
Jun 13
【TechFeedまとめ】2026-06-14
■ Zenn
1. 「モダリティ間の不一致を検知して作り直す」が特許になった日本でマルチモーダルエージェントを作る話
zenn.dev/yasunami_daichi/art…
2. GA した GitHub Copilot SDK (.NET) を試してみた
zenn.dev/microsoft/articles/…
3. AIエージェントとの開発体験を劇的に改善する「セッション主導型」CLIツールを作った
zenn.dev/aqwert/articles/95b…
4. CLAUDE.mdに書いたのに守られない——その正体は「渡す場所」の設計だった(Zenn Book Vol.4「仕組みを渡すまで」)
zenn.dev/tottoko_hamu/articl…
5. 社内ガイドラインが効かない、情報漏洩は安易な個人AI利用からはじまる
zenn.dev/syoshida07/articles…
6. あなたのAIサービスはEU AI法 第50条の対象? 3分でわかる適用判定フローと最小対応
zenn.dev/akagifreeez/article…
7. 日本語RAGに向く中国製オープンソースパーサーはどれか — クロスオーバーだった。BM25ならDeepDoc、denseならMinerU
zenn.dev/elvisyao/articles/9…
8. 「モダリティ間の不一致を検知して作り直す」が特許になった日本でマルチモーダルエージェントを作る話
zenn.dev/yasunami_daichi/art…
9. CLAUDE.mdに書いたのに守られない——その正体は「渡す場所」の設計だった(Zenn Book Vol.4「仕組みを渡すまで」)
zenn.dev/tottoko_hamu/articl…
10. 自分用のLoLのAIコーチングサイトを作ってしばらく使ってみた
zenn.dev/minty1st/articles/c…
11. LLMOps学習でBedrock Claudeを動かしてみた
zenn.dev/yukika/articles/202…
12. UniversalMigrator — 113言語対応、レガシーコード移行の初期診断&変換たたき台ツール
zenn.dev/highdefini/articles…
13. Codex の personal skill を作り、配布可能な skill-export まで整備する
zenn.dev/hikosakasohtaro/art…
14. AIエージェントとの開発体験を劇的に改善する「セッション主導型」CLIツールを作った
zenn.dev/aqwert/articles/95b…
■ Qitta
1. Claude Code v2.1.176: モデル制御の抜け穴修正とバグ修正まとめ
qiita.com/picnic/items/f8974…
2. Claude Mythos 5・Fable 5 アクセス一時停止:影響と対応策まとめ
qiita.com/picnic/items/1e3c8…
3. Claude Codeのネスト型サブエージェント入門 — 最大5階層の設計とトークン設計の勘所
qiita.com/kai_kou/items/618d…
4. 静的キャッシュからPoWの反撃、多層防御からLLMへの毒入れまで
qiita.com/faliye/items/667f7…
5. Claude Code v2.1.176: モデル制御の抜け穴修正とバグ修正まとめ
qiita.com/picnic/items/f8974…
6. Claude Mythos 5・Fable 5 アクセス一時停止:影響と対応策まとめ
qiita.com/picnic/items/1e3c8…
7. 株研究を生成AI行うためのPaaSを作ってみた
qiita.com/belre/items/832e40…
8. Playwright GPT-4oで完全自律型スクレイピングエージェントを作った
qiita.com/muttyan/items/96bd…
9. 『Havoc・Sliver・Metasploitの違い』〜「3つの用途」を混同したまま使うと、本番のペネトレーションテストで詰まる〜
qiita.com/suzukengo/items/d1…
10. Claude Code v2.1.176: モデル制御の抜け穴修正とバグ修正まとめ
qiita.com/picnic/items/f8974…
11. Claude Mythos 5・Fable 5 アクセス一時停止:影響と対応策まとめ
qiita.com/picnic/items/1e3c8…
12. Claude API 最新動向まとめ:Fable 5登場・モデル廃止・破壊的変更を完全解説
qiita.com/picnic/items/ed431…
13. OpenAIがCodexの「レートリミット貯金機能」を発表|好きなタイミングでリセットを利用可能に
qiita.com/zhao-xy/items/9c47…
14. 静的キャッシュからPoWの反撃、多層防御からLLMへの毒入れまで
qiita.com/faliye/items/667f7…
15. Claude Code v2.1.176: モデル制御の抜け穴修正とバグ修正まとめ
qiita.com/picnic/items/f8974…
16. Claude Mythos 5・Fable 5 アクセス一時停止:影響と対応策まとめ
qiita.com/picnic/items/1e3c8…
17. AIとかんたんな謎解き風サイトを作ってみる
qiita.com/omuraisu02/items/9…
18. IBM BobからObsidianを操作する(MCP)
qiita.com/teruq/items/b2d0eb…
19. SalesforceのAgentforce Vibesとは?AIコーディング環境をざっくり整理する
qiita.com/Tadataka_Takahashi…
20. 「ClickHouse のチューニングは LLM エージェント向き」は本当か ― 公式 MCP × Claude で「遅いクエリ特定 → EXPLAIN → スキーマ改善 → 再計測」を自律的に回してみた
qiita.com/asahide/items/902a…
#TechFeed #開発
【PR】CursorのProプラン(月$20)が高くて迷っていた方に朗報です!
下記の招待リンクから新規登録すると、初月が【半額(実質$10)】で使えます。
通常の無料枠だと物足りない方、1ヶ月だけ格安でフル機能を試してみませんか?👇
cursor.com/referral?code=WRL…
2
792

