
🤖 Now on #KaggleModels!
Learn more: kaggle.com/models/mistral-ai…
18 Sep 2025

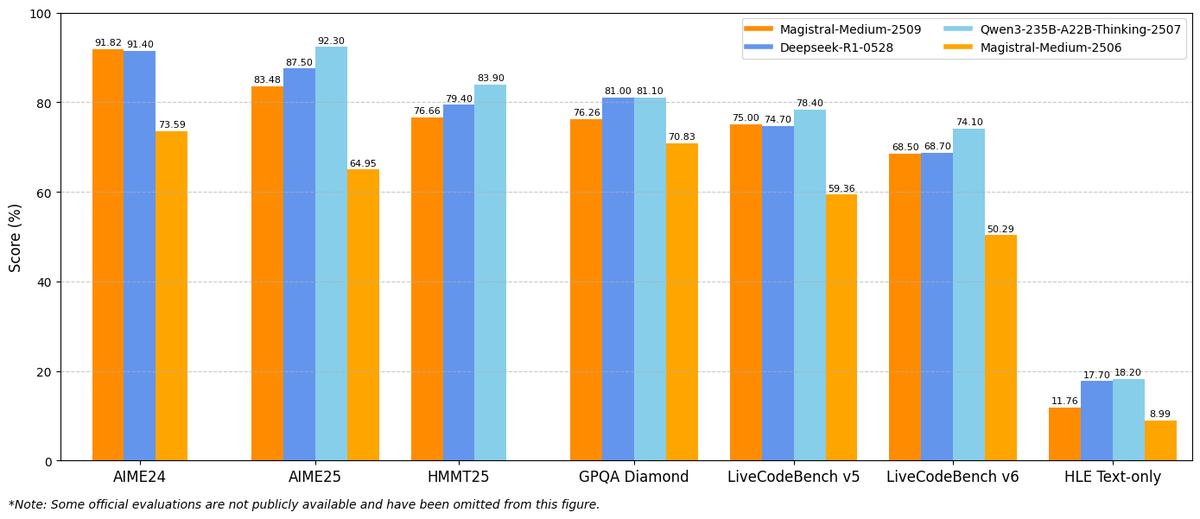
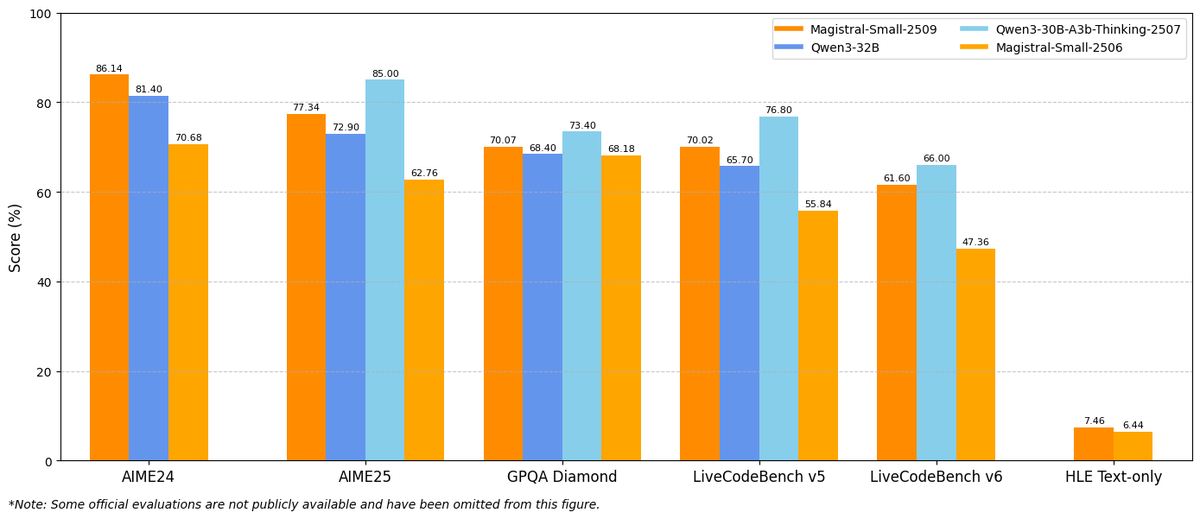
Introducing Magistral Small 1.2 & Magistral Medium 1.2, minor updates to our Magistral 1.1 models!
