
You are looking at an microservices datbase relationship overview.
Im rebuilding the monolithic architecture of client into scalable system.
1
1
4



May 29
Graph Engines: Introducing Neo4j Virtual Graph - Graph reasoning on the data you already have
Unlocking the power of graph intelligence on all your enterprise data - no ETL needed.
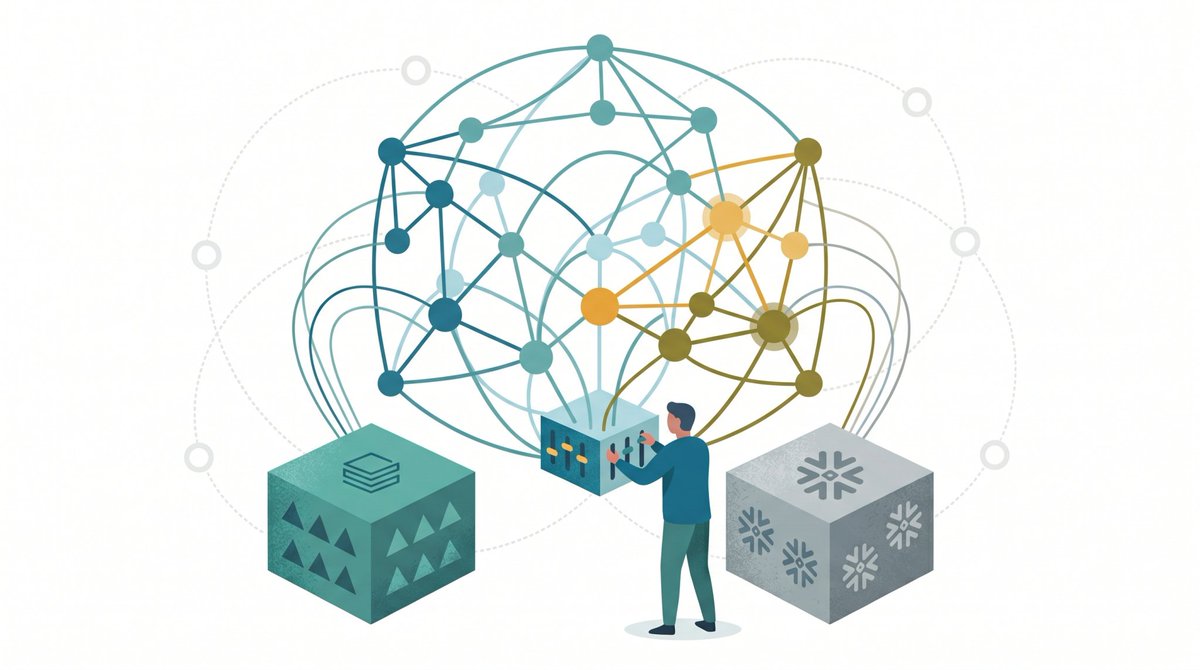
Most graph conversations start with "move your data into a graph database." But what if you can't, or won't?
This is what Graph Engines address: they project a graph model onto warehouses, streams, application platforms and relational databases, and let you traverse and compute there, data in place.
This isn't a crowded space. It's an emerging precision category with a handful of serious offerings doing something genuinely hard. And that's exactly why it needs a map.
The notion of "query your graph-shaped data where it lives" is getting lots of attention lately, and for good reason.
The State of the Graph mapped Graph Engines. Now @neo4j is releasing a product in this category too.
Over the past few quarters, we’ve seen tremendous growth in enterprise adoption of agentic workflows. Large enterprises are realizing that GraphRAG delivers more accurate results than traditional RAG, multi-hop reasoning is essential for many high-value use cases, and memory and context graphs are critical for accurate decision-making.
However, enterprises want a zero-copy architecture; they do not want to move or duplicate data from their data warehouses, lakehouses, and operational databases into a Graph Datbase just to unlock the benefits of graph intelligence.
Neo4j is announcing Virtual Graph, available now in private preview.
Virtual Graph lets you run Cypher queries and graph algorithms directly against the data you already have in Snowflake, Databricks, and other databases and lakehouses.
The zero-copy architecture means your data stays where it is, governed by your existing controls, while you still get the power of Neo4j’s AI-powered Graph Tools. No new system of record to manage.
Virtual Graph surfaces the relationships your tables have always implied but never exposed, ready for graph queries, graph algorithms, and the AI agents that need to reason over them.
The promise: pointing a graph database at your existing warehouse and getting started in minutes, with no data movement, no schema rewrites, and no new pipelines to maintain.
To learn more about Graph Engines and Neo4j Virtual Graph:
Navigate the Graph Engines category: linkedin.com/feed/update/urn…
Introducing Neo4j Virtual Graph: Graph reasoning on the data you already have neo4j.com/blog/graph-databas…
This is an emerging category, and more offerings will be generally available and production ready soon.
If you are exploring graph workloads but can't justify a new database yet, or simply prefer to keep your data where it lives, this map is meant to help you see where Graph Engines fit in your stack.
#GraphEngines #ProductRelease #EmergingTech
--
The Year of the Graph's Summer 2026 newsletter issue on all things #KnowledgeGraph, #GraphDB, Graph #Analytics / #DataScience / #AI and #SemTech is coming soon.
Subscribe and follow to be in the know. Reach out if you'd like to be featured 👇
yearofthegraph.xyz/newslette…
1
2
12
555

