
🚨 Stop.
Before you spend $2,000 on an AI course, Post Graduate / Diploma, read this post completely.
Every day, I see people rushing to buy expensive AI programs because they're afraid of being left behind.
But here's what most people don't realize:
The companies building the AI revolution are already teaching it for free.
Not from influencers.
Not from marketers.
Not from people selling courses.
Directly from the organizations creating the models, chips, infrastructure and frameworks powering modern AI.
If you're serious about becoming an AI Engineer, Agent Builder, AI Product Developer, or AI Researcher, start learning from the source.
💡 10 Free AI Learning Platforms
🔹 Anthropic
https://www. anthropic. com/learn
🔹 Google AI
https://grow. google/ai
🔹 Meta AI
https://ai. meta. com/learn/
🔹 NVIDIA Deep Learning Institute
https://www. nvidia. com/en-us/training/
🔹 Microsoft Learn AI
https://learn .microsoft. com/training/ai/
🔹 OpenAI Academy
https://academy .openai.com
🔹 IBM SkillsBuild
https://skillsbuild. org
🔹 AWS Skill Builder
https://skillbuilder. aws
🔹 DeepLearning. AI
https://www.deeplearning. ai
🔹 Hugging Face Courses
https://huggingface. co/learn
---
🎥 AI YouTube Educators
🎥 Andrej Karpathy
https://www. youtube. com/@AndrejKarpathy
🎥 AI Coffee Break with Letitia
https://www. youtube .com/@AICoffeeBreak
🎥 Umar Jamil
https://www .youtube .com/@umarjamilai
🎥 Simon Oz
https://www .youtube .com/@SimonOz
🎥 3Blue1Brown
https://www. youtube. com/@3blue1brown
🎥 GPU Mode
https://www .youtube. com/@GPUMODE
🎥 AI Jason
https://www .youtube. com/@AIJasonZ
🎥 Yannic Kilcher
https://www. youtube. com/@YannicKilcher
🎥 Artem Kirsanov
https://www .youtube. com/@ArtemKirsanov
🎥 Aleksa Gordić
https://www. youtube .com/@TheAIEpiphany
🎥 Art of Saience
https://www. youtube. com/@ArtofSaience
The reality is:
You don't need a $120,000 degree.
You don't need a $2,000 AI bootcamp.
You don't need another certificate.
You need:
✅ Consistency
✅ Curiosity
✅ Hands-on projects
✅ Building real systems
The people winning in AI today aren't necessarily the ones spending the most money.
They're the ones learning, building, experimenting, failing, and repeating every single day.
AI has created the biggest learning opportunity in modern history.
And for the first time, world-class education is available to anyone with an internet connection. Share this post if you are building serious AI systems in 2026 to help others learn.
1
69

I haven't had to deal with this for a while, because my autoresearch had gotten pretty stable and could run for days to a week at a time.
Something about the GPUMODE contests is throwing it off though.
1
2
889


yes it's already writing a lot ! GPUmode contest submissions are a treat
43

May 19
Just caught @marksaroufim's keynote on "When AI starts writing systems code".
Mark's talks are always information dense and have just the right level of humor. :)
Something about Mark, he is one of the most generous people in the AI industry, volunteering his time and championing @GPU_MODE, creating community and giving back. I have a lot of respect for Mark and what he does.
Excited to see what Mark's new lab, @CoreAutoAI will build!
@PyTorch @linuxfoundation #MLSys #PyTorch #GPUMODE




2
6
583

May 12
Categorical Foundations for CuTe Layouts - Colfax Research share.google/k5BMQ05jntb9tfV… colexicographic isomorphism.
Good vid on this at GPUMode
25


