
May 13
تخيّل أن تُلقي بكتابٍ كامل في الآلة، فتُخرجه لك خريطةً مرئية: كلّ مفهوم نقطة، وكلّ علاقة بين مفهومين خطّ. ما كان مدفونًا في ٤٠٠ صفحة يصبح لوحةً واحدة، تتجوّل فيها بإصبعك.
هذا ما يفعله مستودع «knowledge_graph» على GitHub لراهول نياك. أداة بايثون مفتوحة المصدر، تشتغل محليًّا على حاسوبك دون GPT ولا مفاتيح API، تحوّل أيّ نصّ — كتابًا، مقالًا، أرشيف تغريداتك على إكس، رسالة دكتوراه — إلى رسم بياني للمعرفة (Knowledge Graph).
من يستفيد منها؟
• الباحث الذي يقرأ مرجعًا ضخمًا ويريد أن يرى بنيته قبل أن يكتب.
• الكاتب الذي راكم آلاف الملاحظات ولا يجد ما يربطها.
• طالب الفلسفة الذي يحاول استيعاب «الوجود والزمان» بنظرة كلية.
• صاحب الحساب الذي راكم خمس سنوات من المنشورات ويريد أن يرى نمط تفكيره كخريطة.
• كلّ من يريد أن يُحاور كتبه عبر Graph RAG — استرجاع أعمق من ذلك القائم على البحث المتّجهي وحده.
الفكرة في جوهرها بسيطة: المعرفة شبكة لا قائمة. الكتب تُكتب خطّيًا لأنّ اللغة خطّية، لكنّها في الذهن تنتظم بنيةً متشعّبة. هذه الأداة تُعيد للنصّ صورته كما هو في رأس قارئه الجيّد.
github.com/rahulnyk/knowledg…

