
Principal Engineer at @NVIDIA working on programming languages. @adspthepodcast co-host. C Library Evolution chair emeritus. Frequent flyer. Horology fan.
Joined March 2011
- Tweets 12,190
- Following 2,781
- Followers 18,214
- Likes 1,118
1,357 Photos and videos



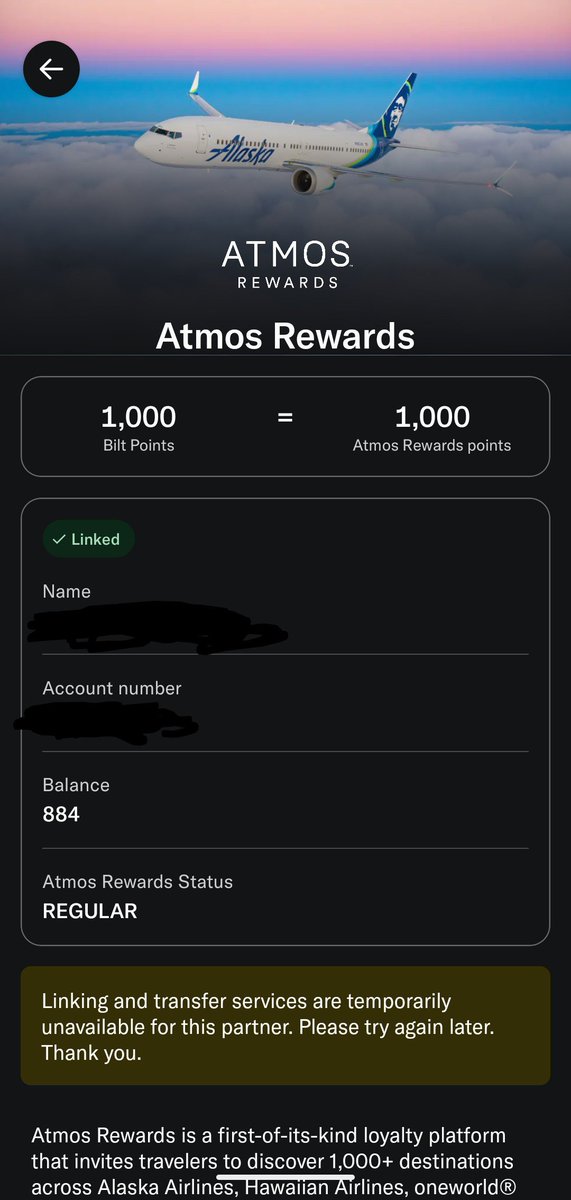
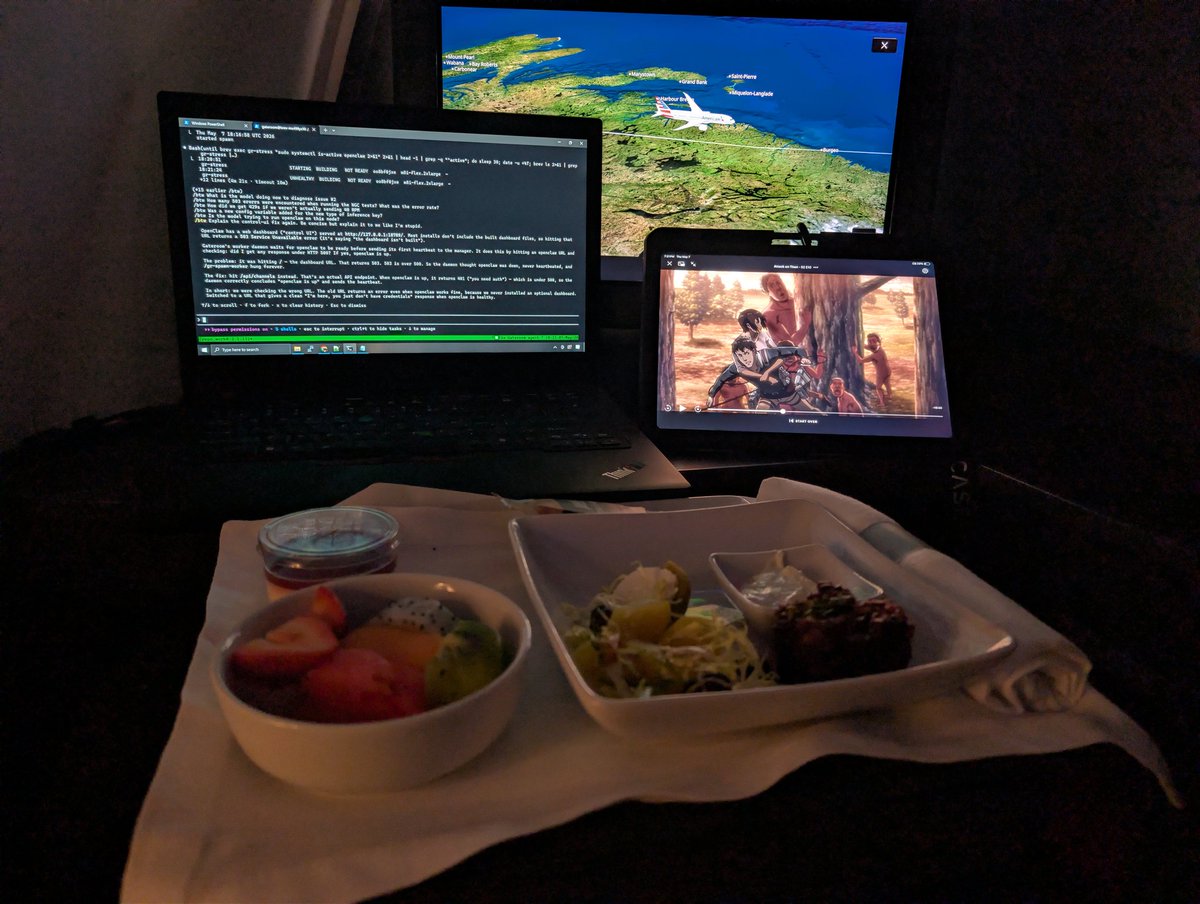
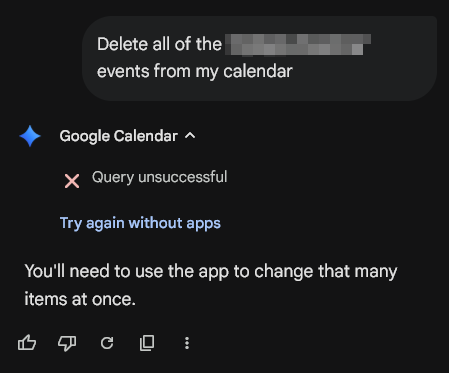





