
May 27
New feature update: Cloud hosting is now live in oneinfer-edge.
Same app you use to run models locally. You pick a model from the catalog, select a GPU, and deploy.
Edge checks if the model fits the hardware before anything spins up, same way it does for local.
No failed deployments, no wasted GPU hours.
Your cloud deployments sit next to your local ones in the same interface. One place to track costs, monitor usage, and swap GPUs.
No CLI. No separate dashboard.
PR contributions are most welcome, love to see how you tune it
Repo details in the comment section below
#OpenSource #AI #MachineLearning #CloudHosting #LLM #MLOps #GPUInference #OneInfer #AIInfrastructure
2
1
3
287

Feb 2
AI Agents are moving into real production — not just demos.
With secure agent standards forming and GPU inference evolving for agentic AI, the next question is how these systems scale and who benefits.
XAIAGENT connects AI Agents, decentralized GPU infrastructure, and tokenized participation to power the next phase of agent ecosystems.
Read the full blog 👇
xaiagent.io/blog/secure-ai-a…
#AIAgents #AgenticAI #GPUinference #TokenizedAI #Web3AI #DecentralizedAI #XAIAGENT

3
108

16 Apr 2025
🚀 China’s first open‑source AI image generation model HiDream‑I1 (0.7B params) just dropped on Hugging Face—stunning realism & detail, subscription‑free!
For rock‑solid reliability, train & deploy YOUR own models on MetaY.ai—low‑cost, secure GPU inference with consumer & distributed GPUs. 🔧
github.com/HiDream-ai/HiDrea…
huggingface.co/HiDream-ai/Hi…
#AI #OpenSource #HiDreamI1 #HuggingFace #ImageGeneration #GenerativeAI #MetaYai #GPUInference #CloudGPU #EdgeAI #DistributedAI #DeepLearning #MachineLearning #ComputerVision #AIPlatform #DevTools #TechNews #AICommunity #Innovation #Reliability #YourModel #Tech

2
1
6
2,859
16 Apr 2025
🚀 OpenAI just released the GPT‑4.1 Prompt Engineering Guide to help you craft precise prompts & maximize model performance!
At MetaY.ai, our all‑in‑one platform offers low‑cost, secure GPU inference on consumer‑grade & distributed cloud GPUs—so you can run your own trained models reliably. 🔧💡
cookbook.openai.com/examples…
@OpenAI @ChatGPTapp
#AI #PromptEngineering #GPT4_1 #MetaYai #GPUInference #CloudGPU #MachineLearning #DeepLearning #NLP #AIPlatform #DevTools #TechNews #AICommunity #EdgeAI #DistributedAI #AIModels #ChatGPT

4
10
2,239
14 Apr 2025
🚀 Tsinghua & Shanghai AI Lab just unveiled GenPRM, a groundbreaking Generative Process Reward Model that empowers compact AIs to outthink GPT‑4 using chain‑of‑thought reasoning, code verification & test‑time scaling! 🔍 Want full transparency and rock‑solid reliability? Run your own custom GenPRM (or any model) on Metay.ai’s low‑cost, secure distributed GPUs—complete control, zero black boxes.
You can find the official repository on GitHub (MIT License: github.com/RyanLiu112/GenPRM…
The authors will also sync the model and data on their homepage:huggingface.co/papers/2504.0…
#AI #GenPRM #Tsinghua #ShanghaiAILab #ProcessRewardModel #ChainOfThought #ExplainableAI #XAI #ModelVerification #ProcessSupervision #ProcessBench #MachineLearning #DeepLearning #GPT4 #AIResearch #CustomModels #ModelTransparency #TrustworthyAI #ResponsibleAI #MetayAI #GPUInference #DistributedGPU #CloudGPU #LowCostGPU #AIInfrastructure #MLOps #AIPlatform #Innovation #TechNews #DataScience #AICommunity #NextGenAI #SelfImprovingAI #CodeVerification #DePIN #DecentralizedAI #ComputePower #FutureOfAI #AITrends

2
12
2,853

10 Jan 2024
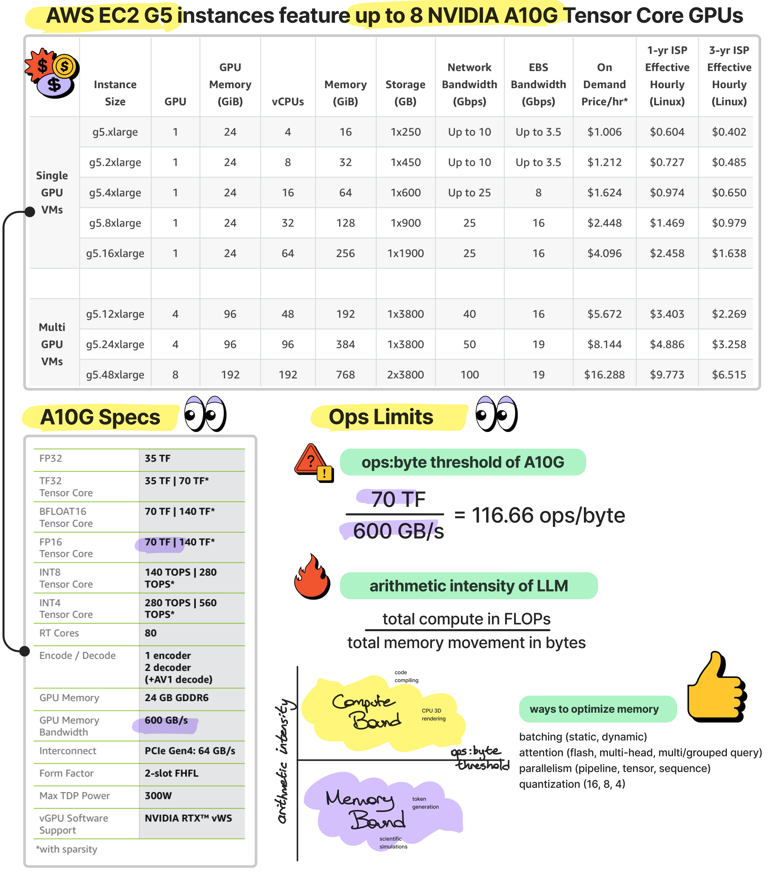
Before paying for high-end GPUs for LLM inference, understand your numbers first.
For example, you can deploy most 7B models using AWS EC2 G5 or Microsoft NVadsA10v5 instances, but would you effectively saturate GPU utilization?
To clarify this, I've created a simple visualization.
If you look at the "FP16 Tensor Core" and "GPU Memory Bandwidth" in specs, AWS EC2 G5 offers 70TF, but Microsoft NVadsA10v5 (A10) steps it up with 125TF. That's ~208 ops/bytes compared to AWS's ~116 ops/bytes.
What does this really mean?
The arithmetic intensity of a model like Llama 7B is approximately 60 ops:bytes, significantly lower than the potential computational capacity per byte of memory.
This means that the inference is memory-bound, and more importantly, you are wasting money.
You need to feed GPU more data, that's why various inference engines use continuous batching of incoming requests to increase the total throughput.
There are also many other areas of active research to optimize memory without sacrificing model performance, such as optimizing attention, quantizing the model, or leveraging pipeline or parallelism.
I will be writing a series of posts about GPU inference in the coming days; if you find such content useful, please consider sharing the post, and don't forget to follow for updates.
Wishing everyone a productive week ahead! #GPUInference #LLM #TechInsights #CloudComputing
14
70
338
37,445