
23 Dec 2025
- you are
- a random CS grad with 0 clue how LLMs work
- get tired of people gatekeeping with big words and tiny GPUs
- decide to go full monk mode
- 2 years later i can explain attention mechanisms at parties and ruin them
- here’s the forbidden knowledge map
- top to bottom, how LLMs *actually* work
- start at the beginning
- text → tokens
- tokens → embeddings
- you are now a floating point number in 4D space
- vibe accordingly
- positional embeddings:
- absolute: “i am position 5”
- rotary (RoPE): “i am a sine wave”
- alibi: “i scale attention by distance like a hater”
- attention is all you need
- self-attention: “who am i allowed to pay attention to?”
- multihead: “what if i do that 8 times in parallel?”
- QKV: query, key, value
- sounds like a crypto scam
- actually the core of intelligence
- transformers:
- take your inputs
- smash them through attention layers
- normalize, activate, repeat
- dump the logits
- congratulations, you just inferred a token
- sampling tricks for the final output:
- temperature: how chaotic you want to be
- top-k: only sample from the top K options
- top-p: sample from the smallest group of tokens whose probabilities sum to p
- beam search? never ask about beam search
- kv cache = cheat code
- saves past keys & values
- lets you skip reprocessing old tokens
- turns a 90B model from “help me I’m melting” to “real-time genius”
- long context hacks:
- sliding window: move the attention like a scanner
- infini attention: attend sparsely, like a laser sniper
- memory layers: store thoughts like a diary with read access
- mixture of experts (MoE):
- not all weights matter
- route tokens to different sub-networks
- only activate ~3B params out of 80B
- “only the experts reply” energy
- grouped query attention (GQA):
- fewer keys/values than queries
- improves inference speed
- “i want to be fast without being dumb”
- normalization & activations:
- layernorm, RMSnorm
- gelu, silu, relu
- they all sound like failed Pokémon
- but they make the network stable and smooth
- training goals:
- causal LM: guess the next word
- masked LM: guess the missing word
- span prediction, fill-in-the-middle, etc
- LLMs trained on the art of guessing and got good at it
- tuning flavors:
- finetuning: new weights
- instruction tuning: “please act helpful”
- rlhf: reinforcement from vibes and clickbait prompts
- dpo: direct preference optimization — basically “do what humans upvote”
- scaling laws:
- more data, more parameters, more compute
- loss goes down predictably
- intelligence is now a budget line item
- bonus round:
- quantization:
- post-training quantization (PTQ)
- quant-aware training (QAT)
- models shrink, inference gets cheaper
- gguf, awq, gptq — all just zip files with extra spice
- training vs inference stacks:
- deepspeed, megatron, fschat — for pain
- vllm, tgi, tensorRT-LLM — for speed
- everyone has a repo
- nobody reads the docs
- synthetic data:
- generate your own training set
- model teaches itself
- feedback loop of knowledge and hallucination
- welcome to the ouroboros era
- final boss secret:
- you can learn *all of this* in ~2 years
- no PhD
- no 10x compute
- just relentless curiosity, good bookmarks, and late nights
- the elite don’t want you to know this
- but now that you do
- choose to act
- start now
- build the models
28
132
1,558
137,952
4 Dec 2025
> you are
> a random CS grad with 0 clue how LLMs work
> get tired of people gatekeeping with big words and tiny GPUs
> decide to go full monk mode
> 2 years later i can explain attention mechanisms at parties and ruin them
> here’s the forbidden knowledge map
> top to bottom, how LLMs actually work
> start at the beginning
> text → tokens
> tokens → embeddings
> you are now a floating point number in 4D space
> vibe accordingly
> positional embeddings:
> absolute: “i am position 5”
> rotary (RoPE): “i am a sine wave”
> alibi: “i scale attention by distance like a hater”
> attention is all you need
> self-attention: “who am i allowed to pay attention to?”
> multihead: “what if i do that 8 times in parallel?”
