
Apr 30
Ready to land your dream AI role? 💼✨
Stop guessing what recruiters want. Get the AI Interview Questions and Answers Masterclass and walk into your next interview with total confidence.
Get the masterclass: 🔗 analyticsvidhya.com/courses/…
#CareerAdvice #AI #DataScienceInterview #FreeCourse #TechCareer

1
3
198

4 Jun 2025
Top 60 Data Science Interview Questions and Answers | Guide by @roadmapsh & @iChuloo
roadmap.sh/questions/data-sc…
#InterviewTips #DataScienceInterview #Statistics #Python #TechRoles #Hackmamba
1
1
3
154

20 Dec 2023
🚀 Checkout Finetuning Open Source Large Language Models - YouTube Playlist🚀🔥
👉 On my YouTube Channel
🟠 youtube.com/playlist?list=PL…
#llm #Largelanguagemodels #Llama2 #MachineLearning #ArtificialIntelligence #datascience #nlp #textprocessing #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #datascience #nlp #textprocessing #tensorflow #pytorch #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #pythonprogramming #python #100DaysOfMLCode #softwareengineer #dataanalysis #datascienceinterview #interviewprep #interviews #python #programming #coding #programmer #developer #coder #code #computerscience #technology #pythonprogramming #software
2
12
92
32,537

1 Dec 2023
Free Data science Lessons - Only 5 people #datascience #datasciencetutorials #datasciencelessons #datasciencemajor #datascienceinterview #datasciencecareeradvice #datasciencecertification #datasciencetoday #ngurubretton #ngurutheguru #ngurubrett
2
1
75
2,264
27 Nov 2023
Massive Cost Saving on OpenAI API Call using GPTCache with
@langchain | Large Language Models
🔥🚀 Checkout on my #YouTube channel 🔥🚀
youtube.com/watch?v=zLRZwQzO…
---------------------
#llm #Largelanguagemodels #Llama2 #Weaviate #vectordb #vector #pinecone #ai #MachineLearning #ArtificialIntelligence #datascience #nlp #textprocessing #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #datascience #nlp #textprocessing #tensorflow #pytorch #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #pythonprogramming #python #100DaysOfMLCode #softwareengineer #dataanalysis #datascienceinterview #python #programming #coding #programmer #developer #coder #code #computerscience #technology #pythonprogramming #software

3
19
7,056
31 Oct 2023
Web scraping with Large Language Models (LLM)-AnthropicAI LangChainAI
👉 Checkout on my #YouTube channel
🟠 youtube.com/watch?v=QAY82Uvr…
#opensource #langchain #LLM #vectorstore #NLP #ArtificialIntelligence #datascience #textprocessing #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #datascience #generativeai #generativemodels #OpenAI #GPT #GPT3 #GPT4 #chatgpt #MachineLearning #ArtificialIntelligence #datascience #nlp #textprocessing #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #datascience #nlp #textprocessing #tensorflow #pytorch #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #pythonprogramming #python #100DaysOfMLCode #softwareengineer #dataanalysis #datascienceinterview

1
4
17
1,703
31 Oct 2023
Massive Cost Saving on OpenAI API Call using GPTCache with LangChain | Large Language Models
👉 Checkout on my #YouTube channel
👉 youtube.com/watch?v=zLRZwQzO…
#opensource #langchain #LLM #vectorstore #NLP #ArtificialIntelligence #datascience #textprocessing #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #datascience #generativeai #generativemodels #OpenAI #GPT #GPT3 #GPT4 #chatgpt #MachineLearning #ArtificialIntelligence #datascience #nlp #textprocessing #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #datascience #nlp #textprocessing #tensorflow #pytorch #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #pythonprogramming #python #100DaysOfMLCode #softwareengineer #dataanalysis #datascienceinterview

1
3
9
948
27 Oct 2023
🚀 Dive into Self-attention Theory - the secret sauce in Transformers & Large Language Models that lets words whisper to each other for deeper meaning! 🚀🔥
Self-attention makes the transformer powerful. The intuition of self-attention is that the mechanism allows the model to focus on (attend to) the most relevant parts of the input. That is, to find the words of importance for a given query word in a sentence.
We know that a word can be encoded as a vector in an embedding. We can also encode the position of that word in the input sentence into a vector, and add it to the word vector. This way, the same word at a different position in a sentence is encoded differently.
---------------------------
**A single self-attention mechanism is called a head.**
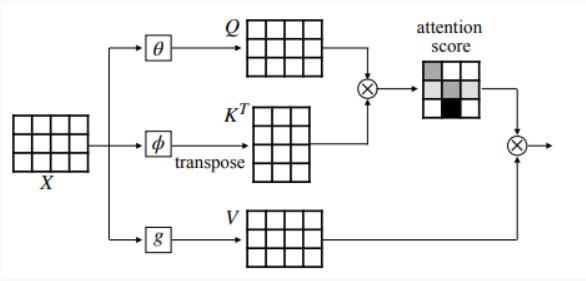
👉As part of the attention mechanism, we have 3 matrices Wq, Wk, and Wv that project each of the input embedding vectors into 3 different vectors: the Query, the Key, and the Value. The attention mechanism works by comparing the Query to every Key (using a score, usually a dot product, indicating similarity).
So for that, for each word, we take its related Query vector and compute the dot products with the Key vectors of all the other words. This gives us a sense of how similar the Queries and the Keys are, and that is the basis behind the concept of "attention": how much attention a word should pay to another word in the words input to understand the meaning of the sentence?
👉 This generates a set of attention scores, which are then normalized (using a softmax function) to sum to 1, so they can be considered as "weights." These weights determine how much attention each Value should get. Basically, A Softmax transform normalizes and further accentuates the high similarities of the resulting vector.
This results to one vector for each word. For each of the resulting vectors we now compute the dot products with the Value vectors of all the other words. We now have computed the self-attention!
The final output is a weighted sum of the Values, using the attention scores as weights.
👉 So again, the workflow goes like this - First, the input is fed into three separate linear layers. Two of those (the queries Q and the keys K) are multiplied, scaled, and turned into a probability distribution using a softmax activation function. Think of this probability distribution as describing which indices matter most for the output (i.e. which words in the prompt matter for the next word to be predicted).
Finally, the output is multiplied with values V. This thus gives V * the importance of each of the tokens in V.
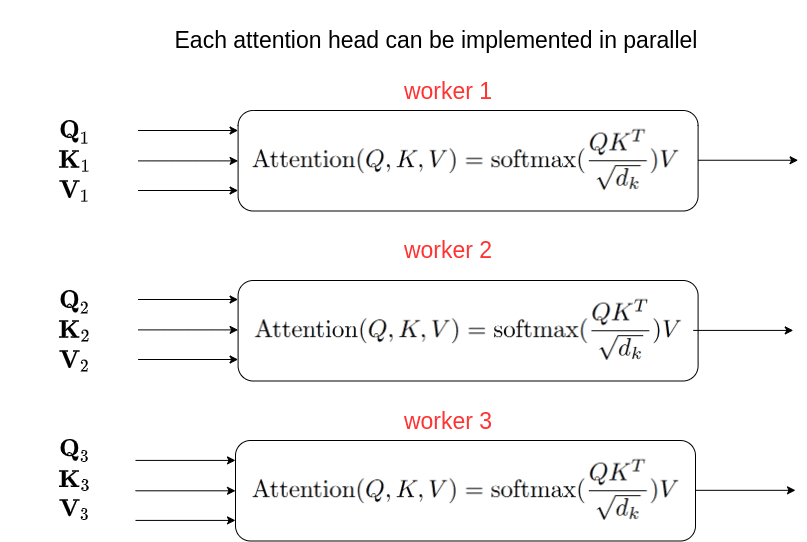
Repeat this process multiple times such that you generate multiple Attentions, and this gives you a multi-head attention layer. This helps diversify the learning of the possible relationships between the words.