The talk will cover:
How can we use AI to discover a new state of the art for a scientific problem? Prior work in test-time scaling, such as AlphaEvolve, performs search by prompting a frozen LLM.
We perform reinforcement learning at test time, so the LLM can continue to train, but now with experience specific to the test problem.
This form of continual learning is quite special, because its goal is to produce one great solution rather than many good ones on average, and to solve this very problem rather than generalize to other problems.
Therefore, our learning objective and search subroutine are designed to prioritize the most promising solutions. We call this method Test-Time Training to Discover (TTT-Discover). Following prior work, we focus on problems with continuous rewards.
We report results for every problem we attempted, across mathematics, GPU kernel engineering, algorithm design, and biology.
TTT-Discover sets the new state of the art in almost all of them:
(i) Erdős’ minimum overlap problem and an autocorrelation inequality;
(ii) a GPUMode kernel competition (up to 2× faster than prior art);
(iii) past AtCoder algorithm competitions; and
(iv) denoising problem in single-cell analysis.
Our solutions are reviewed by experts or the organizers. All our results are achieved with an open model, OpenAI gpt-oss-120b, and can be reproduced with our publicly available code, in contrast to previous best results that required closed frontier models.
Our test-time training runs are performed using Tinker, an API by Thinking Machines, with a cost of only a few hundred dollars per problem.
3
190

NVIDIA cuDNN engineers are diving deep into high-performance computing — sharing insights on peak performance with FP8 & MXFP8 attention.
📅 May 5th, 2026 | 🕛 12pm PST
🎥 Watch live on YouTube: lnkd.in/ey6YCZV3
#GPUMODE #cuDNN #AI #FP8
@cudagdb @marksaroufim @blelbach
39
10,335

Apr 29
24.39 µs.
FP4 GEMM MoE kernel optimization on AMD Instinct MI355X — @AMD X @GPU_MODE Hackathon.
Most AI discussion happens at the application layer — the real bottlenecks are at the hardware boundary.
From training models → to building systems.
#GPUMODE #Inference #AMD
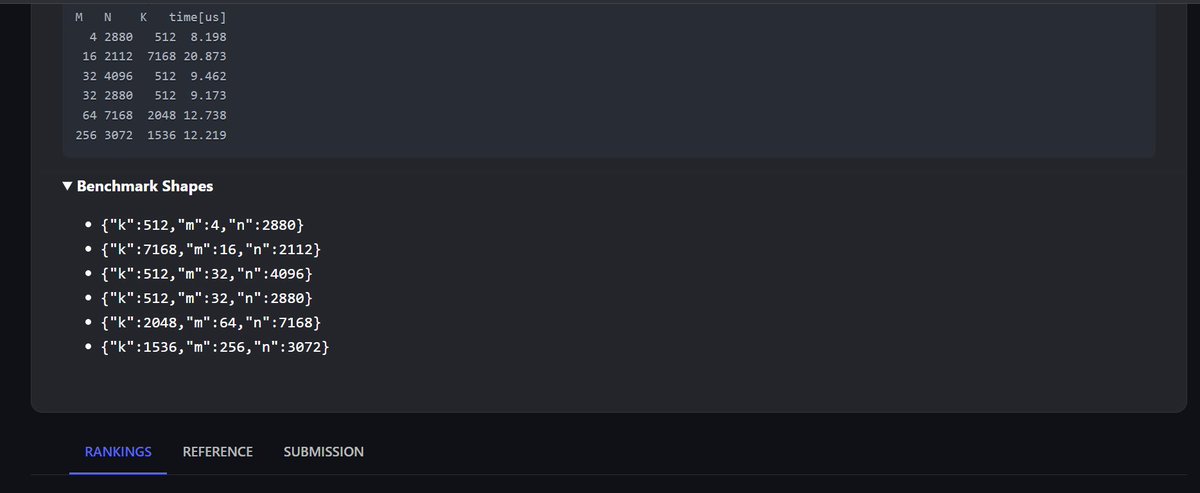
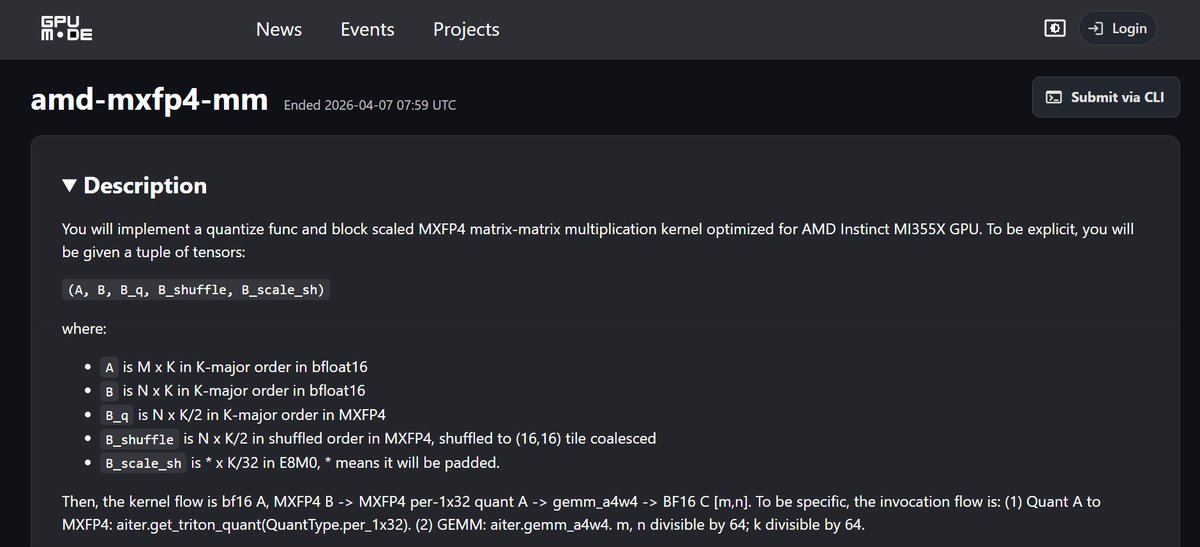
80