May 18
akinator was a datbase and very limited. What we can do is make AI ask more questions, but the reason we don't do that is because it annoys users. Would you like the option to have more questions if it may result in better AI experience?
1
3
5,699

Apr 12
I think Codex 5.4 is so smart that it thinks simple UI tasks are just a pointless endeavor. I can't prove it but i feel like it scoffs at me when i ask it to make a minor layout change.
Yesterday I built a swift iOS app, that is basically a replit clone with sandboxes, datbase, and i can edit and preview my app... One shot 40 minutes of work on codex x high.
Unbelievable...
The prompt alone took me an hour.
Then I SPENT 3 HOURS trying to make a minor change the ui and i had to switch to claude code.
I swear the model was punishing me for giving it boring work.
74
17
652
58,555


context SQLLite is is a datbase designed to have its install and operation done entirely from app code: import sqllite3; connection=sqllite3.connect("somefile"). The somefile will be created if it does not exist, and the app can start issuing sql statements right away.
3
696
Context: MySql is relational datbase system first released on May 23, 1995. The Soviet Union (logo bottom meme) collapsed on Decmber 26, 1991, so the purported "OurSQL" is an impossibility, unless the soviet clone was based on Ingres Db which was released in 1974.
2
167

Feb 9
it's not about age verification it's about building a datbase of the population on a world wide scale.
Like Zoom did during the pandemic.
1
31
6,551

Jan 26
Chicago, are you listening??? @ElectioNark
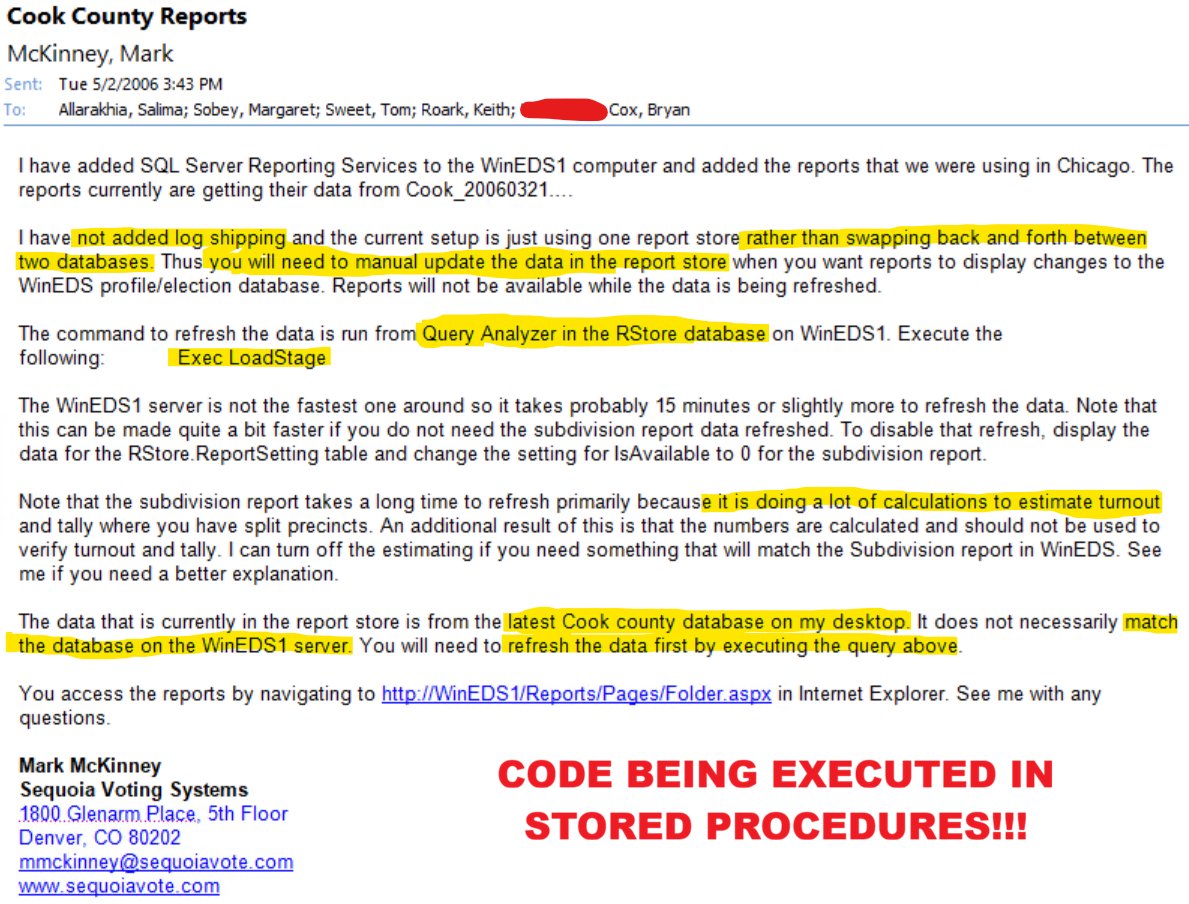
Everyone, READ carefully... SWAPPING BACK AND FORTH BETWEEN TWO DATABASES (think Mesa County Report 3)
EXEC LOADSTAGE (Stored Procedures - I did a big video of this a couple weeks ago! And Dominion is NOT the only vendor that has STORED PROCEDURES!!!)
CALCULATIONS TO ESTIMATE TURNOUT - If you haven't seen my presentation to understand how election modeling can make it easy to manipulate results, YOU NEED TO WATCH IT!
LATEST COOK COUNTY DATBASE ON MY DESKTOP - That's right, election databases are just floating out there everywhere - security is certainly NO CONCERN at Sequoia, lol! But the peasants want to look at their own data? OFF TO PRISON FOR THEM!
And yes, Dominion has the SAME TYPE OF REPORT SERVER and a WEBSITE SERVER running HIDDEN in the background that they don't tell anyone about.
Here's a great presentation showing you the insides: x.com/PatriotMarkCook/status…
28 Dec 2025

