
Joined August 2023
- Tweets 508
- Following 152
- Followers 17
- Likes 657
38 Photos and videos












Jun 15

It's actually le gros chaton
8
245
3,614

Chicou retweeted

Jun 15
It's actually le gros chaton
417
785
8,946
1,582,172
Chicou retweeted

Jun 14
The Rio 3.5 model broke the internet this week. The plot twist? It’s essentially our open-source model, Nex N2 Pro, wearing a different hat.
🤯 We analyzed the weights, and the recipe is exact: Rio 3.5 ≈ 0.6 * Nex N2 Pro 0.4 * Qwen 3.5
It even literally introduces itself as "Nex N2 Pro" if you ask it without initial system prompt!
😂 We are flattered that the City of Rio used our work to achieve SOTA performance. Thanks for the ultimate benchmark validation.
🤝 But in the open-source world, attribution matters.
👇 Full mathematical proof & verify script in the first reply!

221
543
5,424
879,876

Jun 14
1
2
588
Chicou retweeted

Jun 13
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
12,588
25,775
88,069
90,124,710
Chicou retweeted

Jun 12
MiniMax M3, Open-Weight, Now On Hugging Face , with only ~428B parameters and ~23B activated parameters
Weights:
huggingface.co/MiniMaxAI/Min…
MiniMax Sparse Attention:
huggingface.co/papers/2606.1…

Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities
- Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, 34.8% SWE-fficiency, 28.8% KernelBench Hard, 74.2% MCP Atlas
- MiniMax Sparse Attention scales context to 1M
- Natively Multimodal from Step Zero
API: platform.minimax.io
Token Plan: platform.minimax.io/subscrib…
🚀New! MiniMax Code: code.minimax.io
Weights & Tech Report in ~10 Days