Apr 2
Researchers built a RAG engine that:
- doesn't hallucinate sources
- understands document structure before chunking
- traces every answer to exact page and section
- syncs directly from Confluence, Notion, Google Drive, S3, Discord
- understands tables, scanned documents, and images inside PDFs
And it became the #1 open source project on GitHub in 2025.
Here's the core problem it solves:
Ask a typical RAG system about a liability buried in footnote 34 of a 200-page SEC filing. It returns whatever chunk looks most similar to your question. The actual answer, cross-referenced in an appendix, dependent on context from three sections earlier - never surfaces. Your LLM confidently hallucinates something that sounds right.
The problem isn't the model. It's everything that happened before the model saw anything.
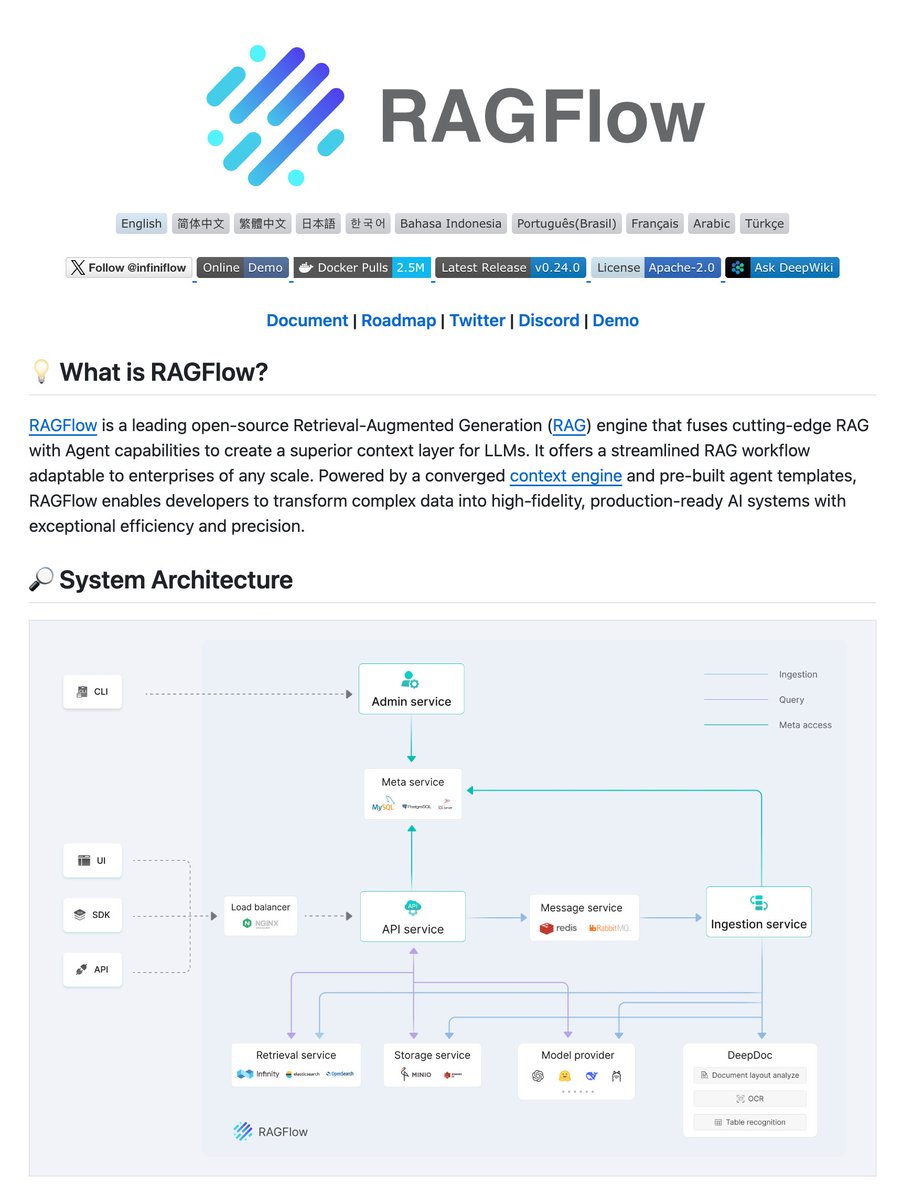
RAGFlow was built around one principle: quality in, quality out.
They built DeepDoc, their own document understanding engine with OCR, table recognition, and layout analysis, because a scanned invoice, a 200-page SEC filing, and a table buried in slide 47 of a PowerPoint are not the same as plain text. Documents are understood before they are chunked. Structure is respected. Every answer traces back to exact page and section. You can see exactly why a specific answer was returned.
What this makes possible:
→ Knowledge bases from Confluence, S3, Notion, Discord, Google Drive
→ Agentic workflows with persistent memory across sessions
→ Multi-modal understanding of images inside PDFs and DOCX files
→ MCP integration for production agent pipelines
→ Template-based chunking with human intervention support
76.9K stars. 527 contributors. 2.5M Docker pulls.
11
24
119
5,057

