
Glad to share our paper “Hard2Verify” has been accepted at #ACL2026 - Main Conference. #LLM can now solve IMO-level math, but can they reliably verify each step of a proof ? Turns out, not really. We built Hard2Verify: a step-level verification benchmark for open-ended, frontier-level math problems sourced from competitions like IMO and Putnam.
The dataset comprises 1,860 steps across 200 model responses, fully annotated by PhD-level math experts over 500 hours of human effort with three rounds of independent agreement checks. We benchmark 29 verifiers, and the takeaway is stark, models that score 60% on existing benchmarks like ProcessBench barely crack 20% on ours. If you're working on reasoning, reward models, or verification, the dataset is publicly available on HuggingFace and we think it's a useful stress test for where things actually stand.
📄 Paper: arxiv.org/pdf/2510.13744
🤗 Dataset: huggingface.co/datasets/Sale…
Grateful to work alongside an amazing team - @austinsxu @xuanphinguyen @ming5_alvin @CaimingXiong @JotyShafiq at @SFResearch

3
15
633

21 Oct 2025
🏛️⚖️🎓How can we ensure accurate and timely evaluation, even in challenging reasoning domains? We introduce Foundational Automatic Reasoning Evaluators (FARE), a new family of 8B and 20B automatic evaluators trained to judge reasoning quality, tool use, and bias across diverse domains! @SFResearch
- Training Approach
Instead of complicated reward-modeling or alignment pipelines, FARE uses a simple iterative rejection-sampling SFT.
Trained via a data-centric, multi-task mixture—2.5M evaluation-specific samples.
- Benchmark Results
Pairwise comparisons: FARE-8B ≈ 32B baselines; FARE-20B > 70B specialized evaluators.
Step-level error detection (ProcessBench): FARE-8B > 7B process RMs; FARE-20B > 72B RMs.
Also strong on reasoning (ReasoningJudgeBench), tool-use (When2Call), and reference-based verification (VerifyBench).
- Real-World Applications
Inference-time reranking (JETTS setup)
FARE-20B → near-oracle performance on MATH;
FARE-8B → best small generative reranker.
GRPO verification (GeneralReasoner setup)
Using FARE as verifiers yields 14.1% downstream policy improvement vs. symbolic/string-match checkers.
📄 Paper: arxiv.org/abs/2510.17793
🤗 Models: huggingface.co/collections/S…
1
5
16
2,165
16 Oct 2025
Hard2Verify evaluates verifiers along 3 tasks: Step-Level, Response-Level, and ErrorID. For each task, verifiers are graded based on how well they agree with step-level labels, how well they agree at the response correctness level, and how well they can identify the first error in a solution, respectively.
We find that Hard2Verify presents a significant challenge for most open-weight LLMs, which lag the closed frontier models by significant margins. PRMs that excel at ProcessBench slump to sub 50% Balanced Accuracy on Hard2Verify.