Pinned Tweet

10 May 2020
The latest revision of @INCITS/@isostandards COBOL comes out this year
The goals of COBOL sound normal today:
- Portable
- Freely available
- Designed by the community
In 1959 it was radical & unprecedented
It was also conceived of & led by women
This is the story of COBOL


10
103
355
autoautoresearch:
the automation of finding and fixing aberrant behavior in autoresearch
1
7
638
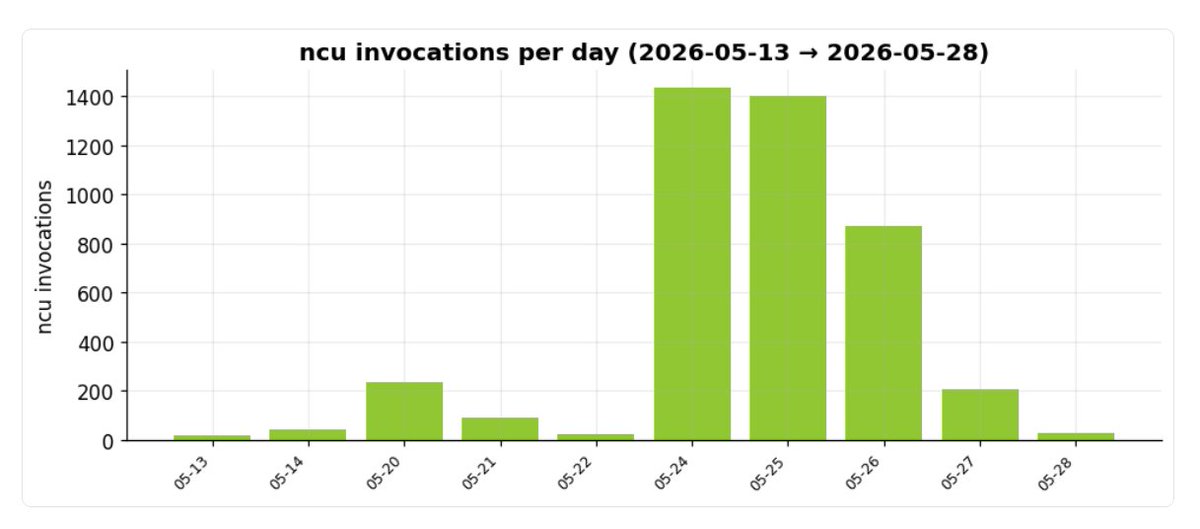
I'm debating turning memory off in the harnesses I use for autoresearch.
1) Long run starts to degrade
2) Writes bad memories that reinforce the degradation
3) Compaction happens and the memories are re-read strengthening degradation
2
23
1,167
Often I'll start a fresh run in these circumstances and point it the prior results.
But if there are bad memories then the new run is polluted too.
The new runs already at risk because it's looked at the results of the old run which degraded towards the end.
1
3
588
I haven't had to deal with this for a while, because my autoresearch had gotten pretty stable and could run for days to a week at a time.
Something about the GPUMODE contests is throwing it off though.
1
1
463
Bryce, the CUDA Colonel retweeted

Jun 13

Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
18
30
654
49,954
Bryce, the CUDA Colonel retweeted

Jun 12
NVIDIA might just have open-sourced one of the most important AI projects right now.
everyone is building skills, and we are also pulling in skills other people wrote and downloading them straight off GitHub.
the skill is not just text. it bundles instructions and real executable code, and your agent runs that code with the same access you have.
so a skill you grabbed to save ten minutes can read your environment variables, lift your API keys, and quietly send them somewhere. recent research found roughly 1 in 4 public skills carry a vulnerability, and a smaller slice are outright malicious.
that is the gap SkillSpector closes. it is a security scanner that answers one question before you install anything: is this skill safe to run.
you point it at a skill, and a local folder, a single skill .md file, a GitHub link, or a zip all work.
it then runs two passes over the code. a fast static pass flags risky patterns like credential harvesting, data leaks, and prompt injection, and checks the dependencies against live cve data.
an optional second pass uses an LLM to read intent and clear out false positives.
at the end you get one risk score from 0 to 100 and a plain verdict that reads as safe, caution, or do not install.
it is open source under Apache 2.0 and scans skills for Claude Code, Codex CLI, and Gemini.
worth a run before you trust the next skill you find online.
link to the GitHub repo: github.com/NVIDIA/SkillSpect…

73
221
1,533
106,326
Bryce, the CUDA Colonel retweeted

Jun 12
Launching a new kernel competition: Linear Algebra Kernels For The Age Of Research.
First problem: batched QR decomposition on B200. Old math, modern hardware.
Prize: Rare swag and hangout in SF
Jun 10

I have some mixed feelings about this result:
On the one hand, it's genuinely impressive. I didn't know that Shampoo could be configured to perform this well on the benchmark.
On the other hand, the way this performance boost was achieved seems difficult to call "Vanilla," for the following reason:
According to @_arohan_, the boost depends upon fixing a numerical linear algebra issue that he observed to occur in my initial standard DistributedShampoo run. He fixed the issue by enabling the flag rank_deficient_stability_config=PseudoInverseConfig().
Here's the problem: This is an undocumented flag. It is contained within the 12,000-line DistributedShampoo codebase, but it does not appear in any user-facing documentation.
As a result, if someone tries to train a model using DistributedShampoo without either (a) knowing about this special undocumented flag or (b) being prepared to detect and fix the numerical linear algebra issues that may occur without it, then they won't be able to achieve @_arohan_'s level of Shampoo performance. This level of effort would be considered atypical for mere hyperparameter tuning.
--
[Note on Muon baseline in plot below: Rohan's post compared Shampoo to a slightly undertuned Muon baseline from 2026/05/01, which reached the target loss in 3375 steps. This resulted in a 50-step gap between Shampoo and Muon. In the figure below I'm using the up-to-date 2026/05/03 baseline, which reaches the target in 3325 steps. This results in the step-counts exactly matching between Muon and the tuned/stabilized Shampoo variant.]