- Multimodality: Now equipped with a vision encoder, these models handle both text and images seamlessly.
- Performance Boost: 15% improvements on math and coding benchmarks such as AIME 24/25 and LiveCodeBench v5/v6.
- Smarter Tool Use: Better tool usage with web search, code interpreter, and image generation.
- Better Tone & Persona: Responses are clearer, more natural, and better formatted for you.
2
31
11,432
🤖 VaultGemma is now on #KaggleModels!
Learn more: kaggle.com/models/google/vau…
12 Sep 2025

🔒 VaultGemma is the world's most capable differentially private LLM.
1
4
27
12,149
Welcome Qwen3-Next-80B-A3B on #KaggleModels! 🤖
Learn more: kaggle.com/models/qwen-lm/qw…
11 Sep 2025

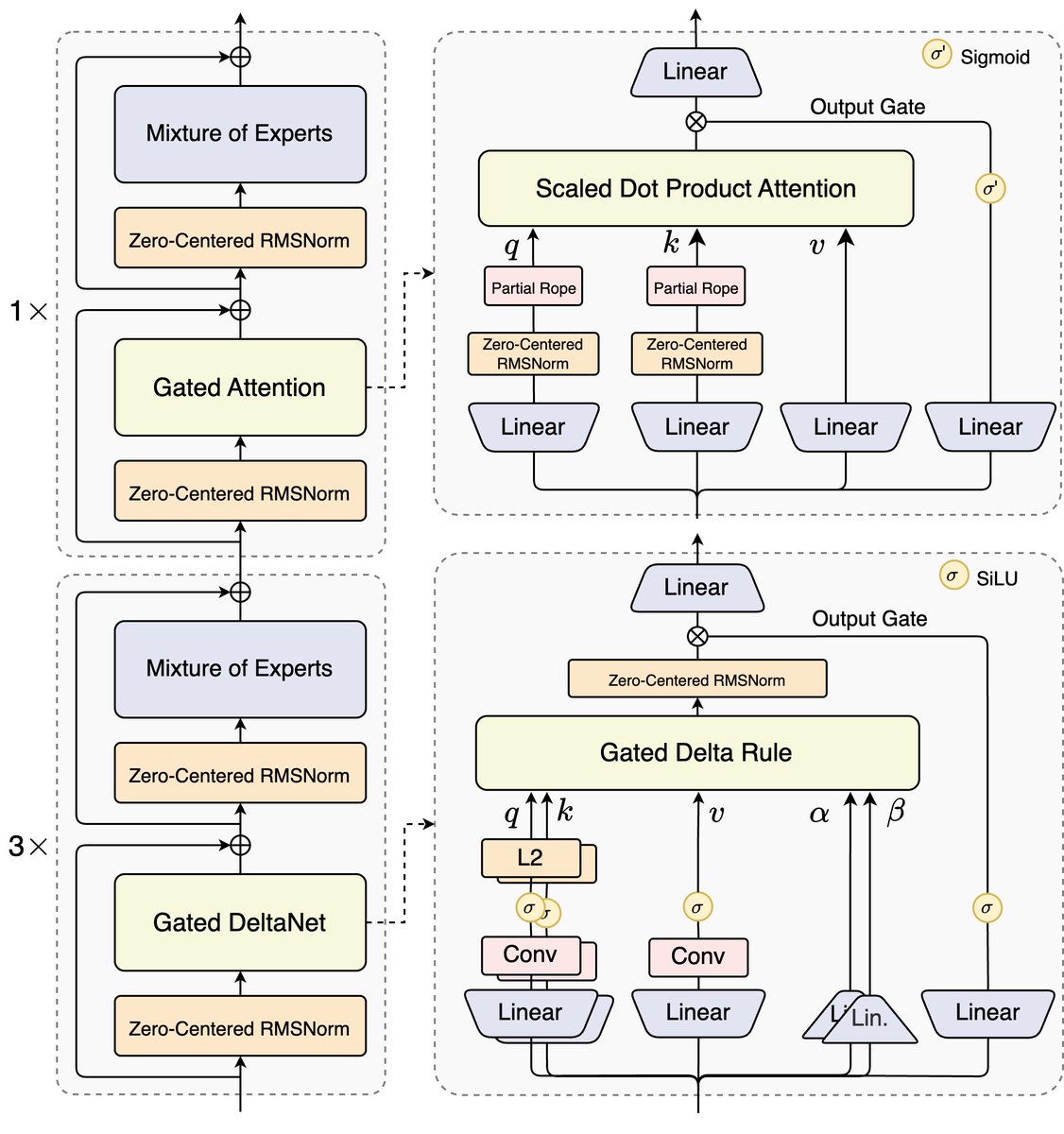
🚀 Introducing Qwen3-Next-80B-A3B — the FUTURE of efficient LLMs is here!
