
Jun 13
🔄 Automated Evaluation & Data Curation Pipelines — the scalability engine that turns manual data drudgery into automated, high-quality flywheels for continuous LLM and agentic system improvement.
Just read this excellent capstone technical white paper from @aasaitech on LLM-as-a-Judge, smart curation, active learning, synthetic data, versioning, and closed-loop refinement.
Key highlights: • 8-step pipeline: Ingestion → Preprocessing → Automated Scoring → Filtering → Enrichment → Curation → Versioning → Improvement • Critical dimensions: Correctness, Relevance, Groundedness, Safety, Completeness, Coherence • Manufacturing use case: Operator interactions, maintenance logs, equipment data → smarter recommendations & lower downtime • Design principles: Quality-first, automation with HITL, transparency, modularity, privacy
This is the practical data layer that powers everything in the series — RAG, agents, domain adaptation, observability, and progressive autonomy — creating compounding advantages in industrial and edge orchestration.
Full white paper infographic: x.com/aasaitech/status/20656…
How are you scaling data evaluation and curation in your systems — LLM-as-Judge pipelines, DeepEval/RAGAS LangSmith, or full custom flywheels with active learning?
#AutomatedEvaluation #DataCuration #LLMDataPipeline #IndustrialAI #AgenticAI #DataFlywheel #ManufacturingAI #EdgeAI

8

Jun 3
AI systems rely on high-quality, well-structured data.
The IndiaAI Data Curator Course introduces learners to the foundations of data curation, preprocessing, governance, visualization, and AI-ready data management through hands-on practical learning.
The course also covers real-world workflows in data collection, cleaning, storage, integration, and responsible AI data practices.
120-hour practical training
Industry-focused learning experience
#IndiaAI #DataCuration #FutureSkills #AIForIndia
@AshwiniVaishnaw @jitinprasada @PIB_India @SecretaryMEITY @kavitabha @GoI_MeitY @_DigitalIndia @mygovindia

1
7
365
May 27
AI systems rely on high-quality, well-structured data.
The IndiaAI Data Curator Course introduces learners to the foundations of data curation, preprocessing, governance, visualization, and AI-ready data management through hands-on practical learning.
The course also covers real-world workflows in data collection, cleaning, storage, integration, and responsible AI data practices.
Industry-focused learning experience
#IndiaAI #DataCuration #FutureSkills #AIForIndia
@AshwiniVaishnaw @jitinprasada @PIB_India @SecretaryMEITY @kavitabha @GoI_MeitY @_DigitalIndia @mygovindia

4
17
841

Apr 9
We’re excited to announce our partnership with Thomson Reuters, a collaboration focused on unlocking the full potential of proprietary data to build the next generation of domain-specific AI.
By applying DatologyAI’s data curation pipeline for legal domain adaptation mid-training, the results were clear:
- 5% improvement on legal benchmarks and 2.5% on general-purpose evaluations after mid-training
- >2.5x amplification in post-training gains on Thomson Reuters’ private legal evals
- Achieved with <1% of the original pre-training token budget
These gains demonstrate that better data doesn’t just improve models, but multiplies the effectiveness of everything built on top of them.
As @schwarzjn_ , Head of AI Research at Thomson Reuters, put it:
“DatologyAI delivered clear, measurable improvements across both public and our proprietary legal evaluations…demonstrating the strength and generalizability of their approach.”
This partnership shows what’s possible when proprietary data and advanced data curation come together — not just incremental gains, but compounding advantages across the entire model lifecycle.
We’re excited to continue building with Thomson Reuters to push the boundaries of domain AI.
#AI #MachineLearning #LegalTech #DataCuration #Partnerships