A key observation is that the learnable parameters in the head are the three linear layers
The mathematical representation for the attention mechanism looks like the figure given below:
So, X is the input word sequence, and we calculate three values from that which is Q(Query), K(Key) and V(Value).
The task is to find the important words from the Keys for the Query word. This is done by passing the query and key to a mathematical function (usually matrix multiplication followed by softmax).
The resulting context vector for Q is the multiplication of the probability vector obtained by the softmax with the Value.
When the Query, Key, and Value are all generated from the same input sequence X, it is called Self-Attention.
The core concept behind self-attention is the scaled dot product attention.
Our goal is to have an attention mechanism with which any element in a sequence can attend to any other while still being efficient to compute.
------------------------
🟠 **Self Attention - More Explanations**
In he original Paper -"Attention as all you need" the general idea is that you learn a weight between each input item.
Self attention is very similar but instead of looking at the relationship between items in the input sequence and the output sequence you look at the relationship between each item in the input sequence and every other item in the input sequence.
A self-attention module takes in n inputs and returns n outputs. What happens in this module? In layman’s terms, the self-attention mechanism allows the inputs to interact with each other (“self”) and find out who they should pay more attention to (“attention”). The outputs are aggregates of these interactions and attention scores.
---------------------
💡**Now what is Multi-Head Attention**💡
In the transformer architecture you do this several times so each head attention relationships independently.
This is multi-headed self attention the attention is a series of three matrices that are combined together and every
value in each of those matrices is learned so it's initially randomized and then updated over time as the network
trains.
-----------------------
#MachineLearning #ArtificialIntelligence #datascience #nlp #textprocessing #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #datascience #nlp #textprocessing #tensorflow #pytorch #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #pythonprogramming #python #100DaysOfMLCode #softwareengineer #dataanalysis #datascienceinterview #interviewprep #interviews
4
7
930
23 Sep 2023
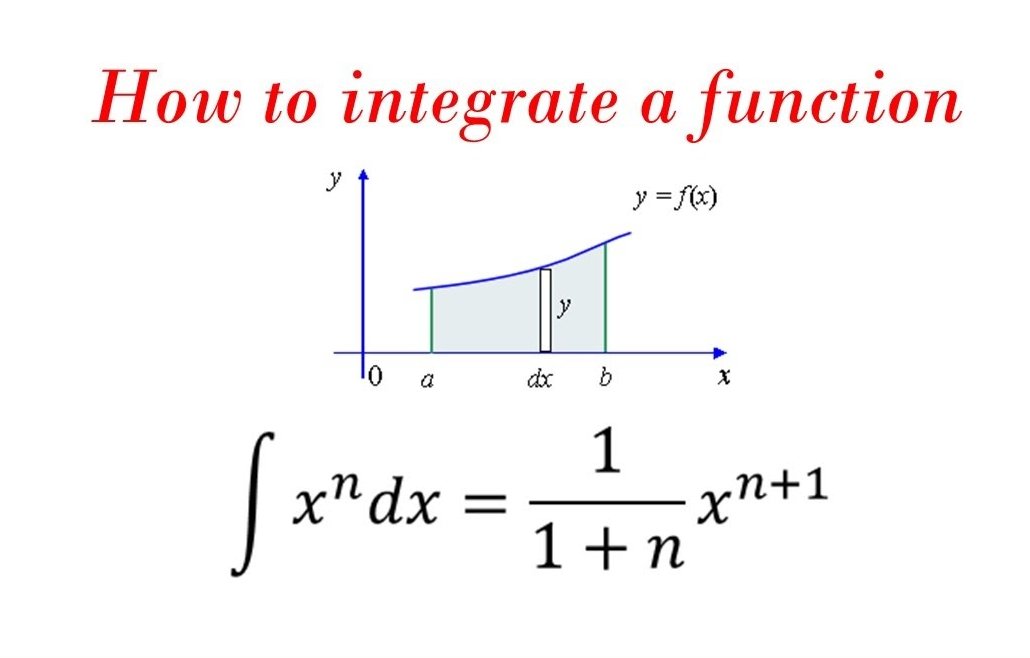
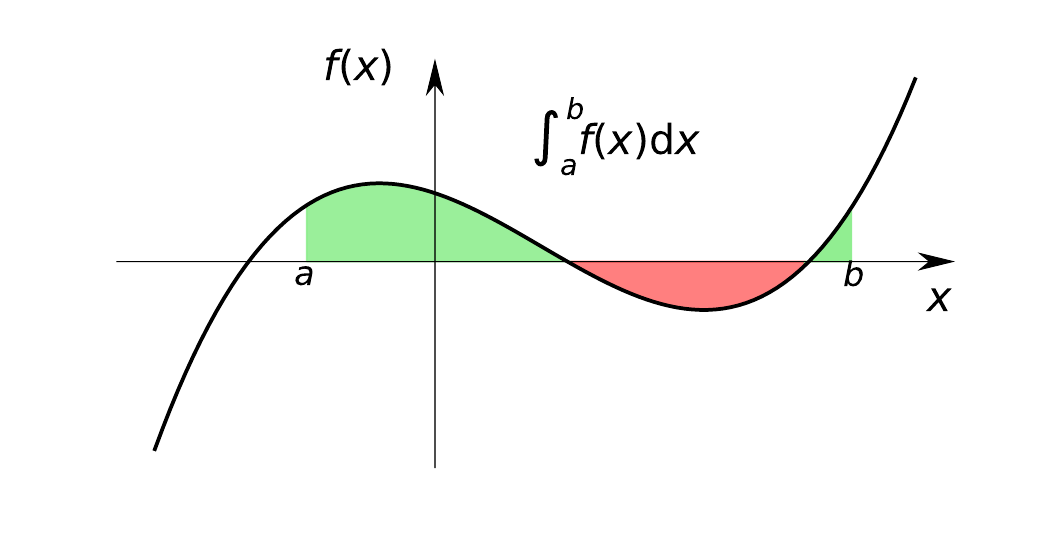
🔥 Integral of a Function - Used all the time in many Machine Learning, Deep Learning Algo - Get it in 2 Sentence 🔥
📌 Integral of a function represents the area under the curve of the function with respect to its independent variable, usually denoted by x
📌 In more formal terms, the integral aggregates infinitesimally small areas using limit processes to provide the total area, which can also be understood as an "antiderivative," reversing the operation of differentiation.
