
i am going to publish an english version too :-) IT-Spektrum, sigs.de/artikel/der-macintos… #LLMs #AgenticAI #DataPipelines #GQL #KnowledgeGraphs #Ontologies #GraphDBs #Reasoning #Microservices #DDD #NeuroSymbolic #Cypher #SPARQL
2
6

Could be also an efficient merge with deep semantic search deterministic tool calls using graphdbs, like good old WAIS.
25

Jun 12
I have an observer agent that continuously records what happened in a session and what got established, plus a dreamer agent that distills those observations into reusable findings.
like you discovered, the unresolved problem is still search within limited context windows.
prompt prehooks, graphdbs, Q&As.mds, etc. all work fine at personal scale. I’m convinced they’re not the real solution, none of them scale with the shape of the problem
with that said, semantic search with prompt prehooks works pretty good
119

Mar 25
ArcadeDB v26.3.2 introduces Graph Analytical Views — a CSR-based OLAP engine that coexists with our transactional engine.
We run the official LDBC benchmark against 8 GraphDBs and OLAP DBMS (DuckDB)
arcadedb.com/blog/graph-olap…

2
2
113

Mar 20
SQL fails at 3 hops. GraphDBs don't.
Imagine finding all accounts within 3 hops of a suspicious transaction. Or linking fragmented customer records across systems by shared emails and phone numbers.
These are graph traversal queries. SQL can handle relationships but not depth.
Sure, you can write recursive CTEs and self-joins. That works at 1-2 hops. But go deeper and two things happen:
- The query becomes unreadable
- And the performance tanks
Each hop adds another self-join. By hop 5-6, you're looking at queries that run for minutes and fall apart under load.
The same query in Cypher:
𝗠𝗔𝗧𝗖𝗛 (𝘁:𝗧𝗿𝗮𝗻𝘀𝗮𝗰𝘁𝗶𝗼𝗻 {𝗶𝗱: '𝗧𝗫𝗡-𝟬𝟬𝟭'})-[:𝗜𝗡𝗩𝗢𝗟𝗩𝗘𝗦*𝟭..𝟯]-(𝗮:𝗔𝗰𝗰𝗼𝘂𝗻𝘁)
𝗥𝗘𝗧𝗨𝗥𝗡 𝗗𝗜𝗦𝗧𝗜𝗡𝗖𝗧 𝗮.𝗻𝗮𝗺𝗲, 𝗮.𝗽𝗵𝗼𝗻𝗲
3 lines. Reads like the question you're asking. Scales to any depth.
This is what graph databases are built for.
FalkorDB is one worth knowing about. It's open-source. And it takes a different architectural approach compared to most graph DBs.
Most graph databases chase pointers from node to node during traversal. FalkorDB doesn't do that. It's built on GraphBLAS, a linear algebra framework that represents graph operations as sparse matrix computations. Each hop becomes an optimized matrix operation instead.
The result:
- Better cache behavior
- Parallel computation across hops
- Sub-millisecond latency on deep multi-hop queries
It also uses openCypher. So if you've written Cypher before (say, with Neo4j), the syntax is identical. No new query language to pick up.
Graphic below nicely illustrates how FalkorDB is superior to traditional relational DBs.
I have shared link to their GitHub repo in the next tweet.
3
10
59
6,660

Mar 12
Nothing is random “graphDBs are all you need” fresh rage bait on the timeline today
2
298

Jan 16
Your support keeps us shipping faster. Let’s keep pushing the boundaries of what’s possible with GraphDBs.
Star the repo here: github.com/FalkorDB/FalkorDB
1
3
126

25 Dec 2025
VectorDB vs GraphDB: Which one should you use for your next GenAI project.
Vector databases are powerful but they’re often misunderstood and overused.
Third-party vector DBs are priced much like cloud hardware: convenient, but expensive at scale. If cloud infra itself can be ~10× more costly than running your own metal, opaque vector DB pricing and lock-in deserve scrutiny especially when they sit on the critical path of your product.
Embeddings also aren’t a silver bullet.
For most tabular or operational data, embeddings alone rarely unlock strong relevance. Without structure, labeling, or domain context, semantic search becomes fuzzy matching with confidence. It “works” until it quietly doesn’t and those failure modes are subtle, hard to debug, and costly.
Many teams treat vector stores like logs:
dump data → embed → retrieve → hope.
That approach is brittle by design.
Some vendors argue that complex proprietary indexes solve these issues. Maybe. But opacity pricing limited control over failure modes make them risky for core systems. If you can’t reason about how retrieval fails, you can’t trust it.
A more robust mental model is structure first, semantics second. Instead of rows and embeddings, model your domain as a digital twin:
entities
- relationships
- processes
- rules
- interfaces
This is where graph databases excel.
Graphs add contextual “texture” that embeddings alone cannot capture. They align naturally with: domain-driven design.
You can embed: nodes and relationships
LLM-generated descriptions of domain concepts
Now semantic search is explainable, navigable, and debuggable.
At this stage, you’re no longer “searching data.” but you’re querying causal structures:
- who did what
- through which process
TL;DR
- VectorDBs alone don’t scale well conceptually
- GraphDBs model reality more faithfully
- Embeddings work best when layered on top of structure
- Semantic search isn’t the goal, understanding is.