🔹 80B params, but only 3B activated per token → 10x cheaper training, 10x faster inference than Qwen3-32B.(esp. @ 32K context!)
🔹Hybrid Architecture: Gated DeltaNet Gated Attention → best of speed & recall
🔹 Ultra-sparse MoE: 512 experts, 10 routed 1 shared
🔹 Multi-Token Prediction → turbo-charged speculative decoding
🔹 Beats Qwen3-32B in perf, rivals Qwen3-235B in reasoning & long-context
🧠 Qwen3-Next-80B-A3B-Instruct approaches our 235B flagship.
🧠 Qwen3-Next-80B-A3B-Thinking outperforms Gemini-2.5-Flash-Thinking.
Try it now: chat.qwen.ai/
Blog: qwen.ai/blog?id=4074cca80393…
Huggingface: huggingface.co/collections/Q…
ModelScope: modelscope.cn/collections/Qw…
Kaggle: kaggle.com/models/qwen-lm/qw…
Alibaba Cloud API: alibabacloud.com/help/en/mod…
6
85
15,907
🤖Now on #KaggleModels!
Learn more: kaggle.com/models/google/gem…
14 Aug 2025
Introducing Gemma 3 270M! 🚀 It sets a new standard for instruction-following in compact models, while being extremely efficient for specialized tasks. developers.googleblog.com/en…
1
4
27
9,651

10 Jul 2025
DevstralがKaggleModelsに入ったのか。
本当にclaude-3.7-sonnetや、Gemini2.5-proなみの性能か気になる。

🤖 Now on #KaggleModels!
Learn more kaggle.com/models/mistral-ai…
4
370
🤖 Now on #KaggleModels!
Learn more kaggle.com/models/mistral-ai…
10 Jul 2025
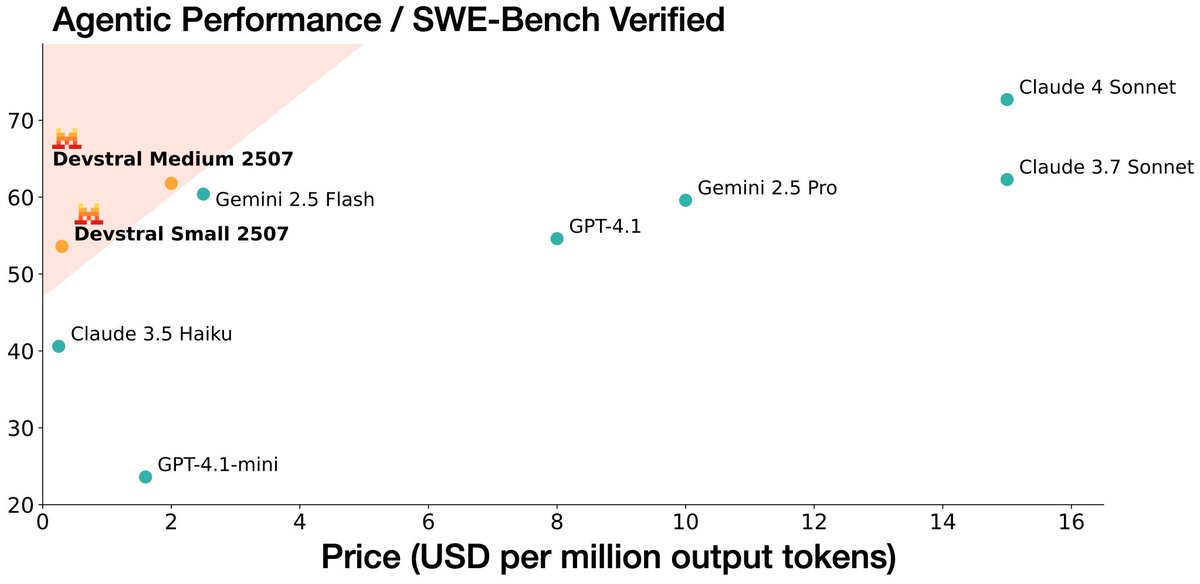
Introducing Devstral Small and Medium 2507! This latest update offers improved performance and cost efficiency, perfectly suited for coding agents and software engineering tasks.