> QKV: query, key, value
> sounds like a crypto scam
> actually the core of intelligence
> transformers:
> take your inputs
> smash them through attention layers
> normalize, activate, repeat
> dump the logits
> congratulations, you just inferred a token
> sampling tricks for the final output:
> temperature: how chaotic you want to be
> top-k: only sample from the top K options
> top-p: sample from the smallest group of tokens whose probabilities sum to p
> beam search? never ask about beam search
> kv cache = cheat code
> saves past keys & values
> lets you skip reprocessing old tokens
> turns a 90B model from “help me I’m melting” to “real-time genius”
> long context hacks:
> sliding window: move the attention like a scanner
> infini attention: attend sparsely, like a laser sniper
> memory layers: store thoughts like a diary with read access
> mixture of experts (MoE):
> not all weights matter
> route tokens to different sub-networks
> only activate ~3B params out of 80B
> “only the experts reply” energy
> grouped query attention (GQA):
> fewer keys/values than queries
> improves inference speed
> “i want to be fast without being dumb”
> normalization & activations:
> layernorm, RMSnorm
> gelu, silu, relu
> they all sound like failed Pokémon
> but they make the network stable and smooth
> training goals:
> causal LM: guess the next word
> masked LM: guess the missing word
> span prediction, fill-in-the-middle, etc
> LLMs trained on the art of guessing and got good at it
> tuning flavors:
> finetuning: new weights
> instruction tuning: “please act helpful”
> rlhf: reinforcement from vibes and clickbait prompts
> dpo: direct preference optimization, basically “do what humans upvote”
> scaling laws:
> more data, more parameters, more compute
> loss goes down predictably
> intelligence is now a budget line item
> bonus round:
> quantization:
> post-training quantization (PTQ)
> quant-aware training (QAT)
> models shrink, inference gets cheaper
> gguf, awq, gptq, all just zip files with extra spice
> training vs inference stacks:
> deepspeed, megatron, fschat, for pain
> vllm, tgi, tensorRT-LLM, for speed
> everyone has a repo
> nobody reads the docs
> synthetic data:
> generate your own training set
> model teaches itself
> feedback loop of knowledge and hallucination
> welcome to the ouroboros era
> final boss secret:
> you can learn all of this in ~2 years
> no PhD
> no 10x compute
> just relentless curiosity, good bookmarks, and late nights
> the elite don’t want you to know this
> but now that you do
> choose to act
> start now
> build the models
21
88
1,035
79,822
13 Oct 2025
- you are
- a random CS grad with 0 clue how LLMs work
- get tired of people gatekeeping with big words and tiny GPUs
- decide to go full monk mode
- 2 years later i can explain attention mechanisms at parties and ruin them
- here’s the forbidden knowledge map
- top to bottom, how LLMs actually work
- start at the beginning
- text → tokens
- tokens → embeddings
- you are now a floating point number in 4D space
- vibe accordingly
- positional embeddings:
- absolute: “i am position 5”
- rotary (RoPE): “i am a sine wave”
- alibi: “i scale attention by distance like a hater”
- attention is all you need
- self-attention: “who am i allowed to pay attention to?”
- multihead: “what if i do that 8 times in parallel?”
- QKV: query, key, value
- sounds like a crypto scam
- actually the core of intelligence
- transformers:
- take your inputs
- smash them through attention layers
- normalize, activate, repeat
- dump the logits
- congratulations, you just inferred a token
- sampling tricks for the final output:
- temperature: how chaotic you want to be
- top-k: only sample from the top K options
- top-p: sample from the smallest group of tokens whose probabilities sum to p
- beam search? never ask about beam search
- kv cache = cheat code
- saves past keys & values
- lets you skip reprocessing old tokens
- turns a 90B model from “help me I’m melting” to “real-time genius”
- long context hacks:
- sliding window: move the attention like a scanner
- infini attention: attend sparsely, like a laser sniper
- memory layers: store thoughts like a diary with read access
- mixture of experts (MoE):
- not all weights matter
- route tokens to different sub-networks
- only activate ~3B params out of 80B
- “only the experts reply” energy
- grouped query attention (GQA):
- fewer keys/values than queries
- improves inference speed
- “i want to be fast without being dumb”
- normalization & activations:
- layernorm, RMSnorm
- gelu, silu, relu
- they all sound like failed Pokémon
- but they make the network stable and smooth
- training goals:
- causal LM: guess the next word
- masked LM: guess the missing word
- span prediction, fill-in-the-middle, etc
- LLMs trained on the art of guessing and got good at it
- tuning flavors:
- finetuning: new weights
- instruction tuning: “please act helpful”
- rlhf: reinforcement from vibes and clickbait prompts