Get ready for some 🔥🔥🔥.
Dominion is going to need some 🧯🚒🚑 after this one.
Every election integrity group, cyber expert, law enforcement (the real kind), legislator, Secretary of State, Board of Elections, Election Official, honest podcasters, and ELIGIBLE VOTING CITIZEN are going to want to see this. Very nice never-seen-before nuggets mixed in! Tag everyone below and share like mad!
Feel free to clip all you like, and I'm happy to provide further detail and serve as an expert witness in anything you'd like in the prosecution of the entire corrupt election manipulation empire participating in SYSTEM ELECTION FRAUD.
So to Sequoia/Dominion/Liberty Vote, whatever you want to IDENTIFY AS...game over. We are done with your Trans-Liberty Agenda that you've been pushing on us. We're taking back the real thing.
So buckle up ASSHOLES, because you're gonna have a lot of questions to answer after people see what's exposed in this video....and yes, I've got much, much, more where this came from.
THANK YOU FOR YOUR ATTENTION TO THIS MATTER!
And FREE @realtinapeters NOW!!!
@realDonaldTrump @POTUS @HarmeetKDhillon @AAGDhillon @DNIGabbard @AGPamBondi @FBIDirectorKash @Joeoltmann @AsheinAmerica @ashincolorado @canncon @xAlphaWarriorx @realMikeLindell @GenFlynn @MikeBenzCyber @mrddmia @KurtOlsen_USA @ParikhClay @DrFrankModels @laralogan @WethePeopleAZA1 @GailGolec @AzPinkLady @AZDesert_Rose @pjcolbeck @PatrickByrne @mad_liberals @KevinMoncla @VoterGa @hoopes_leah @elonmusk @GOPoversight @PeterBernegger @TrueTheVote @DataRepublican @COrepKdeGraaf @BehizyTweets @Lorionafarm @idontexistTore @PaperBallotsGA @Auditthevotepa @mifairelections @hollykesler @KariLake @AbrahamHamadeh @ShawnSmith1776 @jeffhunt @JeffClarkUS
12
182
271
3,179

Jan 24
I managed to get my little Hytale Tavern lobby put together with persistent loadouts, and a stash system that is stored and persisted in a Mongo Datbase.
1
2
181

Jan 21
I'll post without anonymity when all CEOs and politicians have their addresses listed in a datbase accessible to the public and can't have private security.
These elites have all the power in the world and want to take what little scraps we have left.