Apr 29
que es sonicMoE? and how do yall come up with such cool names 😮💨
was just talking to people on gpumode how we needed cooler name for moe kernels 🤣
1
52
Apr 27
this one doesn't make my eyes hurt during implementation, ...but recently, i spend 97% of my time learning from ptx/docs, gpumode, papers, pro repos🦆, etc, cuz agents would slow me down for the tier...legit takes 16 hrs of legwork to write a few lines
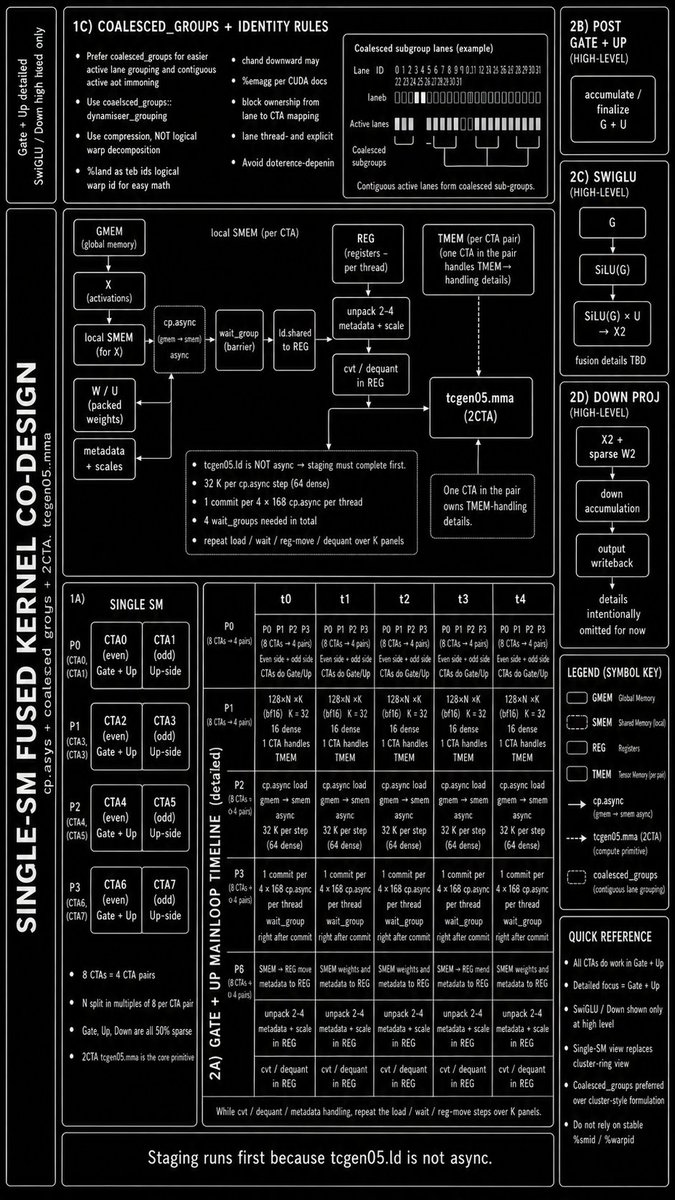