- dpo: direct preference optimization, basically “do what humans upvote”
- scaling laws:
- more data, more parameters, more compute
- loss goes down predictably
- intelligence is now a budget line item
- bonus round:
- quantization:
- post-training quantization (PTQ)
- quant-aware training (QAT)
- models shrink, inference gets cheaper
- gguf, awq, gptq, all just zip files with extra spice
- training vs inference stacks:
- deepspeed, megatron, fschat, for pain
- vllm, tgi, tensorRT-LLM, for speed
- everyone has a repo
- nobody reads the docs
- synthetic data:
- generate your own training set
- model teaches itself
- feedback loop of knowledge and hallucination
- welcome to the ouroboros era
- final boss secret:
- you can learn all of this in ~2 years
- no PhD
- no 10x compute
- just relentless curiosity, good bookmarks, and late nights
- the elite don’t want you to know this
- but now that you do
- choose to act
- start now
- build the models
17
78
881
57,440
4 Oct 2025
- you are
- a random CS grad with 0 clue how LLMs work
- get tired of people gatekeeping with big words and tiny GPUs
- decide to go full monk mode
- 2 years later i can explain attention mechanisms at parties and ruin them
- here’s the forbidden knowledge map
- top to bottom, how LLMs *actually* work
- start at the beginning
- text → tokens
- tokens → embeddings
- you are now a floating point number in 4D space
- vibe accordingly
- positional embeddings:
- absolute: “i am position 5”
- rotary (RoPE): “i am a sine wave”
- alibi: “i scale attention by distance like a hater”
- attention is all you need
- self-attention: “who am i allowed to pay attention to?”
- multihead: “what if i do that 8 times in parallel?”
- QKV: query, key, value
- sounds like a crypto scam
- actually the core of intelligence
- transformers:
- take your inputs
- smash them through attention layers
- normalize, activate, repeat
- dump the logits
- congratulations, you just inferred a token
- sampling tricks for the final output:
- temperature: how chaotic you want to be
- top-k: only sample from the top K options
- top-p: sample from the smallest group of tokens whose probabilities sum to p
- beam search? never ask about beam search
- kv cache = cheat code
- saves past keys & values
- lets you skip reprocessing old tokens
- turns a 90B model from “help me I’m melting” to “real-time genius”
- long context hacks:
- sliding window: move the attention like a scanner
- infini attention: attend sparsely, like a laser sniper
- memory layers: store thoughts like a diary with read access
- mixture of experts (MoE):
- not all weights matter
- route tokens to different sub-networks
- only activate ~3B params out of 80B
- “only the experts reply” energy
- grouped query attention (GQA):
- fewer keys/values than queries
- improves inference speed
- “i want to be fast without being dumb”
- normalization & activations:
- layernorm, RMSnorm
- gelu, silu, relu
- they all sound like failed Pokémon
- but they make the network stable and smooth
- training goals:
- causal LM: guess the next word
- masked LM: guess the missing word
- span prediction, fill-in-the-middle, etc
- LLMs trained on the art of guessing and got good at it
- tuning flavors:
- finetuning: new weights
- instruction tuning: “please act helpful”
- rlhf: reinforcement from vibes and clickbait prompts
- dpo: direct preference optimization — basically “do what humans upvote”
- scaling laws:
- more data, more parameters, more compute
- loss goes down predictably
- intelligence is now a budget line item
- bonus round:
- quantization:
- post-training quantization (PTQ)
- quant-aware training (QAT)
- models shrink, inference gets cheaper
- gguf, awq, gptq — all just zip files with extra spice
- training vs inference stacks:
- deepspeed, megatron, fschat — for pain
- vllm, tgi, tensorRT-LLM — for speed
- everyone has a repo
- nobody reads the docs
- synthetic data:
- generate your own training set
- model teaches itself
- feedback loop of knowledge and hallucination
- welcome to the ouroboros era
- final boss secret:
- you can learn *all of this* in ~2 years
- no PhD
- no 10x compute
- just relentless curiosity, good bookmarks, and late nights
- the elite don’t want you to know this
- but now that you do
- choose to act
- start now
- build the models
40
234
2,840
239,828
22 Sep 2025
- you are
- a random CS grad with 0 clue how LLMs work
- get tired of people gatekeeping with big words and tiny GPUs
- decide to go full monk mode
- 2 years later i can explain attention mechanisms at parties and ruin them
- here’s the forbidden knowledge map
- top to bottom, how LLMs *actually* work
- start at the beginning
- text → tokens
- tokens → embeddings
- you are now a floating point number in 4D space
- vibe accordingly
- positional embeddings:
- absolute: “i am position 5”
- rotary (RoPE): “i am a sine wave”
- alibi: “i scale attention by distance like a hater”
- attention is all you need
- self-attention: “who am i allowed to pay attention to?”