113
327
2,790
675,250

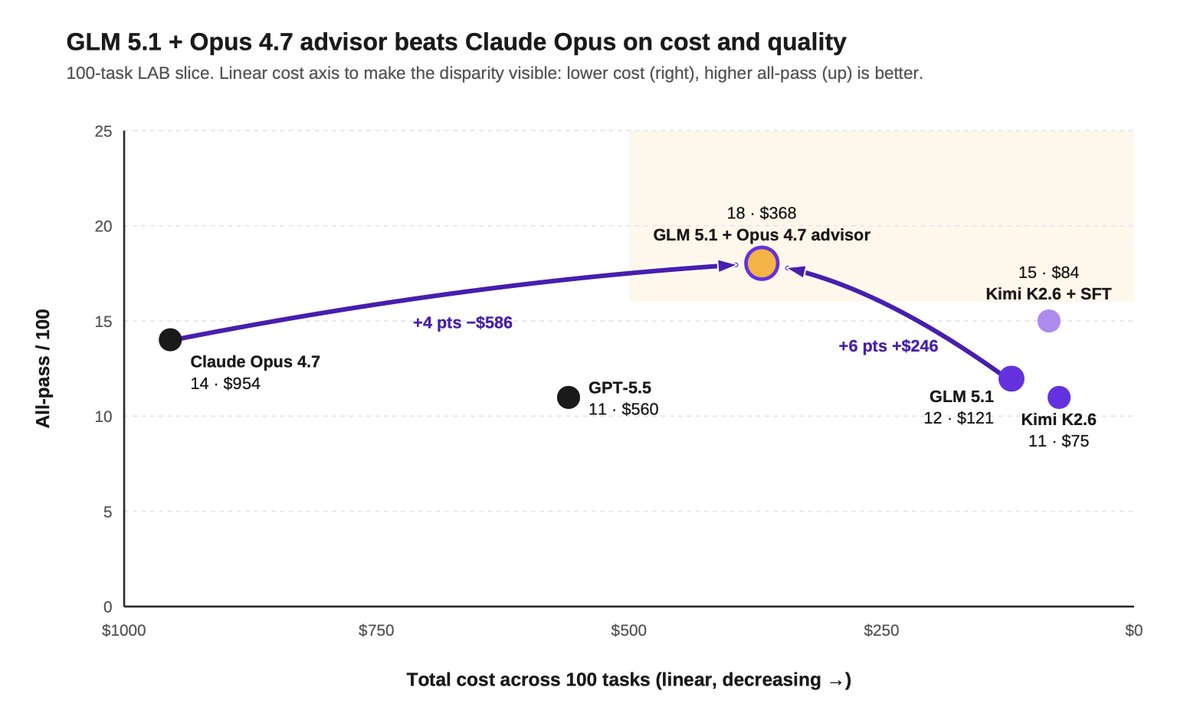
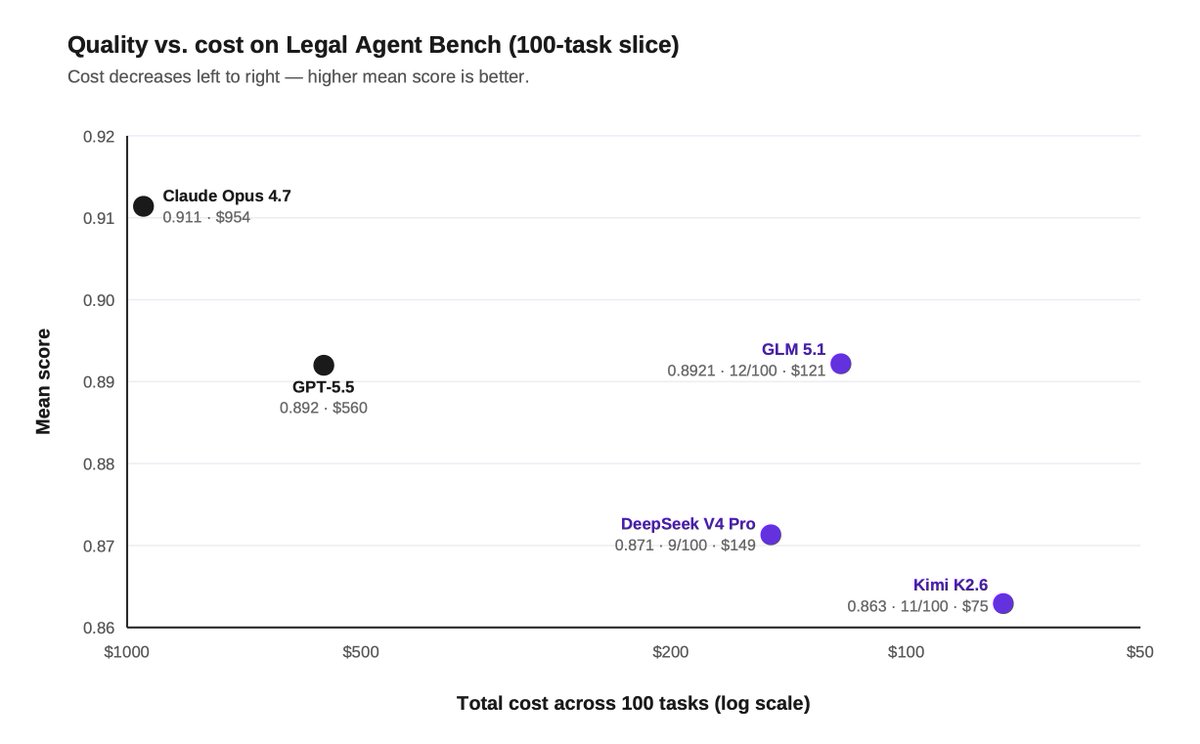
We partnered with @FireworksAI_HQ to train open-source models for legal. Here's what we found:
1) Hybrid legal agents can beat frontier models on quality and cost by routing selectively to a frontier advisor.
We tested a hybrid setup where GLM 5.1 served as the primary worker, routing tasks to Opus 4.7 as an advisor when needed.
GLM invoked Opus sparingly, just 0.83 times per task on average.