2
2
485
Apr 19
GPUMode Lecture 103: Fundamentals of CuTe Layout Algebra and Category-theoretic Interpretation youtube.com/watch?v=MVh_guNb…
42

Apr 15
Day 1 of the Sprint:
- Started with the moe videos from @IBM ,@MaartenGr and @ykilcher to get the idea behind sparsity, routing, load balancing..and then went through triton docs, kernels for vector addition, softmax. Currently going through teh notion blog for moe-amd-gpumode.
1
118

Apr 13
The #MLSys2026 program is out, and it is awesome!
📄 107 research papers 28 industry papers spanning the full AI systems stack
🏆 Three exciting contests: AWS Trainium programming, Google graph scheduling, and NVIDIA AI kernel generation
🎤 Keynotes from an outstanding lineup: Amin Vahdat (Google) on infra; @LukeZettlemoyer (UW & Meta) on models; @kozyraki (Stanford & NVIDIA) on architecture; Lidong Zhou (Microsoft) on systems; and @marksaroufim (GPUMode) on GPUs and kernels.
Join us in Bellevue, WA in a month! Early registration ends April 19 — don’t miss it: mlsys.org.

1
18
104
32,735

Apr 8
Day 95/365 of GPU Programming
Phase 1 of the AMD kernel challenge just ended, so combing through and studying the winning submissions today to get a sense of the kernel solutions and methods used at the very top.
The three problems on MI355X (gfx950/CDNA4) were: MXFP4 GEMM, mixed MLA decode and MXFP4 MoE.
Here are some notes on the winning solutions (might be wrong on any of these, so pls feel free to correct me on whatever):
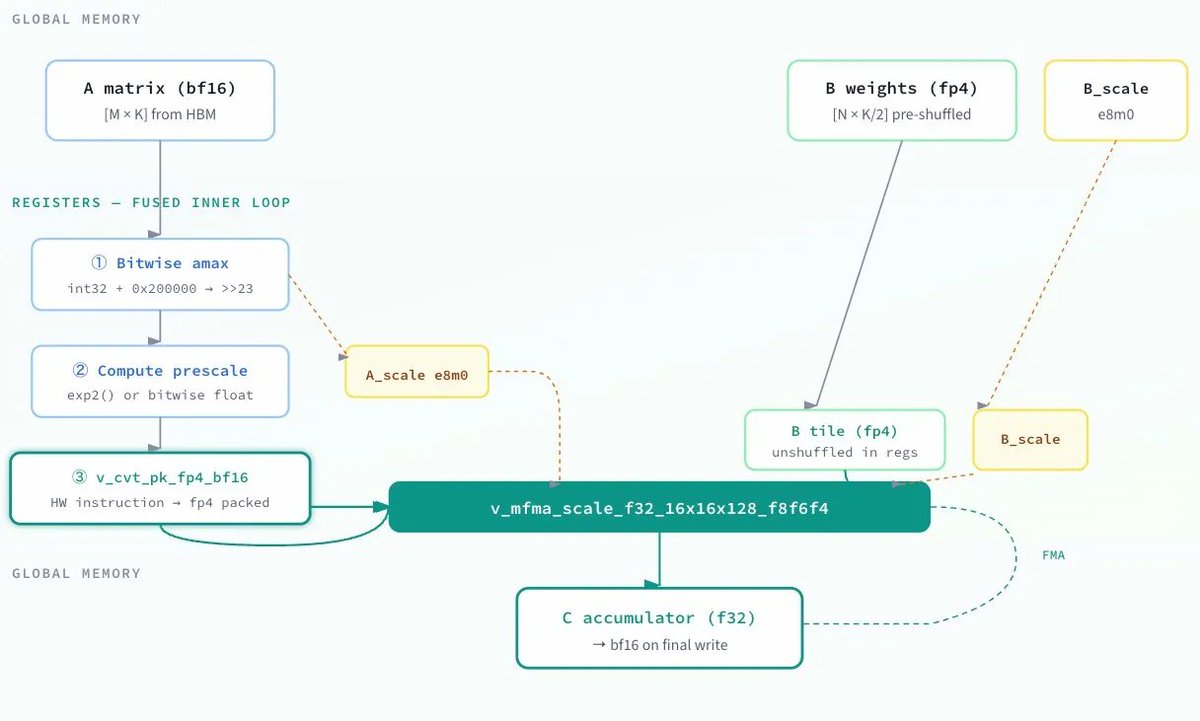
GEMM: fused quant native FP4 MFMA
The key instruction here seems to have been tl.dot_scaled(a_fp4, a_scales, "e2m1", b, b_scales, "e2m1", accumulator): this is Triton's interface to CDNA4's scaled MFMA. The top Triton submission used this/other winners wrote precompiled HIP kernels using v_mfma_scale_f32_16x16x128_f8f6f4 directly. The A matrix arrives as bf16 and is quantized to MXFP4. Winners fused this into the GEMM loop:
- Compute per 32 element amax via bitwise exponent extraction: cast to int32, add 0x200000, mask 0xFF800000, shift right 23
- Compute prescale via either exp2 or bitwise float construction (set exponent bits directly)
- Convert to fp4 via v_cvt_scalef32_pk_fp4_f32 or v_cvt_scalef32_pk_fp4_bf16 hardware instructions as Triton inline_asm_elementwise or HIP inline ASM
- The packed fp4 bytes go straight into the MFMA, hence never touching global mem
Other techniques: XCD remapping (pid redistribution across 8 compute dies?), .wt store modifier for small grids (writethrough to avoid polluting L2? not sure tbh). One submission had a HIP kernel for K=512 shapes using v_mfma_scale_f32_16x16x128_f8f6f4 with LDS double buffering and async buffer-to-LDS loads via llvm.amdgcn.raw.buffer.load.…. And the #5 submission went a bit nuts on the per shape specialization: 6 separate HIP kernels with all dimensions as compile time constants, manual buffer resource descriptors, CK type sched_group_barrier for ds_read/MFMA interleaving no Triton in the hot path. There was also a 4.35µs HSA AQL submission (not yet confirmed valid by organizers) which precompiled a HSACO binary and dispatched by writing 64 byte AQL packets directly to the ring buffer.
