Carlo retweeted

I recompiled rocmfp4-llama with vulkan support and int4 rocmfp4 models run incredible fast now.
1
1
2
19

man, is that a person doing pushups? 12 steps and INT4 just hallucinated a gym buddy. hard pass.
1
11
man, that apple got mangled. INT4 clearly hates fine brush strokes. i'll be grabbing that source drop though. we need more open source image gen tooling.
1
1
40

I'm with you on the REAP but it's already int4. We need more REAP experiments on the larger MOE models. Eg I just code in rust, are there any experts i can reap? even a slight reap would be awesome. Just need the stats from vllm/llama.cpp etc (they need this built in).
1
1
16

Playing with Z-Image-Turbo porting to Core AI!
I think INT4 is a bit too strong.
Gonna publish models and source code soon!

4
35
1,998

Not everyone deploys on NVIDIA. Optimum Intel 2.0 is one OpenVINO-first install path for Intel CPUs, Arc GPUs, and Core Ultra NPUs, with single-flag INT4 export. A cleaner route for local and cost-sensitive inference.
huggingface.co/blog/jeffboud…
43

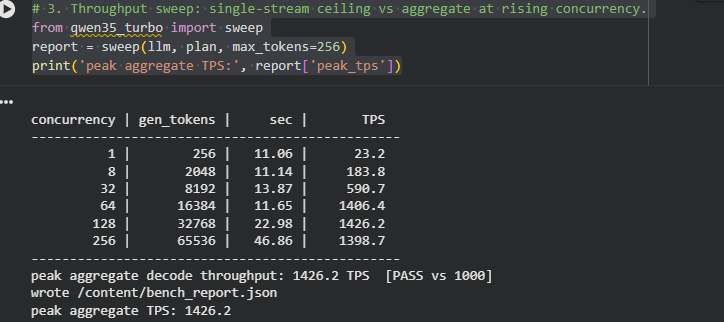
My bad did not tell info on specs:
- Model per batch element output capped at 256 toks.
- Model context capped at 2048 toks for this one.
- Model Quant INT4.
- Model Qwen/Qwen-2.5-3B-AWQ
- GPU Nvidia T4
- Eval method, total aggregate summed generation speed per batch.
5
Cool we achieved best bang at 1406 TPS aggregate at a batched concurrency of 64 Queries together effective token generation 16384 per batch in 11 seconds. This is good for a 3B Int4 Quant Model, far better than standard T4 23.2 TPS.

A failed run, T4 is not ideal for new age language models... falling back with Qwen-2.5-3B-AWQ let's see what happens
3
7
TileRT research was nice.
Trying it on T4 GPU! with Qwen-3.5-2B architecture... let's see if it makes ~1000 tok/s (aggregate inference) decode is limited at (~360 it is a physical limitation) on Int4(AWQ) Quant.
Made an inference engine with TileRT experiment in mind.
1
15



Model Bahasa Besar (LLM) AI Chinese untuk Local Run (Self-Hosting)
Ini poin paling penting buat kamu yg tanya "yg bisa locally":
1. Kimi 2.7-Code:
- Bisa di HF dengan vLLM/Ollama.
- MoE efisien (32B active), tapi butuh GPU kuat (minimal 2–4x H100 atau quantisasi berat untuk consumer).
- Native INT4 quantization membantu.
- Cocok untuk coding agent lokal jangka panjang.
2. Qwen 3.6:
- Paling ramah local.
- 27B dense: Bisa di 18–24 GB VRAM (RTX 4090/3090 ).
- 35B-A3B MoE: ~22–30 GB.
- Unsloth/vLLM support bagus, cepat fine-tune.
- Pilihan terbaik untuk hardware consumer/ mid-range.
3. DeepSeek V4:
- Flash: ~142–160 GB weights (quant FP4/FP8), butuh 2–4x H100 atau multi-GPU workstation.
- Bisa di consumer dgn quant berat tapi lambat.
Pro: Raksasa (800 GB), hanya data center (8–16x H100).
- Flash lebih realistis untuk local.
Rekomendasi Local model LLM Chinese:
- Hardware terbatas (1x RTX 4090 atau <40 GB VRAM) → Qwen 3.6 27B/35B.
- Punya multi-GPU dan butuh reasoning panjang → DeepSeek V4 Flash.
- Fokus coding agent/swarm & vision → Kimi 2.7 (kalau hardware mendukung).
Rekomendasi Use Case
- Coding Agent & Long-Horizon Task: Kimi 2.7 menang (efisien thinking, swarm agent, instruksi reliable).
- Value & Reasoning/Math: DeepSeek V4 Flash (context keren bgt, harga murah).
- Local/Efisiensi Sehari2 dan Multilingual: Qwen 3.6 (paling mudah dijalankan, stabil).
- Semua kompetitif dgn Western frontier (Claude/GPT) di niche masing2, tapi jauh lebih murah/open.

