
16 Dec 2025
Our new #Wisedocs Tech Blog shows how we modernized #EntityExtraction with LLM powered reranking. #ML Intern Jessica Ding shares how testing Gemini models and refining prompts boosted speed and accuracy without rebuilding our models.
Read the Tech Blog 👇
hubs.ly/Q03XxK870

2
55

2 Jul 2025
At 5.15, we use #NLP #ML to turn emails, chats, and tickets into insights.
From #EntityExtraction to #SentimentAnalysis, our pipelines enable smarter, faster decisions.
Let’s build smarter.
#AI #DataAnalysis #DataExtraction #DataScience
wix.to/oU4BdjD

2
23

30 May 2025
I've been building a research tool that automatically extracts entities from historical document collections to create structured knowledge databases. (It's called 'hinbox' (i.e. 'historian in a box') via McChrystal's framing IYKYK 🫠)
The project connects my historian background (manually building Afghan media databases in the 2000s) with current AI capabilities. It processes documents to identify people, organisations, locations, and events, then intelligently merges similar entities across sources.
What makes this interesting: I'm using it as a practical testbed for systematic AI evaluation techniques from the @HamelHusain / @sh_reya evals course I've been taking. Rather than abstract methodology discussions, I want to document rigorous approaches to prompt optimisation and error analysis applied to real research problems.
The tool isn't production-ready - entity merging needs work, prompts require iteration. (Frontend also needs prettifying.) But that's the point. The meaningful learning happens in systematic improvement, not just initial builds.
Upcoming posts will show concrete examples of structured evaluation frameworks improving extraction accuracy. Perfect case study for moving beyond intuitive AI development toward measurable approaches.
Full technical breakdown and context linked in the thread 👇
#AI #Research #History #EntityExtraction #Evals
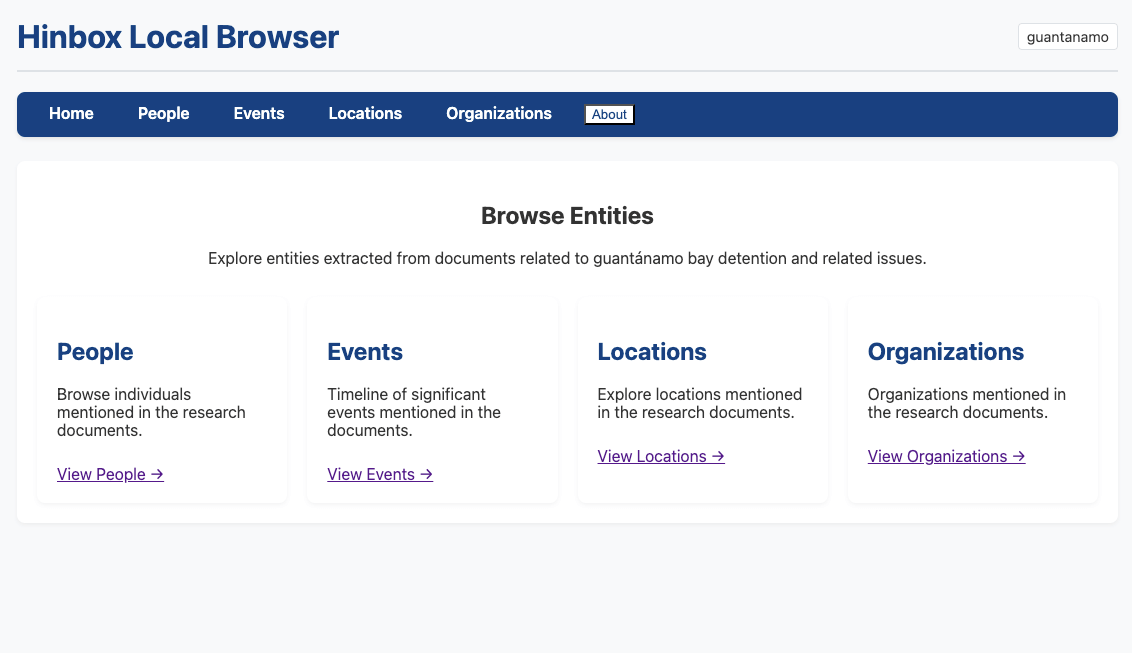
ALT Frontpage of the entity browser UI that comes with the project.
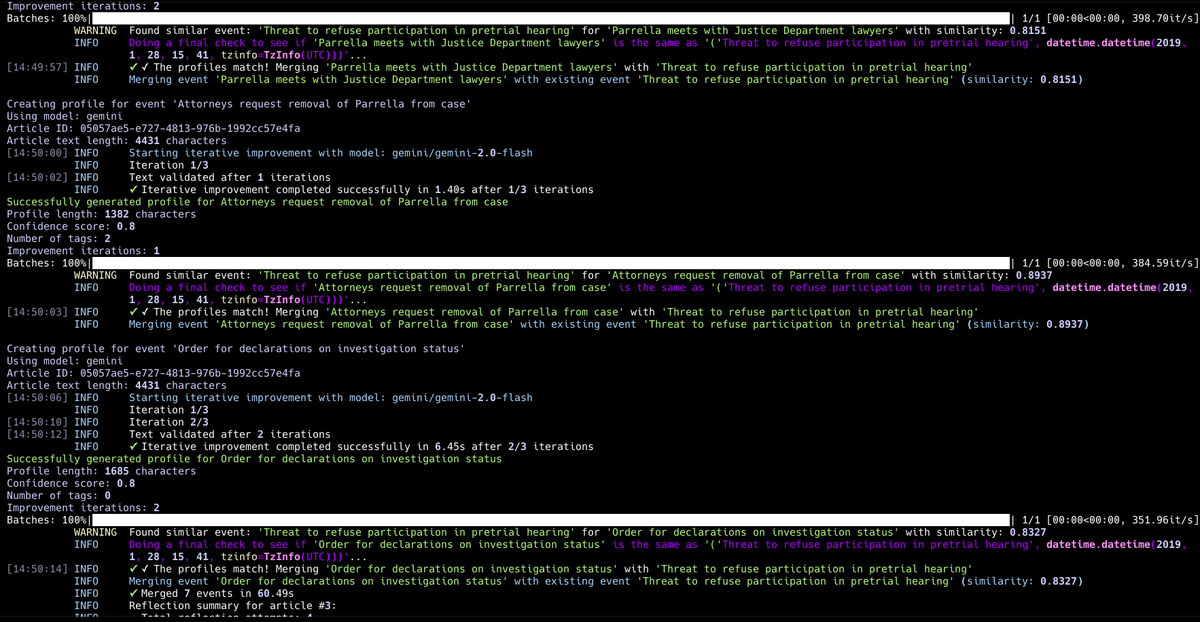
ALT Some processing logs while the system crunches through the articles.
4
9
57
8,575