---------------------
#MachineLearning #ArtificialIntelligence #datascience #huggingface #nlp #textprocessing #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #datascience #nlp #textprocessing #tensorflow #pytorch #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #pythonprogramming #python #100DaysOfMLCode #softwareengineer #dataanalysis #datascienceinterview #python #programming #coding #programmer #developer #coder #code #computerscience #pythonprogramming #software #llm #Largelanguagemodels

1
2
433
23 Sep 2023
Matrix Multiplication - This is what runs the whole world of Machine Learning, Deep Learning, AI, LLM
And YOU are doing it in any of your Machine Learning Projects thousands of times
---------------------
#MachineLearning #ArtificialIntelligence #datascience #huggingface #nlp #textprocessing #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #datascience #nlp #textprocessing #tensorflow #pytorch #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #pythonprogramming #python #100DaysOfMLCode #softwareengineer #dataanalysis #datascienceinterview #python #programming #coding #programmer #developer #coder #code #computerscience #pythonprogramming #software #llm #Largelanguagemodels
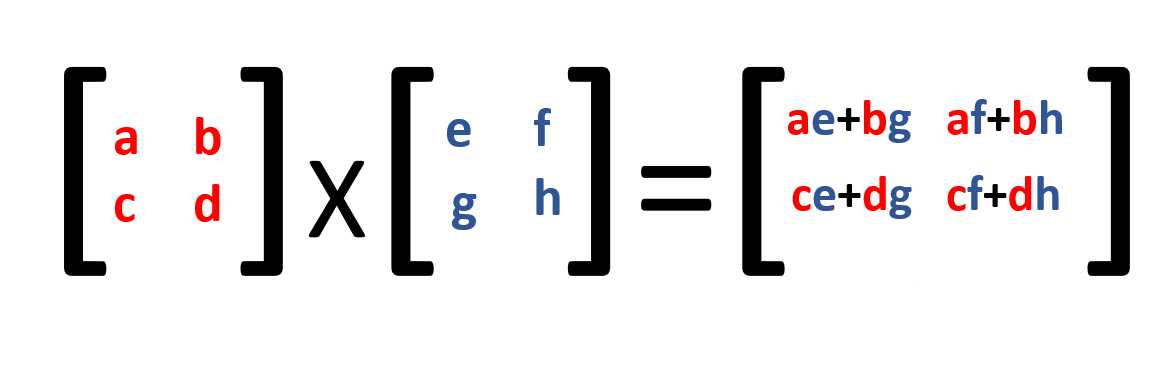
1
4
724
21 Sep 2023
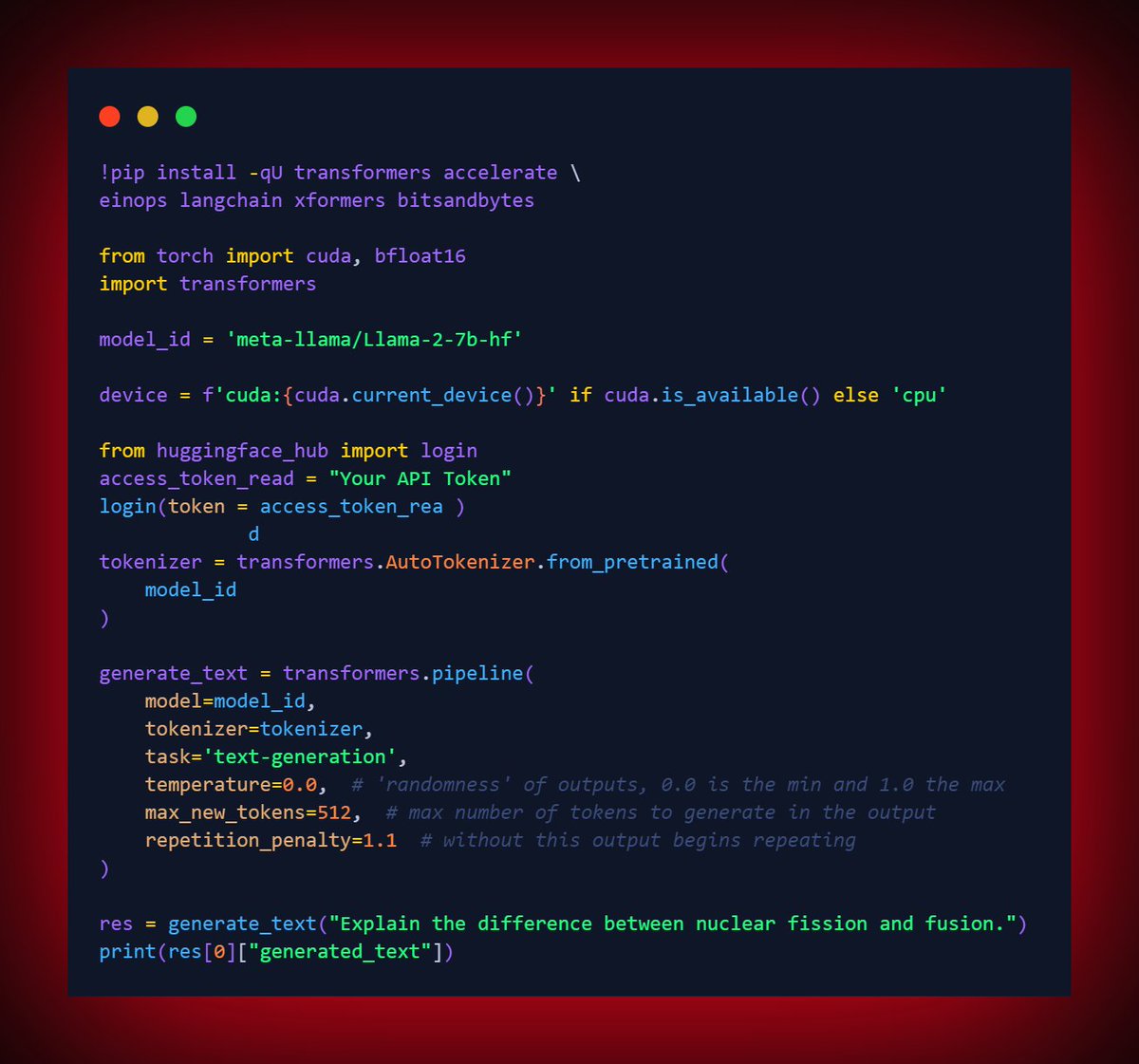
🚀🔥 LlaMa-2 Inferencing with PyTorch Locally with ONLY CPU🚀🔥
First, get access to the model following this official guide of Meta
Next need to initialize a `text-generation` pipeline with Hugging Face transformers, just as needed for any other pre-trained model.
The Pipeline mainly defines the following:
- The specific LLM, in this case it will be 'meta-llama/Llama-2-7b-hf'
- The respective tokenizer for the model
- access_token for your HuggingFace
---------------------
**What is transformers.AutoTokenizer**
The Transformers library introduces the concept of tokenizers to convert the input data, which are typically text strings, into a format that can be used by these pre-trained models.
A tokenizer takes care of converting your input into a format that the model can understand. It generally includes tasks like splitting the input into tokens (words, subwords, or characters), mapping these tokens to their respective IDs in the model's vocabulary, creating attention masks to handle different sequence lengths, and other model-specific requirements.
Now, coming to `transformers.AutoTokenizer`, it is a class in the Transformers library that allows you to automatically instantiate the correct tokenizer associated with the model you want to use. When using a pre-trained model, it's crucial to use the associated tokenizer because each pre-trained model could be tokenized in a specific way during its training. `transformers.AutoTokenizer.from_pretrained('model_name')` will automatically fetch the relevant tokenizer class based on the model name provided, instantiate it, and load the associated vocabulary.
For example, if you're using a BERT model, the AutoTokenizer will instantiate a BERT-specific tokenizer that uses WordPiece tokenization. If you're using a GPT-2 model, it will instantiate a GPT-2-specific tokenizer that uses Byte Pair Encoding (BPE) tokenization.
In essence, `transformers.AutoTokenizer` simplifies the process of getting the right tokenizer for your pre-trained model, helping ensure consistency between the tokenization process and the model you are using.
----------------------
👉 If you enjoyed this post:
✅1. Give me a follow @rohanpaul_ai for more of this every day and
✅2. Like & Retweet this tweet:
✅3. Consider subscribing to my MachineLearning YouTube channel -
youtube.com/@RohanPaul-AI
#opensource #Llama2 #largelanguagemodel #Llama2 #LLM #vectorstore #NLP #ArtificialIntelligence #datascience #textprocessing #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #datascience #generativeai #generativemodels #OpenAI #GPT #GPT3 #GPT4 #chatgpt #langchain #MachineLearning #ArtificialIntelligence #datascience #nlp #textprocessing #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #datascience #nlp #textprocessing #tensorflow #pytorch #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #pythonprogramming #python #100DaysOfMLCode #softwareengineer #dataanalysis #datascienceinterview
9
20
1,672
21 Sep 2023
🚀 Contemplating deploying a Large Language Model (LLM) in production? Here's some important factors to consider:🚀🔥
⏳Sequence Length Restriction
Various LLMs come with differing maximum input sequence lengths. For Falcon-40B, it's capped at 2048 tokens, for StableLM-7B, the limit is 4096, and for Anthropic's Claude, it goes up to 100K tokens. These limitations dictate the volume of data that can be processed by the LLM. While short queries present no challenges, intricate ideas, engineered prompts, or additional contexts like full-text documents may encounter input truncation or cease token creation.