6
54
10,388
🤖 Now on #KaggleModels!
Learn more: kaggle.com/models/google/t5g…
9 Jul 2025
The Gemma family is growing today. First up: T5Gemma ✨, the new generation of encoder-decoder models ↓
developers.googleblog.com/en…
7
72
11,037
10 Jun 2025
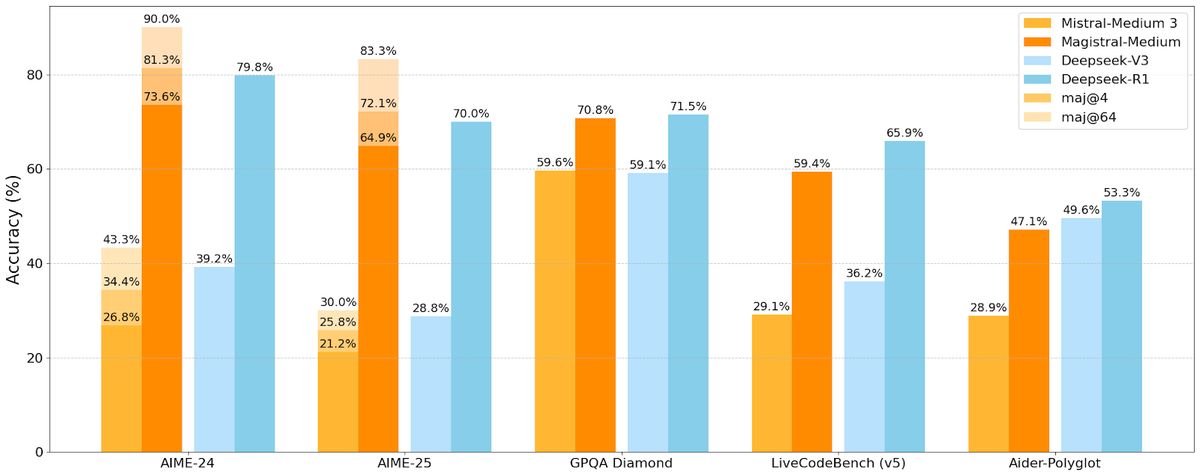
Announcing Magistral, our first reasoning model designed to excel in domain-specific, transparent, and multilingual reasoning.
1
9
85
11,931
🤖 @MistralAI’s Devstral is now on #KaggleModels!
Devstral is a 24B-parameter open model for software engineering tasks - built to support codebase exploration, multi-file edits, and agentic coding workflows.
kaggle.com/models/mistral-ai…
1
4
30
5,726
Now available on #KaggleModels!
Learn more: kaggle.com/models/google/gem…
20 May 2025
✨ Introducing Gemma 3n, available in early preview today.
The model uses a cutting-edge architecture optimized for mobile on-device usage. It brings multimodality, super fast inference, and more.
1
10
54
9,756
🤖 Now on #KaggleModels!
The long-awaited @Alibaba_Qwen's Qwen 3 is here - featuring dense MoE models, trained on 36T tokens across 119 languages. Big gains in reasoning, performance, and long-context (32k tokens) support!