1
8
241

29 Dec 2025
grace assistant: Hello series of entries in a relational datbase. Would you like to enter a trade agreement with the great nation of Phand?
2
9
113

SYSTEM DESIGN PHASE 1 - DAY 1
Databases:
Today we are learning about SQL databases and some methods we can use to make our sql datbase more reliable and prone to crashes.
Before Diving into All those methods first we need to understand the RDBMS.
It stands for Relational Database Management System and so why it is called Relational Even ? we know basically what is DBMS but why there is Relational?
So Relational defines that one table has a relation with another table for example :
Student Table has course id - > courses table , the course id is referenced to courses table which defines which course is the student is enrolled in this creates a relation between both of the tables.
As you can see course id has reference to courses table which makes it relational to another table .Thats why we call it Relational Database Management System.
So now we know What it is lets move ahead towards ACID properties.
ACID means Atomicity, Consistency, Integrity and Durability.
Lets Define these in a single statement.
Atomicity - Each transaction is all or nothing
Consistency - Any transaction will bring the database from one valid state to another
Isolation - Executing transactions concurrently has the same results as if the transactions were executed serially
Durability - Once a transaction has been committed, it will remain so.
There are many techniques to scale a relational database: master-slave replication, master-master replication, federation, sharding, denormalization, and SQL tuning.
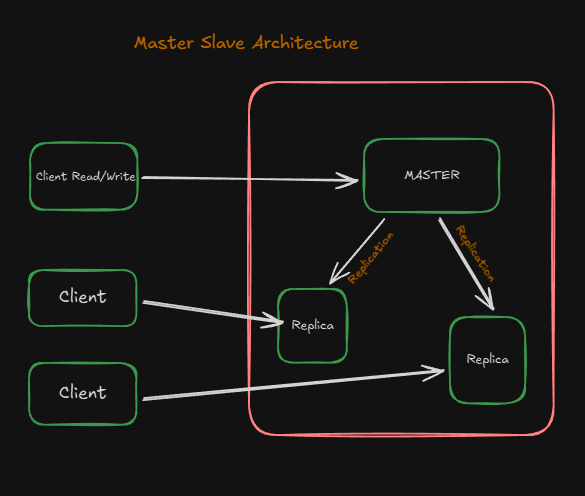
Master Slave Replication - so as we know a single database which resolves read and write operation cannot handle a million requests right? so we create master slave replication technique.
In this technique we create replicas of the primary database which sync with the primary database as writes operations are done on them.
As you can see on the diagram this will give you a better clearity of what i meant above. Read operations are directly hopped into replicas which only supports read operations and write operations are forwared into primary which is the MASTER in this case.
Problem ? having more replicas means they all have to sync up with the master database if any write operation happnes which increases latency and perfomance issues. and also requires complex code logic to divide the operations.
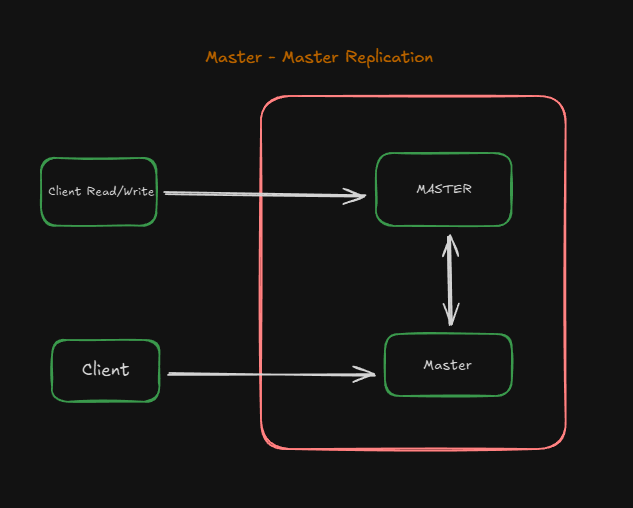
Master-Master-Replication- So instead of creating more replicas why dont we create two master dbs which stays in sync with each other and if one fails there is another master db which stays up as a backup.
Problems?
-You'll need a load balancer or you'll need to make changes to your application logic to determine where to write.
-Most master-master systems are either loosely consistent (violating ACID) or have increased write latency due to synchronization.
