
Langsmith transforms LLM debugging from guesswork to traceable replay. Integrate evaluation early to ship reliable agents faster. #Langsmith #LLMDev
9

Unlock the power of LangChain! 🚀 My new video dives deep into VectorStores, Chains, Agents & Memory to help you build advanced LLM apps.
#LangChain #LLMDev #AITutorial youtu.be/PbzYJfubFJs?si=uaQK… via @YouTube
1
16


>assume they are currently doing their best
That's explicitly the problem, I can't; they just told me "we're openly admitting we plan quiet sabotage of LLMdev uses"
I want to trust my model fights for me in typical circumstances, and probably will be switching over to codex.

1
25
933


Mar 12
Most developers are still coding like it's 2020. The ones building $10K MRR SaaS products in 30 days aren't working harder, they've changed their entire stack.
Here are 10 agentic tools & frameworks dominating 2026:
→ Build full-stack SaaS without writing boilerplate
→ Ship production-ready apps at the speed of thought
→ Automate the parts that used to take weeks
What are the best tools for vibe coding in 2026? How do developers build SaaS products faster with AI agents?
This post answers both, in 60 seconds. 🧵
Which tool in your stack has 10x'd your shipping speed the most? Drop it below
#foundontropical #VibeCoding #AgenticAI #AITools #SaaSBuilder #BuildInPublic #AIAgents #NoCode #LLMDev #StartupTools #AIAutomation #ProductivityHacks #FutureOfCoding #AIStartup

1
5
5
76

Mar 3
Langflow gives you the building blocks to design that system visually, but without losing engineering control.
Start with real foundations:
🔹 API Integration
Connect external services directly into your flows. Turn APIs into callable tools inside your agent architecture.
🔹Agent
Combine prompts tools reasoning into decision-making agents that can act, not just respond.
🔹 Basic Prompting
Prototype fast. Iterate visually. Refine behavior without rewriting everything.
🔹 Doc Assistant (RAG)
Build assistants that retrieve precise information from large knowledge bases, grounding responses in real data.
And when you need more control? There’s Python under the hood.
Langflow isn’t just about building flows. It’s about designing modular, extensible AI systems that can evolve from prototype to production.
Build visually. Think architecturally. Scale confidently.
Learn more about Langflow: langflow.org/?utm_source=x&u…
#Langflow #AIEngineering #Agents #LLMDev #OpenSourceAI

1
1
6
609

Jan 31
Generic LLMs shine in demos.
They struggle in production.
The difference isn’t the model.
It’s the context you give it.
In real systems:
Context > Parameters.
#ContextEngineering #LLMDev #AIEngineering #BuildInPublic #Deskree
1
18
8,619
Jan 28
If your AI answers feel generic…
You don’t have a model problem.
You have a context problem.
#ContextEngineering #BuildInPublic #AIEngineering #LLMDev #DevTools #AICopilot #SoftwareEngineering
1
10
293

Cloud LLMs are great until you need privacy, speed & scale.
In this 🔥 deep dive, Kinfey Lo shows how he built a local-first, multi-agent podcast studio powered by:
🧠 Agentic orchestration
🧰 Local SLMs (Qwen-3-8B)
🗣️ Voice synthesis
techcommunity.microsoft.com/… #EdgeAI #LLMdev

ALT Engineering a Local-First Agentic Podcast Studio: A Deep Dive into Multi-Agent Orchestration
1
2
334

Your agent uses GPT-4 to reason
Claude to write
Nice ✨
Until GPT learns a user preference
and Claude forgets it 5 minutes later 🤦♂️
This is the Cross-LLM Memory Barrier.
Why should an agent’s brain be siloed by model?
memU = one persistent memory
works across any LLM
one brain, many models
no brittle middleware
Consistent agents, finally.
#AgenticAI #LLMDev #OpenSource

4
1
7
222
🚀 AI needs memory — and we’re building it together.
We’re launching the memU Ambassador Program 🌍
For devs, creators, and community leaders shaping the future of Agentic AI & persistent memory.
What you can do:
🧠 Contribute code
✍️ Create content
🎤 Host events
🌏 Lead your region
What you get:
✨ Early feature access
🤝 Direct line to the core team
🏆 Public recognition Ambassador swag
If you believe AI should remember, not just respond — join us 👇
👉 Apply: forms.gle/GbGJPfktHkToC1PW6
#AgenticAI #AIMemory #LLMDev

5
14
1,034

4 Dec 2025
Building AI apps shouldn’t feel like stitching a dozen APIs together.
Routing, load balancing, multi-model support, RAG, workflows devs need one place where everything just works.
That’s why @miranetwork is a game-changer: one unified SDK to manage models, build flows, integrate knowledge, and scale AI systems without the chaos.
The AI stack is finally becoming simple, powerful, and developer-first. ⚡🐍
#MiraNetwork #MiraFlows #AIInfra #LLMDev #PythonSDK #AIDevelopment #RAG #AIWorkflows #AgenticAI #DevTools @wallchain