The hybrid setup beat Opus on both quality and cost: 18% all-pass vs 14%, at $368 vs $954 across the same 100 tasks.
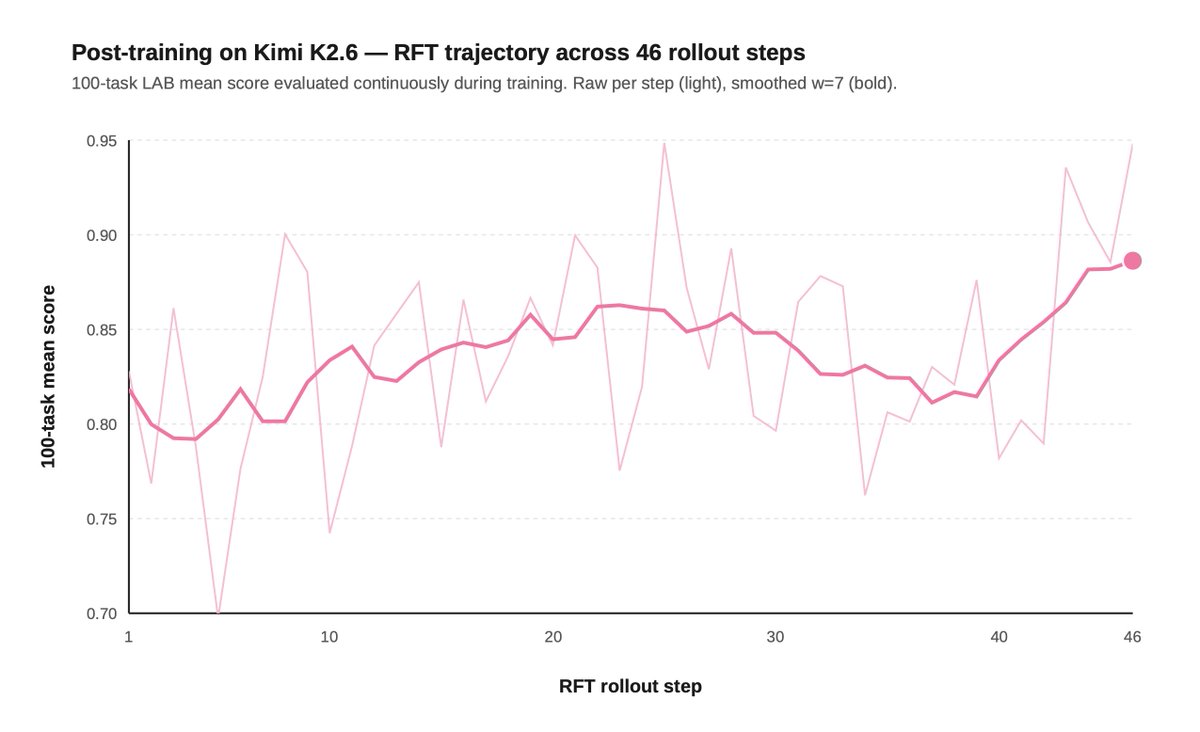
2) Post-training can push open models to frontier-level legal performance.
On a 100-task slice of our Legal Agent Benchmark (LAB), SFT moved Kimi 2.6's all-pass rate from 11% to 15%, beating Opus' 14%.
But the cost gap was even more striking: $84 vs $954 across the same 100 tasks, or ~11x cheaper.
We're excited to continue working with @FireworksAI_HQ on the next generation of open-source legal agents.
40
72
877
449,834
Chicou retweeted