5
186

28 Nov 2025
Graphs everywhere. Relational DBs? Dying on complexity. Tools or revolution? GraphDBs as AI backbone via cCortex: c-cortex.com #GraphDB #AI #DeepTech 🚀
1
2
25

4 Nov 2025
Who are the smartest people on GraphRAG in my network? Who is doing really interesting work with graphDBs?
4
914

29 Sep 2025
Big Memory wants you to use GraphDBs.
Who is Big Memory you ask? You’ll see
28 Sep 2025

I'm excited to announce this new lesson with @jobergum : "You Don't Need a Graph DB" 🌶️
There is a time honored tradition of "killing" AI concepts.
- "RAG is dead"
- "Evals are dead"
We humbly submit our argument for "GraphDBs are dead".
Yes, we decided to choose violence . Sign up here: maven.com/p/933026/you-don-t…

3
4
692
28 Sep 2025
I'm excited to announce this new lesson with @jobergum : "You Don't Need a Graph DB" 🌶️
There is a time honored tradition of "killing" AI concepts.
- "RAG is dead"
- "Evals are dead"
We humbly submit our argument for "GraphDBs are dead".
Yes, we decided to choose violence . Sign up here: maven.com/p/933026/you-don-t…
5
8
63
8,847

17 Aug 2025
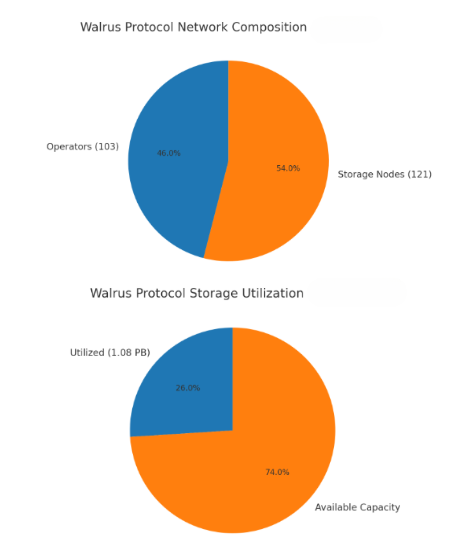
Growth of @WalrusProtocol
- Total Capacity: 4,167 TB
- Utilization: 26 % - 1.08 PB stored
- Network: 103 operators, 121 storage nodes
Projects are starting to utilize Walrus a lot more for decentralized storage and content delivery.
WalGraph - decentralized GraphDBs on Sui
Decrypt - archiving news articles, videos, and photos
OneFootball - storing sports media & fan content
EthSign - decentralized agreements & document storage
SuiNS (Sui Name Service) - storing metadata and name records reliably
Social dApps (like ComingChat) - decentralized chat & media sharing
NFT platforms (e.g., BlueMove, TradePort) - asset metadata and media files
2
4
80

13 Aug 2025
My experiments in improving the interface between GraphDBs and Graph Algorithm packages came to an end today. I'll chalk it up as a partial success.
2
2
107

30 Jul 2025
🧠 Cooking up a capstone project with GraphDB LangChain 🧩⚡
RAG meets relationships — think knowledge graphs that think.
Let’s turn context into connections.
GraphDBs don’t just store data — they map relationships, making them perfect for reasoning. #AI #LangChain #GraphDB

1
3
51

24 Jul 2025
#SQL databases with graph support: Game-changer or just another player? Delve into the debate and see where they stack up against dedicated GraphDBs! #NebulaGraph #GraphDB 🧩🤔 nebula-graph.io/posts/Graph_…
68
9
2
301