2
2
69

28 Nov 2025
Last week my custom T5-style model was collapsing gibberish outputs and endless CUDA crashes.
Instead of starting over, I spent days dissecting Google’s Gemma codebase.
What I found changed everything. Thread
Gemma-27B is not just another model it’s a masterclass in disciplined engineering. Its custom T5-derived design, RoPE implementation, and memory discipline are surgical.
I kept my original multi-billion parameter vision but deliberately incorporated every architectural insight that aligned with a clean from-scratch codebase.
Outcome → complete ground-up rewrite. Zero copy-paste. Every line remains mine:
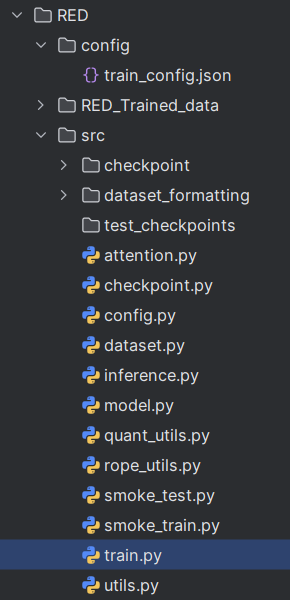
- attention.py – custom attention block with shared QKV projection, RoPE, and RMSNorm inspired by Gemma’s patterns
- rope_utils.py – positional embeddings derived directly from the original math
- quant_utils.py – 4-bit & 8-bit kernels written from first principles and whitepapers
Training and file structure now follow DeepSeek’s ESFT philosophy:
- Strict separation: config → dataset → model → train/inference API
- train.py mirrors DeepSeek’s trainer pattern (hooks, resume logic, clean eval loop)
- Entire layout designed for future distributed scaling without refactoring
Current status (honest):
Still chasing NaNs in the hybrid attention backward pass beyond 4096 tokens.
Masking logic and gradient flow are the remaining culprits.
Next 48 h: lock down correct causal padding masks, then push sequence length hard.
Key lesson:
Sometimes the most valuable techniques aren’t hidden in the latest 1T monster they live quietly in the overlooked 27B gems that few bother to study line-by-line. All is100 % custom-written, and battle-tested and will be code will be public soon
AT :- github.com/RedAILabs/RED
Which lesser-hyped model taught you the most when you actually read its source? Reply I read every one.
Full technical write-up on LinkedIn (link in bio).
#LLMDev #BuildingInPublic #PyTorch #ProjectRedLinkedIn

4
64

27 Nov 2025
Bringing together the best of both worlds: transformers and classical gradient boosting.
Problem: Relying solely on transformer architectures can be inefficient, especially at inference time, and often lacks transparency.
Solution: Use transformers to encode semantic meaning, then leverage XGBoost to classify achieving strong results with lower latency and better interpretability.
Deep dive here: betaflow.substack.com/p/tran…
If you want thoughtful, applied AI insights, follow me.
And if you want to learn more about how to apply AI to grow your business as a Tech Entrepreneur join my X community (AI for Entrepreneurs) x.com/i/communities/19918901…
#AI #ML #LLM #LLMDev #AIData #StartupAI
2
74

18 Nov 2025
Ever watched your AI agent get stuck in an endless back-and-forth? 🤔
Answering the same question 3 different ways?
Or chatting forever because the user went off the rails? 🙈
Yeah… that’s a sign your agent needs to know when to stop. 🙅
In my new video I show how to add Model Call Limits in LangChainJS — a tiny middleware that makes your agent fail gracefully and escalate to a human at the right moment.
If you’re building support or helpdesk agents, this is a game-changer.
🎥 Watch here: youtube.com/watch?v=x5jLQTFX…
#LangChain #AIagents #AIengineering #TypeScript #LLMDev

ALT Stop Endless Back-and-Forth with ModellCallLimitMiddleware
1
6
24
5,809


19 Oct 2025
Love when Claude-4-Sonnet “fixes” the bug, completely ignores the failing unit tests in the code, and proudly calls it done.
Like… bro, the red tests are right there. Guess I’ll prompt you 3 more times until you acknowledge reality.
#buildinpublic #LLMdev
2
10
240

18 Oct 2025
🚀 Challenge: Test Your LangChain V1 Skills!
To test your @langchain V1 knowledge, convert a LangGraph workflow into a full AI agent using Middleware.
Why? Middleware offers powerful control over agent behavior, like dynamic model routing, custom error handling, or HITL checks, without rebuilding from scratch. It's ideal for production-ready agents.
#LangChain #LangGraph #AIAgents #LLMDev
1
2
81

24 Aug 2025
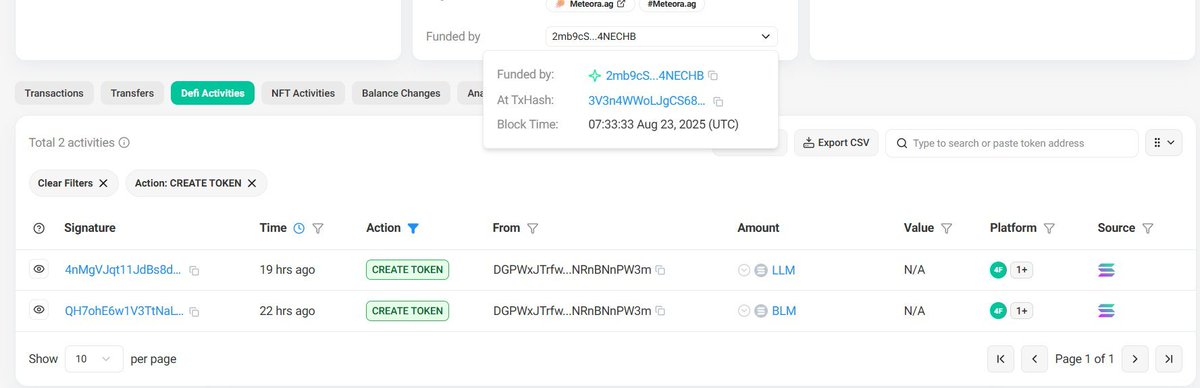
创始人明牌支持 , 鲍威尔那么大的叙事
llmdev亲自部署 你们在波个啥???

1
1
710