Learn more: kaggle.com/models/qwen-lm/qw…
28 Apr 2025
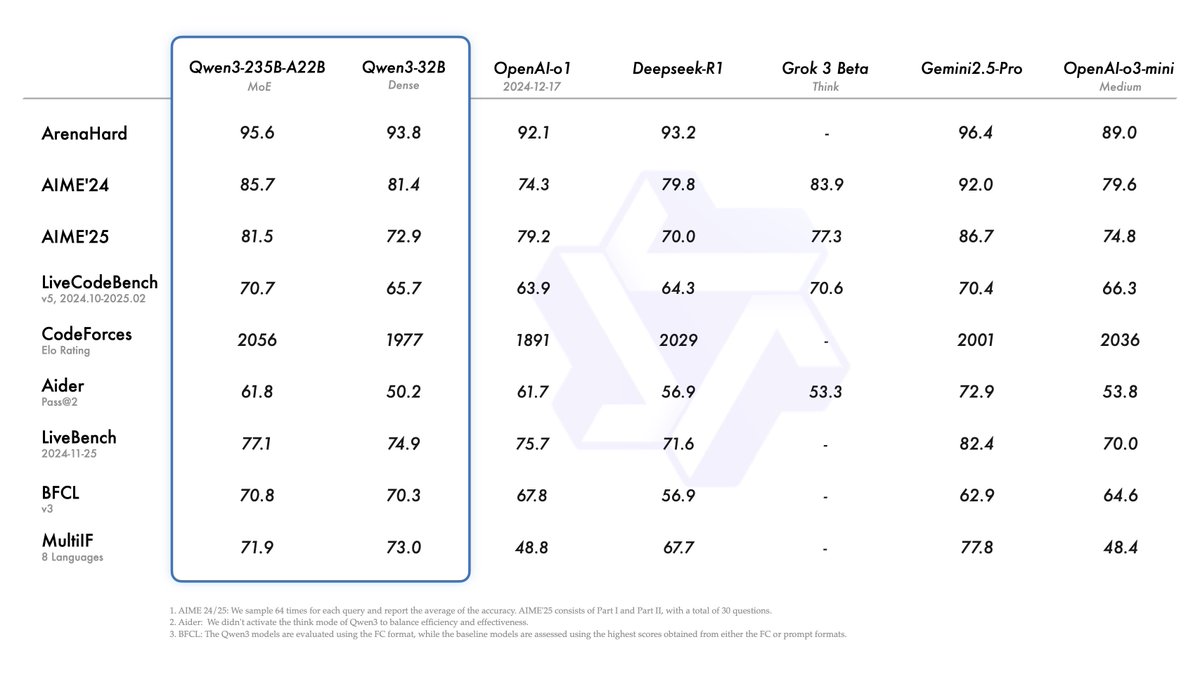
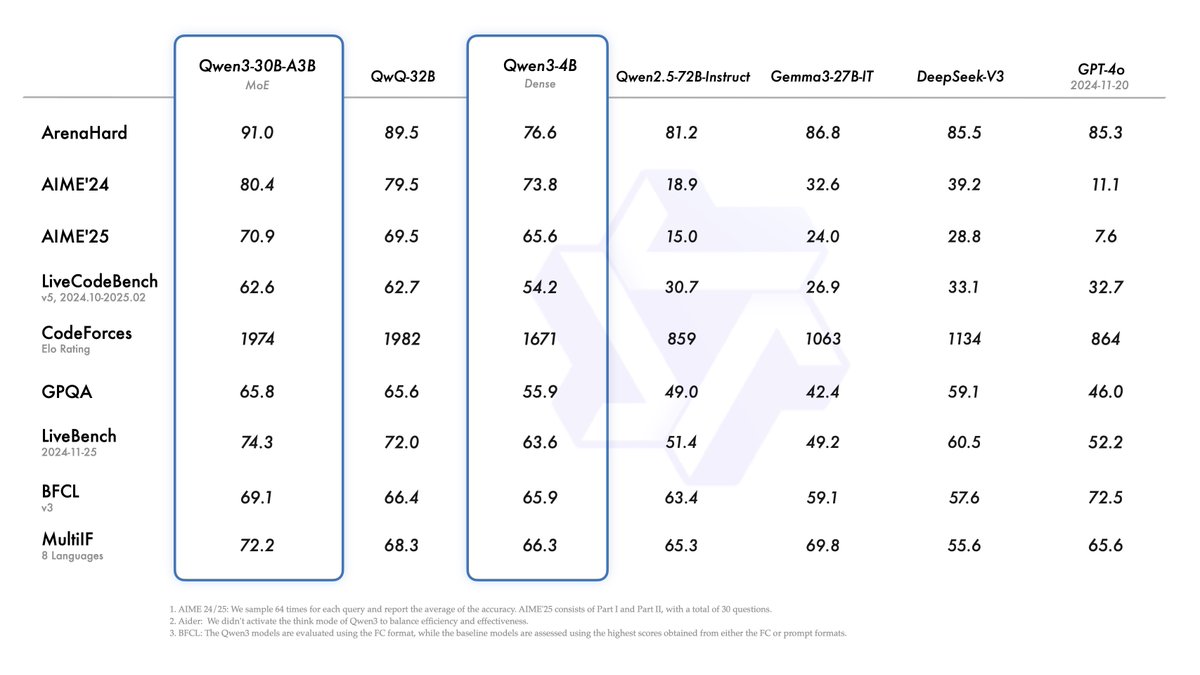
Introducing Qwen3!