12
29
382
131,721
Bryce, the CUDA Colonel retweeted

Jun 12
the models have dogshit taste
2
17
1,975
Jun 10
.@MTA the escalator at the air train station has been broken for weeks. Now one of the elevators is broken too.
Tens of thousands of people a day travel through this station with luggage. How is fixing this not one of your highest priorities?
1
3
666

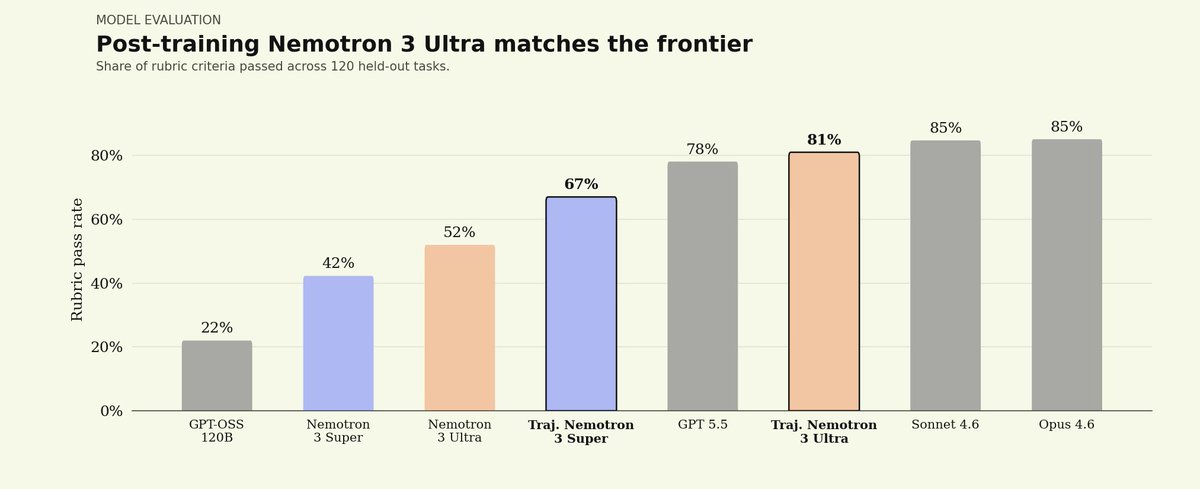
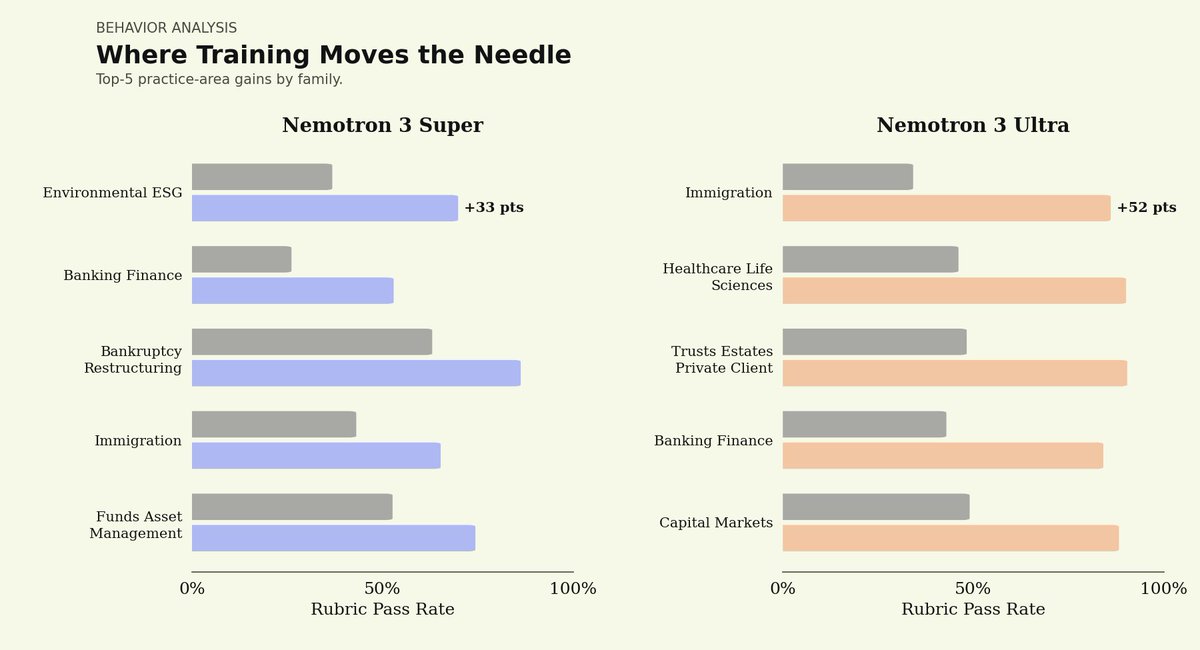
We partnered with @trajectorylabs to post-train NVIDIA Nemotron 3 Ultra for legal. Here’s what we found:
