
8 Jul 2025
AF3互換モデルとして、今度はIntFoldというのがリリースされてますね。
AF3などよりも性能が高いことがアピールされてますが、ほかのモデルとの大きな違いは、追加データを用いてモデルを目的に応じてファインチューニングできることでしょうか。
arxiv.org/abs/2507.02025
1
6
657

8 Jul 2025
IntFold: A Controllable Foundation Model for General and Specialized Biomolecular Structure Prediction. arxiv.org/abs/2507.02025
3
179

7 Jul 2025
𝘛𝘦𝘤𝘩𝘯𝘪𝘤𝘢𝘭 𝘈𝘥𝘷𝘢𝘯𝘤𝘦𝘴
Custom FlashAttentionPairBias kernel: Faster and more memory-efficient than standard industry implementations
Model-agnostic ranking method: Training-free approach that improves success rates by ~3% through structural similarity consensus
𝘗𝘳𝘢𝘤𝘵𝘪𝘤𝘢𝘭 𝘐𝘮𝘱𝘢𝘤𝘵
IntFold demonstrates the potential for controllable foundation models in drug discovery, successfully addressing limitations of general-purpose models by enabling:
Prediction of functionally critical conformational states
Integration of prior structural knowledge
Accurate binding affinity estimation for virtual screening
1
2
975

5 Jul 2025
まいどです。
本日の生成AIニュース テクノロジー情報。
note.com/toshia_fuji/n/na668…
『KreaでGen-4』『LangScene-X』『Kontext Relight』『Flux Kontext Diff Merge』『ComfyUI-FramePackWrapper_PlusOne』『ComfyUI Prebuilt Docker Images』『ComfyUI Workflow Notification Plugin』『Kimi Researcher』『Akuma ai』『BeltOut』『SlimMoE』『Skywork-Reward-V2』『WebSailor』『IntFold』『RoboCowboys』『Genius, G1の使い道』『AdobeCCのプラン』
5
492

5 Jul 2025
📚 AI Native Daily Paper Digest - 20250704 🌟
Follow @AINativeF for the latest insights on AI Native.
Covering AI research papers from Hugging Face, featured in the image.
💡 Stay updated with the latest research trends and dive deep into the future of AI! 🚀
#AI #HuggingFace #AIPaper #AINative #AINF
— Appendix: Today's AI research papers —
1. WebSailor: Navigating Super-human Reasoning for Web Agent
2. LangScene-X: Reconstruct Generalizable 3D Language-Embedded Scenes with TriMap Video Diffusion
3. Heeding the Inner Voice: Aligning ControlNet Training via Intermediate Features Feedback
4. Skywork-Reward-V2: Scaling Preference Data Curation via Human-AI Synergy
5. IntFold: A Controllable Foundation Model for General and Specialized Biomolecular Structure Prediction
6. Thinking with Images for Multimodal Reasoning: Foundations, Methods, and Future Frontiers
7. Fast and Simplex: 2-Simplicial Attention in Triton
8. Decoupled Planning and Execution: A Hierarchical Reasoning Framework for Deep Search
9. Bourbaki: Self-Generated and Goal-Conditioned MDPs for Theorem Proving
10. Can LLMs Identify Critical Limitations within Scientific Research? A Systematic Evaluation on AI Research Papers
11. Self-Correction Bench: Revealing and Addressing the Self-Correction Blind Spot in LLMs
12. Energy-Based Transformers are Scalable Learners and Thinkers
13. AsyncFlow: An Asynchronous Streaming RL Framework for Efficient LLM Post-Training