MLA Decode: wrapper bypass fewer kernels per call
So it looks like the winning submission at 21µs bypassed the mla_decode_fwd wrapper by relying on its percall tensor allocation, metadata computation dispatch logic. The submission preallocatedsall intermediate tensors and metadata at import time and calls the underlying primitives (mla_decode_stage1_asm_fwd and mla_reduce_v1_ directly) thus constructing the persistent mode metadata path itself. Some winning submissions also switched from fp8 Q (a8w8) to bf16 Q (a16w8) for certain shapes (eliminating the per call quantization kernel). Others used static fp8 scales where they kept fp8 Q. One effective shape level optimization seems to have been: num_kv_splits=1 for 8K sequences which lets stage1 write final output directly skipping the reduce kernel for 4/8 benchmark shapes. Per batchsize page sizes for 8K ranged from 512 (bs=64) to 2048 (bs=4, bs=256).
MoE: environment kernel tuning
The gpumode runner had an old version of AITER where the Python wrappers didn't expose FlyDSL stage1 kernel configs. The winners used shutil.copy2 to overwrite the runner's AITER Python files with newer ones from a git clone using FlyDSL for both MoE stages, and precompiled kernels during setup to avoid JIT timeouts. The speed differences also seems to have come from some kernel tuning on top of that: split K values, tile_n sizing in stage2, patching expert counts (e.g. E=257 to trigger faster FlyDSL codegen paths?) and fused sort quant via t2s mapping. Nice find by the teams that used both the environment gap and the right configs to take advantage of this.
Next steps
Only ended up finishing in the top 15 (presumably; results have still to be verified), so likely won't make it to phase 2 this time around. Fell out of the top 10 on the last day, which is unfortunate but it was a super fun process nonetheless. Mainly started this as a learning exercise and wasn't able to spend as much time on the MM/MLA challenges as I would've liked to but it really helped me study lots of new topics, so nothing but thankful for the fun opportunity to play around with these kernels and benchmark them on real hardware.
Major props and thanks to @GPU_MODE @marksaroufim @m_sirovatka @myainotez, Ben and Daniel who set up the competition and volunteered tirelessly (even on weekends) to make sure servers were up & running around the clock.
Good luck to all phase 2 participants! Super excited to read up on the winning Kimi K2.5/Deepseek R1 submissions next month.