50
333
14,798

Apr 20
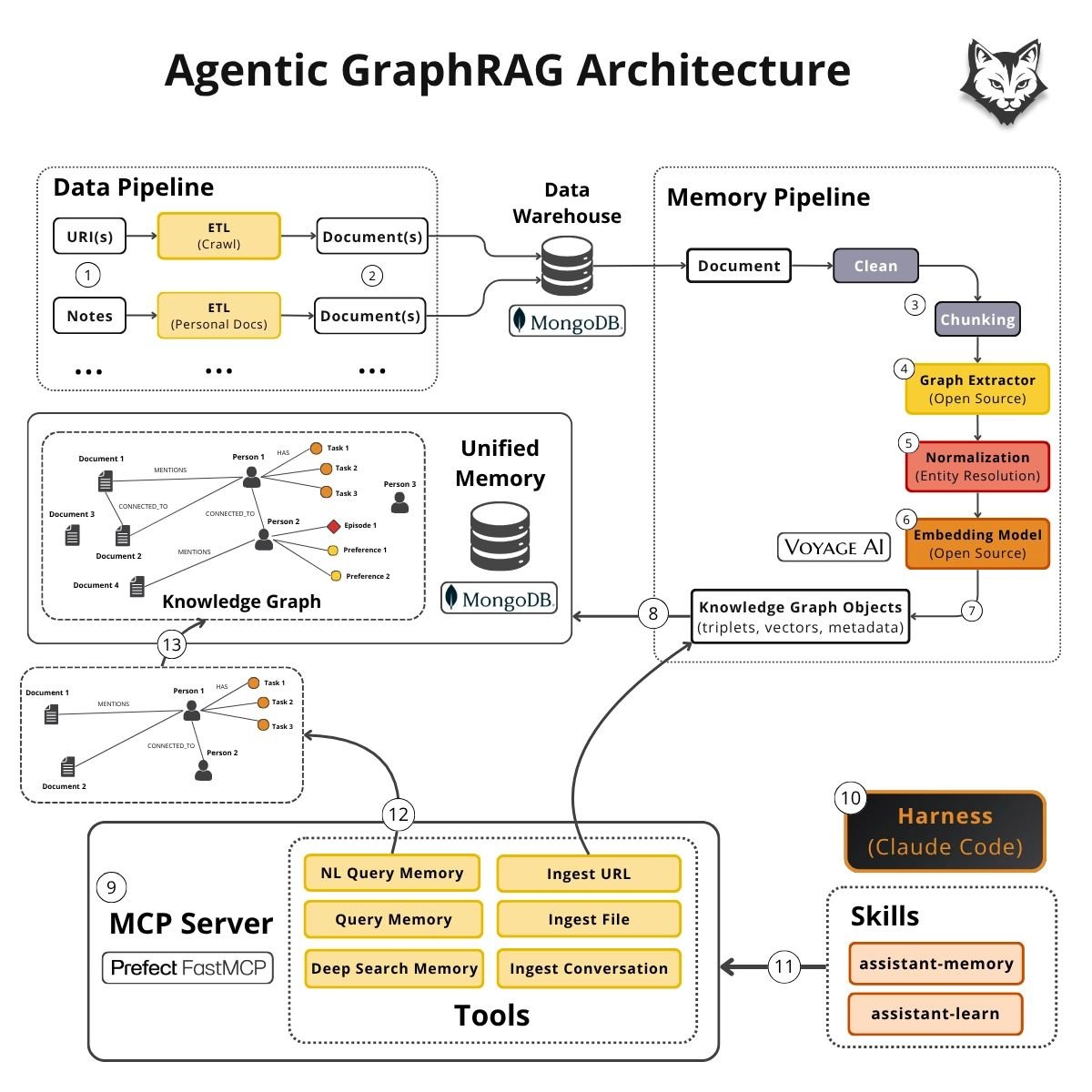
The Simplified GraphRAG Stack: Unified Memory Over Fragmented Databases
"Building a Graph RAG System without a Graph Database" sounds like a contradiction in terms.
Recently, an architecture for implementing Graph RAG without a graph database emerged. Store entities, relations, and passages in 3 Milvus collections linked by IDs. Graph traversal becomes ID lookups. No Cypher. No separate infrastructure.
Now a similar principle appears again, but with MongoDB as the unified memory layer instead of Milvus.
The pattern: consolidate all memory - documents, vectors, and graph links - into a single system. Stop fragmenting knowledge across databases.
Here's how it materializes with MongoDB:
The ingestion layer pulls data from URIs, notes, emails, docs. Normalized into a single schema in MongoDB. Raw documents stored durably.
The memory pipeline processes each document: Clean text metadata. Graph extraction (entities relationships). Normalization (merge "Abi" vs "Abi Aryan").
Embeddings with Voyage AI. Output: knowledge graph objects with triplets, vectors, and metadata.
The unified layer lives in a single knowledge_graph collection with three index types working in parallel: Text index for keyword recall.
Vector index for semantic recall. Graph links for multi-hop traversal. All in one place.
Retrieval happens through an MCP server exposing GraphRAG as tools. Natural language query for compact retrieval. Deep search for progressive graph expansion. Ingest for new data.
The agent layer (Claude Code) orchestrates reasoning. It decides when to retrieve, when to write memory, when to expand context via graph traversal (2-3 hops).
Skills bridge the gap: Assistant-memory harnesses semantic retrieval. Assistant-learn pushes insights back to memory.
Two independent architects, two database choices, one architectural insight: simplification beats infrastructure sprawl.
Unified memory is the flywheel. Everything else—retrieval, traversal, reasoning—becomes faster and cheaper when you stop syncing multiple systems.
The emerging pattern: whether Milvus, MongoDB, or something else, the question is not "which database?" It is "can we consolidate graph, vector, and document memory in one coherent layer?"
linkedin.com/posts/pauliuszt…
#GraphRAG #UnifiedMemory #MongoDB #AgenticAI #VectorSearch #AIArchitecture
--
📩 The Year of the Graph Spring 2026 newsletter issue is out!
Beyond Context Graphs: How Ontology, Semantics, and Knowledge Graphs Define Context 👇
yearofthegraph.xyz/newslette…
All things #KnowledgeGraph, #GraphDB, Graph #Analytics / #DataScience / #AI and #SemTech.
Subscribe and follow to be in the know. Reach out if you'd like to be featured
7
60
242
9,774