- multihead: “what if i do that 8 times in parallel?”
- QKV: query, key, value
- sounds like a crypto scam
- actually the core of intelligence
- transformers:
- take your inputs
- smash them through attention layers
- normalize, activate, repeat
- dump the logits
- congratulations, you just inferred a token
- sampling tricks for the final output:
- temperature: how chaotic you want to be
- top-k: only sample from the top K options
- top-p: sample from the smallest group of tokens whose probabilities sum to p
- beam search? never ask about beam search
- kv cache = cheat code
- saves past keys & values
- lets you skip reprocessing old tokens
- turns a 90B model from “help me I’m melting” to “real-time genius”
- long context hacks:
- sliding window: move the attention like a scanner
- infini attention: attend sparsely, like a laser sniper
- memory layers: store thoughts like a diary with read access
- mixture of experts (MoE):
- not all weights matter
- route tokens to different sub-networks
- only activate ~3B params out of 80B
- “only the experts reply” energy
- grouped query attention (GQA):
- fewer keys/values than queries
- improves inference speed
- “i want to be fast without being dumb”
- normalization & activations:
- layernorm, RMSnorm
- gelu, silu, relu
- they all sound like failed Pokémon
- but they make the network stable and smooth
- training goals:
- causal LM: guess the next word
- masked LM: guess the missing word
- span prediction, fill-in-the-middle, etc
- LLMs trained on the art of guessing and got good at it
- tuning flavors:
- finetuning: new weights
- instruction tuning: “please act helpful”
- rlhf: reinforcement from vibes and clickbait prompts
- dpo: direct preference optimization — basically “do what humans upvote”
- scaling laws:
- more data, more parameters, more compute
- loss goes down predictably
- intelligence is now a budget line item
- bonus round:
- quantization:
- post-training quantization (PTQ)
- quant-aware training (QAT)
- models shrink, inference gets cheaper
- gguf, awq, gptq — all just zip files with extra spice
- training vs inference stacks:
- deepspeed, megatron, fschat — for pain
- vllm, tgi, tensorRT-LLM — for speed
- everyone has a repo
- nobody reads the docs
- synthetic data:
- generate your own training set
- model teaches itself
- feedback loop of knowledge and hallucination
- welcome to the ouroboros era
- final boss secret:
- you can learn *all of this* in ~2 years
- no PhD
- no 10x compute
- just relentless curiosity, good bookmarks, and late nights
- the elite don’t want you to know this
- but now that you do
- choose to act
- start now
- build the models
2
14
174
11,520
19 Sep 2025
- you are
- a random CS grad with 0 clue how LLMs work
- get tired of people gatekeeping with big words and tiny GPUs
- decide to go full monk mode
- 2 years later i can explain attention mechanisms at parties and ruin them
- here’s the forbidden knowledge map
- top to bottom, how LLMs *actually* work
- start at the beginning
- text → tokens
- tokens → embeddings
- you are now a floating point number in 4D space
- vibe accordingly
- positional embeddings:
- absolute: “i am position 5”
- rotary (RoPE): “i am a sine wave”
- alibi: “i scale attention by distance like a hater”
- attention is all you need
- self-attention: “who am i allowed to pay attention to?”
- multihead: “what if i do that 8 times in parallel?”