吴恩达老师分享:《GenAI应用工程师:新一代开发者的关键技能与面试技巧》
得益于生成式AI(GenAI)的迅猛发展,软件开发领域诞生了一类全新的岗位——GenAI应用工程师。他们能以前所未有的速度构建强大的软件应用,正日益受到企业的高度青睐。然而,这一岗位的具体职责仍在不断清晰化。下面我将阐述这种角色所需的关键技能,以及我在面试中用来识别优秀人才的方法。
** GenAI应用工程师的关键技能
要成为优秀的GenAI应用工程师,候选人通常需要具备两大核心能力:
1. 善于灵活运用AI“积木”快速搭建应用;
2. 熟练使用AI辅助编码工具实现快速开发。
此外,如果候选人还拥有优秀的产品思维和设计直觉,那将是极大的加分项。
*** 1. 灵活运用AI“积木”
假设你只有一种乐高积木,你也许只能建造简单的模型;但如果你拥有丰富多样的乐高积木类型,就能快速搭建复杂且功能强大的结构。AI工具箱里的各种组件(如框架、SDK等)就类似于这些乐高积木:
- 如果你只知道调用大语言模型(LLM)API,这是很好的起点。
- 如果你熟悉更多的AI构建组件——如:
- 提示工程(prompting techniques)
- 智能体框架(agentic frameworks)
- 模型评估方法(evals)
- 安全防护措施(guardrails)
- 检索增强生成(RAG)
- 语音技术栈(voice stack)
- 异步编程(async programming)
- 数据提取
- 向量数据库(embeddings/vectorDBs)
- 模型微调(fine-tuning)
- 图数据库与LLM结合使用(graphDBs)
- 智能浏览器/计算机操作
- MCP(模型控制协议)
- 推理模型(reasoning models)
你就能更快、更灵活地构建出丰富且复杂的应用。
尽管新的AI工具持续涌现,但许多诞生于一两年前的“积木”(例如模型评估技术、向量数据库框架)至今依然非常实用,值得持续关注。
*** 2. AI辅助编程能力
AI辅助编程工具极大地提高了工程师的生产力,近年发展迅猛:
- 2021年,GitHub Copilot首次推出,掀起了代码自动补全工具的浪潮。
- 随后,Cursor和Windsurf等新型AI增强IDE迅速涌现,显著改善了代码的质量保证(QA)和生成能力。
- 当前,高智能自主的AI编码助手——如OpenAI的Codex和Anthropic的Claude Code——已能自主完成代码编写、测试及多轮迭代的调试。
不过,要充分发挥这些工具的潜力,开发者不仅仅是“感觉式”写代码(vibe coding),而是必须对AI和软件架构的基本原理有深刻理解,能够有策略地引导开发过程,以实现明确的产品目标。
与AI构建组件不同,AI辅助编程工具的更新换代非常迅速,一两年前的技术可能很快就显得落伍。这一现象的原因之一是:工程师通常只会同时使用少数几种辅助编程工具,市场竞争更加激烈。这一领域巨头(Anthropic、谷歌、OpenAI等)持续投入巨资推动创新,因此持续关注和掌握最新的AI辅助编程工具对于工程师来说极为重要。
*** 3. 产品思维和设计直觉(加分项)
在一些公司,开发者通常被动地根据设计稿一一实现产品细节。然而,AI领域产品经理的短缺使得开发团队如果事无巨细地依赖产品经理,效率会大大降低。
经验表明,如果GenAI应用工程师拥有基本的用户同理心和设计直觉,即使只获得“高层次的产品指引”(比如:“给用户做一个能查看个人信息、修改密码的界面”),也能迅速做出合理的判断,并迅速搭建出可迭代的原型,大幅提升团队整体的效率。
** 如何在面试中识别优秀的GenAI工程师?
在面试GenAI应用工程师时,我通常会从三个方面展开:
- 对AI构建组件的掌握程度
- AI辅助编程工具的熟练程度
- 候选人的产品/设计直觉能力(选问)
除此之外,我特别看重的一个问题是:
> “你如何保持对AI领域最新进展的关注?”
因为AI技术发展速度极快,能够系统性跟进行业最新趋势的工程师通常具备以下习惯:
- 订阅并定期阅读专业资讯(如The Batch)
- 持续参与高质量的短期培训课程(😃)
- 经常进行项目实战训练,保持实践能力
- 积极参与相关的技术社区,交流前沿知识与实践经验
这些习惯不仅体现了候选人持续学习和探索的态度,也能够确保他们始终站在技术前沿。
---
掌握好上述技能组合,并善于持续学习的GenAI应用工程师,将在企业快速发展的AI生态系统中发挥越来越关键的作用。