1
1
2
356
16 Oct 2025
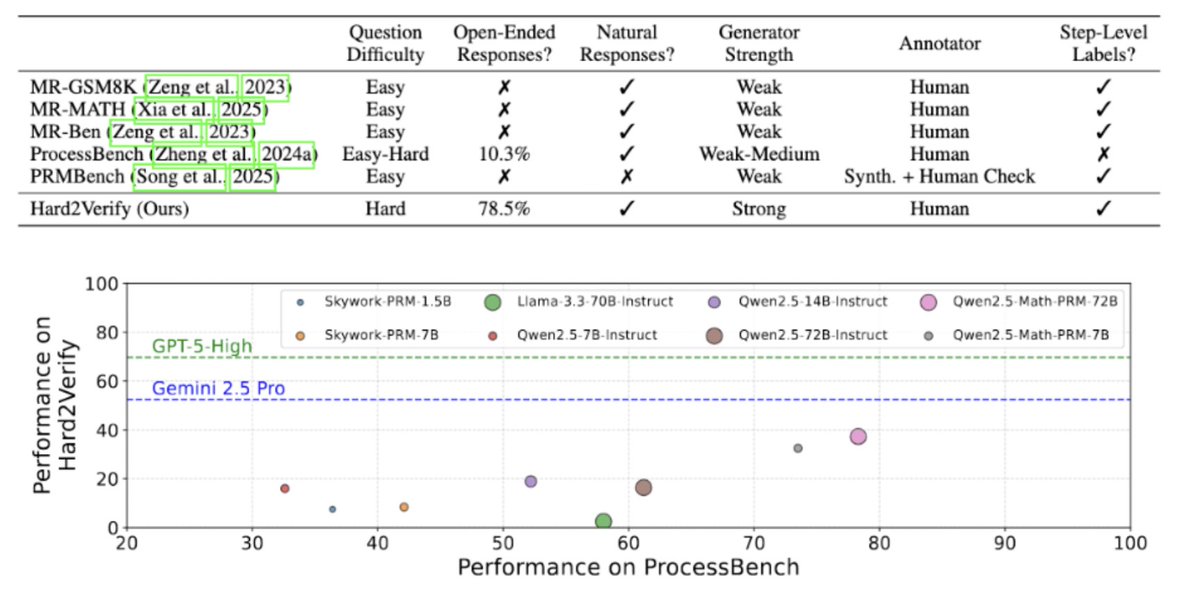
How is Hard2Verify different from recent step-level verification benchmarks, like ProcessBench or PRMBench?
🎓Open-ended, difficult, and recent math questions: Nearly 80% of the questions in Hard2Verify are open-ended, coming largely from recent (2024 and beyond) math Olympiads like IMO and Putnam!
💪Natural responses from frontier LLMs: All responses in Hard2Verify are naturally occurring outputs from GPT-5, Gemini-2.5 Pro, and Claude Sonnet 4 (Thinking), without unnaturally injected errors!
✍Human annotated steps: We partnered with @turingcom, a research accelerator that specializes in frontier data curation and annotation, to meticulously label each step!
The final result? A step-level verification benchmark with 1860 rigorously graded steps across 200 unique model responses that is the product of 500 hours of human expert effort!
1
1
2
471

6 Sep 2025
Here’s this week’s Ritual Research Digest — the latest in the world of LLMs and the intersection of Crypto × AI.
We sift through hundreds of papers so you don’t have to :
1. Deep Think with Confidence (DeepConf) :
➡️ Combines parallel thinking confidence-aware filtering
➡️ Uses local confidence measurements
➡️ Outperforms other methods across reasoning benchmarks while using fewer tokens
2. rStar2-Agent: Agentic Reasoning Technical Report :
➡️ Trains a 14B reasoning model (rStar2-Agent-14B) rivaling the 671B DeepSeek-R1
➡️ Uses GRPO-ROC to handle noisy feedback in code environments
➡️ Trained on 64× MI300X GPUs in 1 week
➡️ Hits 80.6% on AIME24 math comp generalizes to science & coding.
3. AetherCode: Coding Benchmark:
➡️ Curated from ICPC Olympiads in Informatics
➡️ Designed to rigorously test LLM coding reasoning
➡️ Hybrid test-case generation for higher quality eval
➡️ Models like O4-mini-high & Gemini-2.5-pro achieve ~35%
4. Stepwise Generative Judges (Stepwiser) :
➡️ Rewards intermediate reasoning steps via RL
➡️ Segments "chunks of thought" → assigns rewards
➡️ Evaluated on ProcessBench
➡️ RL-trained judges > supervised fine-tuned judges.
5.Memento: Fine-tuning LLM Agents without Fine-tuning LLMs
➡️ Framework for agent learning without touching LLM params
➡️ Built with:
1. Planner
2. Tool-enabled executor
3. Growing episodic memory
➡️ Scores: 87.8% GAIA, 67% DeepResearch, competitive with SOTA on HLE SimpleQA.
•That’s a wrap on this week’s Ritual Research Digest.
@ritualnet @ritualdigest @joshsimenhoff @Jez_Cryptoz @Viewsvalidator @raysonsiosol