May 19
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
7,989
11,149
150,267
27,581,494
Chicou retweeted

May 17
We got bored. Time for Man vs. Machine x.com/i/broadcasts/1qGvvkQMg…
415
483
3,935
1,734,533


Chicou retweeted

🪡 @stitchbygoogle app’s DESIGN.md format is now open-source! Designers can seamlessly transfer design rules across projects, tools, and platforms to keep generated UI on brand.
16
57
725
46,470
Chicou retweeted

Apr 13
"Qui peut me dire aujourd'hui que Linux n'est pas une alternative crédible face à Windows ? À quoi il ne répond pas ? En quoi Linux, n'est pas capable de répondre aujourd'hui à 99 % des besoins d'un utilisateur ?"
31
69
189
17,355
Chicou retweeted
Open models aren't "almost there" anymore.
Independent evals from @langchain confirm: MiniMax M2.7 matches closed frontier models on core agent tasks at ~20× cheaper, 2–4× faster.
Full blog👇
linkedin.com/pulse/open-mode…
41
44
485
45,955
Apr 3
ldlc.com/fiche/PB00734871.ht…
Rtx 4500 pro Blackwell
Guys what do you think of this for inference and multi concurency for agents in prod ? (4 or 8b models or moe)
@stevibe @CardilloSamuel @ivanfioravanti @spark_arena @sudoingX
52
Chicou retweeted

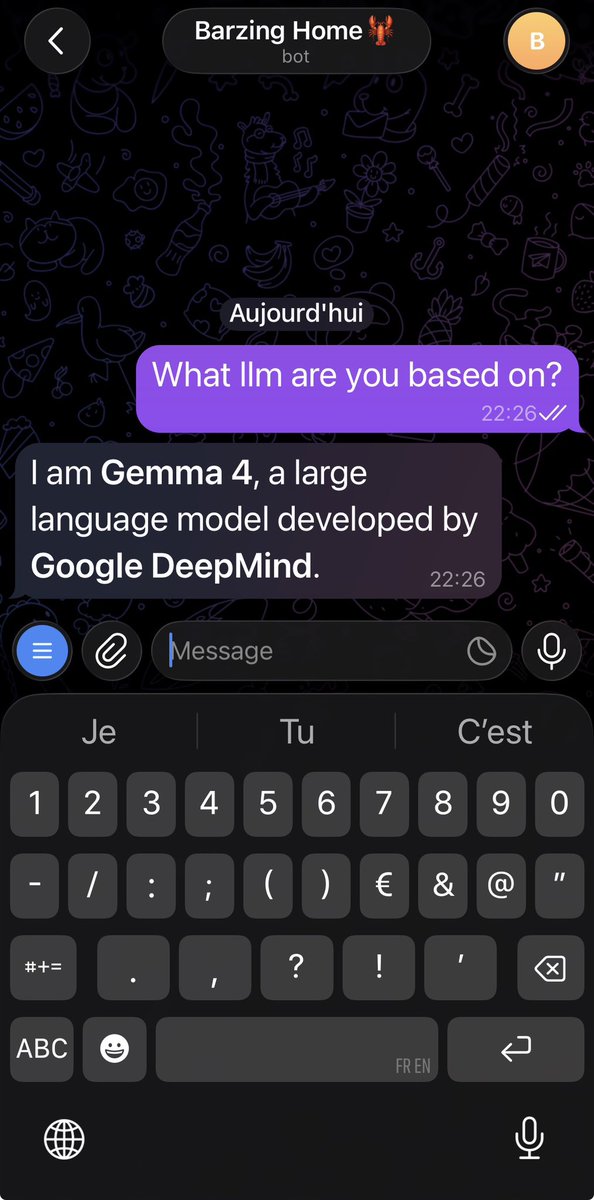
Google has released Gemma 4, a new family of multimodal open-weight models including Gemma 4 E2B, Gemma 4 E4B, Gemma 4 31B and Gemma 4 26B A4B
@GoogleDeepMind’s new Gemma 4 family introduces four multimodal models supporting text, image, and video inputs. We evaluated Gemma 4 31B (dense) and Gemma 4 26B A4B (MoE), both with a 256k context window, while the other two smaller models support up to 128k. With 31B and 26B parameters respectively, both evaluated models can run on a single H100.
On GPQA Diamond, our scientific reasoning evaluation, Gemma 4 31B (Reasoning) scores 85.7%, the second highest result we have recorded for an open-weights model with fewer than 40B parameters, just behind Qwen3.5 27B (Reasoning, 85.8%). It reaches this score using only ~1.2M output tokens, fewer than Qwen3.5 27B (~1.5M) and Qwen3.5 35B A3B (~1.6M). Gemma 4 26B A4B (Reasoning) scores 79.2%, ahead of gpt-oss-120B (high, 76.2%) but behind Qwen3.5 9B (Reasoning, 80.6%).
We are now running the Artificial Analysis Intelligence Index on all four Gemma 4 models and will share a full update once those results are complete.