💸Latency & Expenditure
The longer the input sequence, the higher the latency. Thanks to the quadratic computational cost of the Transformer's self-attention mechanism, adding tokens means increased processing time and higher costs. For instance, 4000 input tokens & 10k executions could cost $1800 with GPT-4 (4k) and $140 with GPT-3.5-turbo (16k) per OpenAI API Pricing.
🔓Prompt Injection Risk
Deploying an LLM could open doors to prompt injection, a way for hackers to manipulate your model's output. This can be a serious risk if your LLM handles internal documents with vector databases or has been fine-tuned using sensitive data.
In essence, scalability is a big challenge when it comes to using LLMs in production. Issues like cost, latency, sequence length limits, and data leaks make it a difficult task, needing vigilant attention in recent times."
---------------------
#llm #Largelanguagemodels #Llama2 #MachineLearning #ArtificialIntelligence #datascience #nlp #textprocessing #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #datascience #nlp #textprocessing #tensorflow #pytorch #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #pythonprogramming #python #100DaysOfMLCode #softwareengineer #dataanalysis #datascienceinterview

1
3
810
20 Sep 2023
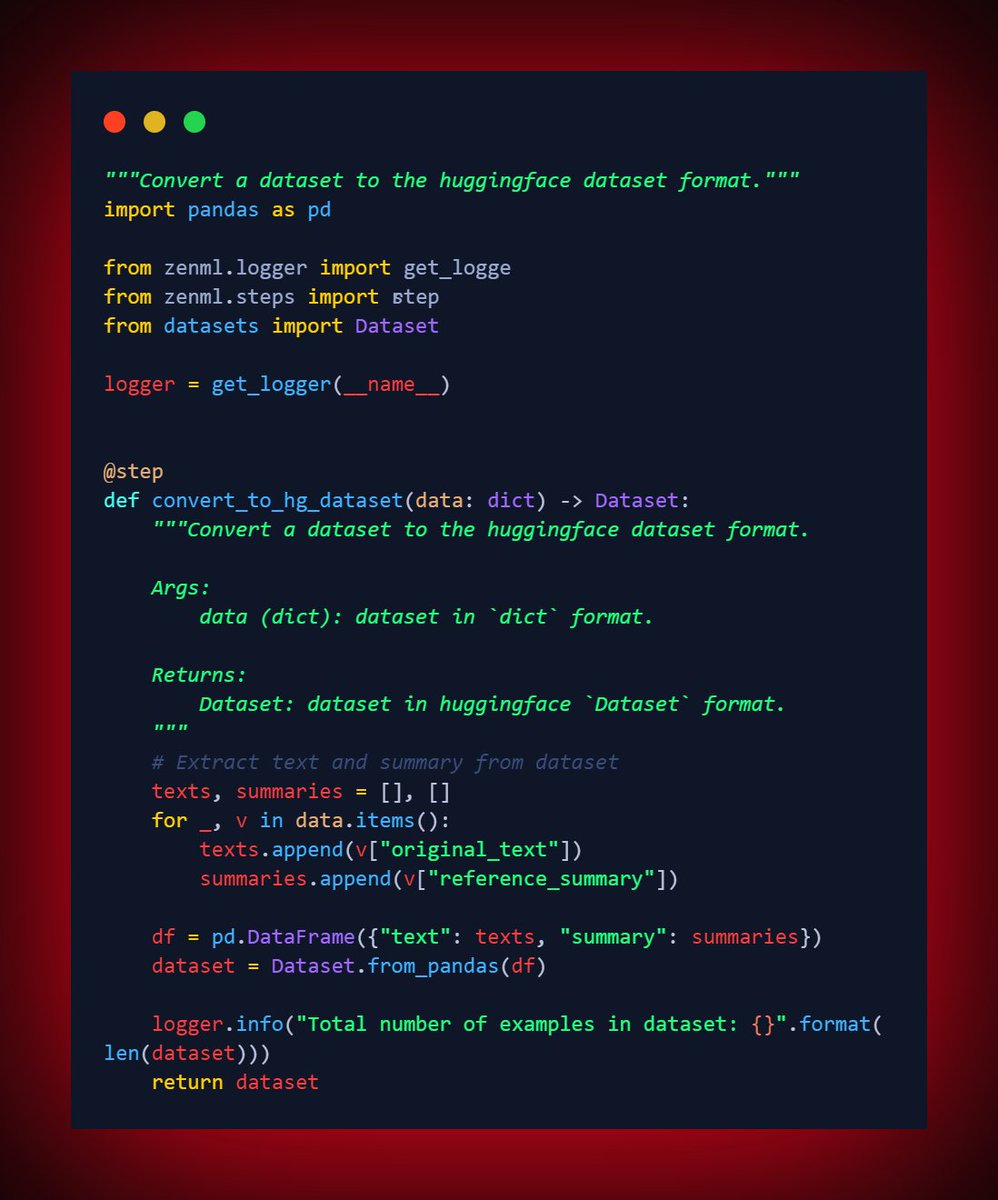
👉 Code to convert a given dataset into a HuggingFace `Dataset`.🔥🚀
HuggingFace Datasets are a collection of datasets designed for Machine Learning and Natural Language Processing. They provide a uniform and efficient way to manipulate datasets, which is crucial for Machine Learning tasks.
👉 The function `convert_to_hg_dataset` takes as input a dictionary `data`, which represents the dataset. Each key-value pair in the dictionary is assumed to represent one example (or data point) in the dataset. The value is another dictionary, with the keys `original_text` and `reference_summary` containing the respective text and summary.
👉 It loops over the dictionary to extract all the `original_text` and `reference_summary` values, then constructs a pandas DataFrame from these. This DataFrame is then converted to a HuggingFace `Dataset` using the `from_pandas` method. Finally, it logs the total number of examples in the dataset and returns the HuggingFace `Dataset`.
---
👉 Now, looking at the specific block of code:
```py
for _, v in data.items():
texts.append(v["original_text"])
summaries.append(v["reference_summary"])
```
This part of the code is responsible for iterating over the input dictionary and extracting the `original_text` and `reference_summary` fields from each item.
👉 The `for _, v in data.items():` line is a Python idiom for looping over the items in a dictionary. The `_` is a convention used when the loop variable is not needed - in this case, we are not interested in the keys of the dictionary, only the values. The `v` variable will hold the value for each item (which is itself a dictionary containing `original_text` and `reference_summary`).
👉 The `texts.append(v["original_text"])` line extracts the `original_text` field from the dictionary `v` and appends it to the `texts` list.
👉 Similarly, the `summaries.append(v["reference_summary"])` line extracts the `reference_summary` field and appends it to the `summaries` list.
👉 This block of code is critical because it transforms the data from the original dictionary format into two separate lists, `texts` and `summaries`, that can be used to construct a DataFrame. This step is essential to convert the data into a format that the HuggingFace `Dataset` can understand.
👉 Without this step, we wouldn't be able to convert the data into a pandas DataFrame, which in turn is necessary to create the HuggingFace `Dataset`. So while it may seem simple, this part of the code plays a vital role in the data transformation process.
------------
💡Does the final output from the `convert_to_hg_dataset()` method produces a Apache Arrow format data💡
👉 Yes, when using the `from_pandas` method to convert a pandas DataFrame to a HuggingFace `Dataset`, the underlying data structure of the returned `Dataset` object is indeed an Apache Arrow table.
👉 Apache Arrow is a cross-language development platform for in-memory data. It specifies a standardized, language-agnostic columnar memory format, which enables efficient data exchange and high performance due to its locality of reference.
👉 The HuggingFace `Dataset` API uses Apache Arrow as the backend for data storage and computation. The decision to use Apache Arrow has several benefits including, but not limited to, efficient memory usage, high-speed loading of large datasets, and support for a wide variety of data types.
👉 So, the `Dataset` produced by the `convert_to_hg_dataset` function can indeed be considered to be in Apache Arrow format, although from a user's perspective, they're interacting with a `Dataset` object. The Apache Arrow format is more of an implementation detail that's hidden behind the API.