1
5
35
10,335

Feb 28
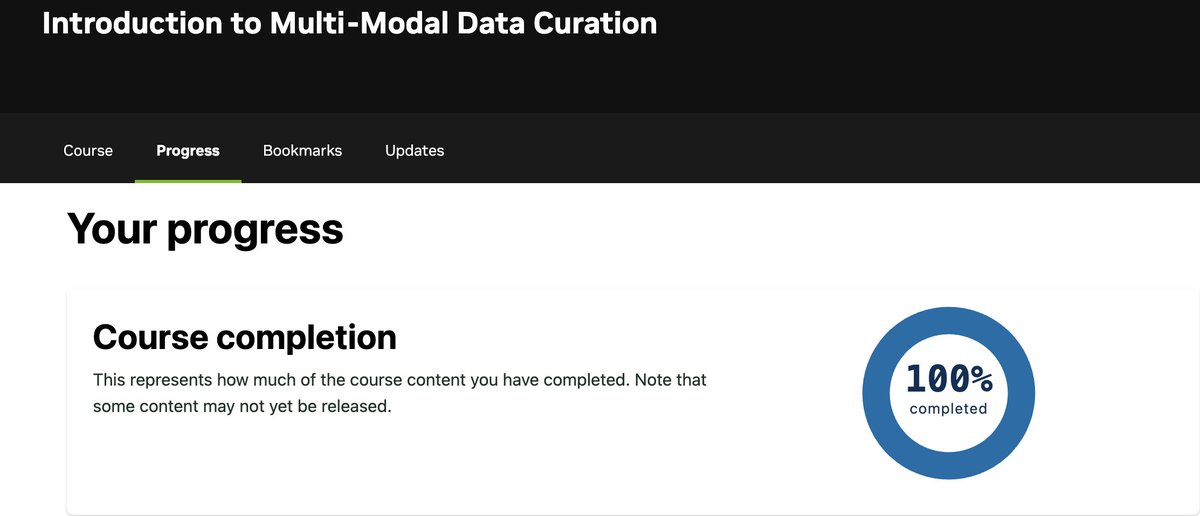
I am pleased to have completed the "Introduction to Multi-Modal Data Curation" course with 100%. It strengthens my ML and AI skills through diverse data handling and enhances my cloud capabilities for scalable pipelines. #AI #MachineLearning #CloudComputing #DataCuration
1
4
37

After a fantastic week in Orlando @GCSAAConference, LU Golf & Fields is looking forward to having a booth at the @GolfSupers conference in Calgary on Feb 25th.
@LandscapesUnLLC
#golfconstruction
#golfirrigation
#golfrenovation
#datacuration




1
16
747

19 Dec 2025
🟢 The Green & Digital session held in Oct by @ItTransilvania tackled the challenge of sustainable cities and how we can turn them into smarter communities.
👉 More: dataspace2.eu/post/green-dig…
#Datasharing #sustainability #Innovation #Datacuration #DataSpaces #HorizonEurope
2
4
44
17 Dec 2025
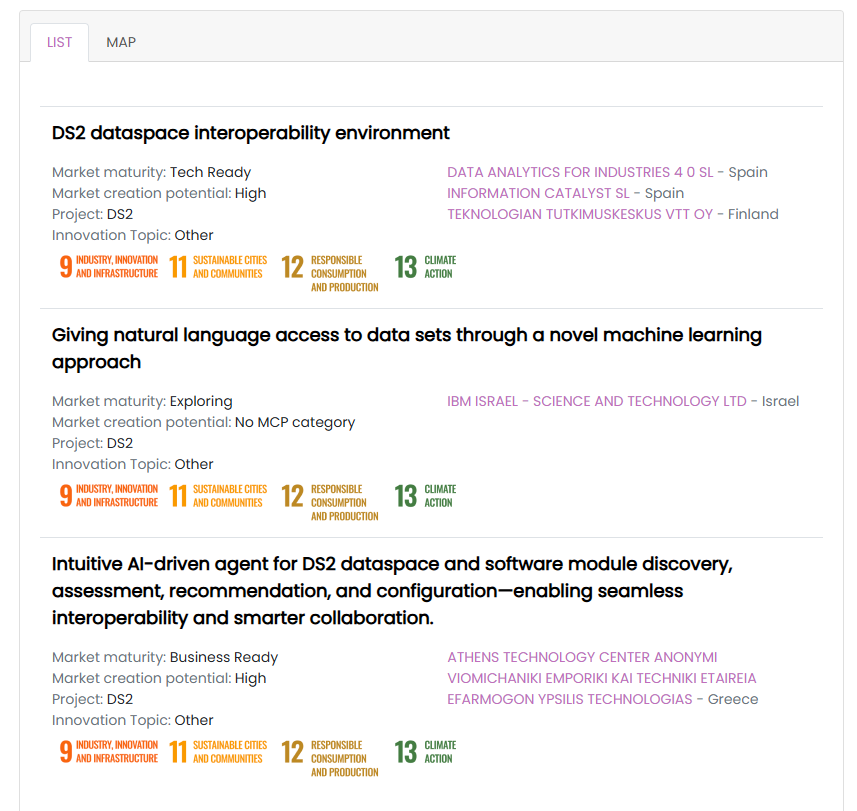
🔝 #DS2 Project has been officially featured on the European Commission’s Innovation Radar — recognized for our cutting‑edge innovations.
More ⏩ dataspace2.eu/post/ds2-proje…
#Datasharing #BigData #AI #sustainability #EUOpenData #Innovation #Datacuration #DataSpaces #HorizonEurope
1
5
83