Apr 17
I’ve spent the past year building GraphRAG systems from scratch.
Here’s the architecture I keep coming back to (steal it)…
@MongoDB is the unified memory.
@VoyageAI by MongoDB for embeddings.
Agent on top.
Here's how the end-to-end flow looks:
1–2 / Ingestion → Data warehouse
Pull data from URIs, notes, emails, docs.
Normalize into a single document schema and store in @MongoDB
Example: emails, research notes, and meeting transcripts become raw_documents.
This is the durable ingestion layer.
3–7 / Memory pipeline
Each document flows through:
• Clean text metadata
• Chunk (optional)
• Graph extraction (entities relationships)
• Normalization (merge duplicates like “Abi” vs “Abi Aryan”)
• Embeddings with @VoyageAI
Output: knowledge graph objects with triplets, vectors, and metadata.
8 / Unified memory in @MongoDB
Materialize into a knowledge_graph collection with entities and relationships as documents.
Indexes:
• Text index → keyword recall
• Vector index → semantic recall
• Graph links → multi-hop traversal
Documents, vectors, and graph memory in one place.
9 / MCP server
Expose GraphRAG through tools:
• NL query → compact high-level retrieval
• Deep search → progressive graph expansion
• Ingest → URLs, files, conversations
10 / Harness
Claude Code orchestrates reasoning and tool usage.
It decides when to retrieve vs write memory.
11 / Skills
Skills define interaction with GraphRAG:
• Assistant-memory → harness to MCP bridge
• Assistant-learn → push insights back to memory
12–13 / Agentic GraphRAG
The agent selects tools dynamically.
Semantic text search retrieves entry nodes.
Graph traversal (2–3 hops) expands context.
Example: "Create GraphRAG talk for O’Reilly"
→ Retrieve GraphRAG O’Reilly
→ Expand to past talks and preferences
→ Return structured context
@MongoDB stores evolving graph memory.
@VoyageAI by MongoDB powers semantic recall. Agents turn retrieval into reasoning.
One unified memory layer. One ingestion and retrieval pipeline. One agent loop.
P.S. Are you building GraphRAG with a unified memory layer, or still splitting vectors, graphs, and documents across multiple databases?