Extract entities from 7.5 million reports in just 3 hours with DataWalk’s cutting-edge AI and seamless integration. Turn unstructured text into actionable intelligence—faster, smarter, and more secure! hubs.li/Q035ChK20 #entityextraction #actionableintelligence #AI
2
11
1,395

7 Dec 2024
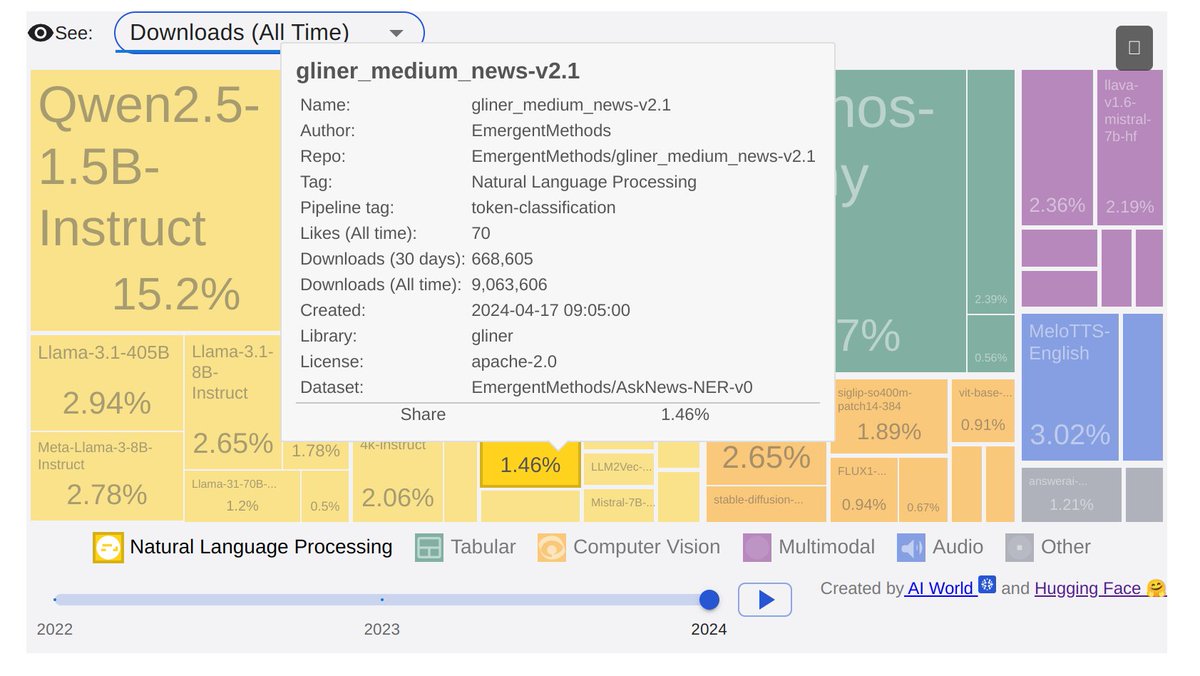
#GLiNER-News is among the top 20 most downloaded models of all time on @huggingface 🎉
To celebrate our achievement, we made the coupon code: BESTENTITYEXTRACTOR24 for 50% off the Spelunker or Analyst Tier at my.asknews.app/plans
#EntityExtraction #NEWS #opensource #BEST
1
2
2
83

13 Feb 2024
🔵 Seems to work better with non-English text even though it was only trained on English
bit.ly/3oTS3l5
What could/should be done with the Wikipedia URLs of entities?
#OpenAI #entityextraction #structureddata #generativeai
2/2
2
128

2 Feb 2024
3/3 More details on the SEASON project, including the custom automatic entity extraction and classification model used in this work can be found here:
github.com/kalawinka/season
doi.org/10.1007/s11192-023-0…
huggingface.co/kalawinka/fla…
#EntityExtraction #NLP #India #Germany #Bibliometrics
1
3
150

17 Jun 2023
This thread is saved to your Notion database.
Tags: [Openai, Langchain, Entityextraction]
14
17 Jun 2023
This thread is saved to your Notion database.
Tags: [Openai, Langchain, Entityextraction]
14

📚 Ever dreamed of discovering hidden insights and trends in texts without passing hours of reading? With #TopicExtraction #APIs, it’s no longer a dream (🔗 in comment)
Cohere
@googlecloud
@IBMWatson
@MeaningCloud
@OpenAI
Rosette
@TextRazor
@twinwordinc
#AI #EntityExtraction

1
1
2
170

23 Jan 2023
It's #NationalHandwritingDay and we're highlighting @Rosoka which brings an additional power of analysis to ADF's suite of digital forensic software - hubs.ly/Q01xyB9l0
#Rosoka #EntityExtraction #Intel #languagetranslation #gisting #gloss #infosec #bigdata

1
3
386

4 Oct 2022
Automatically detect and classify key elements/entities from unstructured text data from any industry.
Know More- bit.ly/3SUMdJS
seulgi #entityextraction #textanalysis

ALT Bytesview Entity Extraction
2
30 Sep 2022
Solve investigations in the field with Triage-G2 PRO. Digital forensic text analytics for 230 languages & English Language gisting: hubs.ly/Q01ncbMJ0
#digitalforensics #dfir #forensics #intel #investigator #case #legal #entityextraction #multilingual #translation

ALT Triage-G2 PRO dongle showing entity extraction and translation using the ADF Rosoka Add-on in 230 languages
2
5

25 Jul 2022
Keywords in #ConversationalAI
Intents, Agent, NLU, #NLP, #Chatbot, DeepLearning, GDPR, IVR, #ML, SentimentAnalysis, VoiceAssistant, NeuralNetworks, #API, Context, Dialog, EntityExtraction, EntityRecognition, FAQ, Handover, Unsupervised, UX
What else?
1
2