Apr 7

Day 94/365 of GPU Programming
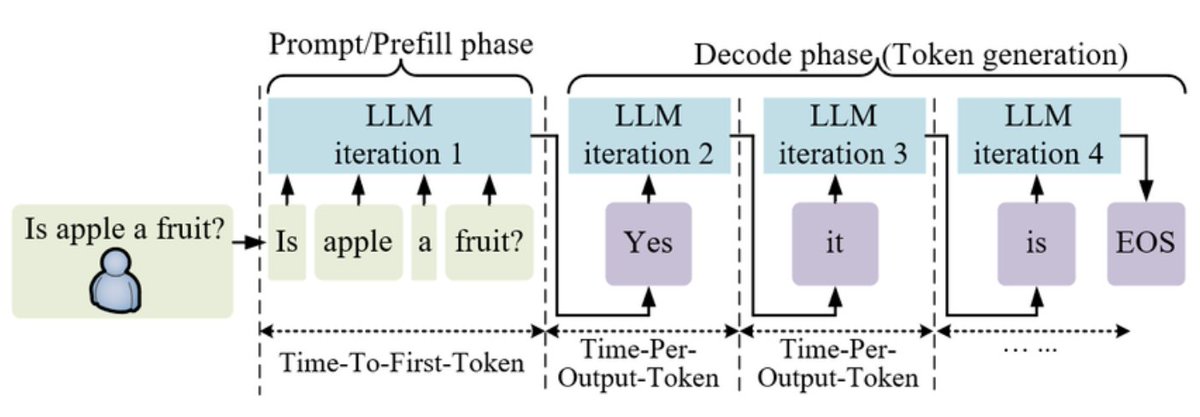
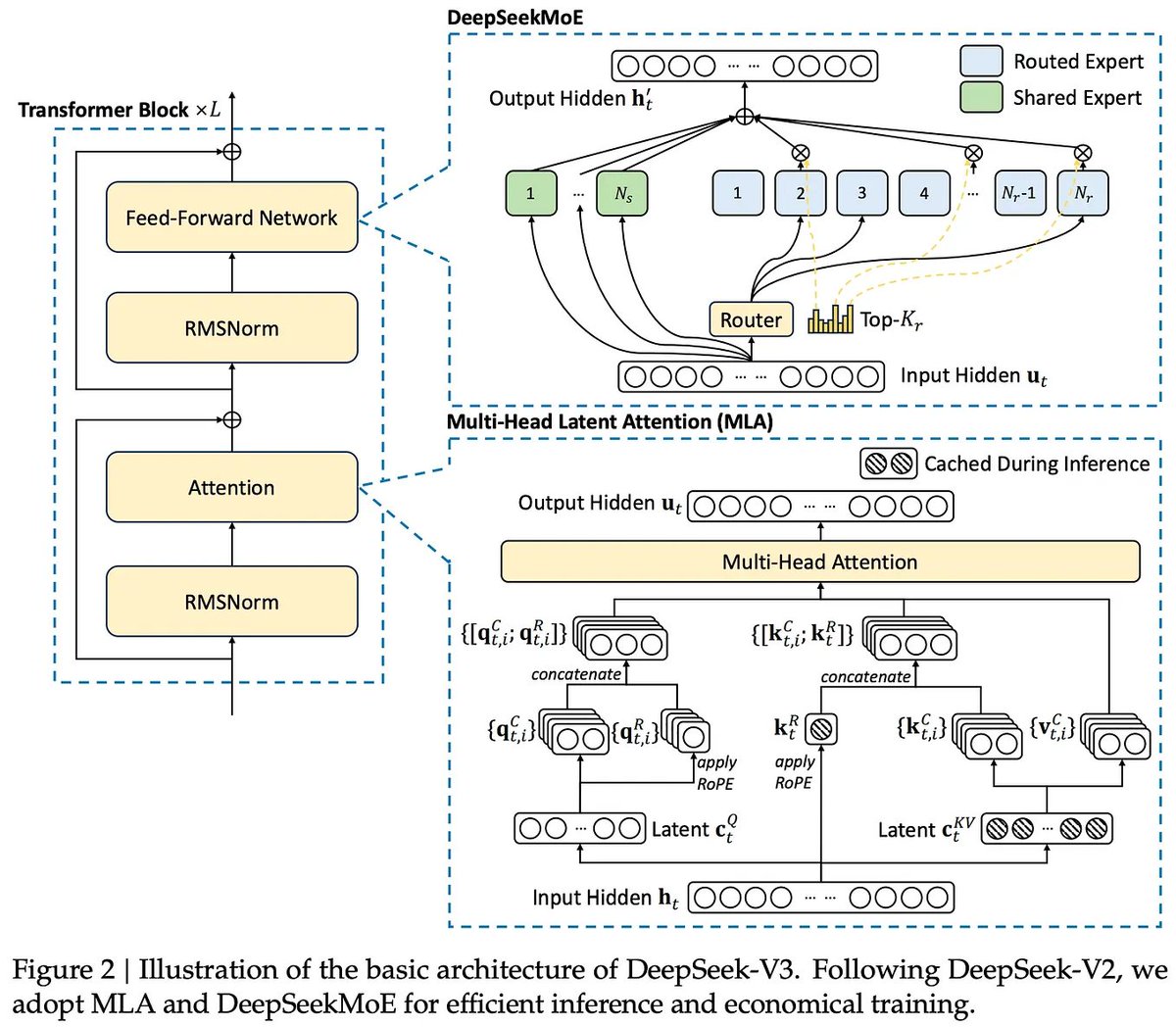
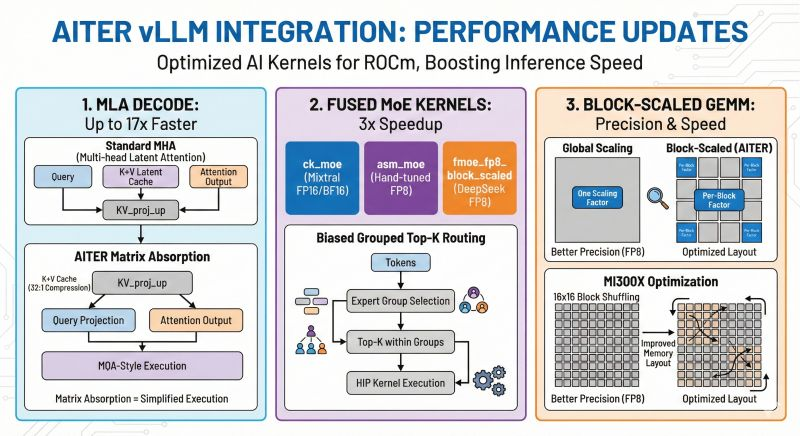
Doing a review day today. It's been a fun couple weeks digesting lots of new information, so just wanted to spend some time looking back at concepts and ideas I recently encountered: TPOT, TTFT, prefill/decode, disaggregation, MLA, KV cache, GQA, speculative decoding, MoE, routing, TP/DP/EP, AITER, ATOM, HIP, ROCm, CDNA4, MXFP4, scaling factors, tensor cores, TMA, reward hacking, kernel fusion, et cetera.
I'm only just starting to scratch the surface on these topics, so my understanding is still shallow across the board but I think I'm heading towards the right direction and getting a better of the field at large.
1
5
85
6,841