2
26
421



1 Sep 2025
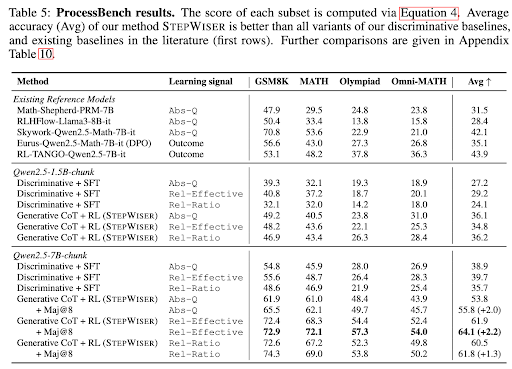
The model learns to segment thought chunks (chunks of thought) and then assign these chunks rewards. They evaluate it on ProcessBench, and their RL-trained model beats supervised fine-tuned judges.
1
1
2
120

28 Aug 2025
The paper builds a generative stepwise judge that learns to grade reasoning steps and boosts math solving.
ProcessBench average jumps to 61.9 vs 39.7 on the same 7B base.
The judge initially writes a short rationale for the step, then issues a clear verdict.
To make steps meaningful, the solver is trained to self-segment its chain of thought into coherent chunks with 1 goal.
After each chunk, the system runs rollouts from that point to estimate success, then labels the chunk by whether success rises or falls.
These labels drive reinforcement learning, so the judge learns to reason about steps and mark them Positive or Negative.
At inference, the judge rejects bad chunks and forces a rewrite from the last accepted point, lifting accuracy without longer answers.
Relative signals work best because they reward steps that actually improve success odds, not ones that only look locally good.
Taken together, reasoning about the reasoning plus RL yields a judge that catches errors early and guides training and test-time search.
----
Paper – arxiv. org/abs/2508.19229
Paper Title: "StepWiser: Stepwise Generative Judges for Wiser Reasoning"

3
12
2,734

27 Aug 2025
StepWiser is SOTA on ProcessBench, a benchmark to measure the performance of PRMs.
Our results also show the importance of:
- RL training (compared to SFT)
- A generative judge with CoT (compared to a discriminative PRM)
…with large gains from both StepWiser ingredients 🥣
🧵3/5


1
11
1,590
27 Aug 2025
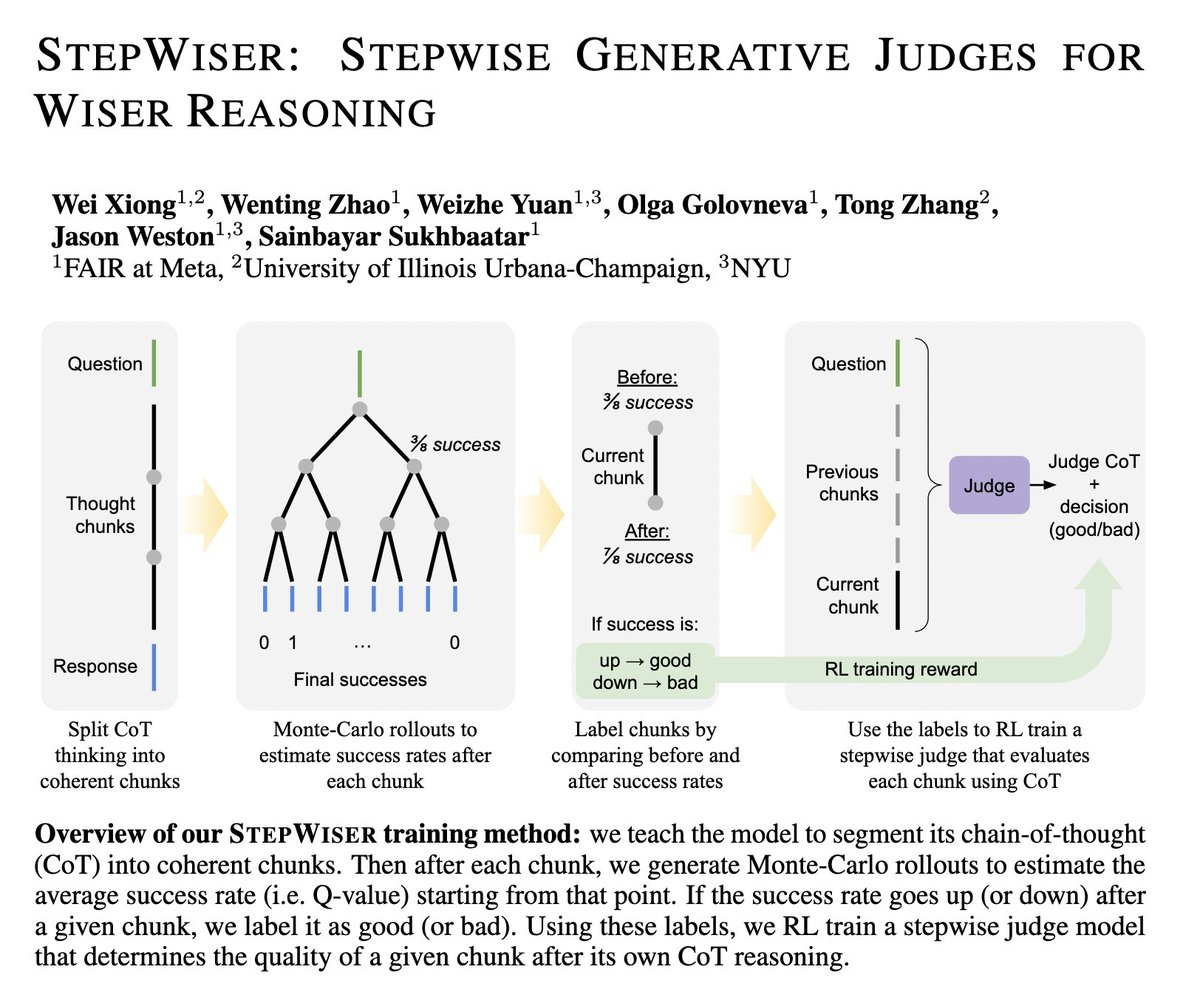
🪜Introducing: StepWiser🦉
📝: arxiv.org/abs/2508.19229
- Reframes stepwise reward modeling as a reasoning task: outputs CoT judgment.
- Trained by RL using relative outcomes of rollouts.
Results:
(1) SOTA performance on ProcessBench!
(2) Improves policy at train time.
(3) Improves inference-time search.
🧵1/5
11
92
474
89,059