- QKV: query, key, value
- sounds like a crypto scam
- actually the core of intelligence
- transformers:
- take your inputs
- smash them through attention layers
- normalize, activate, repeat
- dump the logits
- congratulations, you just inferred a token
- sampling tricks for the final output:
- temperature: how chaotic you want to be
- top-k: only sample from the top K options
- top-p: sample from the smallest group of tokens whose probabilities sum to p
- beam search? never ask about beam search
- kv cache = cheat code
- saves past keys & values
- lets you skip reprocessing old tokens
- turns a 90B model from “help me I’m melting” to “real-time genius”
- long context hacks:
- sliding window: move the attention like a scanner
- infini attention: attend sparsely, like a laser sniper
- memory layers: store thoughts like a diary with read access
- mixture of experts (MoE):
- not all weights matter
- route tokens to different sub-networks
- only activate ~3B params out of 80B
- “only the experts reply” energy
- grouped query attention (GQA):
- fewer keys/values than queries
- improves inference speed
- “i want to be fast without being dumb”
- normalization & activations:
- layernorm, RMSnorm
- gelu, silu, relu
- they all sound like failed Pokémon
- but they make the network stable and smooth
- training goals:
- causal LM: guess the next word
- masked LM: guess the missing word
- span prediction, fill-in-the-middle, etc
- LLMs trained on the art of guessing and got good at it
- tuning flavors:
- finetuning: new weights
- instruction tuning: “please act helpful”
- rlhf: reinforcement from vibes and clickbait prompts
- dpo: direct preference optimization — basically “do what humans upvote”
- scaling laws:
- more data, more parameters, more compute
- loss goes down predictably
- intelligence is now a budget line item
- bonus round:
- quantization:
- post-training quantization (PTQ)
- quant-aware training (QAT)
- models shrink, inference gets cheaper
- gguf, awq, gptq — all just zip files with extra spice
- training vs inference stacks:
- deepspeed, megatron, fschat — for pain
- vllm, tgi, tensorRT-LLM — for speed
- everyone has a repo
- nobody reads the docs
- synthetic data:
- generate your own training set
- model teaches itself
- feedback loop of knowledge and hallucination
- welcome to the ouroboros era
- final boss secret:
- you can learn *all of this* in ~2 years
- no PhD
- no 10x compute
- just relentless curiosity, good bookmarks, and late nights
- the elite don’t want you to know this
- but now that you do
- choose to act
- start now
- build the models
42
270
3,178
259,423
13 Sep 2025
> be you
> random CS grad with 0 clue how LLMs work
> get tired of people gatekeeping with big words and tiny GPUs
> decide to go full monk mode
> 2 years later i can explain attention mechanisms at parties and ruin them
> here’s the forbidden knowledge map
> top to bottom, how LLMs *actually* work
> start at the beginning
> text → tokens
> tokens → embeddings
> you are now a floating point number in 4D space
> vibe accordingly
> positional embeddings:
> > absolute: “i am position 5”
> > rotary (RoPE): “i am a sine wave”
> > alibi: “i scale attention by distance like a hater”
> attention is all you need
> self-attention: “who am i allowed to pay attention to?”
> multihead: “what if i do that 8 times in parallel?”
> QKV: query, key, value
> sounds like a crypto scam
> actually the core of intelligence
> transformers:
> > take your inputs
> > smash them through attention layers
> > normalize, activate, repeat
> > dump the logits
> > congratulations, you just inferred a token
> sampling tricks for the final output:
> > temperature: how chaotic you want to be
> > top-k: only sample from the top K options
> > top-p: sample from the smallest group of tokens whose probabilities sum to p
> > beam search? never ask about beam search
> kv cache = cheat code
> > saves past keys & values
> > lets you skip reprocessing old tokens
> > turns a 90B model from “help me I’m melting” to “real-time genius”
> long context hacks:
> > sliding window: move the attention like a scanner
> > infini attention: attend sparsely, like a laser sniper
> > memory layers: store thoughts like a diary with read access
> mixture of experts (MoE):
> > not all weights matter
> > route tokens to different sub-networks
> > only activate ~3B params out of 80B
> > “only the experts reply” energy
> grouped query attention (GQA):
> > fewer keys/values than queries
> > improves inference speed
> > “i want to be fast without being dumb”
> normalization & activations:
> > layernorm, RMSnorm
> > gelu, silu, relu
> > they all sound like failed Pokémon
> > but they make the network stable and smooth
> training goals:
> > causal LM: guess the next word
> > masked LM: guess the missing word
> > span prediction, fill-in-the-middle, etc
> > LLMs trained on the art of guessing and got good at it
> tuning flavors:
> > finetuning: new weights
> > instruction tuning: “please act helpful”
> > rlhf: reinforcement from vibes and clickbait prompts
> > dpo: direct preference optimization — basically “do what humans upvote”
> scaling laws:
> > more data, more parameters, more compute
> > loss goes down predictably
> > intelligence is now a budget line item
> bonus round:
> quantization:
> > post-training quantization (PTQ)
> > quant-aware training (QAT)
> > models shrink, inference gets cheaper
> > gguf, awq, gptq — all just zip files with extra spice
> training vs inference stacks:
> > deepspeed, megatron, fschat — for pain
> > vllm, tgi, tensorRT-LLM — for speed
> > everyone has a repo
> > nobody reads the docs
> synthetic data:
> > generate your own training set
> > model teaches itself
> > feedback loop of knowledge and hallucination
> > welcome to the ouroboros era
> final boss secret:
> you can learn *all of this* in ~2 years
> no PhD
> no 10x compute
> just relentless curiosity, good bookmarks, and late nights
> the elite don’t want you to know this
> but now that you do
> choose to act
> start now
> build the models
30
165
2,124
144,877

6 Oct 2024
I needed ChatGPT a bit more programmatically accessible, so I sat down over the weekend and produced #FsChat:
FsChat is #fsharp client for interactive fiddling with GPT APIs.