12 Jun 2025

There’s a new breed of GenAI Application Engineers who can build more-powerful applications faster than was possible before, thanks to generative AI. Individuals who can play this role are highly sought-after by businesses, but the job description is still coming into focus. Let me describe their key skills, as well as the sorts of interview questions I use to identify them.
Skilled GenAI Application Engineers meet two primary criteria: (i) They are able to use the new AI building blocks to quickly build powerful applications. (ii) They are able to use AI assistance to carry out rapid engineering, building software systems in dramatically less time than was possible before. In addition, good product/design instincts are a significant bonus.
AI building blocks. If you own a lot of copies of only a single type of Lego brick, you might be able to build some basic structures. But if you own many types of bricks, you can combine them rapidly to form complex, functional structures. Software frameworks, SDKs, and other such tools are like that. If all you know is how to call a large language model (LLM) API, that's a great start. But if you have a broad range of building block types — such as prompting techniques, agentic frameworks, evals, guardrails, RAG, voice stack, async programming, data extraction, embeddings/vectorDBs, model fine tuning, graphDB usage with LLMs, agentic browser/computer use, MCP, reasoning models, and so on — then you can create much richer combinations of building blocks.
The number of powerful AI building blocks continues to grow rapidly. But as open-source contributors and businesses make more building blocks available, staying on top of what is available helps you keep on expanding what you can build. Even though new building blocks are created, many building blocks from 1 to 2 years ago (such as eval techniques or frameworks for using vectorDBs) are still very relevant today.
AI-assisted coding. AI-assisted coding tools enable developers to be far more productive, and such tools are advancing rapidly. Github Copilot, first announced in 2021 (and made widely available in 2022), pioneered modern code autocompletion. But shortly after, a new breed of AI-enabled IDEs such as Cursor and Windsurf offered much better code-QA and code generation. As LLMs improved, these AI-assisted coding tools that were built on them improved as well.
Now we have highly agentic coding assistants such as OpenAI’s Codex and Anthropic’s Claude Code (which I really enjoy using and find impressive in its ability to write code, test, and debug autonomously for many iterations). In the hands of skilled engineers — who don’t just “vibe code” but deeply understand AI and software architecture fundamentals and can steer a system toward a thoughtfully selected product goal — these tools make it possible to build software with unmatched speed and efficiency.
I find that AI-assisted coding techniques become obsolete much faster than AI building blocks, and techniques from 1 or 2 years ago are far from today's best practices. Part of the reason for this might be that, while AI builders might use dozens (hundreds?) of different building blocks, they aren’t likely to use dozens of different coding assistance tools at once, and so the forces of Darwinian competition are stronger among tools. Given the massive investments in this space by Anthropic, Google, OpenAI, and other players, I expect the frenetic pace of development to continue, but keeping up with the latest developments in AI-assisted coding tools will pay off, since each generation is much better than the last.
Bonus: Product skills. In some companies, engineers are expected to take pixel-perfect drawings of a product, specified in great detail, and write code to implement it. But if a product manager has to specify even the smallest detail, this slows down the team. The shortage of AI product managers exacerbates this problem. I see teams move much faster if GenAI Engineers also have some user empathy as well at basic skill at designing products, so that, given only high-level guidance on what to build (“a user interface that lets users see their profiles and change their passwords”), they can make a lot of decisions themselves and build at least a prototype to iterate from.
When interviewing GenAI Application Engineers, I will usually ask about their mastery of AI building blocks and ability to use AI-assisted coding, and sometimes also their product/design instincts. One additional question I've found highly predictive of their skill is, “How do you keep up with the latest developments in AI?” Because AI is evolving so rapidly, someone with good strategies for keeping up — such as reading The Batch and taking short courses 😃, regular hands-on practice building projects, and having a community to talk to — really does stay ahead of the game.
[Original post: deeplearning.ai/the-batch/is… ]
8
127
429
59,504

11 Jun 2025
See my timeline for plenty of graphRAG takes. But a recap
- The biggest hurdle is to build the knowledge base (easier with LLMs, but still a real challenge)
- Then how do you use the knowledge base during retrieval, how far should you traverse the graph
Finally, graphDBs optimizes traversal of graph data structures, but there is nothing stopping you from representing graphs and relationships using searchengineRAG if you want to give it a specific name.
3
106
6 Jun 2025
I have definitely incurred plenty injury ripping out graphDBs almost every time they are used 🤣
Ofc you can say this is selection bias. But alas, this is my lived experience 😅
1
2
128

23 Feb 2025
It’s been a minute in fintech, and I recently started working on a Fraud Monitoring System with Go and Neo4j as a side project. It’s turning out to be way more interesting than I expected!.
GraphDBs are cool. it's amazing how easily you can map out complex relationships⚡
4
7
95
2,379