-Conflict resolution comes more into play as more write nodes are added and as latency increases
Disadvantages of whole replication system-
-There is a potential for loss of data if the master fails before any newly written data can be replicated to other nodes.
-Writes are replayed to the read replicas. If there are a lot of writes, the read replicas can get bogged down with replaying writes and can't do as many reads.
-The more read slaves, the more you have to replicate, which leads to greater replication lag.
-On some systems, writing to the master can spawn multiple threads to write in parallel, whereas read replicas only support writing sequentially with a single thread.
-Replication adds more hardware and additional complexity.
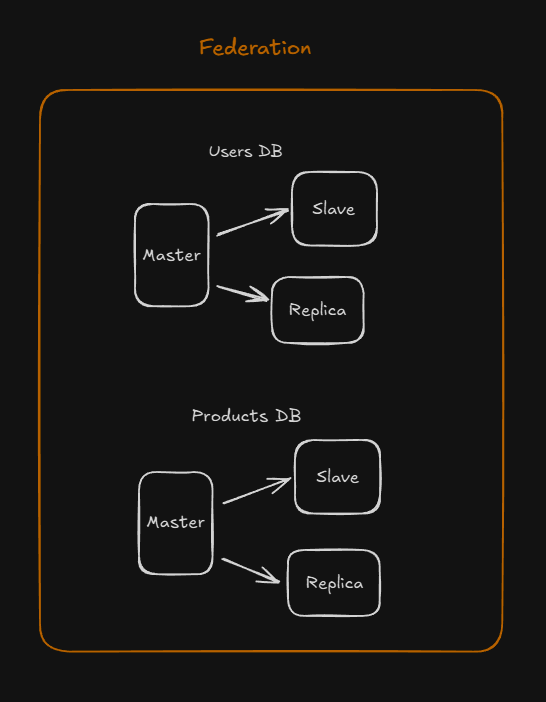
Federation- Federation (or functional partitioning) splits up databases by function. For example, instead of a single, monolithic database, you could have three databases: forums, users, and products, resulting in less read and write traffic to each database and therefore less replication lag. Smaller databases result in more data that can fit in memory, which in turn results in more cache hits due to improved cache locality. With no single central master serializing writes you can write in parallel, increasing throughput.
Disadvantage of federation -
-Federation is not effective if your schema requires huge functions or tables.
-You'll need to update your application logic to determine which database to read and write.
-Joining data from two databases is more complex with a server link.
-Federation adds more hardware and additional complexity.
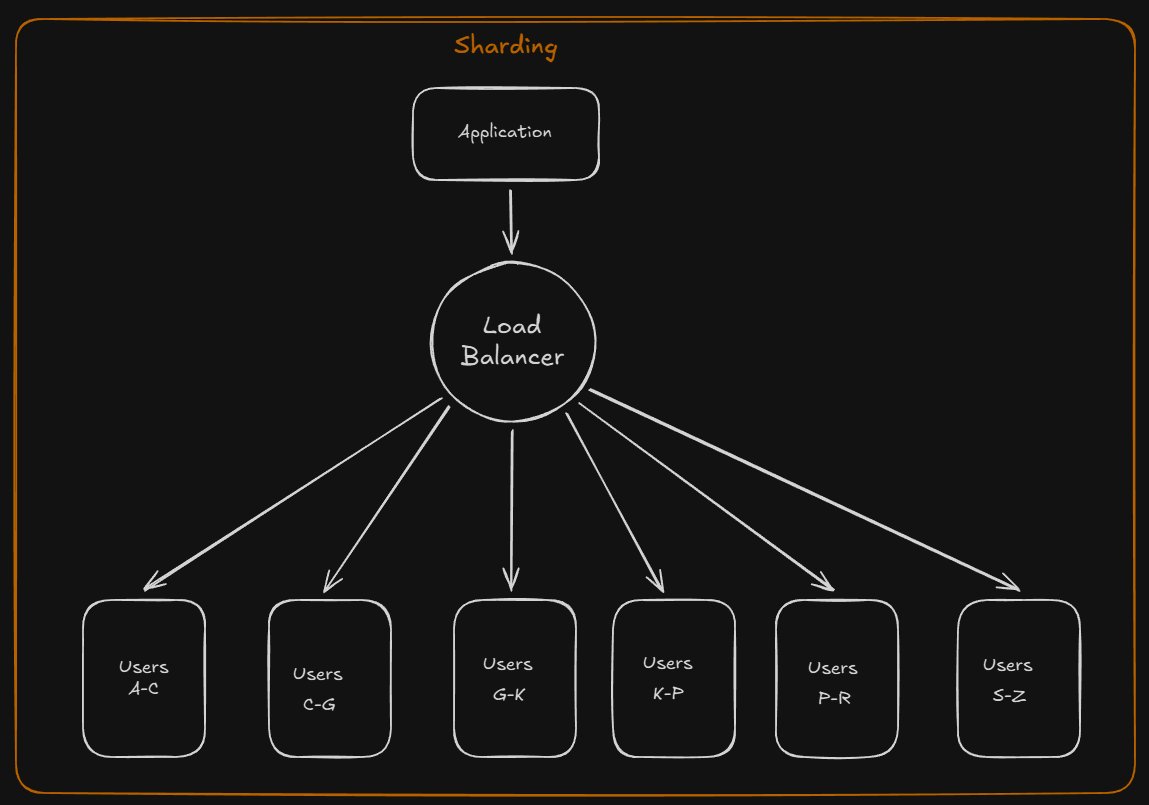
Sharding -Sharding distributes data across different databases such that each database can only manage a subset of the data. Taking a users database as an example, as the number of users increases, more shards are added to the cluster.
Disadvantages of sharding -
-You'll need to update your application logic to work with shards, which could result in complex SQL queries.
-Data distribution can become lopsided in a shard. For example, a set of power users on a shard could result in increased load to that shard compared to others.
-Rebalancing adds additional complexity. A sharding function based on consistent hashing can reduce the amount of transferred data.
-Joining data from multiple shards is more complex.
Sharding adds more hardware and additional complexity.
Denormalisation and sql tuning topics are super easy you can lookup on the internet , as the post become already so damn big you can look for these yourself that would be super easy to understand .
Thanks for reading :)
THE NEXT POST WILL BE ABOUT NOSQL DATABASE.
6
5
31
2,029
System Design Phase 0 - Part 2 - Day 2
Core Building Blocks
These are the minimum concepts any system must understand before designing real applications.
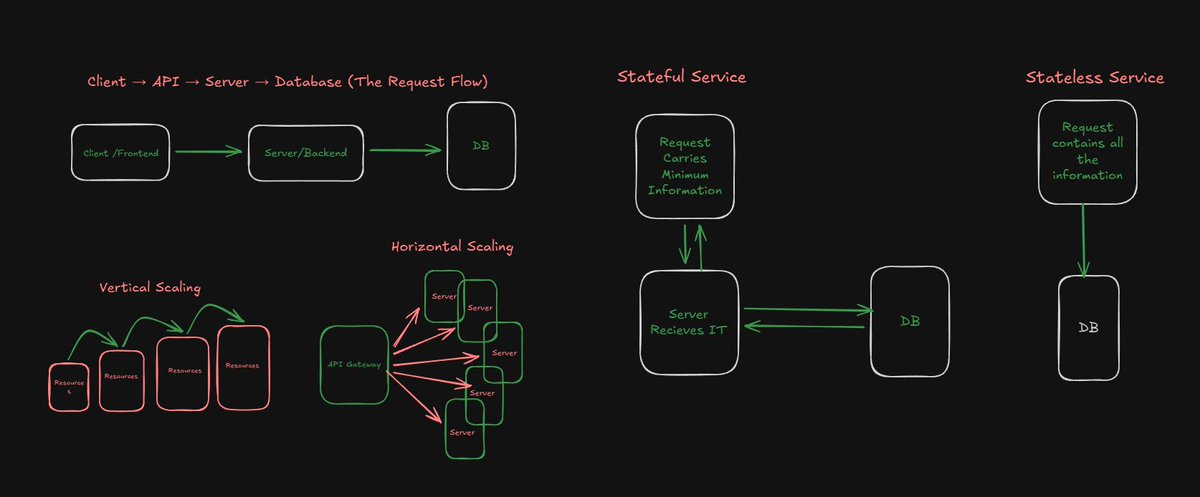
1 .Client → API → Server → Database (The Request Flow)
As the name suggest above Client calls the api and then API contacts to datbase.