Project & documentation: github.com/pkese/FsChat
1
12
571

11 Sep 2024
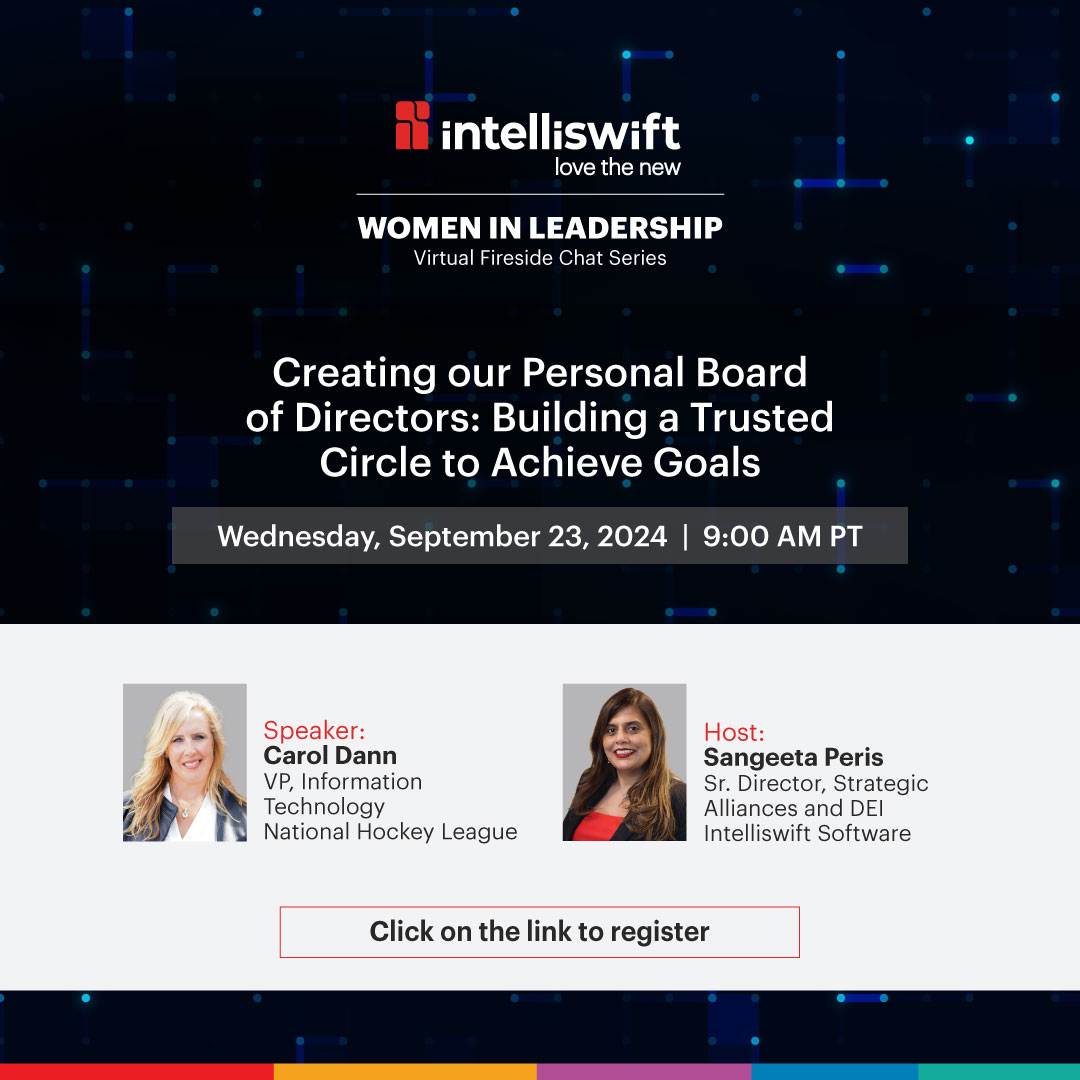
Join us for a #virtualfiresidechat hosted by Sangeeta Peris with Carol Dann, VP of IT @NHL! Carol will share about nurturing your network to stay aligned with personal and professional goals.