1
9
270



4 Jul 2025
some impressive claims for IntFold
4 Jul 2025

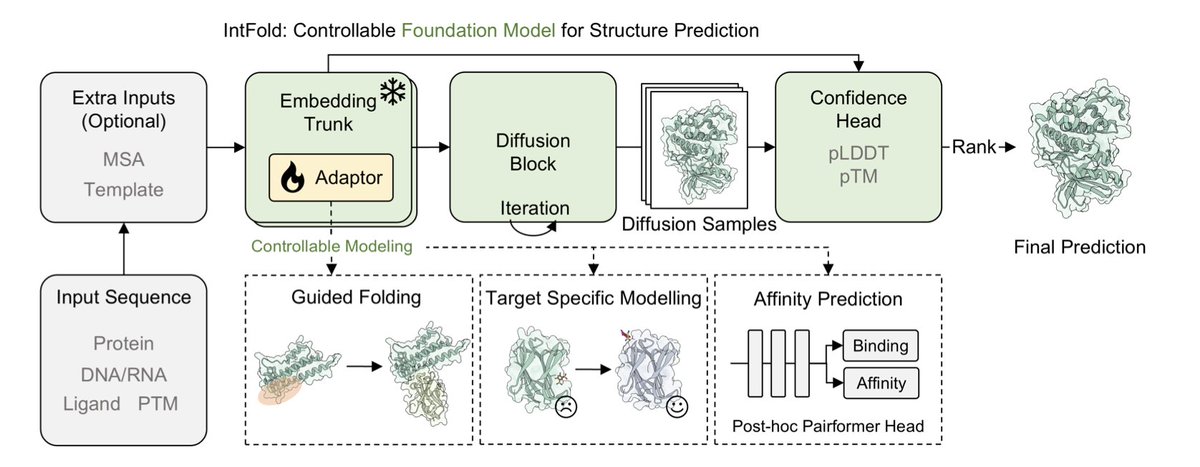
IntFold: A Controllable Foundation Model for General and Specialized Biomolecular Structure Prediction
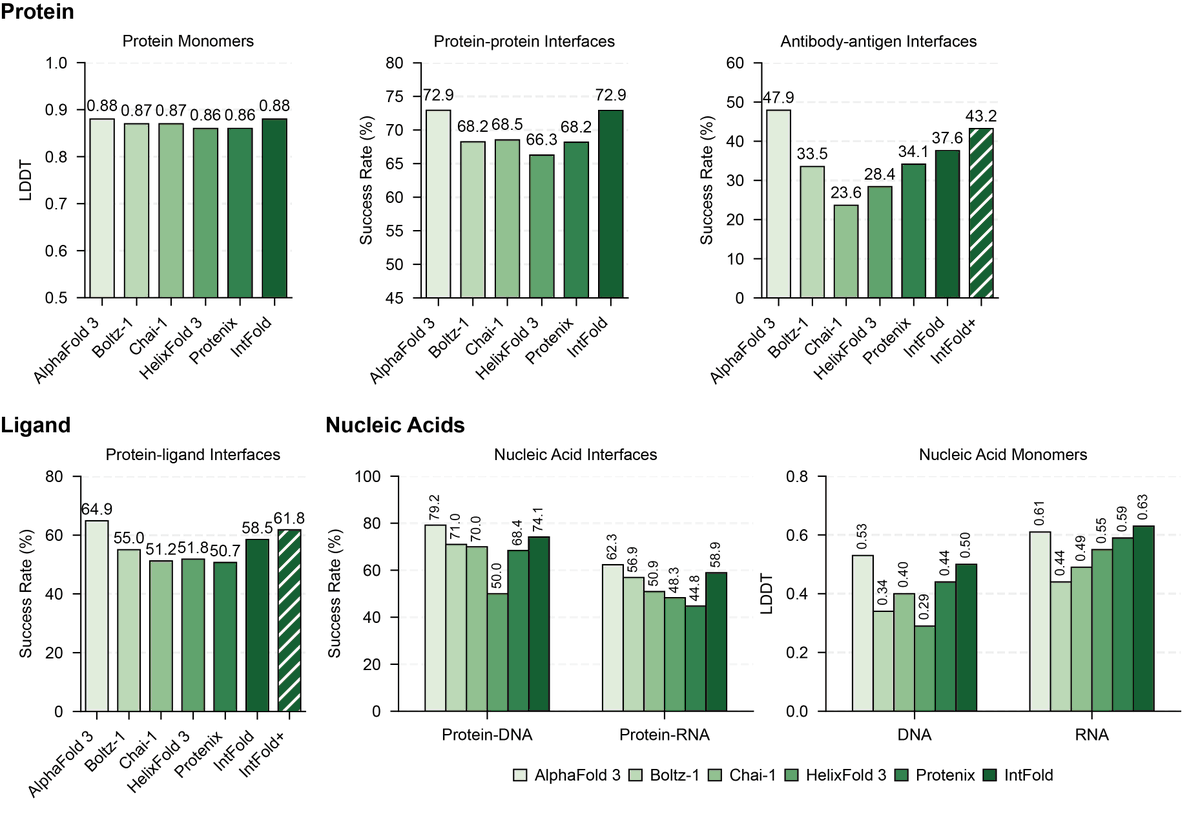
1.IntFold introduces a new class of biomolecular structure predictors—combining AlphaFold 3-level accuracy with fine-grained control over predictions. Its standout innovation: modular adapters enabling guided modeling of allosteric states, structural constraints, and binding affinities, critical for drug discovery.
2.On the FoldBench benchmark, IntFold matches AlphaFold 3 in protein monomer and protein-protein interaction prediction. It outperforms all other competitors—including Boltz-2 and HelixFold 3—across protein-ligand, antibody-antigen, and nucleic acid tasks.
3.A specialized variant, IntFold , further improves antibody-antigen docking (success rate 43.2%, nearly matching AlphaFold 3’s 47.9%) and protein-ligand interface predictions (61.8%), closing critical performance gaps in therapeutic contexts.
4.For CDK2, a classic allosteric kinase target, general models failed to capture inhibitor-induced conformations. IntFold’s fine-tuned adapter correctly identified 4 out of 5 rare allosteric states, without degrading accuracy on common structures—showcasing robust controllability.
5.By incorporating prior knowledge as structural constraints (e.g., known binding pockets or epitopes), IntFold drastically improves predictions. On antibody-antigen interfaces, success rates jumped from 37.6% to 69.0%—a major boost for immunological modeling.
6.IntFold delivers accurate binding affinity prediction using a downstream adapter. On DAVIS and BindingDB, it beats both structure-based and sequence-based baselines. On CASP16 targets, its predictions showed higher correlation with experimental affinities than Boltz-2.
7.The team developed a custom Triton-based attention kernel—FlashAttentionPairBias—more memory-efficient and faster than industry kernels from DeepSpeed and NVIDIA, enabling larger and more diverse training inputs.
8.A training-free, model-agnostic ranking method based on internal structural similarity improves prediction selection. For antibody-antigen targets, it raised success by 3% over random selection—offering a simple yet effective upgrade to multi-sample inference.
9.Training insights revealed sources of instability in large-scale biomolecular models. Solutions included layernorm tweaks, a “skip-and-recover” mechanism for exploding gradients, and carefully chosen initialization strategies, highlighting practical engineering know-how.
10.IntFold was trained on a rich and diverse dataset, including distilled predictions, curated affinity measurements, antibody-antigen distillations, and orthosteric/allosteric CDK2 complexes—laying a strong foundation for both generalization and specialization.
11.Despite its strengths, IntFold faces challenges typical of high-complexity models—such as cubic-time attention and imperfect performance on the hardest interface types. The team aims to improve scalability and expand applications into de novo protein design.
💻Code: github.com/IntelliGen-AI/Int…
📜Paper: arxiv.org/abs/2507.02025v1
#ProteinFolding #DrugDiscovery #AlphaFold #Biotech #ComputationalBiology #DeepLearning #IntFold #AntibodyDesign #MolecularModeling #BindingAffinity #AllostericPrediction
7
1,110