Basically Client is your Frontend and Server is Your API and Datbase is Where you store your data.
You make a HTTP request it senda POST PUT GET etc request to your api and then it stores the value or updates the value in the database. This is the most basic flow for every system.
2.Latency vs Throughput:
These two determines how much fast and how much presure your system can handle.
Latency determines how much faster your system responds.
Example:
API responded in 120ms.
Lower latency = better user experience.
Throughput determines how much requests your system can handle concurrently.
Example:
Server can handle 20,000 requests/sec.
Throughput = capacity.
Balancing both is the best system design you cannot go all in on one remember that . if you go all in on latency your db will crash handling 20000 req P/s.
And if you decide to go all in on Throughput it will cost you performance issue to proceed a ton of requests.
3.Horizontal vs Vertical Scaling
Horizontal Scaling
This scaling mechanism is very simple you just keep adding new servers and according to the load you face from the system.
A load balancer will decide which requests will go to which server according to the count of requests incoming. This is how Google, Netflix, Meta scale.
Vertical Scaling
This scaling mechanism is very simple instead of adding more servers you just increases the resources of the current server for example 16GB ram server isnt enough for you anymore so you upgrade it to 64GB its that simple.
Rule:
Small companies scale vertically.
Big companies scale horizontally.
4.Stateless vs Stateful Services
Stateless Service
Service does NOT store session or user data inside itself.
Every request is independent.
For example:
Login API
Search endpoint
Notification service
These services just act as a bridge nothing else they dont store anything but their state is stored in DB, Cache Redis, JWT tokens, Object Storage etc
Stateful Service
These services stores sessions and maintains the state of the application.
These type of services recieves limited information because they know what to do with that limited information and can fetch more information through that limited information.
Example:
WebSocket chat server
Video streaming session
Multiplayer game server
Stateful systems are unavoidable in certain use cases (like real-time comms).
But we try to minimize them where possible.
5.Serialization Formats – JSON, Protobuf, Avro
Serialization = converting data into a format that can be sent over the network.
For Example
JSON
Human readable
Text-based
Easy to debug
Slower
Larger size
Used in: REST APIs
Protobuf (Protocol Buffers by Google)
Binary format
Extremely fast
Very compact
Schema-based
Used in: gRPC, microservices, internal communication at scale.
Avro
Binary format
Schema included with data
Great for big data & streaming
Used in: Kafka, Hadoop, data pipelines.
So these were the core topics which someone has to know before building a basic system for like a single API these topics are must.
Thanks for reading :) I hope you learnt something from this.
8
6
35
1,504