26 Nov 2025
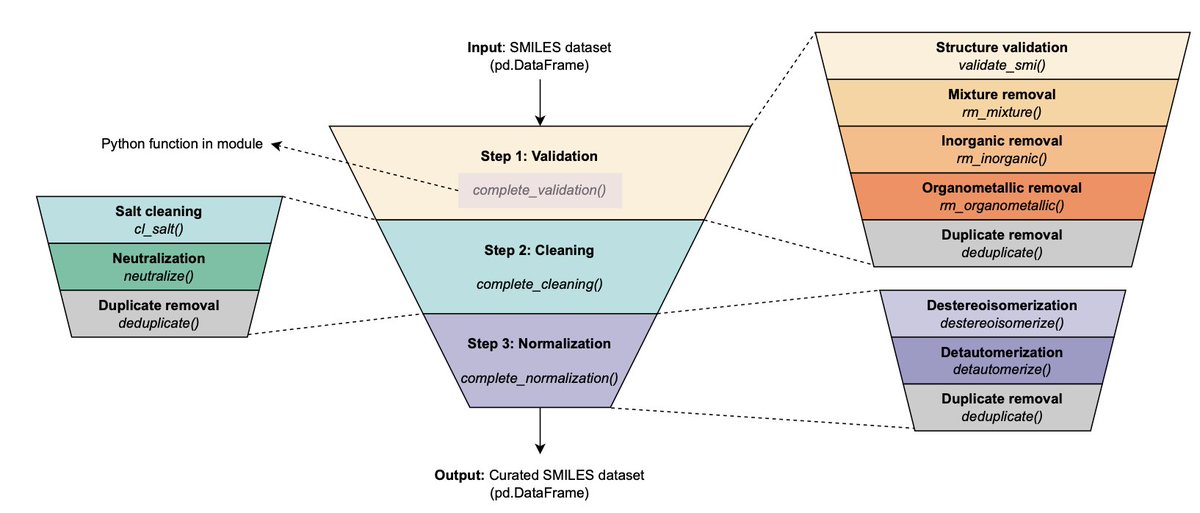
MEHC-Curation: A Python Framework for High-Quality Molecular Dataset Curation
1. Researchers have developed MEHC-curation, a user-friendly Python framework that simplifies the curation of molecular datasets, crucial for improving the performance and reliability of QSAR modeling and drug discovery.
2. The tool employs a three-stage pipeline—validation, cleaning, and normalization—with integrated duplicate removal and error tracking. This streamlined process transforms complex curation tasks into straightforward operations accessible to all researchers.
3. MEHC-curation significantly enhances dataset quality by removing invalid structures, duplicates, and inconsistencies. Extensive testing on 15 benchmark datasets demonstrated that curated datasets lead to better model performance across various machine learning algorithms.
4. The framework leverages parallel processing to achieve high computational efficiency, making it suitable for both small and large datasets. Its modular design allows for customization, adapting to specific requirements in different applications.
5. A comprehensive logging system ensures traceability by generating detailed log files that document dataset changes and identify errors. This feature is invaluable for maintaining data integrity and reproducibility.
6. MEHC-curation is designed for ease of use, requiring only a .csv file containing SMILES strings as input. It integrates seamlessly into existing workflows, making high-quality molecular dataset curation accessible without specialized expertise.
📜Paper: doi.org/10.26434/chemrxiv-20…
#Cheminformatics #QSAR #DataCuration #DrugDiscovery #Python #MachineLearning
2
17
1,205
20 Nov 2025
🌟 The Municipality of Murska Sobota is taking a step toward cleaner air and smarter urban planning with the help of the #DS2 project.
Read more in the blog post below⤵️ ⤵️ ⤵️
🔗 dataspace2.eu/post/advancing…
#EUOpenData #Datacuration #DataSpaces #Innovation #MurskaSobota
1
4
32