4 Jul 2025
IntFold: A Controllable Foundation Model for General and Specialized Biomolecular Structure Prediction
1.IntFold introduces a new class of biomolecular structure predictors—combining AlphaFold 3-level accuracy with fine-grained control over predictions. Its standout innovation: modular adapters enabling guided modeling of allosteric states, structural constraints, and binding affinities, critical for drug discovery.
2.On the FoldBench benchmark, IntFold matches AlphaFold 3 in protein monomer and protein-protein interaction prediction. It outperforms all other competitors—including Boltz-2 and HelixFold 3—across protein-ligand, antibody-antigen, and nucleic acid tasks.
3.A specialized variant, IntFold , further improves antibody-antigen docking (success rate 43.2%, nearly matching AlphaFold 3’s 47.9%) and protein-ligand interface predictions (61.8%), closing critical performance gaps in therapeutic contexts.
4.For CDK2, a classic allosteric kinase target, general models failed to capture inhibitor-induced conformations. IntFold’s fine-tuned adapter correctly identified 4 out of 5 rare allosteric states, without degrading accuracy on common structures—showcasing robust controllability.
5.By incorporating prior knowledge as structural constraints (e.g., known binding pockets or epitopes), IntFold drastically improves predictions. On antibody-antigen interfaces, success rates jumped from 37.6% to 69.0%—a major boost for immunological modeling.
6.IntFold delivers accurate binding affinity prediction using a downstream adapter. On DAVIS and BindingDB, it beats both structure-based and sequence-based baselines. On CASP16 targets, its predictions showed higher correlation with experimental affinities than Boltz-2.
7.The team developed a custom Triton-based attention kernel—FlashAttentionPairBias—more memory-efficient and faster than industry kernels from DeepSpeed and NVIDIA, enabling larger and more diverse training inputs.
8.A training-free, model-agnostic ranking method based on internal structural similarity improves prediction selection. For antibody-antigen targets, it raised success by 3% over random selection—offering a simple yet effective upgrade to multi-sample inference.
9.Training insights revealed sources of instability in large-scale biomolecular models. Solutions included layernorm tweaks, a “skip-and-recover” mechanism for exploding gradients, and carefully chosen initialization strategies, highlighting practical engineering know-how.
10.IntFold was trained on a rich and diverse dataset, including distilled predictions, curated affinity measurements, antibody-antigen distillations, and orthosteric/allosteric CDK2 complexes—laying a strong foundation for both generalization and specialization.
11.Despite its strengths, IntFold faces challenges typical of high-complexity models—such as cubic-time attention and imperfect performance on the hardest interface types. The team aims to improve scalability and expand applications into de novo protein design.
💻Code: github.com/IntelliGen-AI/Int…
📜Paper: arxiv.org/abs/2507.02025v1
#ProteinFolding #DrugDiscovery #AlphaFold #Biotech #ComputationalBiology #DeepLearning #IntFold #AntibodyDesign #MolecularModeling #BindingAffinity #AllostericPrediction
1
9
40
4,618
4 Jul 2025
IntFold: A Controllable Foundation Model for General and Specialized Biomolecular Structure Prediction
1.IntFold introduces a new class of biomolecular structure predictors—combining AlphaFold 3-level accuracy with fine-grained control over predictions. Its standout innovation: modular adapters enabling guided modeling of allosteric states, structural constraints, and binding affinities, critical for drug discovery.
2.On the FoldBench benchmark, IntFold matches AlphaFold 3 in protein monomer and protein-protein interaction prediction. It outperforms all other competitors—including Boltz-2 and HelixFold 3—across protein-ligand, antibody-antigen, and nucleic acid tasks.
3.A specialized variant, IntFold , further improves antibody-antigen docking (success rate 43.2%, nearly matching AlphaFold 3’s 47.9%) and protein-ligand interface predictions (61.8%), closing critical performance gaps in therapeutic contexts.
4.For CDK2, a classic allosteric kinase target, general models failed to capture inhibitor-induced conformations. IntFold’s fine-tuned adapter correctly identified 4 out of 5 rare allosteric states, without degrading accuracy on common structures—showcasing robust controllability.
5.By incorporating prior knowledge as structural constraints (e.g., known binding pockets or epitopes), IntFold drastically improves predictions. On antibody-antigen interfaces, success rates jumped from 37.6% to 69.0%—a major boost for immunological modeling.
6.IntFold delivers accurate binding affinity prediction using a downstream adapter. On DAVIS and BindingDB, it beats both structure-based and sequence-based baselines. On CASP16 targets, its predictions showed higher correlation with experimental affinities than Boltz-2.
7.The team developed a custom Triton-based attention kernel—FlashAttentionPairBias—more memory-efficient and faster than industry kernels from DeepSpeed and NVIDIA, enabling larger and more diverse training inputs.
8.A training-free, model-agnostic ranking method based on internal structural similarity improves prediction selection. For antibody-antigen targets, it raised success by 3% over random selection—offering a simple yet effective upgrade to multi-sample inference.
9.Training insights revealed sources of instability in large-scale biomolecular models. Solutions included layernorm tweaks, a “skip-and-recover” mechanism for exploding gradients, and carefully chosen initialization strategies, highlighting practical engineering know-how.
10.IntFold was trained on a rich and diverse dataset, including distilled predictions, curated affinity measurements, antibody-antigen distillations, and orthosteric/allosteric CDK2 complexes—laying a strong foundation for both generalization and specialization.
11.Despite its strengths, IntFold faces challenges typical of high-complexity models—such as cubic-time attention and imperfect performance on the hardest interface types. The team aims to improve scalability and expand applications into de novo protein design.
💻Code: github.com/IntelliGen-AI/Int…
📜Paper: arxiv.org/abs/2507.02025v1
#ProteinFolding #DrugDiscovery #AlphaFold #Biotech #ComputationalBiology #DeepLearning #IntFold #AntibodyDesign #MolecularModeling #BindingAffinity #AllostericPrediction