---------------------
👉 If you enjoyed this post:
✅1. Give me a follow @rohanpaul_ai for more of this every day and
✅2. Like & Retweet this tweet:
✅3. Consider subscribing to my MachineLearning YouTube channel -
youtube.com/@RohanPaul-AI
#llm #Largelanguagemodels #Llama2 #MachineLearning #ArtificialIntelligence #datascience #nlp #textprocessing #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #datascience #nlp #textprocessing #tensorflow #pytorch #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #pythonprogramming #python #100DaysOfMLCode #softwareengineer #dataanalysis #datascienceinterview #python #programming #coding #programmer #developer #coder #code #computerscience #pythonprogramming #software
2
8
980
20 Sep 2023
🐍🚀 Deep Copy vs. Shallow Copy in Python: A Case of Object Versioning 🐍🚀
One less-trodden path in Python development involves maintaining versions of mutable objects. Think of it as a simplified versioning system where you can make changes to an object while preserving its previous states. Deep copying plays a pivotal role in such scenarios.
**Scenario**: You're working on a graphics software that allows designers to manipulate shapes. For every change the designer makes, the software needs to store that version of the shape so the designer can revert to any previous state.
👉 **Setting up the Shape Class**:
First, let's design a simple shape class with some attributes.
```python
class Shape:
def __init__(self, color, points):
self.color = color
self.points = points # list of x,y coordinates
```
👉 **Versioning System**:
Here, we'll maintain versions using a list. When a change is made, we'll store the current state using a deep copy.
```python
# 🐍🚀 Deep Copy vs. Shallow Copy in Python:
# A Case of Object Versioning 🐍🚀
import copy
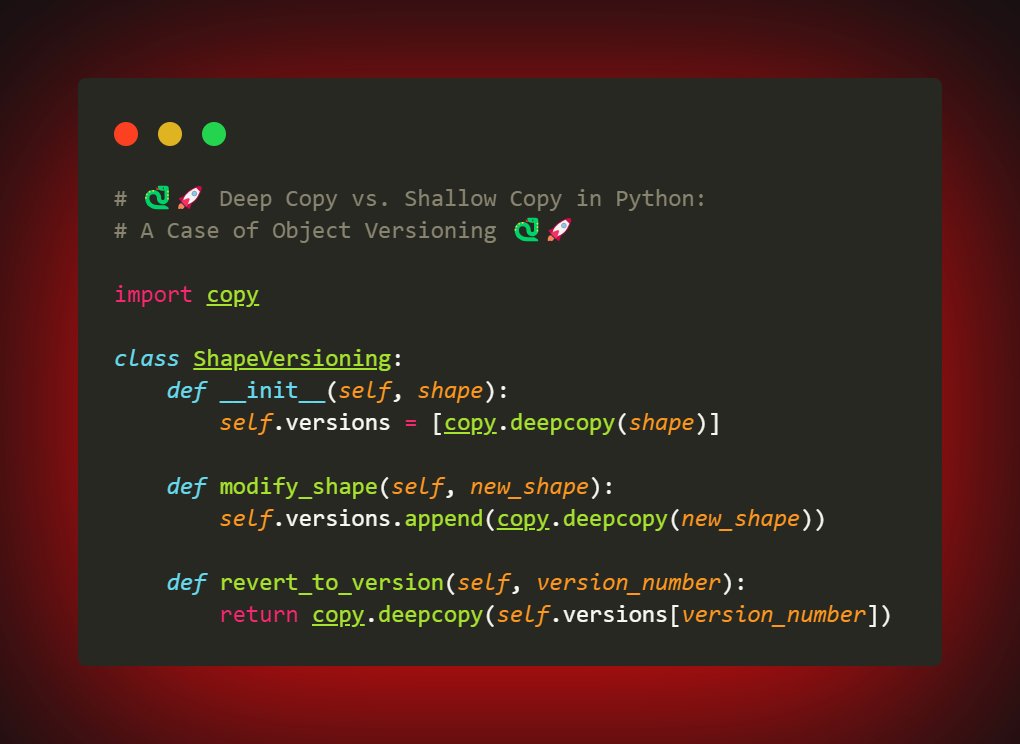
class ShapeVersioning:
def __init__(self, shape):
self.versions = [copy.deepcopy(shape)]
def modify_shape(self, new_shape):
self.versions.append(copy.deepcopy(new_shape))
def revert_to_version(self, version_number):
return copy.deepcopy(self.versions[version_number])
```
👉 **Using the System**:
Let's assume a designer creates a triangle and then decides to modify it.
```python
triangle = Shape("red", [(0, 0), (0, 1), (1, 0)])
# Initialize versioning system
version_system = ShapeVersioning(triangle)
# Designer decides to change the color
triangle.color = "blue"
version_system.modify_shape(triangle)
# Designer modifies a point
triangle.points[2] = (1, 1)
version_system.modify_shape(triangle)
# Reverting to the original triangle
original_triangle = version_system.revert_to_version(0)
print(original_triangle.color) # Outputs: red
print(original_triangle.points) # Outputs: [(0, 0), (0, 1), (1, 0)]
```
👉 **Diving Deeper**:
Here's why a deep copy is vital. When storing versions, any mutable attributes (like our `points` list) need to be entirely independent between versions. A shallow copy wouldn't suffice as modifying `points` in one version would inadvertently affect other versions, thus defeating the versioning purpose.
👉 **Takeaway**:
While versioning systems can get much more complex in real-world scenarios (like Git), this simplified approach showcases the utility of deep copying in preserving the integrity of object versions. It's a unique blend of design principles and Python's built-in capabilities to enable feature-rich applications.
👉 **Takeaway**:
Deep and shallow copies are fundamental for managing data in Python. While a shallow copy is quicker and uses less memory, it can lead to unintended data alterations due to shared references. A deep copy, although more resource-intensive, guarantees complete independence between the source and the copied data. For critical operations, understanding the distinction is vital. Always choose wisely based on the requirements of your application.
---------------------
👉 If you enjoyed this post:
✅1. Checkout my recent Python book, covering 130 Python Core concepts like this across 350 pages and detail analysis.
📌Book Link in my Twitter Bio
✅2. Give me a follow @rohanpaul_ai for more of these every day and like and Retweet this tweet
------------
#llm #Largelanguagemodels #Llama2 #MachineLearning #ArtificialIntelligence #datascience #nlp #textprocessing #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #datascience #nlp #textprocessing #tensorflow #pytorch #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #pythonprogramming #python #100DaysOfMLCode #softwareengineer #dataanalysis #datascienceinterview #python #programming #coding #programmer #developer #coder #code #computerscience #pythonprogramming #software

20 Sep 2023

🐍🚀 Deep Copy vs. Shallow Copy in Python 🚀🧠
When you’re duplicating data structures in Python, the depth of the copy matters. Let's dissect the intricacies of deep and shallow copies, and why they're crucial for advanced Python development.
👉 Understanding the core difference:
Shallow Copy: Only the outermost object is duplicated, while the inner objects are still references and not actual copies. The `copy` module's `copy()` function can achieve this.
Deep Copy: Both the outer and inner objects are duplicated, ensuring that no referenced objects from the source are left. This can be accomplished using the `copy` module's `deepcopy()` function.