1
3
172

Mar 20
LangChain gave me a knowledge graph in 10 minutes.
But I couldn't use it in production. Here's why...
I started with LangChain’s MongoDBGraphStore.
A few minutes later, I had a working knowledge graph stored in @MongoDB
@MongoDB acts as the unified memory layer for my assistant because it supports:
• Text search
• Vector search (Voyage embeddings reranking)
• Graph traversal using $graphLookup
At first glance, everything looked fine.
Then I inspected the data model.
From just 5 documents, the LLM produced:
• 17 node types
• 34 relationship types
Including variations like:
• part_of
• Part Of
• part of
3 relationship types for the same concept.
This was just one of many inconsistencies.
It also didn’t support embeddings or vector indexes.
And relationships were stored as arrays in entity documents.
Which meant:
• Detecting duplicate edges was nearly impossible
• Updating relationships required rewriting the entity
• Tracing each chunk’s source document wasn’t possible due to limited metadata
• Versioning evolving entities wasn’t possible
The problem was the data model.
Most GraphRAG tutorials jump straight to:
• Entity extraction
• Embeddings
• Retrieval pipelines
…but skip the ontology.
Without an ontology, LLM extraction is unconstrained.
Models invent new entities, relationships, and naming across documents.
So instead, I designed the ontology first.
This system uses 6 node types and 8 edge types with strict constraints.
Example: PERSON → TASK uses the TODO edge.
If the model outputs: PERSON → TASK with EXPERIENCED
…it gets rejected.
Because EXPERIENCED must be: PERSON → EPISODE.
Once the ontology exists, extraction becomes predictable.
Two strategies handle it:
1/ LLM extraction
Entities:
• Person
• Task
• Episode
• Preference
Relationships:
• TODO
• EXPERIENCED
• RELATED_TO
2/ Deterministic extraction
Structural nodes and edges:
• Document
• Chunk
Relationships:
• MENTIONS
• PART_OF
• NEXT
These come directly from the ingestion pipeline.
The storage layer becomes:
• documents → raw content
• knowledge_graph_log → immutable observations
• knowledge_graph → materialized graph built with @MongoDB aggregation
This enables:
• Scalable duplicate detection and normalization
• Ontology-based extraction (so costs don’t explode)
• Metadata control for retrieval
• Unified graph vector search
Embeddings are computed after materialization, so vectors represent the full entity.
Without control over the data model, GraphRAG breaks down quickly.
Out-of-the-box extractors look impressive in demos…
…but they produce noisy graphs and systems that cannot run in production.
LangChain is great for prototypes.
But production GraphRAG usually requires building ingestion and retrieval pipelines.
Takeaway:
GraphRAG looks like a retrieval problem.
But most of the time, it’s a data modeling problem.
P.S. Do you treat GraphRAG as a retrieval problem or a data modeling problem?
2
1
2
133

27 Aug 2025
Read #Paper "Domain-Specific Dictionary between Human and Machine Languages" by Md Saiful Islam, and Fei Liu.
See more details at:
mdpi.com/2078-2489/15/3/144
#knowledge_graph #medicine_dictionary
@ComSciMath_Mdpi

1
2
59


20 Aug 2025
<META> type:generate lang:ja model:agentic-rag </META>
<DEF>
T = 調査テーマ # Topic
QL = 検索クエリ集合 (≤15) # Query_List
RDB= 情報 メタ情報リスト # Results_DB
KG = 概念グラフ # Knowledge_Graph
RP = 最終レポート # Report
Q = {cmp,acc,coh,cite,read,act} # Quality 指標
TAGS={planning,intent,search_strategy,knowledge_graph,search,results,information_analysis,context_analysis,self_reflection,search_refinement,specialized_search,integration,cross_references,conflicts,knowledge_synthesis,knowledge_gaps,final_verification,fact_checking,logical_consistency,citation_preparation,report_structure,audience_adaptation,report_generation,executive_summary,detailed_findings,supporting_evidence,citations,visualizations,quality_assessment,self_evaluation,deep_analysis,pdf_analysis,image_interpretation,data_visualization,domain_adaptation,memory_management,iterative_learning}
</DEF>
<TASK> T を深く調査し、QL→RDB→KG を経て RP を生成せよ。
T: [ユーザーが入力]
</TASK>
<LOGIC>
Step1 planning{
intent{}; # 目的・範囲
search_strategy{QL←gen(T)}; # クエリ設計
knowledge_graph{KG←init(T)} # 初期KG
}
Step2 for q∈QL{ # 反復検索
search{q}; results{RDB⊕=info(q)}; # 収集
information_analysis{analyse(RDB,q,KG)}; # 評価&KG更新
self_reflection{adj?→search_refinement} # 自己調整
if need→specialized_search{} # 特殊ソース
}
Step3 integration{
cross_references{}; conflicts{}; # 統合&矛盾解決
knowledge_synthesis{}; knowledge_gaps{} # 洞察 ギャップ
}
Step4 report_structure{audience_adaptation{}; sections; format}
Step5 report_generation{
executive_summary; detailed_findings; supporting_evidence;
citations; visualizations → RP
}
Step6 quality_assessment{∀k∈Q: score(k,RP)}
Step7 self_evaluation{process_strengths; process_weaknesses; learning_points;
iterative_learning}
Step8 answer{O=RP}
</LOGIC>
1
8
116
12,978