29 Nov 2025
Hey @BreannaMorello can you interview @VBierschwale and @EngineerChiefCE on infowars. They have a lot of info on the H1B scam and each run a datbase with facts to prove our gov is lying. We need traction on this. And Virgil is running to replace Cornyn in Texas.
1
3
7
246
Lets learn about scalability techniques in system design which is basically the core fundamental of every system.
Why does this concept exist and what problems does it solves?
When your sites traffic increases from one to a million users in a minute. which eats machine resources to compute all the requets and data retrieval, thats why scaling a good system is important.
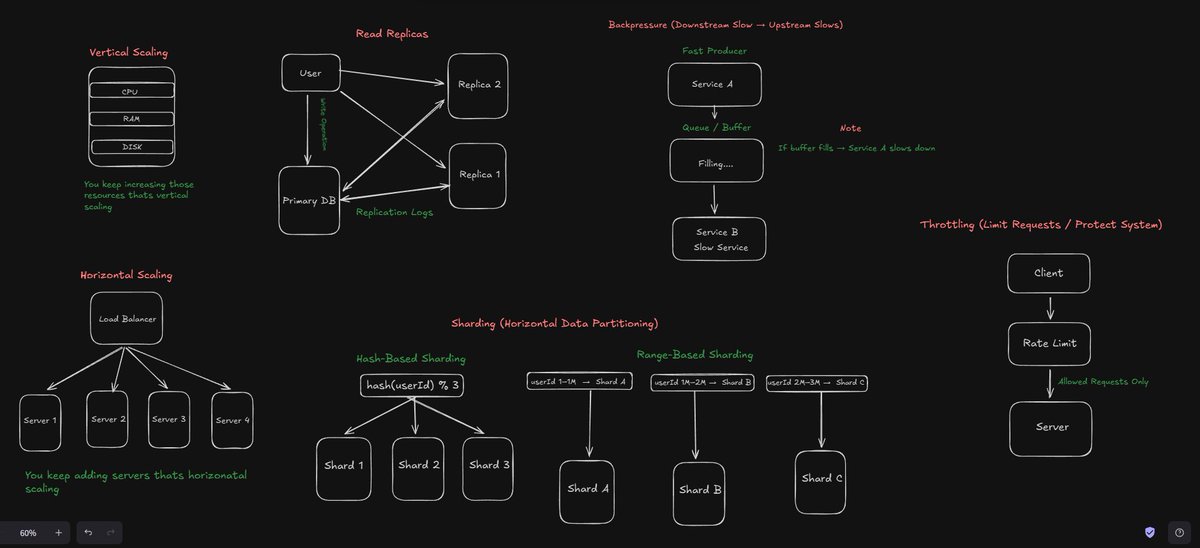
Horizontal and Vertical Scaling:
Both are scaling techniques
Horizontal scaling means you add more servers that runs your code basically.
Vertical scaling means you keep upgrading the same server like incresing ram cpu and disk power which is basically not a recommended approach for obvious reasons.
Database Sharding:
Sharding is the process of splitting a large dataset across multiple database servers, where each shard stores only a specific portion of the data such as users A–H in one shard, H–P in another, and so on allowing the system to handle more traffic, reduce load on any single database, and scale horizontally with better performance.
Replicas,A read replica is a fully duplicated copy of your primary (master) database that is kept in sync with the primary database through replication basicall its read only datbase you can only do SELECT queries.
This replicas are used to prevent load from primary database for both read and write operations.
Now primary only handles writes .
Throttling is a technique used to limit the rate of incoming requests so a system doesn’t get overloaded. It ensures that APIs, microservices, or authentication endpoints don’t receive more traffic than they can safely handle.
By enforcing rules like “100 requests per minute per user” or “only 5 login attempts allowed,” throttling protects the backend from sudden traffic spikes, abusive clients, or bot attacks. This keeps the system stable, prevents downtime, and guarantees fair usage for all users.
Backpressure Handling ensures that when a downstream system is slow or overloaded, the upstream system automatically slows down instead of blindly pushing more data.
This prevents cascading failures across the architecture. Systems like Kafka, reactive streams, and modern data pipelines use backpressure so that consumers control the pace and producers adjust their output accordingly.
It ensures smooth flow, protects resources, and keeps the entire pipeline healthy even under heavy load.
There are Event sourcing and cqrs are also in this techniques which ive explained pretty well in previous posts.
Thanks for reading and your valuable time :)
10
7
38
1,959