👉 **Code Illustration**:
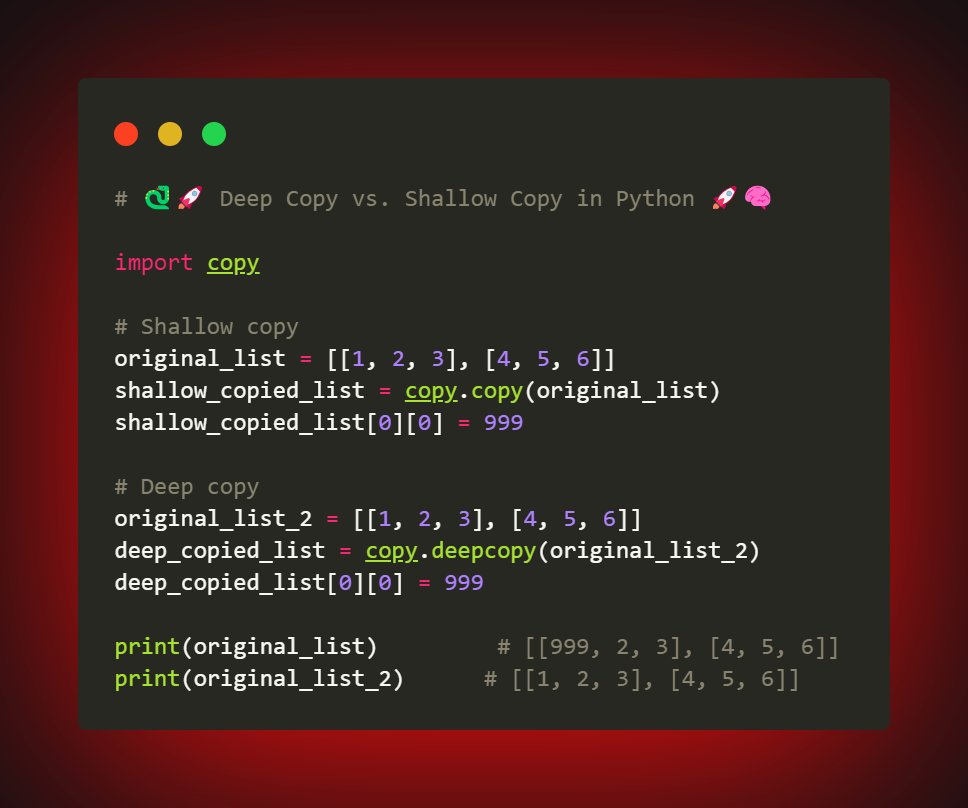
```python
# 🐍🚀 Deep Copy vs. Shallow Copy in Pythone 🚀🧠
import copy
# Shallow copy
original_list = [[1, 2, 3], [4, 5, 6]]
shallow_copied_list = copy.copy(original_list)
shallow_copied_list[0][0] = 999
# Deep copy
original_list_2 = [[1, 2, 3], [4, 5, 6]]
deep_copied_list = copy.deepcopy(original_list_2)
deep_copied_list[0][0] = 999
print(original_list) # [[999, 2, 3], [4, 5, 6]]
print(original_list_2) # [[1, 2, 3], [4, 5, 6]]
```
💡 Here, modifying the shallow-copied list changed the original list as well. But the deep-copied list remained isolated.💡
---------------
👉 Behind the curtains:
Python stores variables as references to objects. When doing a shallow copy, the outermost container gets a new reference, but the inner objects still point to the same references. In contrast, a deep copy ensures every object has a new reference, making the copied object totally independent.
-----------------------
👉 Real-life Use case code - Config File Generation:
Imagine a configuration template for a software package. You want to generate multiple configuration files from this template, with slight variations for different server environments, without altering the master template.
```python
# Original config template
config_template = {
"database": {
"user": "admin",
"password": "password123"
},
"server": {
"port": 8080
}
}
# Deep copy the template for production adjustments
production_config = copy.deepcopy(config_template)
production_config["database"]["password"] = "prod_secure_pass"
production_config["server"]["port"] = 8000
# The master template remains unchanged
print(config_template["database"]["password"]) # password123
print(config_template["server"]["port"]) # 8080
```
👉 By using a deep copy, modifications for the production environment don't affect the original template. This ensures consistent and error-free configuration generation.
---------------------
👉 If you enjoyed this post:
✅1. Checkout my recent Python book, covering 130 Python Core concepts like this across 350 pages and detail analysis.
📌Book Link in my Twitter Bio
✅2. Give me a follow @rohanpaul_ai for more of these every day and like and Retweet this tweet
------------
#llm #Largelanguagemodels #Llama2 #MachineLearning #ArtificialIntelligence #datascience #nlp #textprocessing #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #datascience #nlp #textprocessing #tensorflow #pytorch #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #pythonprogramming #python #100DaysOfMLCode #softwareengineer #dataanalysis #datascienceinterview #python #programming #coding #programmer #developer #coder #code #computerscience #pythonprogramming #software

1
3
821
20 Sep 2023
🐍🚀 Deep Copy vs. Shallow Copy in Python 🚀🧠
When you’re duplicating data structures in Python, the depth of the copy matters. Let's dissect the intricacies of deep and shallow copies, and why they're crucial for advanced Python development.
👉 Understanding the core difference:
Shallow Copy: Only the outermost object is duplicated, while the inner objects are still references and not actual copies. The `copy` module's `copy()` function can achieve this.
Deep Copy: Both the outer and inner objects are duplicated, ensuring that no referenced objects from the source are left. This can be accomplished using the `copy` module's `deepcopy()` function.
👉 **Code Illustration**:
```python
# 🐍🚀 Deep Copy vs. Shallow Copy in Pythone 🚀🧠
import copy
# Shallow copy
original_list = [[1, 2, 3], [4, 5, 6]]
shallow_copied_list = copy.copy(original_list)
shallow_copied_list[0][0] = 999
# Deep copy
original_list_2 = [[1, 2, 3], [4, 5, 6]]
deep_copied_list = copy.deepcopy(original_list_2)
deep_copied_list[0][0] = 999
print(original_list) # [[999, 2, 3], [4, 5, 6]]
print(original_list_2) # [[1, 2, 3], [4, 5, 6]]
```
💡 Here, modifying the shallow-copied list changed the original list as well. But the deep-copied list remained isolated.💡
---------------
👉 Behind the curtains:
Python stores variables as references to objects. When doing a shallow copy, the outermost container gets a new reference, but the inner objects still point to the same references. In contrast, a deep copy ensures every object has a new reference, making the copied object totally independent.
-----------------------
👉 Real-life Use case code - Config File Generation:
Imagine a configuration template for a software package. You want to generate multiple configuration files from this template, with slight variations for different server environments, without altering the master template.
```python
# Original config template
config_template = {
"database": {
"user": "admin",
"password": "password123"
},
"server": {
"port": 8080
}
}
# Deep copy the template for production adjustments
production_config = copy.deepcopy(config_template)
production_config["database"]["password"] = "prod_secure_pass"
production_config["server"]["port"] = 8000
# The master template remains unchanged
print(config_template["database"]["password"]) # password123
print(config_template["server"]["port"]) # 8080
```
👉 By using a deep copy, modifications for the production environment don't affect the original template. This ensures consistent and error-free configuration generation.
---------------------
👉 If you enjoyed this post:
✅1. Checkout my recent Python book, covering 130 Python Core concepts like this across 350 pages and detail analysis.