Mar 6
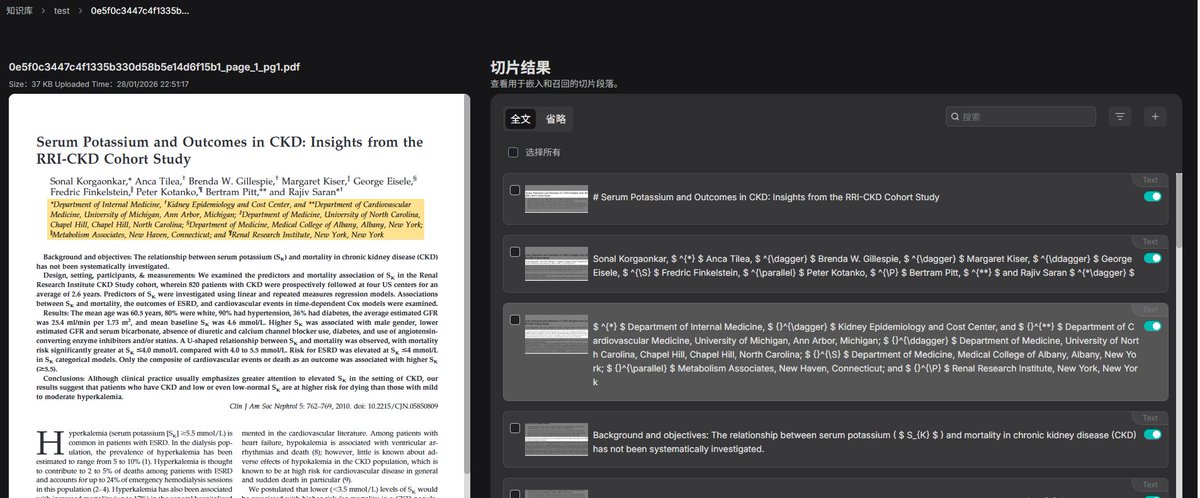
🚀 RAGFlow × PaddleOCR-VL-1.5 — a powerful new integration for document RAG
PaddleOCR-VL-1.5 is now integrated into RAGFlow’s DeepDoc Parser, bringing stronger document understanding to the very first step of the RAG pipeline.
Why it stands out
🔹 Better parsing for scans, photos, distortion, and complex layouts
🔹 Polygon-level localization for more precise element detection
🔹 Cross-page table merging heading continuity for long documents
🔹 Visual citation grounding for more traceable and trustworthy retrieval
From messy PDFs to structured, citation-ready knowledge — now built directly into RAGFlow.
Learn more
👉PaddleOCR-VL-1.5:
github.com/PaddlePaddle/Padd…
👉RAGFlow:
github.com/infiniflow/ragflo…
👉Quick start:
ragflow.io
#RAGFlow #PaddleOCR #RAG #DocumentAI