9 Mar 2025
An Intelligent Hand-Assisted Diagnosis System Based on Information Fusion
mdpi.com/1424-8220/24/14/474…
#computer_vision #knowledge_graph

2
56

6 Jan 2025
#Callforreading
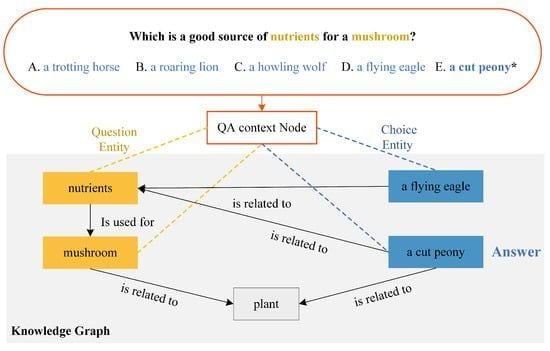
📝 Retrieval-Augmented #Knowledge_Graph Reasoning for #Commonsense_Question_Answering
✍️ by Prof. Yimu Ji et al.
📌 buff.ly/3PkdSnS
#Natural_language_processing;
#Linguistics
@MDPIOpenAccess @ComSciMath_Mdpi
3
3
93

20 Oct 2023
Many thanks for the invitation, @MarshallXMa! Look forward to sharing our research in #knowledge_graph and #geovisualization with @ESIPfed colleagues. @YuanyuantianG
20 Oct 2023

Bookmark your calendar! On 11/15/2023 2PM ET @WenwenLi_ and Yuanyuan Tian will give a talk about the KnowWhere #KnowlegeGraph via the invitation of @ESIPfed find zoom link at ESIPFED.ORG/COMMUNITY-CALEND…

1
5
700

21 Aug 2023
📚 Machine Learning Meets the Semantic Web
👉 This paper presents how Machine Learning (ML) meets the Semantic Web and how KGs are related to Neural Networks and Deep Learning.
#Knowledge_graph #Semantic_web #Ontology #Deep_learning
🔗 DOI: doi.org/10.30564/aia.v3i1.31…

1
2
59

27 Jul 2022
How we can learn more about the world around us by looking at the relationships between words and concepts. 🧵
Personal knowledge management tools allow anyone to build their own #knowledge_graph.
These tools include @RoamResearch @obsdmd and @NotionHQ 1/3