17 Nov 2025
👥 Work With @Debargha_ @sumitkk01010 @Ishwar__B Weicong, Shashank, Srinivasan, @shivkuma_k @vchaudhary
Paper: arxiv.org/abs/2509.22631
#AI #ComputerVision #DataCuration #MultimodalAI #LLMAgents #AgenticAI #IEEEBigData #OpenScience #ProfGiri
1
2
165
6 Nov 2025
💻 Today, we explored the backbone of our project, the use cases.
We aligned each module with its corresponding use case. @ItTransilvania leads the use cases.
⏯️More info on our use cases dataspace2.eu/
#EUOpenData #Datacuration #DataSpaces #Innovation

5
36

23 Oct 2025
13/13
🕸️Sentient’s Data Curation shows how a decentralized, community-driven approach improves data quality for AI training, boosting model performance and creating a fair, transparent ecosystem where everyone contributes!
#Sentient #DataCuration #AI
8
62

🌍🌱 Exciting news! A new dataset on soil moisture from the Al-Khanasri restoration site is now available on Dataverse.
Check it out here:📎bit.ly/48anz31
#DataManagement #DataCuration #SoilMoisture #SoilData #LandRestoration 🇯🇴 📊✨
@ICARDA
1
3
412

23 Sep 2025
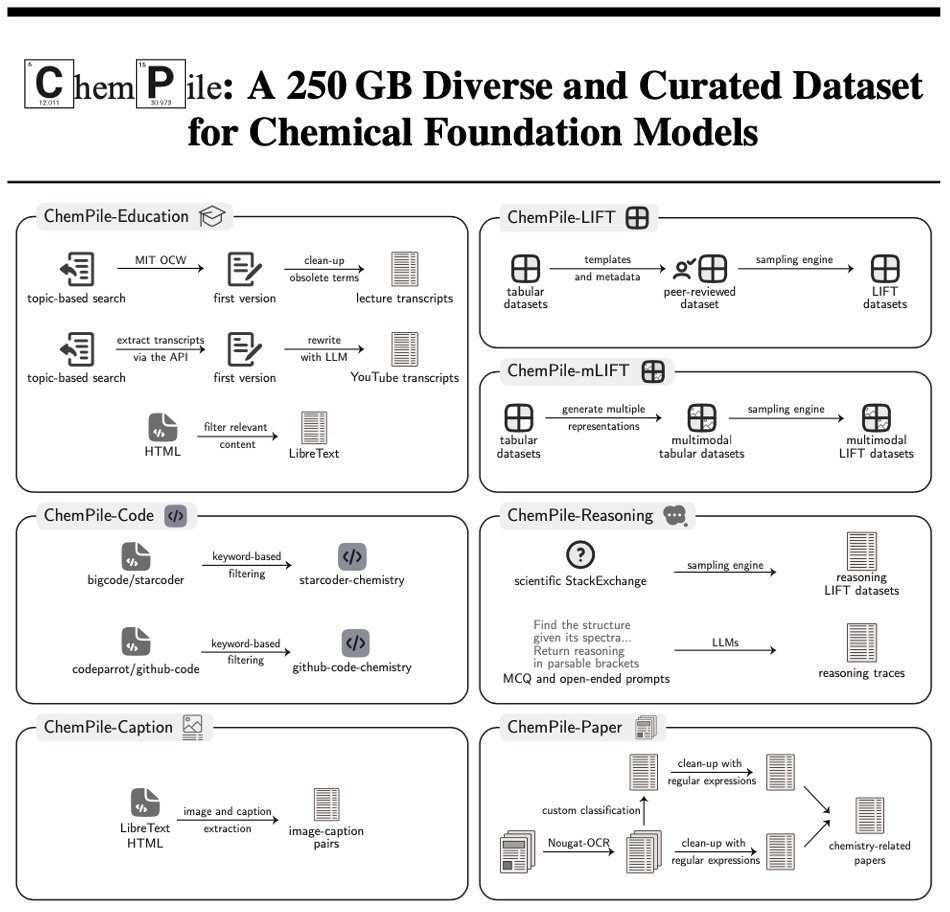
Thrilled to share that our paper “ChemPile: A 250GB Diverse and Curated Dataset for Chemical Foundation Models” has been accepted to NeurIPS 2025! 🎉
Massive kudos to first author Adrian Mirza (@adrian_mirza_) and project leads Kevin Maik Jablonka (@kmjablonka @jablonkagroup), Michael Pieler (@MichaelMPieler) and the rest of the team. I’m proud to have contributed as a co-author (contributor) alongside an amazing group of researchers.
What’s ChemPile?
A rigorously curated, ~75B-token, multimodal chemistry corpus spanning Education, Papers, (m)LIFT instruction data, Code, Reasoning, and Captions, with standardized splits and multiple chemical representations (SMILES, SELFIES, InChI, IUPAC). Hosted on Hugging Face with consistent formatting and documentation for immediate FM pretraining or fine-tuning.
Why it matters?
ChemPile is, to our knowledge, the largest open chemical dataset designed for training foundation models—built for diversity, scale, and usability to accelerate AI-for-science.
📄 Paper (arXiv): arxiv.org/abs/2505.12534
🌐 Site & docs: chempile.lamalab.org
🤗 Hugging Face collection: huggingface.co/collections/j…
#NeurIPS2025 #AI4Science #Chemistry #Cheminformatics #MaterialsScience #FoundationModels #LLMs #Multimodal #OpenScience #HuggingFace #DataCuration #MachineLearning #AIResearch
1
11
514