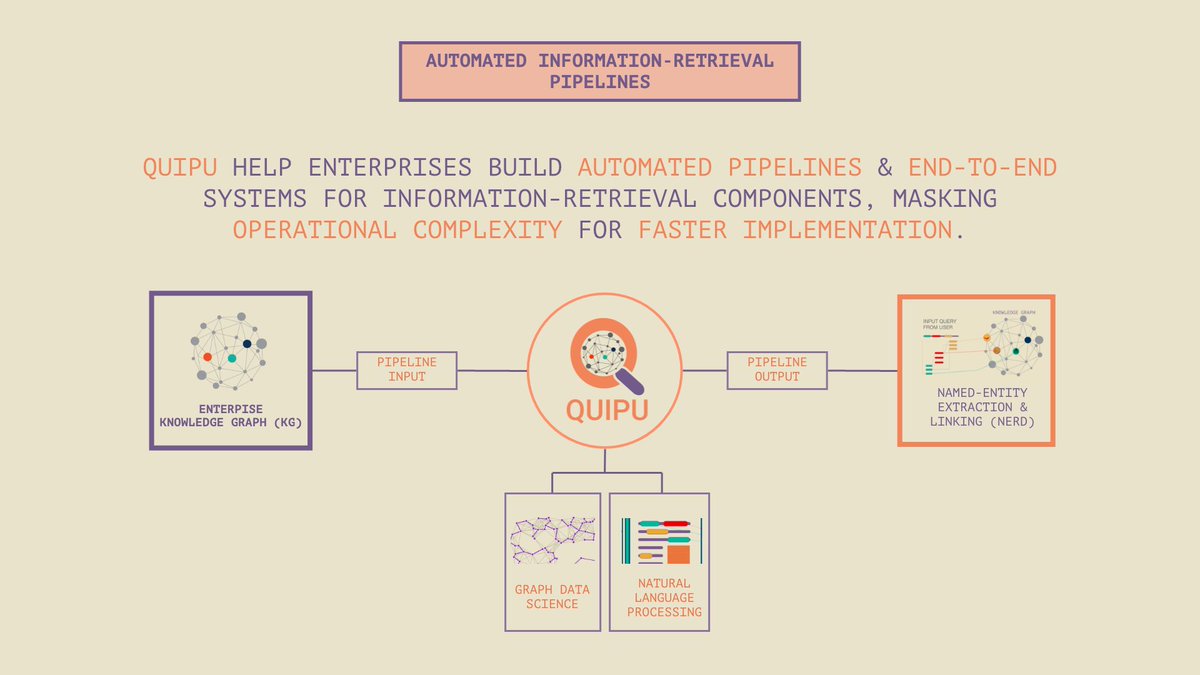
Faster migration of Enterprises into #GraphTechnologies with Automated Pipelines & Low-Code Platforms with #QUIPU.
#InformationRetrieval #NLP #ENTITYEXTRACTION #NERD #GDS #QUIPU #ENTITYLINKING
2
2
3 Sep 2021
📢Use entity extraction to access the travel history of your customers.🛫🛬
🔗Here is the link - bytesview.com/industry/airli…
Check it out😀👍
#MachineLearning #Analytics #AI #airline #Airport #entityextraction

6
3
31 Jul 2021
📢Use entity extraction to improve your airline operations and access the travel history of your customers.✈️
🔗Here is the link - bytesview.com/industry/airli…
Check it out👨✈️
#MachineLearning #Analytics #Airlines #entityextraction #customerservice

4
4
14 Jul 2021
📢Use bytesview to extract named entities such as patients, diagnosis, drugs, and more. 🧪
🔗Here is the link - bytesview.com/entity-extract…
Check it out👨🔬👩🔬
#MachineLearning #AI #Analytics #Pharmacist #Biotechnology #entityextraction

4
5
8 Jul 2021
📢Check out new work on my @Behance profile📃
🤖Entity Extraction Infographic🤖
🔗Check it out - be.net/gallery/123066773/Ent…
#MachineLearning #analytics #AI #entityextraction #NLP
7
6
25 Jun 2021
📢Extract competitive restaurant aspects from the unstructured text with @BytesView. 👨🍳
🔗Here is the link - bytesview.com/industry/resta…
Check it out😋👍
#MachineLearning #Analytics #restaurants #FoodFriday #AI #entityextraction

4
5