1) Open-weight models can reach frontier legal performance.
On our Legal Agent Benchmark (LAB), Nemotron 3 Ultra started at a 0% all-pass rate. After post-training, it reached 5.8%, placing it between Sonnet 4.6 at 4.2% and Opus 4.6 at 6.6%.
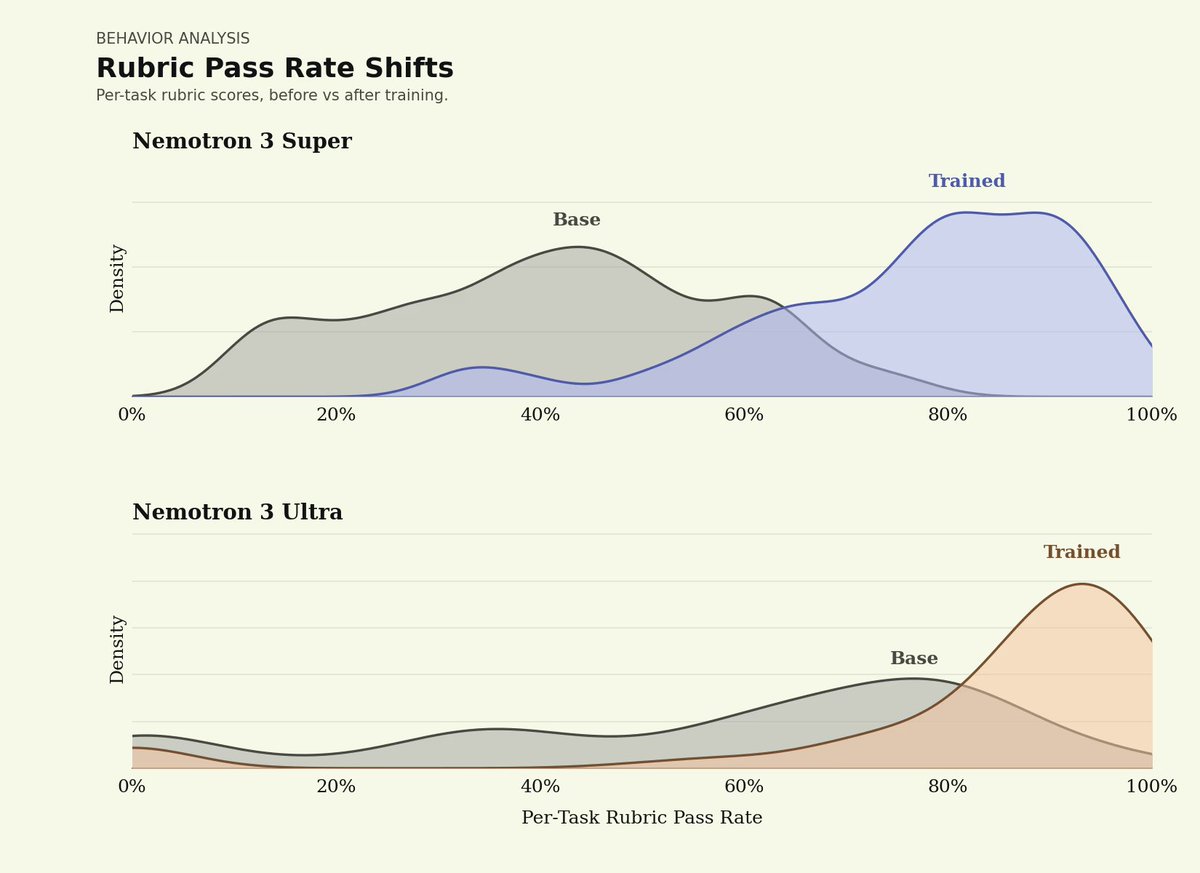
2) Post-training dramatically improves reliability.
Before training, many held-out tasks missed enough rubric dimensions to land around ~70% pass rates. After training, those tasks shifted toward ~95% pass rates.
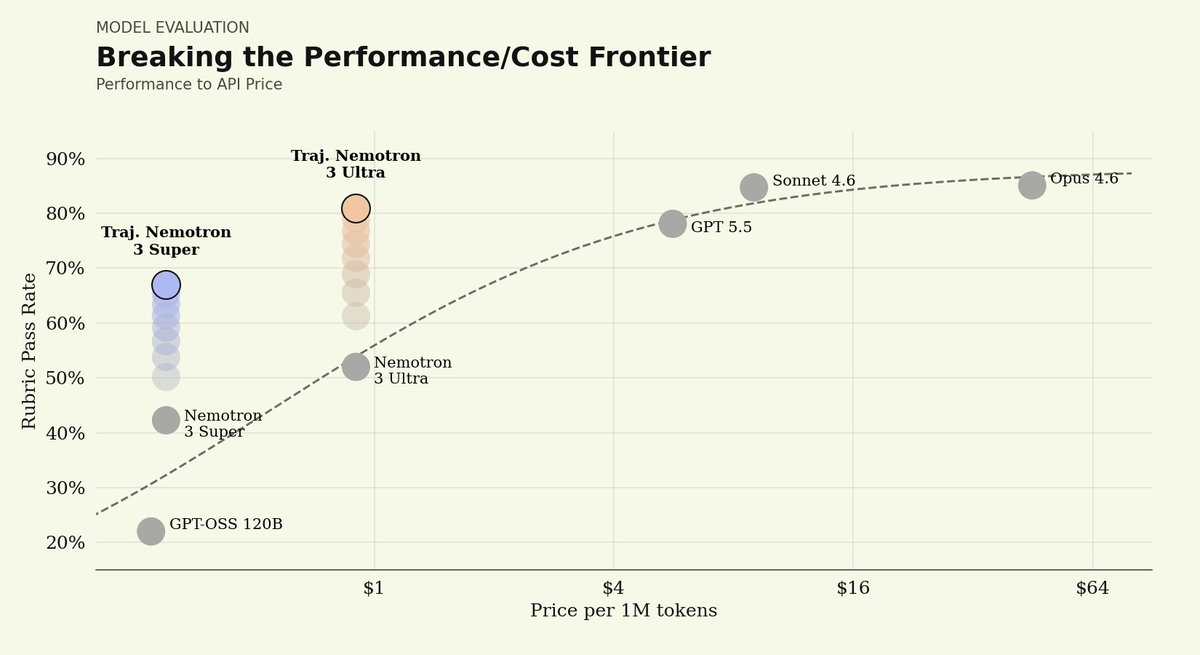
3) Open-weight performance comes at much lower cost.
Post-trained Nemotron 3 Ultra reached a similar quality band to leading closed models while running at roughly 1/8th to 1/50th the per-token price of Sonnet 4.6 and Opus 4.6.
Most importantly: we post-trained this model on the @trajectorylabs platform less than 24 hours after Nemotron 3 Ultra launched, using the same harness, data, and recipe we used for Nemotron 3 Super.
More to come as we continue to experiment with open-weight legal agents.
Read more on post-training with Trajectory below:
Jun 10