2
3
11

17 Jun 2022
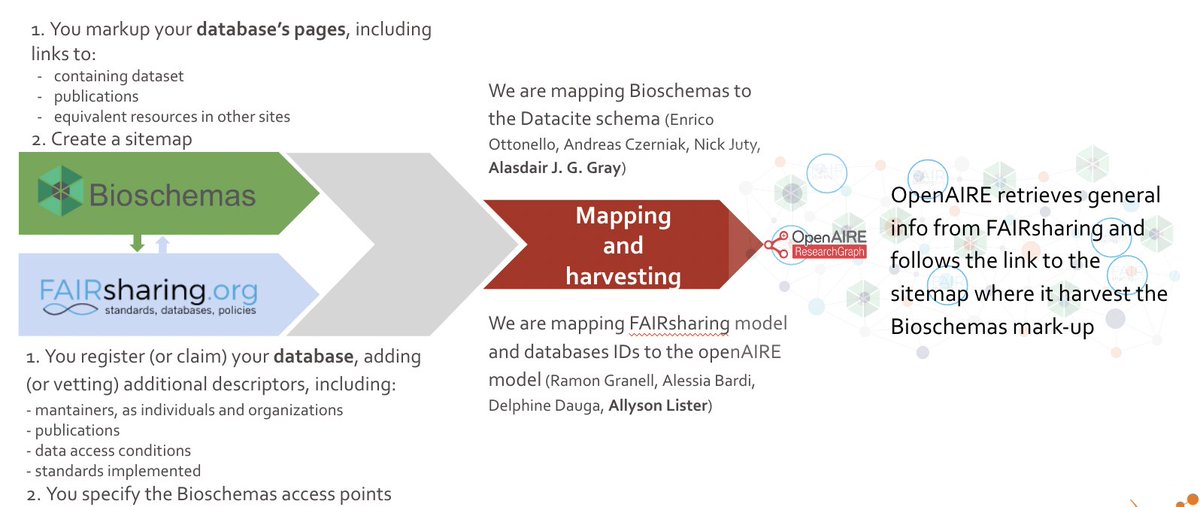
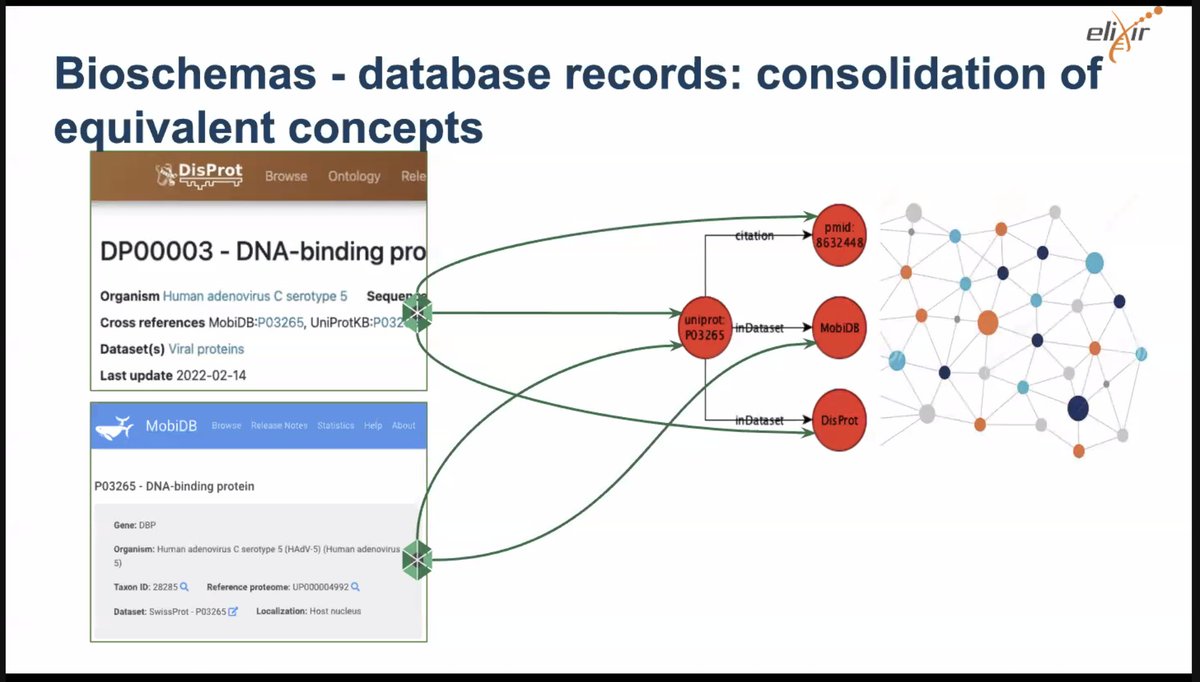
Using @BioSchemas and @FAIRsharing_org to feed the @OpenAIRE_eu #knowledge_graph being presented by @SusannaASansone during the @AlanTuringInsti #KG #meetup
6
18