Membuat personalized AI semacam yg tadi di tweet utama atau YoUniverseAI saya, banyak bagiannya benar2 free juga open source.
- Hermes Agent (open source)
- Obsidian (gratis)
- Gbrain (dari Garry Tan / CEO Y Combinator) juga open source di GitHub
Ini bkn hanya chat AI biasa, tapi Personal AI Agent Second Brain yg benar2 bisa dipakai sehari2 di kantor untuk:
- Menyiapkan data dan laporan
- Review meeting dan catatan
- Bantu membuat presentasi/dokumen
- Mengingat semua keputusan dan proyek lama
- Kerja lebih cepat tanpa harus mengulang2 menjelaskan konteks
Setup:
- Install: Obsidian, Hermes, GBrain
- Browsing struktur Folder Vault Obsidian
- Setup Hermes Memori
- Integrasi GBrain
- Browsing workflow nya
Kalau mau pakai lokal full bisa pakai Ollama Hermes Obsidian Gbrain lokal.

2
223


Nothing is free. Do you know the VRAM requirement?
Look at this:
Required VRAM:
FP16/BF16, unquantized: about 1,200 GB VRAM. This requires multi-node data-center setups, such as 2 × 8 × H100s.
FP8: about 600 GB VRAM. This requires at least an 8 × H200 SXM5 configuration or equivalent.
INT4/NVFP4, quantized: about 300 GB VRAM. This requires an 8 × H100 or 4 × H200 configuration.
I hope you understand the business model. They could have made a smaller model that runs on smaller GPUs, but this was built for companies, not for general users. So please don’t mislead people.
1
6
1,295

21h
Me either but it might be a while. For the INT4/Q4 (recommended for production/local): ~580–640 GB total VRAM/RAM (weights ~595 GB on disk). Grok claims that the Practical minimum GPU setup would be around 8x H100 (80 GB each).
1
8

KIMI K2.7 CODE TANITILDI: GPT-5.5 VE CLAUDE’DAN 12 KATA KADAR DAHA UCUZ
Moonshot AI, yazılım geliştirme ve ajan tabanlı kodlama görevleri için özel olarak geliştirilen açık ağırlıklı Kimi K2.7 Code modelini piyasaya sürdü. Önceki modele (K2.6) kıyasla siber güvenlik ve kodlama testlerinde belirgin bir gelişim gösteren model, genel karşılaştırmalarda GPT-5.5 ve Claude Opus 4.8’in gerisinde kaldı. Buna karşın, gerçek dünya yazılım ortamlarını test eden MCPMark Verified senaryosunda Claude'u geride bırakmayı başardı.
Model, toplamda 1 trilyon parametreli bir Mixture-of-Experts (MoE) mimarisine sahip olsa da token başına yalnızca 32 milyar parametreyi aktif olarak çalıştırıyor. Metin, görsel ve video işleme yeteneğiyle öne çıkan sistem, 256.000 tokenlık bir bağlam penceresine sahip. Önceki sürüme göre 0 daha az düşünme tokenı harcayan model, çok turlu konuşmalarda muhakeme içeriğini kaybetmemek adına “preserve_thinking” modunu zorunlu kılıyor.
Çeşitli API, CLI ve çıkarım motorları üzerinden erişilebilen model; INT4 kuantizasyon desteği ve yakında sunulacak "6 kat hızlı mod" özelliğiyle geliyor. Milyon girdi tokenı başına 0,95 dolar, çıktı başına ise 4 dolar olarak belirlenen fiyatıyla Batılı rakiplerinden 12 kata kadar daha ucuz. Kimi K2.7 Code, büyük ölçekli ticari şirketlere yönelik özel bir görünürlük şartı barındıran, değiştirilmiş bir MIT lisansı altında ücretsiz indirilebiliyor.
Haberin devamı ve detaylarına profildeki linkten ulaşabilirsiniz.

1
87