📌Book Link in my Twitter Bio
✅2. Give me a follow @rohanpaul_ai for more of these every day and like and Retweet this tweet
------------
#llm #Largelanguagemodels #Llama2 #MachineLearning #ArtificialIntelligence #datascience #nlp #textprocessing #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #datascience #nlp #textprocessing #tensorflow #pytorch #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #pythonprogramming #python #100DaysOfMLCode #softwareengineer #dataanalysis #datascienceinterview #python #programming #coding #programmer #developer #coder #code #computerscience #pythonprogramming #software
1
4
1,604
18 Sep 2023
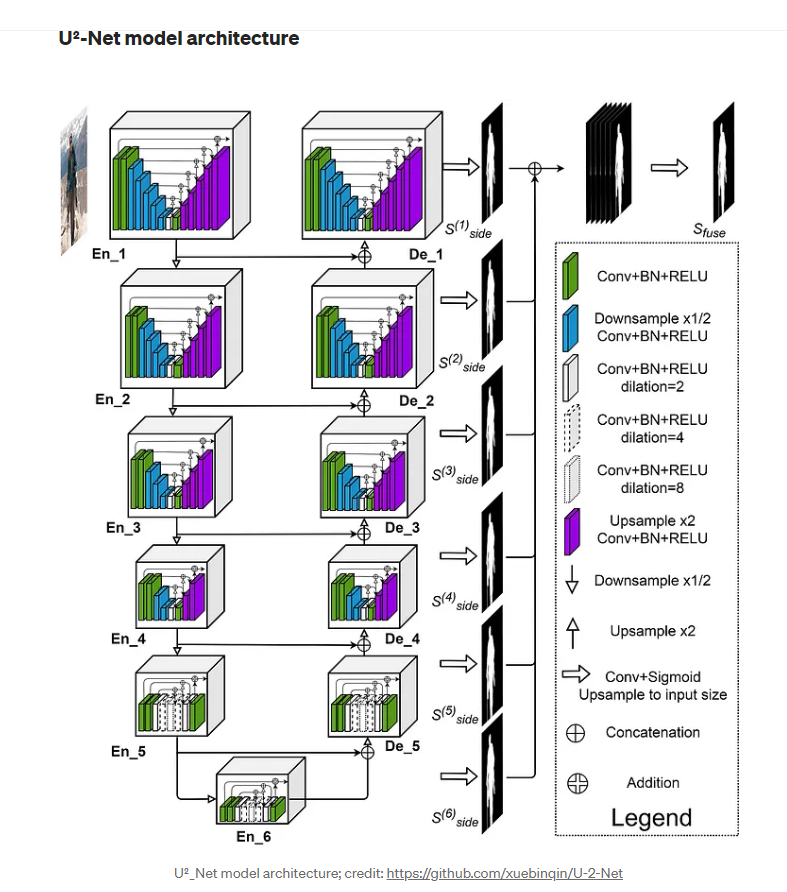
For anybody interested, the great `rembg `library, was developed by implementing the deep learning model U²-Net
The rembg Python library is behind multiple successful background removal applications
---------------------
#MachineLearning #ArtificialIntelligence #datascience #huggingface #nlp #textprocessing #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #datascience #nlp #textprocessing #tensorflow #pytorch #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #pythonprogramming #python #100DaysOfMLCode #softwareengineer #dataanalysis #datascienceinterview #python #programming #coding #programmer #developer #coder #code #computerscience #technology #pythonprogramming #software #llm #Largelanguagemodels
1
20
2,676
18 Sep 2023
Web scraping with Large Language Models (LLM)- @AnthropicAI @langchain
👉 Checkout on my #YouTube channel
🟠 youtube.com/watch?v=QAY82Uvr…
--------------
#MachineLearning #ArtificialIntelligence #datascience #nlp #textprocessing #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #datascience #nlp #textprocessing #tensorflow #pytorch #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #pythonprogramming #python #100DaysOfMLCode #softwareengineer #dataanalysis #datascienceinterview #interviewprep #interviews #python #programming #coding #programmer #developer #coder #code #computerscience #technology #pythonprogramming #software #generativeai #generativemodels

1
2
455
18 Sep 2023
🔥🚀 In spite of all the BRILLIANCE of LoRA - It isn't a direct substitute for Full Finetuning. While it cuts down on computational needs by 3 times, there are specific drawbacks.🔥🚀
The way data is prepared for both methods differs as well. 🔑
👉 LoRA demands a larger data set to stabilize compared to full FineTuning.
Establishing the rank for LoRA often involves much experimentation and adjustments.
Specifically,
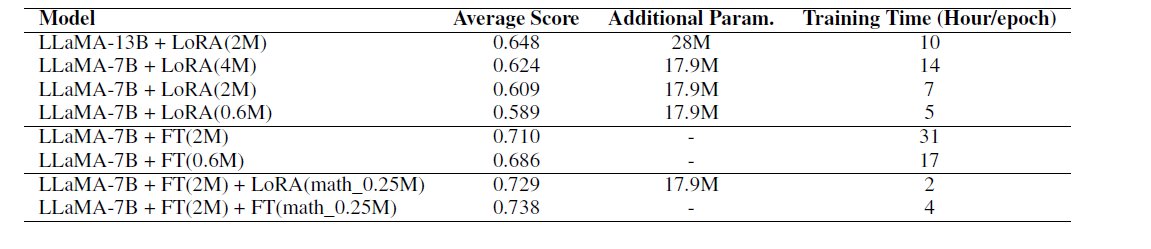
👉 LoRA-based tuning benefits from the number of model parameters. Comparing LLaMA-7B LoRA(4M) and LLaMA-13B LoRA(2M) shows that the number of model parameters
has a greater impact on the effectiveness of LoRA-based tuning than the amount of training data.
👉 The choice of the base model has a significant impact on the effectiveness of LoRA-based tuning.
Comparing LLaMA-7B LoRA(0.6M)
and LLaMA-7B FT(0.6M), as well as LLaMA-7B LoRA(2M) and LLaMA-7B FT(2M), it is evident that LoRA-based tuning on a base
model that has not undergone instruction tuning has limited effectiveness and is far less effective than full-parameter fine-tuning (averaging 10 points lower).
👉 And increasing the amount of training data can continuously improve the model’s effectiveness.
Comparing LLaMA-7B LoRA(0.6M), LLaMA-7B LoRA(2M), and LLaMA-7B LoRA(4M) shows that as the amount of training data increases, the model’s effectiveness improves (an average of approximately 2 points improvement for every doubling of data).
🔗 arxiv.org/pdf/2304.08109.pdf
🔗 arxiv.org/pdf/2304.14999.pdf
---------------------
#llm #Largelanguagemodels #Llama2 #MachineLearning #ArtificialIntelligence #datascience #nlp #textprocessing #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #datascience #nlp #textprocessing #tensorflow #pytorch #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #pythonprogramming #python #100DaysOfMLCode #softwareengineer #dataanalysis #datascienceinterview #python #programming #coding #programmer #developer #coder #code #computerscience #pythonprogramming #software
1
3
371
18 Sep 2023
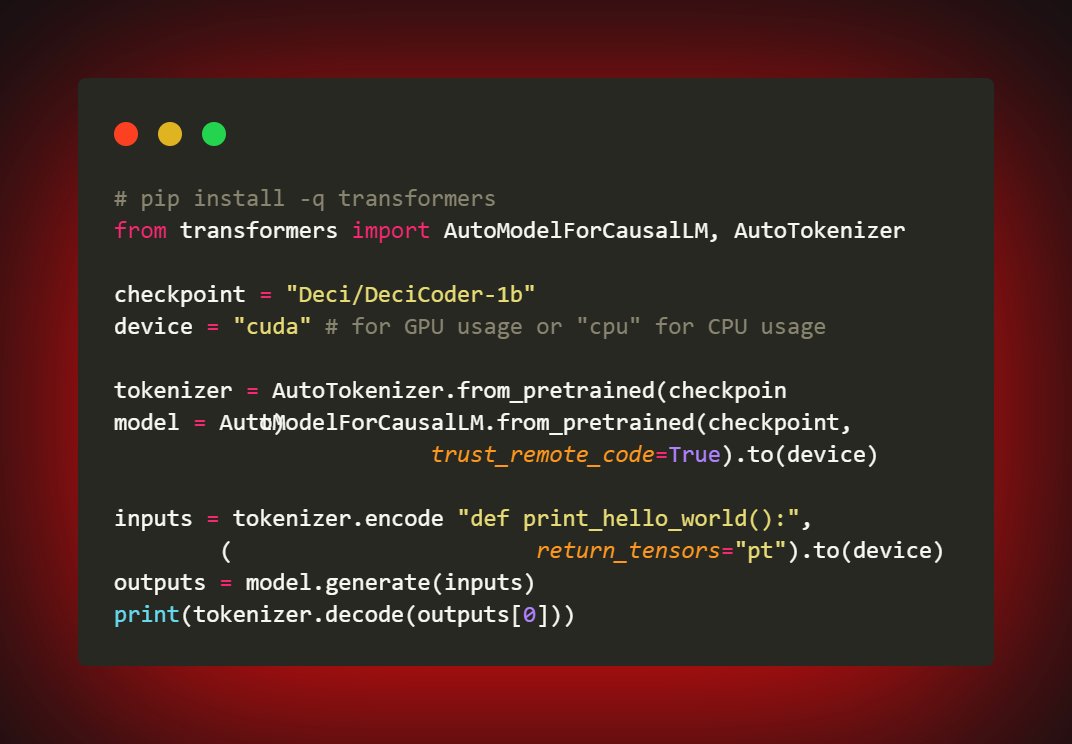
🔥🚀The New Large Language Model (with Commercial Use Apache 2.0 License) - DeciCoder, an open-source code-completion model for these three languages🔥🚀
The dataset. DeciCoder is trained on the Stack dataset, which has 6TB of code from >350 programming languages. But, the dataset is filtered to only include Python, Java, and Javascript code.