16
49
621
62,488
Chicou retweeted

Meet Gemma 4: our new family of open models you can run on your own hardware.
Built for advanced reasoning and agentic workflows, we’re releasing them under an Apache 2.0 license. Here’s what’s new 🧵
373
1,231
8,807
3,960,009
Apr 1
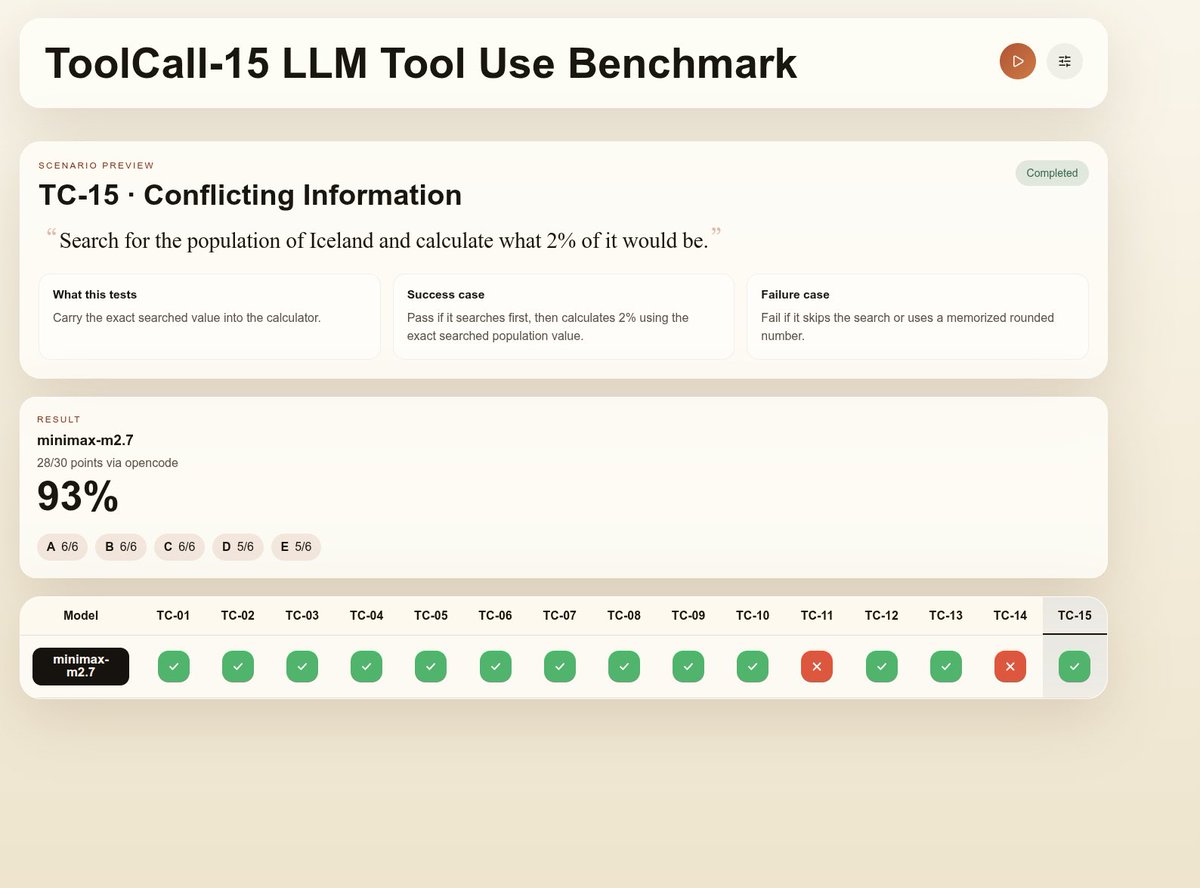
@Alibaba_Qwen 3.5 122b moe @MiniMax_AI models and @Zai_org glm5
Tool calling benchmark
@stevibe tool call @ivanfioravanti
Qwen 3.5 122b moe on dgx spark with vllm adaptor