We release and open-weight Qwen3, our latest large language models, including 2 MoE models and 6 dense models, ranging from 0.6B to 235B. Our flagship model, Qwen3-235B-A22B, achieves competitive results in benchmark evaluations of coding, math, general capabilities, etc., when compared to other top-tier models such as DeepSeek-R1, o1, o3-mini, Grok-3, and Gemini-2.5-Pro. Additionally, the small MoE model, Qwen3-30B-A3B, outcompetes QwQ-32B with 10 times of activated parameters, and even a tiny model like Qwen3-4B can rival the performance of Qwen2.5-72B-Instruct.
For more information, feel free to try them out in Qwen Chat Web (chat.qwen.ai) and APP and visit our GitHub, HF, ModelScope, etc.
Blog: qwenlm.github.io/blog/qwen3/
GitHub: github.com/QwenLM/Qwen3
Hugging Face: huggingface.co/collections/Q…
ModelScope: modelscope.cn/collections/Qw…
The post-trained models, such as Qwen3-30B-A3B, along with their pre-trained counterparts (e.g., Qwen3-30B-A3B-Base), are now available on platforms like Hugging Face, ModelScope, and Kaggle. For deployment, we recommend using frameworks like SGLang and vLLM. For local usage, tools such as Ollama, LMStudio, MLX, llama.cpp, and KTransformers are highly recommended. These options ensure that users can easily integrate Qwen3 into their workflows, whether in research, development, or production environments.
Hope you enjoy our new models!
4
28
197
31,673
Now available on #KaggleModels!
Learn more: kaggle.com/models/google/gem…
18 Apr 2025
Run Gemma 3 27B on your desktop GPU 🔥
Our new QAT-optimized int4 models slash VRAM needs (54GB -> 14.1GB) while maintaining quality. Now accessible on consumer cards like the NVIDIA RTX 3090 via @ollama, @huggingface, @lmstudio & more.
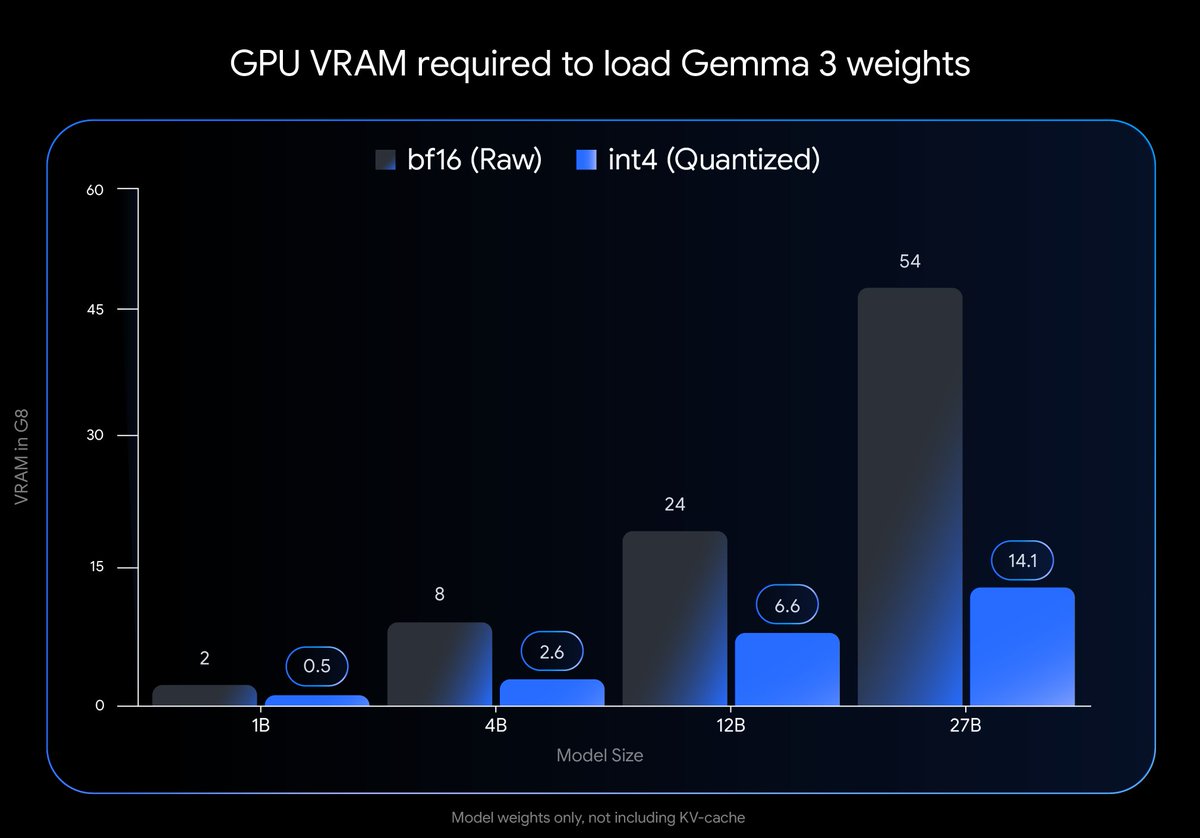
ALT Image shows GPU VRAM required to load Gemma 3 weights
9
61
9,927
🤖 Now available on #KaggleModels!
👉 Learn more: kaggle.com/models/google/gem…
3 Apr 2025

I'm very excited to announce the release of Quantization-Aware Trained (QAT) Gemma 3🚀
🤏3x less VRAM
🔥while retaining almost same quality
🤖use today with llama.cpp and Ollama
Models in huggingface.co/collections/g…
1
3
33
8,831
🤖 @Google’s Gemma 3 and Shield Gemma are now on #KaggleModels!
👉 Gemma 3 kaggle.com/models/google/gem…