1 Sep 2025
🔎 Desde la Unidad de Gestión de Acceso Abierto @AA_UNR elaboramos esta "Lista de revisión para la curaduría de datos", una guía práctica para asegurar la calidad de los datasets y potenciar su reutilización.
👉 dataverse-info.unr.edu.ar/bu…
#AccesoAbiertoUNR #DataCuration

3
11
176

Presentations include:
➡️ "Scaling Synthetic Data for Industrial AI: From CAD to Model in Hours" by @lasermatts from @BucketRobotics
➡️ "Detecting the Unexpected: Practical Approaches to Anomaly Detection in Visual Data" by Paula Ramos from Voxel51
➡️ "Swarm Intelligence: Solving Complex Industrial Optimization in Seconds" by @DirectNirvana from Collide Technology
Save your spot here: link.voxel51.com/manufacturi…
#Manufacturing #Robotics #DataCuration #ComputerVision #FiftyOne

1
2
200

📢 For the first time ever, the International Biocuration Conference is coming to Africa!
Join us in Cape Town, South Africa from April 20–24, 2026 for #Biocuration2026 🌍
✨ Submit your abstract & be part of this historic event!
#ABI #DataCuration #LifeScience

📢 Call for Workshops – #Biocuration2026
📍 Cape Town | 🗓️ April 20–24, 2026
Share your skills in biocuration, bioinformatics & data science with a global community!
🧠 Skill-building & collaboration welcome!
🔗 Info: bioinformaticsinstitute.afri…
📩 Submit: bioinformaticsinstitute.afri…

2
7
318

8 Aug 2025
[Nota metodológica] Algunos pensaréis: “Quizás es que hay contenedores de distinto tamaño”. Y sí, los hay: desde 120L hasta 5kL. Para evitar distorsiones, normalizamos los datos a un contenedor equivalente de 1,1kL (uno de 2,2kL cuenta como 2 y uno de 600L como 0,5) #DataCuration


1
1
6
246
29 Jul 2025
📰 "Navigating Challenges and Strategies for Data Sharing and Integration in the Data Space Era" is the latest joint publication of the Data Space Cluster ⬇️⬇️⬇️
💻 Read more: dataspace2.eu/post/fresh-ins…
#EUOpenData #Innovation #Datacuration #DataSpaces #HorizonEurope #DSSC
1
4
35