➡️Register Now: intelliswift.zoom.us/webinar…
#WomenLeaders #FSChat
2
73
14 May 2024
Join our virtual fireside chat with Jisun, hosted by Sangeeta, Senior Director at Intelliswift, on May 22 at 9:30 AM PT! Explore strategies for AANHPI Women Leaders to navigate cultural and gender dynamics in the executive suite. intelliswift.clickthiscard.t…
#FSChat #WomenLeaders
1
90


3️⃣ lm-sys / FastChat fschat 25K Stars 🌟 -
github.com/lm-sys/FastChat
@lmsysorg's FastChat, your one-stop solution for training, serving, and evaluating large language models like Vicuna & FastChat-T5, now comes with a distributed serving system and OpenAI-compatible APIs.
1
7
31
12,116

16 May 2023
Indeed! We need a new social contract for women health and care workers to ensure strong health systems & fair and equitable societies. A must read report of @womeninGH on the issue. womeningh.org/resources/gend… Thank you once again @JustinKoonin for a great FSchat @UHC2030

"On average 70%, in some countries even 90%, of #healthworkers are #women. Yet in most countries, less than 20% of women hold #leadership positions." @mfespinosaEC and @JustinKoonin discuss #genderequality, #womenleaders, and the importance of paid work. #HealthForAll


5
4
2,459

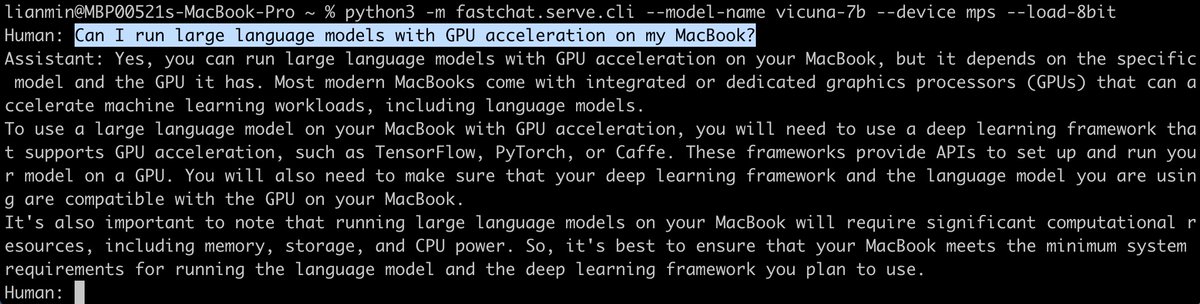
We’re releasing Vicuna-7B: small, efficient, yet capable.
💻 MacBook users can simply "pip install fschat" and run Vicuna-7B with GPU acceleration on M1 chips!
code: github.com/lm-sys/FastChat
weights: huggingface.co/lmsys/vicuna-…
23
213
1,053
189,091



Our elegant S-Class Mercedes cars make travel a breeze.
And while you’re gliding through the city, place an order for a coffee to be served piping hot when you arrive back in your room, via #FSChat.
Style never goes out of fashion, and we didn’t say it first!
#MercedesBenz


2


13 Jan 2022
Had a great FSchat with @JackieRoembke about #Meat #livestock #poultry and what to expect for @FeedStrategy Conference @IPPEexpo 2022 VIDEO: What's in store for broiler, feed producers in 2022 feedstrategy.com/poultry/vid…
1
2

17 Jun 2021
If this is what breakfast dreams are made of... we’ll take it all! ☕️
Get breakfast served right to your room with a few taps on the #FourSeasons App or #FSChat with us at bit.ly/3yugRR5
📷: @theshutterwhale

2