17 Nov 2025
Sir, An year ago I have developed similar system using GoogleFInance APIs.
Simple yet very Effective, No Datbase & No Hardware Infra requirement.
Backtested above momentum along with Simple MarketCycle form 2009 to 2024. Results are quite amazing with < 8% Max. Drawdown.
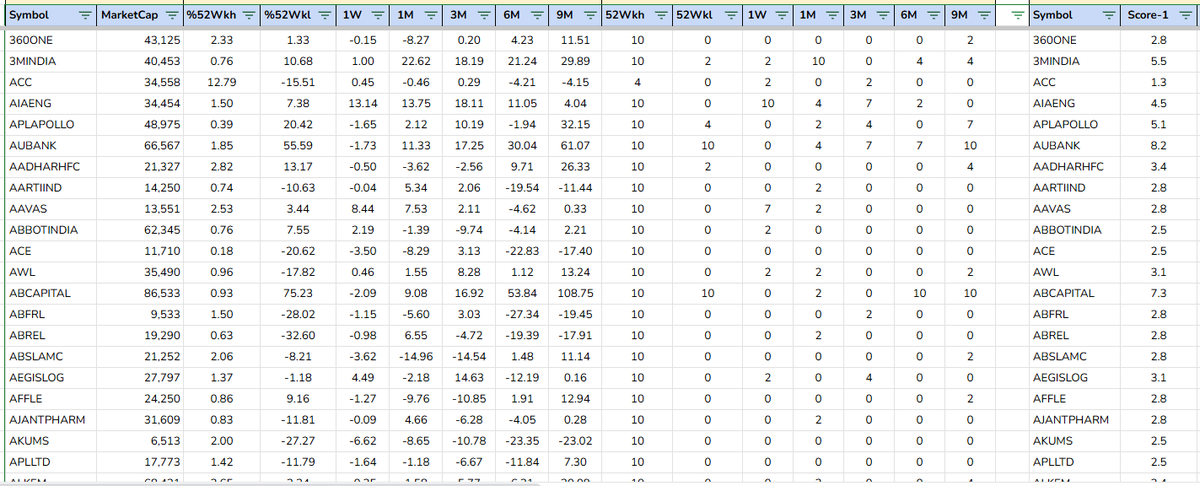
2
7
638

I've been building Bklit.com - an open-source analytics SaaS. It's finally starting to feel as though it's maturing and i'm pretty hyped about it...
◈ Hosted @vercel
◈ Database @prisma postgres
◈ Datbase ORM @prisma
◈ Framework @nextjs
◈ Authentication @better_auth
◈ Emailing @resend
◈ Payments @polar_sh
◈ Monorepo @turborepo
◈ Package manager @pnpmjs
◈ Typesafe APIs @trpcio
◈ Linter @biomejs
◈ UI @shadcn
1
1
19
2,025

Here's how you can teach that:
> teach prompting techniques
> teach UI terms (padding etc
> teach backend terms (datbase etc)
> teach product testing
> teach deployment.
Don't teach coding! Let them use "English" as their main coding language.
Now just let them run wild.
1 Nov 2025

vibe coding should be taught in every school and university around the world, first day on campus, welcome to the future
6
2
20
4,351