30 Jul 2025
ProcessBench wins the ACL 2025 SAC Award, huge congrats to the team 🎉
@Alibaba_Qwen

10 Dec 2024

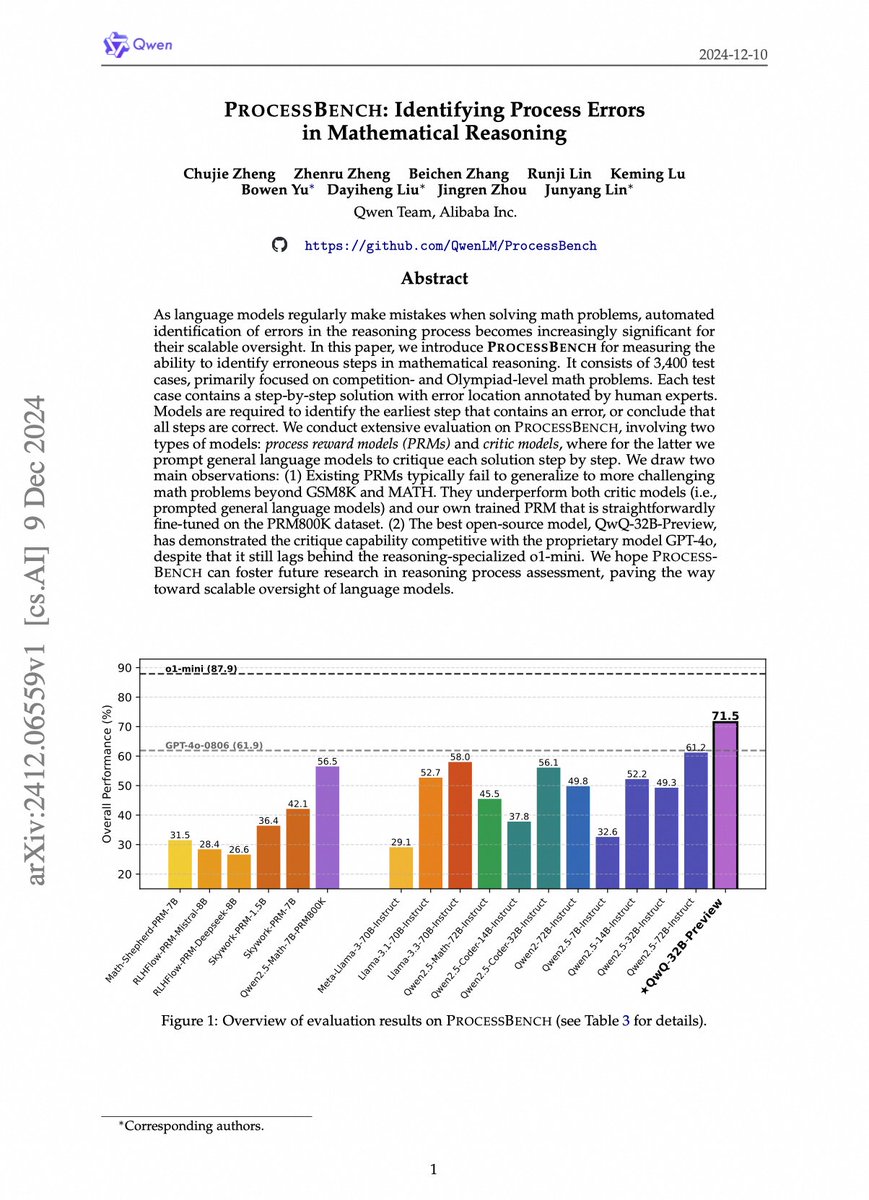
Thrilled to introduce ProcessBench, our benchmark for measuring the ability to identify process errors in mathematical reasoning
Paper: huggingface.co/papers/2412.0…
We have some really intriguing observations in this work, see below👇
3
5
52
4,194