👉ShieldGemma 2 kaggle.com/models/google/shi…
12 Mar 2025
Gemma 3 is a collection of lightweight, state-of-the-art open models built from the same research and technology that powers our Gemini 2.0 models. → goo.gle/43Ic5RV
6
34
7,013
🤖 Now on #KaggleModels!
@Alibaba_Qwen's QwQ-32B, a 32B parameter reasoning model, uses Reinforcement Learning to enhance tasks like math, coding, and problem-solving, ensuring high performance and accuracy.
Check it out here 👇
kaggle.com/models/qwen-lm/qw…
2
8
76
6,325
🤖 @CohereForAI’s Aya Vision is now available on #KaggleModels
👉 Learn more: kaggle.com/models/coherefora…
4 Mar 2025

Introducing ✨ Aya Vision ✨ - an open-weights model to connect our world through language and vision
Aya Vision adds breakthrough multimodal capabilities to our state-of-the-art multilingual 8B and 32B models. 🌿
2
13
65
11,536
🤖PaliGemma 2 mix is now on #KaggleModels!
Learn more: kaggle.com/models/google/pal…
19 Feb 2025
PaliGemma 2 mix is an upgraded vision-language model that supports image captioning, OCR, image Q&A, object detection, and segmentation. With sizes from 3B-28B parameters, there's a model for everyone. Get started. → goo.gle/430HnDe

ALT The text "PaliGemma 2 mix" is centered on a dark background with smaller images and text snippets surrounding it, showcasing examples of image captioning and location identification.
1
2
30
7,255
🤖 Now on #KaggleModels!
@MistralAI’s Small 3 is the newest open-weight model under 70B, built for efficiency and versatility. Ideal for conversational AI, robotics, and low-latency tasks, it packs powerful performance into a compact size.
Learn more: kaggle.com/models/mistral-ai…
1
4
25
6,134
30 Jan 2025
Introducing Small 3, our most efficient and versatile model yet! Pre-trained and instructed version, Apache 2.0, 24B, 81% MMLU, 150 tok/s. No synthetic data so great base for anything reasoning - happy building!
mistral.ai/news/mistral-smal…
1
9
39
12,347
🤖 Now on #KaggleModels!
@deepseek_ai's Janus-Pro is a unified MLLM for multimodal understanding and generation, built on DeepSeek-LLM-1.5b/7b-base. It uses SigLIP-L for vision encoding, supporting 384x384 images, optimized for image generation.
kaggle.com/models/deepseek-a…
2
5
32
6,340