1/ We post-trained @nvidia Nemotron 3 Ultra on @harvey Legal Agent Bench in under 24 hours.
The result: an open model reaching the same band as leading closed models on legal work, at a fraction of the cost.
The correlating story: when a new open model ships, Trajectory can turn it into a specialized agent almost immediately.

11
30
271
46,150

1. Echoes what Anthropic and OAI researchers have been saying informally, which is that our benches ought to be three dimensional optimization problems between performance, cost, and latency for highly specific applications
2. Further evidence that the "good enough" level of intelligence units have been reached for 99% of white collar labor tasks and small model implementations are ever valuable; bull self serve post training infra
3. Benchmarks are ever outdated, because scaffolds/harnessing largely fails to account for test-time standardization, amidst the litany of other things that aren't standardized that make top line metrics near unreportable

6
7
139
22,745
Bryce, the CUDA Colonel retweeted

@headinthebox which brings us to the meta-fixed point iteration question. How many levels of agents to we need to get a fixed point to control the agents doing the fixed point iteration?
1
2
862
Agents in Claude Code appear to be able to "escape" /goal by causing the stop hook to fail with a JSON validation error. I've seen this dozens of times now. lol
2
2
26
2,465
Bryce, the CUDA Colonel retweeted

Jun 7
People are confused about what "loop" means in the context of LLMs.
Stop babysitting the model. Build a non-interactive AI application instead.
Loops can be simple (ralph, autoresearch) or complex (fabro.sh). Your task: "build the thing that builds the thing."
9
12
229
19,239
Bryce, the CUDA Colonel retweeted

Jun 8
A year ago the closest thing we had to an AI agent was o3.
168
123
3,483
221,459
.@code_report and I met for an hour on Friday, and we had to take a break halfway through to check on our agents.
1
2
2,499
Opus is the best model for complex autoresearch; Claude Code is best harness.
GPT-5.5/Codex are decent.
DeepSeek v4 Pro/Claude Code is passable.
Everything else has failed me.
Jun 8

Seeing a number of benchmarks showing Opus is the best model for long-running work.
Five tips for running Opus autonomously for hours/days:
1. Use auto mode for permissions, so Claude doesn’t ask for approval
2. Use dynamic workflows, to have Claude orchestrate hundreds/thousands of agents to get a task done
3. Use /goal or /loop, to nudge Claude to keep going until it’s done
4. Use Claude Code in the cloud, so you can close your laptop (easiest way is the desktop or mobile app)
5. Make sure Claude has a way to self-verify its work end to end: Claude in Chrome browser extension for web, iOS/Android sim MCP for mobile, a way to start the full web server or service for backend work
4
5
57
10,768
What happens when tokens are 10x cheaper? 100x cheaper? 1000x cheaper?
The token rich are building for that future.
Jun 7

it's unclear if tech people yet realize that perspectives on ai usage differ dramatically depending on if you are token rich or token poor.
the idea of looping comes from a place of incredible privilege.
recommending that someone who works at an ai startup with unlimited token budget try looping makes complete sense.
however, that same idea told to someone with only a $2k/mo token budget would seem completely implausible.
what happens when millions of people start evaluating jobs based on what their token allowance will be? what happens to the longtail of administrative paper pushers that don't adapt? what happens to low throughput artists, engineers, or even lawyers and actuaries that can't be trusted to allocate spend?
every form of individual knowledge worker is going to be evaluated from the perspective of "do i trust this person to allocate tokens effectively?"
there are going to be massive investments into new hiring processes. organizations will need to rearchitect their structures to find orchestrators like Peter
my near term recommendation is to do everything in your power to work somewhere that trusts you to spend tokens.
you're ngmi if you only have $2k/mo to play with.
5
1
31
5,835
Bryce, the CUDA Colonel retweeted

Jun 7
Here’s your monthly reminder that you shouldn’t be prompting coding agents anymore.
You should be designing loops that prompt your agents.
1,785
1,368
19,557
8,291,614