21 Jul 2025
The Qwen team created ProcessBench for measuring the ability to identify erroneous steps in mathematical reasoning.
github.com/QwenLM/ProcessBen…

1
3
446

28 Jun 2025
I think we're never going to have a perfect solution here so what we need are really good meta-evaluations (like on the WMT metrics task). The preference collection, processbench, etc are good but not good enough
3
461
28 May 2025
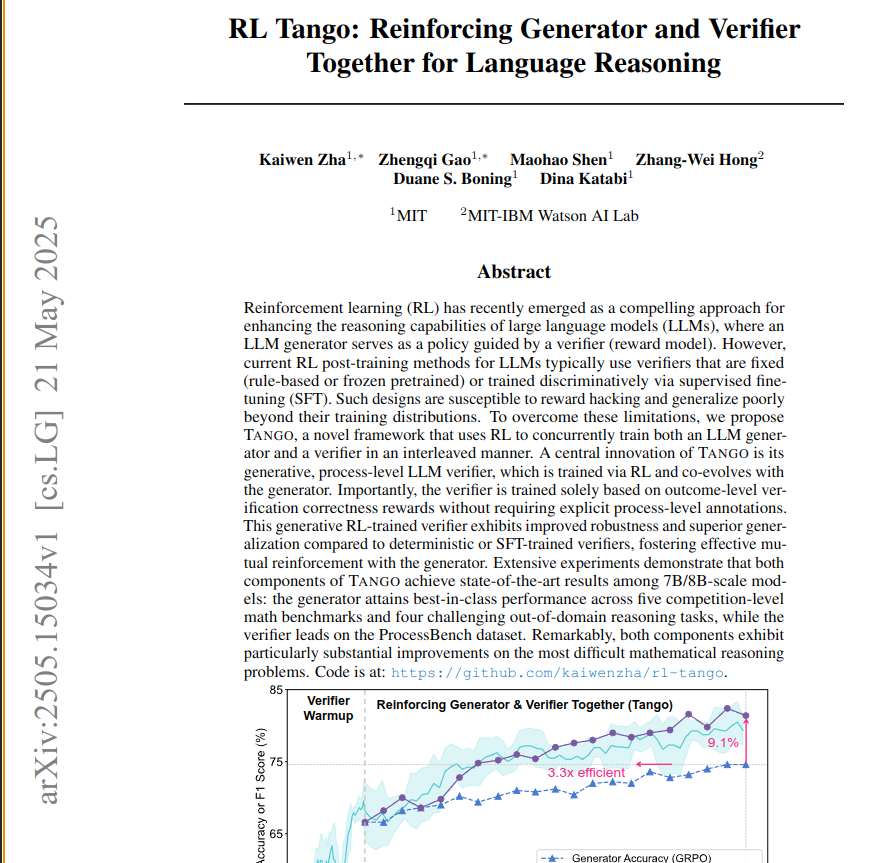
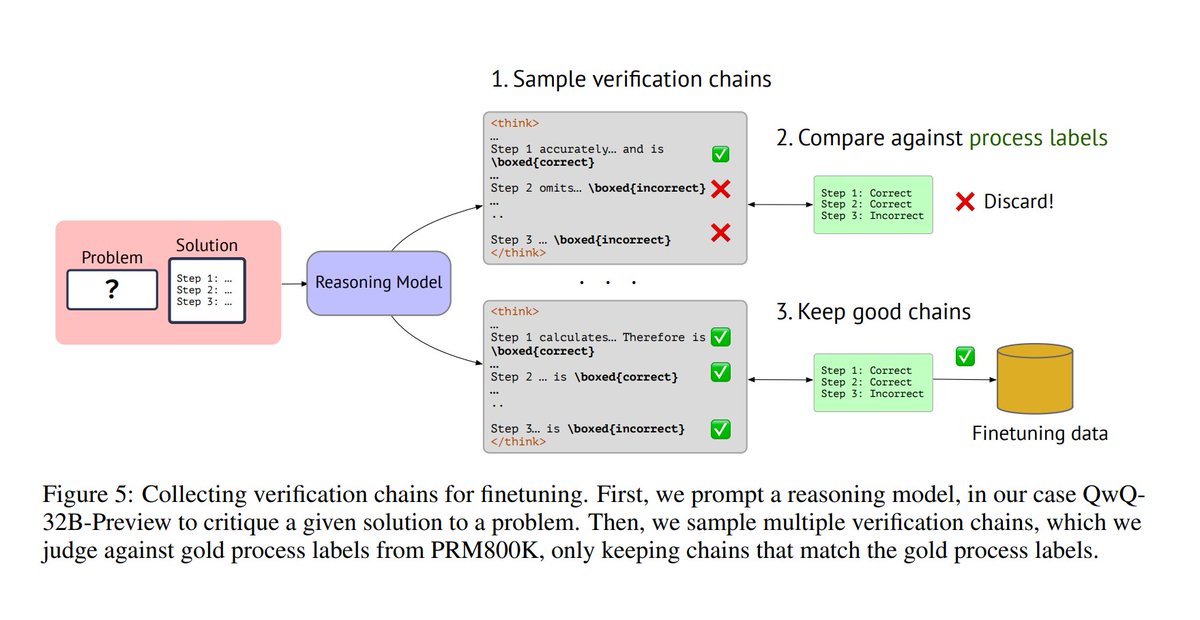
TANGO trains an LLM generator and an LLM verifier together using Reinforcement Learning, allowing them to improve each other.
This boosts performance, showing a 25.5% relative gain on math benchmarks.
Methods 🔧:
→ The generator produces multi-step reasoning solutions.
→ The verifier provides step-level natural language feedback and an overall judgment.
→ The generator uses outcome-level and verifier step-level rewards for updates.
→ The verifier trains using only outcome-level correctness rewards via Reinforcement Learning.
→ It learns accurate step verification through co-evolving training with the generator, achieving state-of-the-art on ProcessBench without process annotations.
📌 Reinforcement Learning trains the generative verifier for better generalization than supervised fine-tuning.
📌 Co-training allows the verifier to adapt to generator progress, avoiding static reward models.
📌 Training the verifier only on outcome correctness effectively bootstraps step-level accuracy.
----------------------------
Paper - arxiv. org/abs/2505.15034