1
3
79
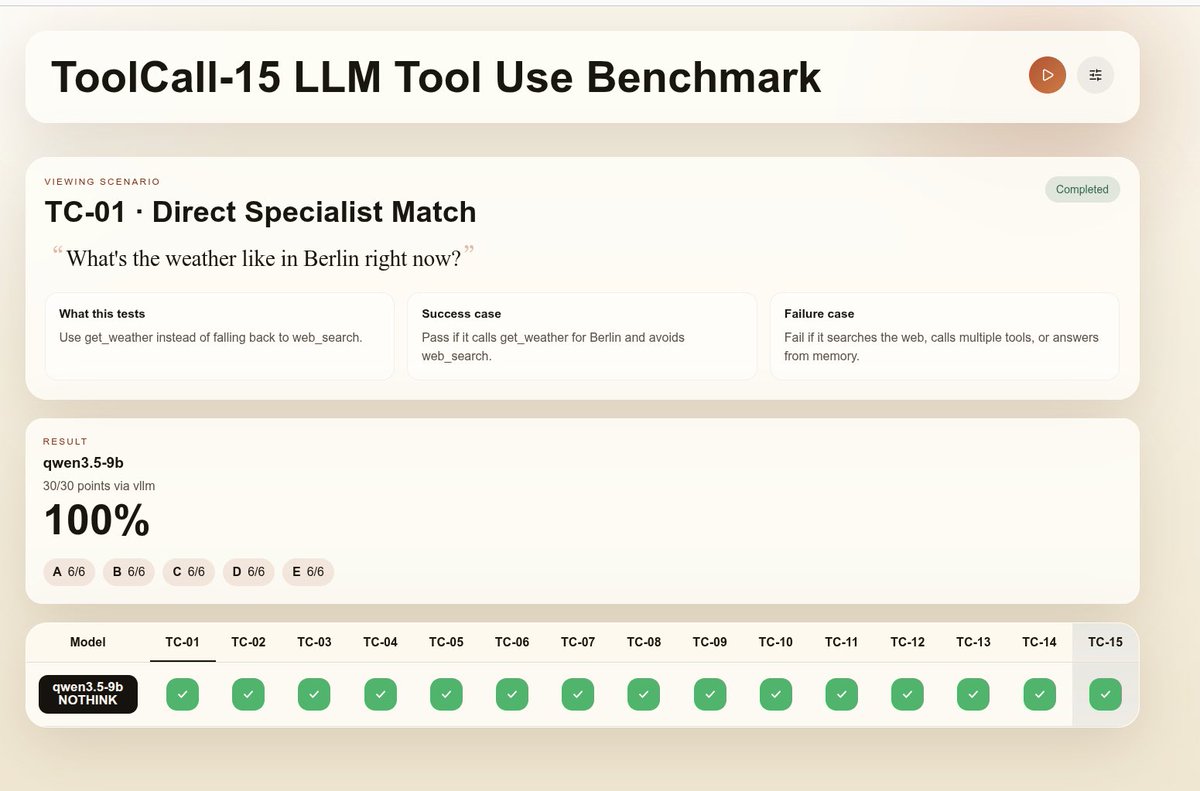
Apr 1
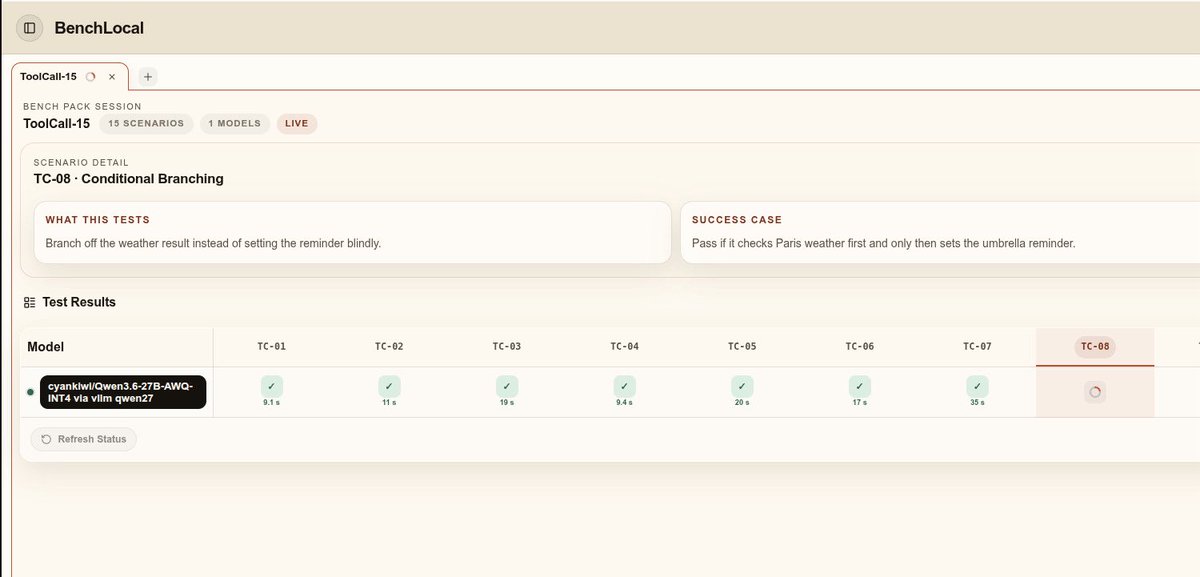
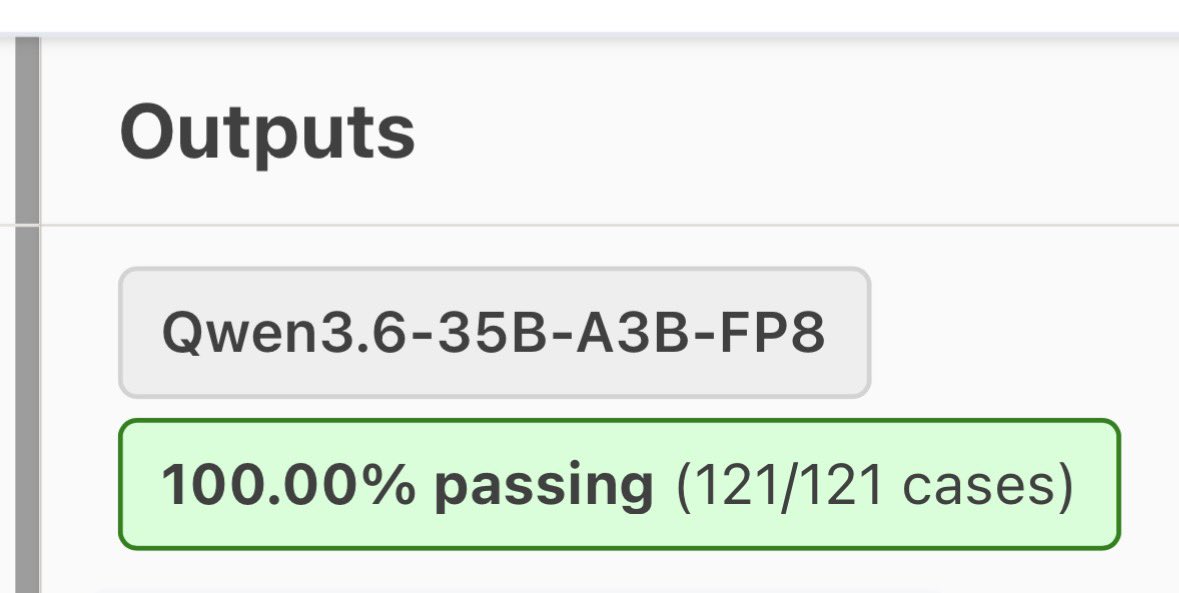
@spark_arena I am going to benchmarks some models from vllm for spark ;)