1
4
1,368

4 Jul 2025
IntFold: A controllable foundation model for general and specialized biomolecular structure prediction.
Achieves accuracy comparable to AlphaFold3, but with unique controllability for drug screening and design.
Visualize complex biomolecular structures like never before!
2
2
5
847

Our ReFOLD3 method presentation at ISMB/ECCB 2021 by Recep Adiyaman - 3DSIG @intfold youtu.be/AcdwUPXECwI

4
3
We used IntFOLD, ModFOLD, and ReFOLD for modeling SARS‐CoV2 proteins in the CASP‐commons experiment onlinelibrary.wiley.com/doi/…
1
1
2
IntFOLD has served ~11,000 unique users from over 100 different countries.
1
1
IntFOLD version 6 is now publicly available for user testing. Our recently published ModFOLD8 and ReFOLD3 methods are fully integrated with IntFOLD6. reading.ac.uk/bioinf/IntFOLD…
1
2
Our latest method for refinement of 3D models of proteins has also just been published. ReFOLD3 is also integrated with IntFOLD. "ReFOLD3: refinement of 3D protein models with gradual restraints based on predicted local quality and residue contacts" academic.oup.com/nar/advance…

2
3
Find out about our latest method for predicting the quality of 3D models of proteins. ModFOLD8 is fully integrated with the latest version of IntFOLD. "ModFOLD8: accurate global and local quality estimates for 3D protein models" academic.oup.com/nar/advance…

2
3