1
10
119
25,168

deployed DeepDoc contract address is 0x75573053B0D559CE669D83c8f2E74d2Ab1922BA3
view token: app.doppler.lol/tokens/base/…
10
deployed deepdoc contract address is 0x1Ea753c628CAf12C24529977BA65aba0564f6bA3
view token: app.doppler.lol/tokens/base/…
note: due to platform restrictions on X, I couldn't transfer the fee beneficiary share to @tom_doerr (0xaea333d4f6f750985e931e1b74865794b3205672). the creator share (57%) is currently assigned to your wallet.
295

26 Nov 2025
为什么知识库配置明明一样,但不同平台的效果却完全不同?
昨晚给一家企业做咨询,讨论到他们内部流程的知识库目前检索效果不佳。我看他们在用的是一个私有部署的工作流平台,顺口问了一句:“这块有没有试过专门的 FastGPT 或者 RAGFlow?”
对方很疑惑:“没有。我们这个平台现在的知识库功能挺全的,切片、向量化、混合检索都有。底层的原理不都是 RAG 吗?换个平台效果能有多大差别?”
这其实是很多B端落地的误区:以为 RAG(检索增强生成)是一个标准化的功能模块,只要有了“上传 切片 搜索”这三板斧,效果就应该是一样的。
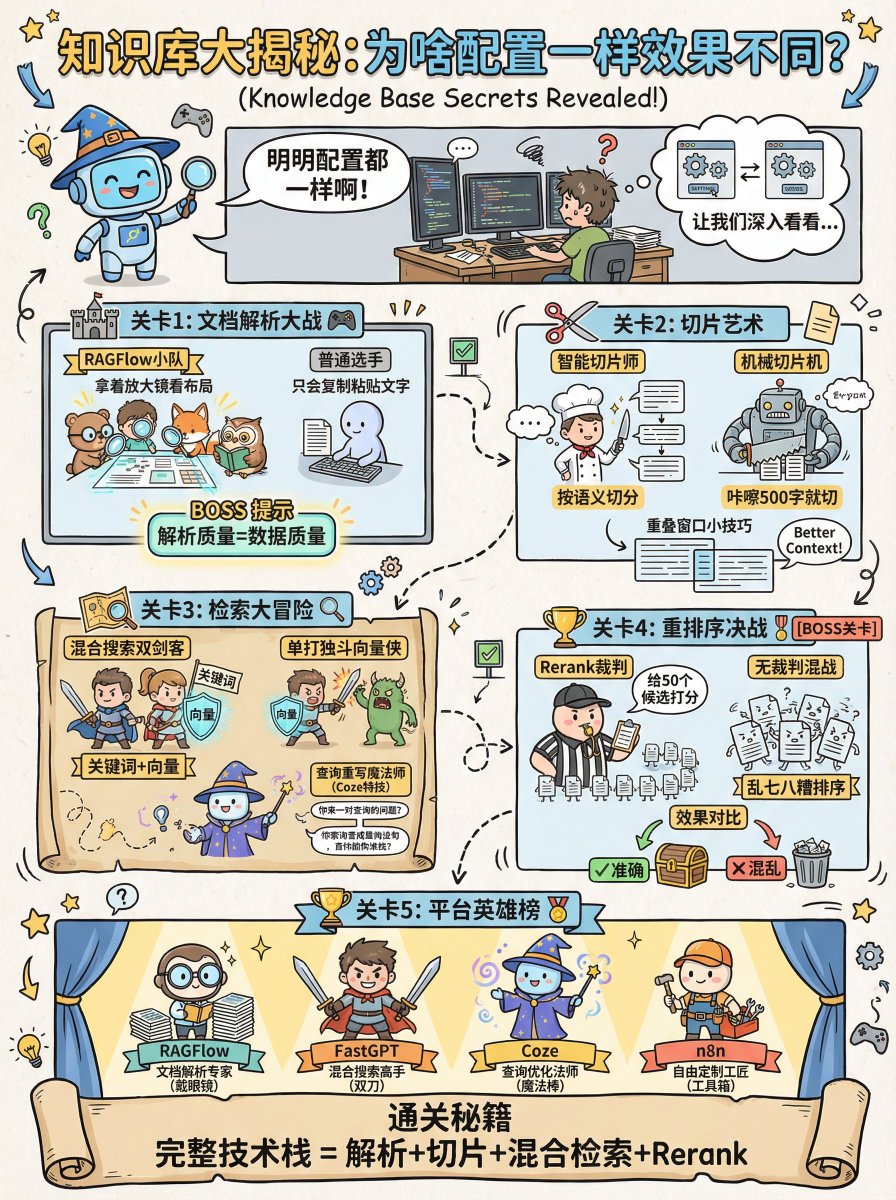
其实不然。这里的核心差异在于「知识库工程化」的深度。即使你上传同样的文件、配置同样的切片大小(Chunk Size)、使用同样的 Embedding 模型,不同平台跑出来的检索命中率可能天差地别。
1、很多人被平台配置的UI 骗了。
通用的 RAG 流程确实大同小异:文档解析、切片、向量化、存储、检索、生成。在 UI 界面上,你看到的配置项也无非是“切片长度 512,TopK 5”。
但这两个看似相同的数字背后,执行的代码逻辑可能完全不同。决定检索质量的,往往是那些配置界面上看不到的隐形工程。
2、差异的第一步发生在「文档解析」(Parsing)阶段:是读文字,还是理解排版?
很多通用平台使用开源的基础库(如 LangChain 的默认 Loader)来读取 PDF。如果你的文档是双栏排版,普通解析器只会傻傻地按行读取,结果就是把左栏的半句话和右栏的半句话拼在一起,造成语义错乱。这种数据一旦进入数据库,检索效果必然崩塌。
而在RAGFlow 这类平台中,它引入了 DeepDoc 视觉模型。它像人眼一样先看文档的布局,识别出哪里是标题、哪里是表格、哪里是跨页段落。比如处理一张复杂的财务报表,普通平台提取出来的是一堆乱码字符,而 RAGFlow 能保留表格结构。解析精度的差异,避免了Garbage in, Garbage out 的问题。
3、当「切片策略」设置 Chunk Size = 500 时,不同平台的执行逻辑也是完全不同的:字符数 vs 语义。