Model type: Its Auto-regressive Model based on the transformer decoder architecture, using Grouped Query Attention.
Its Grouped Query Attention with 8 key-value heads, groups the query heads and allows them to share a key head and value head. So computation becomes streamlined, and memory usage optimized. This approach provides a better tradeoff between accuracy and efficiency than does Multi-Query Attention
deci.ai/blog/decicoder-effic…
---------------------
#llm #langchain #Largelanguagemodels #Llama2 #MachineLearning #ArtificialIntelligence #datascience #nlp #textprocessing #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #datascience #nlp #textprocessing #tensorflow #pytorch #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #pythonprogramming #python #100DaysOfMLCode #softwareengineer #dataanalysis #datascienceinterview #python #programming #coding #programmer #developer #coder #code #computerscience #pythonprogramming #software
2
1
536
18 Sep 2023
🐍🔥If you are considering replacing Spark with Polars for your data-pipeline - Here's the key points🐍🔥
📌 Spark is a distributed processing framework built to run on large clusters of machines, processing Big Data.
📌 Polars is a tool that right now, is made for single node/machine processing.
📌 Spark has a lot of overhead when running on a single node; it wasn’t made to do that. Polars is going to be faster on a single machine.
📌 If you’re running Spark on a single machine/node to process data because Pandas choked on your data size, that’s like using a sledgehammer when you needed a hammer.
📌 If processing 100TB datasets on a cluster, you’re better off with Spark.
📌 If you are processing data on a single machine, use Polars, that’s what it was made for.
📌 Polars is going to Rust or Python. Spark is going to be Scala or Python.
📌 Use Polars if you want to save money and try to process data on a single node in an efficient and fast manner.
---------------------
#MachineLearning #ArtificialIntelligence #datascience #huggingface #nlp #textprocessing #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #datascience #nlp #textprocessing #tensorflow #pytorch #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #pythonprogramming #python #100DaysOfMLCode #softwareengineer #dataanalysis #datascienceinterview #python #programming #coding #programmer #developer #coder #code #computerscience #technology #pythonprogramming #software #llm #Largelanguagemodels

16 Sep 2023
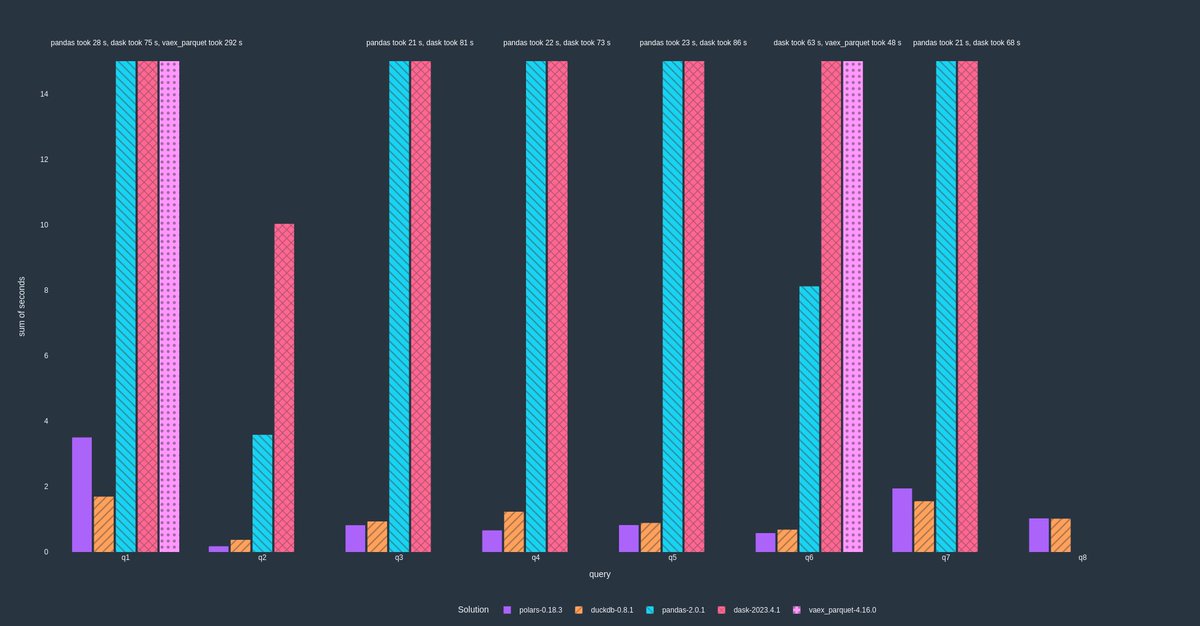
🔥📈 If you are You Still Using Pandas to Process big csv files - check out Polar 🛠️🔥
While processing large amounts of data with Pandas, it can hugely slow you down or even crash your environment due to "out of memory" reason.
💡 What does polars offer beyond pandas?💡💡
🚀 Polars utilizes all available cores on your machine whereas pandas uses a single CPU core to execute the operations.
🚀 Because, Polars is written with Rust, which is great at implementing concurrency, Polars is way faster than other libraries (e.g. Pandas) that try to implement concurrency using python.
Note, Python is bad at implementing concurrency because of its global interpreter lock (GIL), which does not exist in Rust. GIL is a lock which prevents multiple native threads from executing Python bytecodes at once..
🚀 Polars is relatively lightweight than pandas and has no dependencies, which makes it quite faster to import polars. It takes 70 ms to import polars whereas it takes 520 ms for pandas.
🚀 Polars does query optimization to reduce unnecessary memory allocations. It is also able to process queries partially or entirely in a streaming fashion. As a result, polars can handle datasets that are larger than the available RAM in your machine.
**Also the difference between Eager vs Lazy Execution**
Pandas is a eager API: you tell it execute something, and it immediately executes. So if you tell it to load a file, it will load all of it into memory; it has no way of knowing you intend to drop half the data on the next line of code.
The alternative is a lazy API that allows you to string together a series of operations — loading, filtering, aggregating, transforming—without actually doing any work. After creating this series of operations, you can then separately tell the library to execute the whole thing.
A smart lazy library can then come up with an optimized execution plan that takes into account everything you plan to do—and everything you plan not to do. For example:
If you’re not touching a column at all, there is no need to load it into memory.
Polars supports both eager and lazy APIs.
Example code of Lazy Evaluation
------------------
```py
import polars as pl
# Example of Explicit Lazy Evaluation
import polars as pl
df = pl.read_csv('data.csv')
.lazy()
.filter(
(pl.col('AGE') == 28) &
(pl.col('COUNTRY') == 'INDIA')).collect()
```
------------------
If you don’t run the .collect() method in above code, the operation is not executed right away. Instead, you will see the execution graph.
-------------------------
#MachineLearning #ArtificialIntelligence #datascience #nlp #textprocessing #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #datascience #nlp #textprocessing #tensorflow #pytorch #deeplearning #deeplearningai #100daysofmlcode #neuralnetworks #pythonprogramming #python #100DaysOfMLCode #softwareengineer #dataanalysis
4
8
1,478