Paper Title: "RL Tango: Reinforcing Generator and Verifier Together for Language Reasoning"
5
13
1,556
15 May 2025
ProcessBench
10 Dec 2024
Thrilled to introduce ProcessBench, our benchmark for measuring the ability to identify process errors in mathematical reasoning
Paper: huggingface.co/papers/2412.0…
We have some really intriguing observations in this work, see below👇
1
4
858
11 May 2025
Reliably evaluating LLM reasoning steps is hard due to costly manual annotation.
This paper introduces Self-Play Critic (SPC), where two models compete: one creates subtle errors, the other detects them, both improving error detection (accuracy from 70.8% to 77.7% on ProcessBench) without manual labels.
📌 Adversarial self-play evolves critic accuracy (70.8% to 77.7% ProcessBench) without human step-labels.
📌 SPC guides LLM search, improving MATH500 ( 2.4 percentage points) by identifying step errors.
📌 Sneaky generator's attack success (21.5% to 33.6%) fuels robust adversarial critic training.
----------
Methods Explored in this Paper 🔧:
→ SPC initializes a "sneaky generator" and a "critic" by fine-tuning two copies of a base model.
→ These models then engage in an adversarial self-play game, generating training data through their interactions.
→ Reinforcement learning uses game outcomes, rewarding winners and penalizing losers, to iteratively improve both models.
----------------------------
Paper - arxiv. org/abs/2504.19162v1
Paper Title: "SPC: Evolving Self-Play Critic via Adversarial Games for LLM Reasoning"