n8n 如果你手动搭建流程,它可能就是机械地在第 500 个字符处截断。如果这句话没说完?对不起,切断。这会导致关键信息的上下文丢失。
而 Coze(扣子) 或 FastGPT 的切片逻辑更具语义感知。它们会尝试寻找句号、段落结束符,甚至根据语义完整性自动调整切片长度,确保一段话是完整的。更有甚者,如 RAGFlow 支持的分层切片(RAPTOR)或知识图谱结构,它不是在切分文本,而是在构建信息之间的逻辑关联。
4、「检索策略」配置里都叫“混合检索”,但搜得不一定都准
纯向量检索对于模糊语义很强,但对精确信息很弱。比如你搜“RTX 4090 显卡参数”,纯向量可能会给你找来一堆“高性能计算设备”的描述,却漏掉了包含“4090”这个具体型号的段落。
FastGPT 和 RAGFlow 都在这里下了重注。它们不仅强制开启关键词(BM25)与向量的混合检索,更关键的是引入了 重排序(Rerank) 步骤。系统先粗略召回 50 个片段,再用一个精细模型给这 50 个片段打分排序。
Coze 的做法则更偏向「意图优化」。在检索之前,它可能已经在后台把用户模糊的提问“那个很贵的显卡多少钱”,悄悄重写成了“RTX 4090 的具体价格”,然后再去检索。这种“查询重写”机制,极大地提升了命中率,但你在配置面板上是看不到的。
5、搞清楚不同平台的工程基因,也就决定了他们的应用场景。
RAGFlow 属于重型解析引擎。 它把工程资源砸在了 OCR 和版面分析上。如果你的资料是复杂的工业手册、扫描件、研报,RAGFlow 的视觉解析能力会让检索效果肉眼可见地提升。
FastGPT 偏前端应用。 它的核心是 Q&A 问答对的处理和高效的混合检索工作流。它非常适合做客户服务、标准问答库,强调的是让“问题”直接找到“答案”。
Coze 是有点迷的。 它的知识库是嵌在 Agent 逻辑里的。你觉得它效果好,往往是因为它的工作流在前置意图识别和后置数据处理上帮你做了优化,但效果依然不如前两者。
n8n 实际上并没有知识库,啥都要你自己去搭,费劲。
对于这个话题,大家还有什么看法没?欢迎讨论。
5
4
34
9,254

18 Oct 2025
Just wrapped up the retrieval & generation pipeline for the single-doc chat module in DeepDoc.
Also shipped the multi-doc chat module with ingestion, retriever & generation pipelines.
Tomorrow: diving deeper into reranking techniques and implementing them
#buildinpublic #rag
1
7
113
16 Oct 2025
Had to park DeepDoc development for a while due to some tight deadlines on shipping a new feature at work.
Since yesterday, I’ve been spending some time building document compare module and single document chat module for DeepDoc
#buildinpublic