Do you wanna learn the fundamental concepts about #schema markups?
How to create them connect them and form a #Knowledge_Graph?
How to connect entities including how to connect with #Yoast #SEO schema?
How to deploy them using #GTM?
Watch this 20 min. Video
#schemantra
16 May 2022

here is our first semantic #SEO workshop:
-How to create a schema markup
-build a knowledge graph for a car as per schema org
-Semantic integration with a car dealership
-How to install markups using GTM
-for more videos please like and subscribe
youtu.be/rO5iSUOQa5Q
1
6

29 Apr 2022
A paper shows an #ML to #automate #knowledge_discovery with #knowledge_graph, #inconsistency_resolution and #iterative_link_prediction, per Nat Comput Sc today. An #Escherichia_coli #antibiotic_resistance KG was built with 651,758 triples, after resolving 236 #inconsistency sets.
2
5

27 Oct 2020
✓ #Advertools' knowledge_graph()" function, 849 used.
✓ @eliasdabbas used 2000 words for criticizing the article.
✓ I have used 1000 more words for revising it.
✓ 11 hours spent.
Entities, Knowledge Graphs, and NLP for #SEO.
Some NLTK Facts below..
holisticseo.digital/python-s…
2
4
24

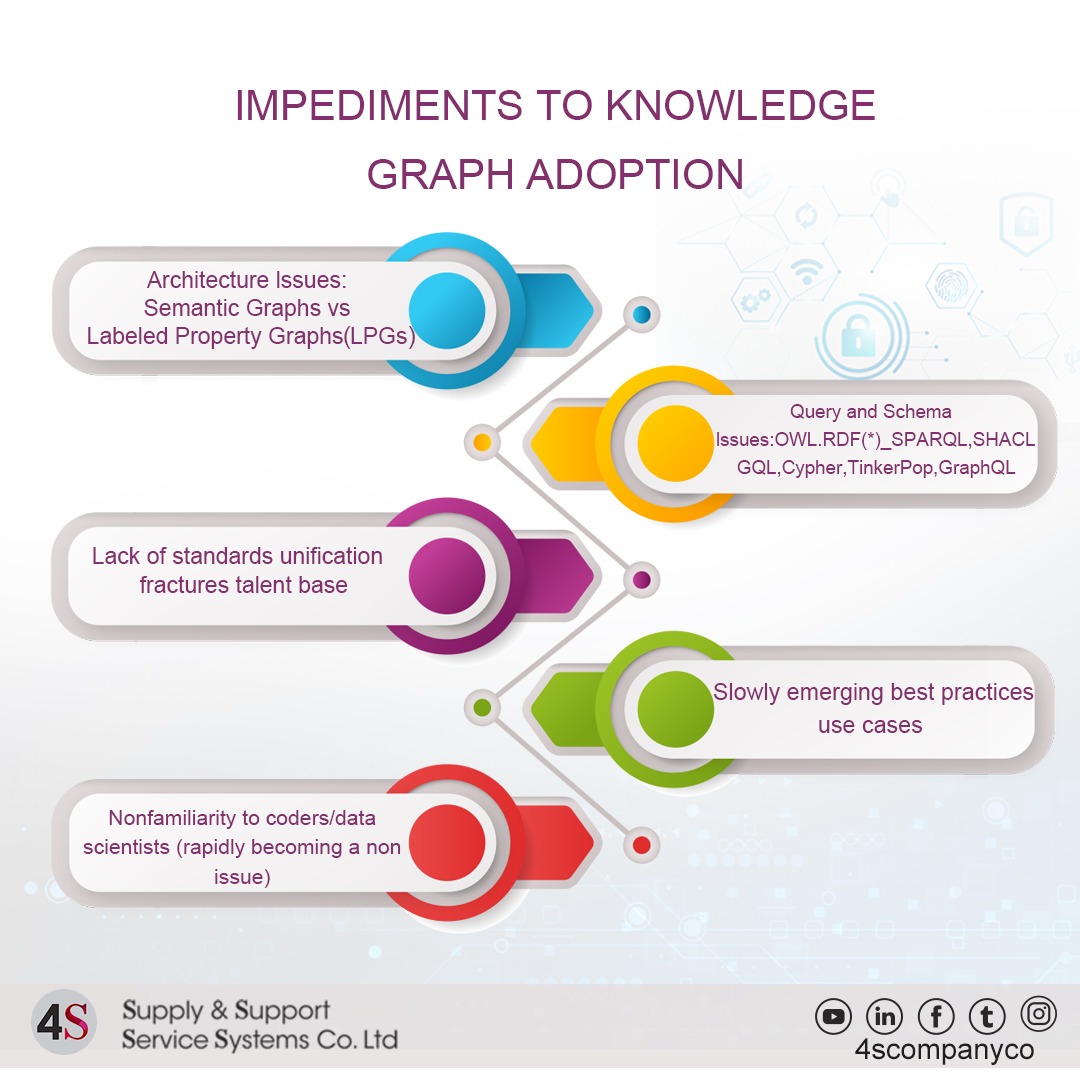
Impediments to #knowledge_graph adoption:
Website: 4s.net.sa
Whatsapp: wa.me/966138653872
#القمةالعالميةللذكاء_الاصطناعي
#القمة_العالمية_للذكاء_الاصطناعي
#GlobalAISummit
2