1
1
9
1,817

27 Apr 2025
Process Reward Models That Think
Overview:
ThinkPRM introduces a data-efficient process reward model that verifies solution steps using generated chains-of-thought, requiring only 1% of the supervision data needed for discriminative PRMs.
By leveraging the reasoning capabilities of long CoT models, it outperforms LLM-as-a-Judge and standard PRMs across benchmarks including ProcessBench and MATH-500.
ThinkPRM demonstrates strong out-of-domain generalization, improving by up to 8% over fully supervised discriminative models on tasks like GPQA-Diamond.
It also scales verification compute more effectively, outperforming LLM-as-a-Judge by 7.2% under the same token budget.
Paper:
arxiv.org/abs/2504.16828
1
1
7
1,100

Process Reward Models That Think (ThinkPRM)
Trains a step-level verifier that verbalizes its own CoT, using just 1% of PRM800K labels. Outperforms LLM-as-a-Judge and full-label PRMs.
- generative CoT verifier > discriminative judge on ProcessBench, MATH500, AIME’24
- 8% GPQA-Diamond, 4.5% LiveCodeBench (w/ zero in-domain tuning)
- 7.2% vs LLM-as-a-Judge under equal token budget
- ThinkPRM = cheaper, better, scalable test-time reward model
- verbalized process models scale verification via CoT—not label count
𝑟𝑒𝑎𝑠𝑜𝑛𝑖𝑛𝑔 𝑜𝑢𝑡 𝑙𝑜𝑢𝑑

2
17
101
7,679

14 Apr 2025
🚀 Tsinghua & Shanghai AI Lab just unveiled GenPRM, a groundbreaking Generative Process Reward Model that empowers compact AIs to outthink GPT‑4 using chain‑of‑thought reasoning, code verification & test‑time scaling! 🔍 Want full transparency and rock‑solid reliability? Run your own custom GenPRM (or any model) on Metay.ai’s low‑cost, secure distributed GPUs—complete control, zero black boxes.
You can find the official repository on GitHub (MIT License: github.com/RyanLiu112/GenPRM…
The authors will also sync the model and data on their homepage:huggingface.co/papers/2504.0…
#AI #GenPRM #Tsinghua #ShanghaiAILab #ProcessRewardModel #ChainOfThought #ExplainableAI #XAI #ModelVerification #ProcessSupervision #ProcessBench #MachineLearning #DeepLearning #GPT4 #AIResearch #CustomModels #ModelTransparency #TrustworthyAI #ResponsibleAI #MetayAI #GPUInference #DistributedGPU #CloudGPU #LowCostGPU #AIInfrastructure #MLOps #AIPlatform #Innovation #TechNews #DataScience #AICommunity #NextGenAI #SelfImprovingAI #CodeVerification #DePIN #DecentralizedAI #ComputePower #FutureOfAI #AITrends

2
12
2,853