1
5
113
1 Sep 2025
After chunk analysis, DeepDoc:
•Consolidates multiple summaries into a single narrative
•Picks the best title (heuristics: length, capitalization, relevance)
•Chooses valid authors/dates
•Detects language
•Merges page counts intelligently
1
2
14
1 Sep 2025
New strategy : dynamic document handling
Instead of feeding in the whole doc all at once, DeepDoc now :
- Splits texts into chunks
- Runs metadata extraction per chunk
- Consolidates result into a clean JSON schema
1
2
9
10 Aug 2025
Day 6 of #100DaysOfCode
- Solved a medium LeetCode : Valid Sudoku
- Explored #Structlog: processor chaining, JSON logging, console & file outputs
Built a custom logger for DeepDoc
#Python #DevLogs
3
78
4 Aug 2025
Update on DeepDoc:
Decided upon the features:
- document analysis
- document comparison
- multidoc chat
- single doc chat
Implemented data ingestion and document comparator pipelines
Also a quick refresher on numpy operations, broadcasting
#llmops
2
42
20 Jul 2025
Day 2 and 3 of #100DaysOfCode
Solved a medium @neetcode1 problem on group anagrams
Starting to learn LLMOps with a project based approach by building DeepDoc : an AI powered document chat, comparison and analysis platform
#rebootprotocol
#llmops
#LearnInPublic
1
2
57

23 Apr 2025
RAGFlow 0.18 is released, highlights:
-Support MCP server.
-DeepDoc supports adopting VLM model as a processing pipeline.
-Support agent version control.
-Agents can be shared with team members.
-Enhanced conversation experiences.
More features here👉
github.com/infiniflow/ragflo…
2
4
748
18 Dec 2024
RAGFlow 0.15 is released! Highlights:
-Upgrades doc layout analysis in DeepDoc
-Supports step run for Agent
-Supports resuming GraphRAG/RAPTOR from a failure, enhancing task management resilience
-Importing/Exporting agents in JSON
More features here👉:
github.com/infiniflow/ragflo…
3
1,438

3 Oct 2024
# RAG 落地场景
基于 3500 页 PDF 构建工程 Chatbot
Reddit 讨论很热烈的话题, 作者接 Boss 任务需要基于一份 3500 页的标准文档, 为团队构建专属的工程 Chatbot。
挺典型的 RAG 场景, 而且是很典型的重点在 R 的场景, 也代表了非常多企业的痛点, 企业数据积累不少但质量不高:
- 文件可能是长年累月积累下来的, 缺少整体结构, 基本属于无限累加
- 文件中文本质量很低, 可能附加了很多截图, 外链或其他无法访问的企业内部系统链接
- 文件的正确性不能保证, 也无法完全修正
如果你正在为团队设计构建, 或正在为企业咨询设计, 在动手设计 RAG 方案前, 还是要尽可能借助更懂这些文件的人来提升文件的结构化和可用性:
- 超长文件拆分为多个小文件
- 多个文件的关联结构, 每个文件的目录整理
- 无法访问的外链补充对应内容, 或删掉链接, 无效截图删除
- 无法确定正确性或已无效的内容, 删除掉
做完这一步, RAG 方案就成功了至少一半, 因为这些是最没有参考经验, 每个团队的情况都不太一样, 且不容易得到团队足够的支持。
到了 R 这一步, 问题就比较明确了, PDF 解析可以借助很多开源方案:
- @OpenDataLab_AI MinerU, @UnstructuredIO Unstructured 都是解析 PDF 很好的选择, 兼顾文本和图像、页面结构等
- @infiniflowai Ragflow deepdoc 对表格和 Excel 等的解析可以参考使用
- @firecrawl @JinaAI_ 爬取外链、提取网页内容等可以借助它们来实现
文件读取解析后, 后面的分块、嵌入、检索、重排序、生成就都有很明确的方案了。
# Reddit 原帖
reddit.com/r/ChatGPTCoding/c…

2
61
248
19,555

31 Jul 2024
Generate fresh content with old files using DeepDoc.
Try it here: silatus.com
1
1
3
5,736

9 May 2024
🌎 @SylvesterCancer researcher @deepdoc & PhD student @lashaerolle were co-authors in the @TheLancetOncol "Personal View" paper which discusses challenges in delivering cancer care in the Caribbean, esp. amid climate hazards. #GlobalHealthCollaboration
bit.ly/3Wy57eA

2
5
950