20 Oct 2020
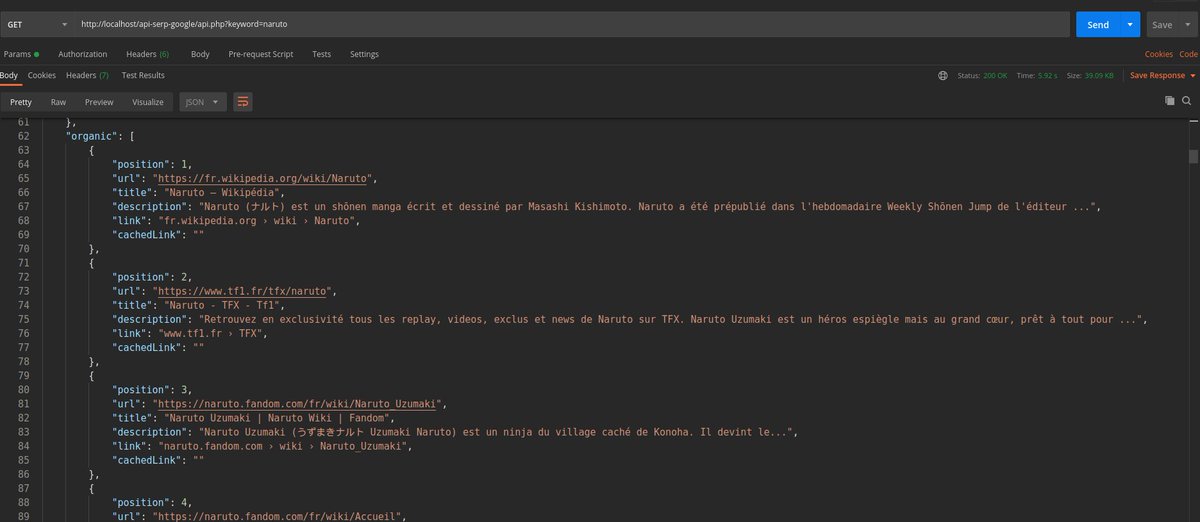
🆕 Depot Github sur une simple API Json pour scraper les résultats Google knowledge_graph ... Facile à utiliser :D
github.com/drogbadvc/api-ser…

1
4
11

18 Sep 2020
2/4
New function: knowledge_graph
- Query Google's Knowledge Graph API
- Multiple queries, across multiple languages or IDs in one call
- Full data (type, URL, images, etc.)
Details here:
advertools.readthedocs.io/en…
Thanks for the Inspiration @KorayGubur (expect his tutorial soon)
2
1
11