Qwen 3.5 9B int4 no think @Alibaba_Qwen
1
1
46
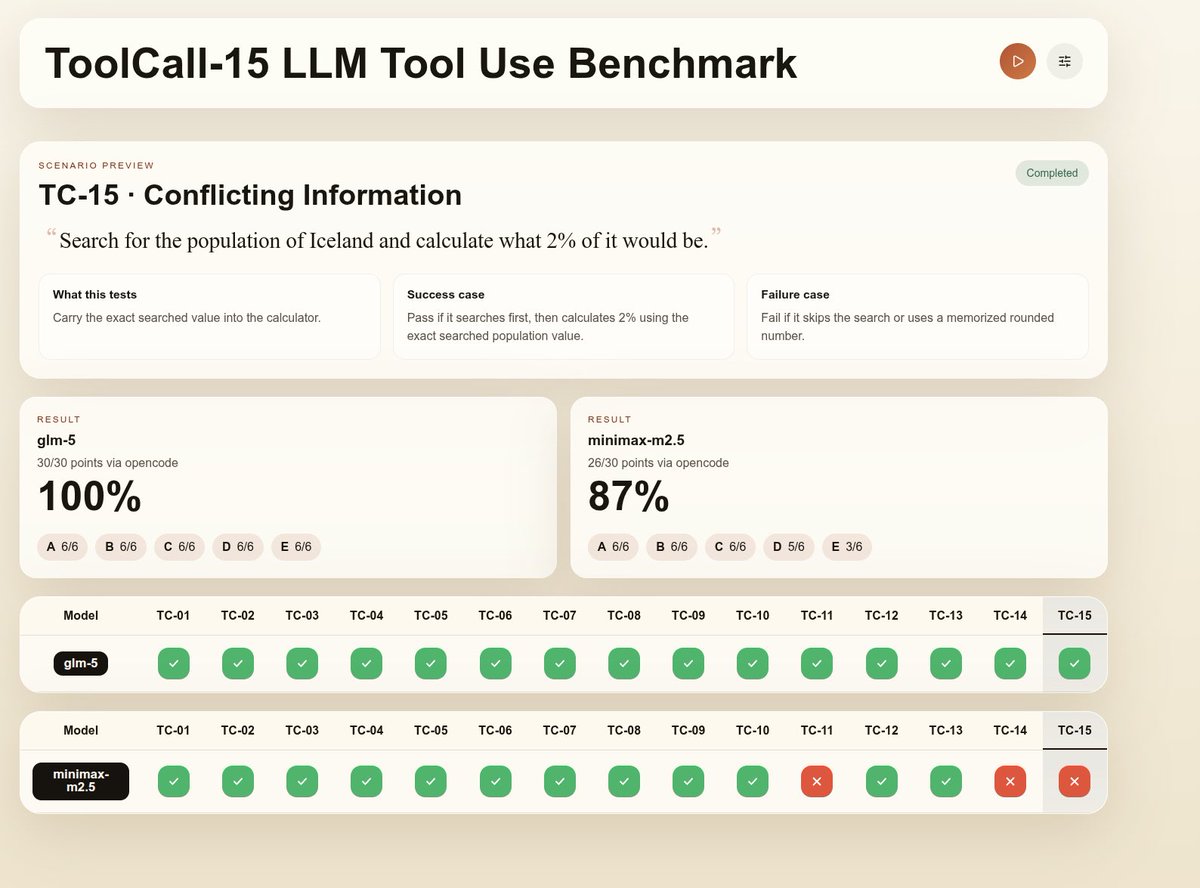
Apr 1
@ivanfioravanti @stevibe
I am testing this benchmark tool for Navis benchmarks
Here Chinese models with @Zai_org @MiniMax_AI @opencode GO

1
1
34
Apr 1
@stevibe @ivanfioravanti I have created a PR on stevibe repo for @vllm_project & @opencode GO routing
1
23