for beginners | Learn AI with SOAI
#datascience #datasciencetutorials @societyofai

2

Check out which Dataiku Academy courses had the highest enrollment from 2020 so you can decide which ones to take in the new year! | bit.ly/3qnSaBJ | #upskilling #datasciencetutorials #datasciencelearning
1
2

5 Nov 2020
Follow @philodiscite for more.
.
.
.
.
.
.
.
.
.
.
.
#pythonfordatascience #datascience
#datasciencetutorials #deeplearning #programminglanguagesfordatascience
#advacedpythonprojects #r #ml #ai #machinelearning #programminghumour
#pythonprogramming #pythonprojects
#python


1
2


2 May 2020
Recommended Data Science Books For Beginners!
amzn.to/2U299Ks
amzn.to/2U9lnkq
#CoderzColumn #DataScience #Pythonanywhere #DataScience #DataScienceTutorials #Saturday #Weekend #WeekendVibes
2
4
25 Apr 2020
Recommended Data Science Books For Data Science Enthusiasts
amzn.to/2U299Ks
amzn.to/2U9lnkq
#CoderzColumn #DataScience #DataScienceTutorials #Saturday #weekendvibes
1
4
25 Apr 2020
Want To Learn About Holoviews?? Then let’s get started!
Holoviews is an open-source python plotting library designed to make plotting easy and interactive.
Read more @ coderzcolumn.com/tutorials/d…
#CoderzColumn #DataScience #DataScienceTutorials #Saturday #weekendvibes

2
5
22 Apr 2020
How To Create A Dashboard Using Python(Matplotlib and Panel)
Read more @https://coderzcolumn.com/tutorials/data-science/how-to-create-dashboard-using-python-matplotlib-panel
#CoderzColumn #DataScience #DataScience #DataScienceTutorials
@Datascience__
@datagenius @ChakerRzouga

2
4
22 Apr 2020
Recommended Data Science Books
amzn.to/2U299Ks
amzn.to/2U9lnkq
#CoderzColumn #DataScience #Pythonanywhere #DataScience #DataScienceTutorials #Saturday #Weekend #WeekendVibes
1
1
3
14 Apr 2020
#BigData data is at the foundation of all the megatrends that are happening.”
-ChrisLynch
#CoderzColumn #DataScience #BigData #DataScienceTutorials
1
2
11 Apr 2020
Recommended #DataScience Books You Would Love To Read During This #Quarantine Time
amzn.to/2U299Ks
amzn.to/2U9lnkq
#CoderzColumn #DataScience #Pythonanywhere #DataScience #DataScienceTutorials #Saturday #Weekend #WeekendVibes #QuarantineLife
3
3
31 Mar 2020
Mask R-CNN has been the new state of the art in terms of instance segmentation. #DataScience #DataScienceLearning #CoderzColumn #DataScienceTutorials
2
3
14 Mar 2020
Recommended Books
amzn.to/2U299Ks
amzn.to/2U9lnkq
#CoderzColumn #DataScience #Matplotlib #DataScienceTutorials #Saturday #weekend
2
5
14 Mar 2020
Recommended Books
amzn.to/2U299Ks
amzn.to/2U9lnkq
#CoderzColumn #DataScience #Matplotlib #DataScienceTutorials #Saturday #weekend
2
2

14 Mar 2018
Introduction to #MultipleLinearRegression #Video Playlist. What are Regression Techniques in #DataScience ? buff.ly/2Dq67VW
#DataScienceCourse
#ExcelRSolutions #StatisticalControlCharts #SPC #datascienceforbeginners #datasciencetutorials #WednesdayWisdom #Wednesday
1
4