
Jun 8
【#Tech24H】At the 4th China Digital Earth Conference, the "#Langya" Ocean #LargeModel version 2.0, a global ocean phenomena intelligent forecasting model, was officially released. Langya 2.0 expands from forecasting ocean state variables to intelligent forecasting of complex ocean phenomena. It can more accurately capture rapidly intensifying typhoons and those with sudden changes in track, improving 24-hour path and intensity forecasting capabilities. Around six key phenomena — typhoons, precipitation, storm surges, internal solitary waves, mesoscale eddies, and sea ice — the research team developed six dedicated models, building a multi-scenario, systematic prediction capability. The release of Langya 2.0 moves ocean forecasting from specialized variables to scenarios for practical perception, application, and decision-making , providing new intelligent support for marine disaster prevention and mitigation, shipping safety, polar navigation support, and global climate change response.
en.youth.cn/RightNow/202606/…

1
23

May 11
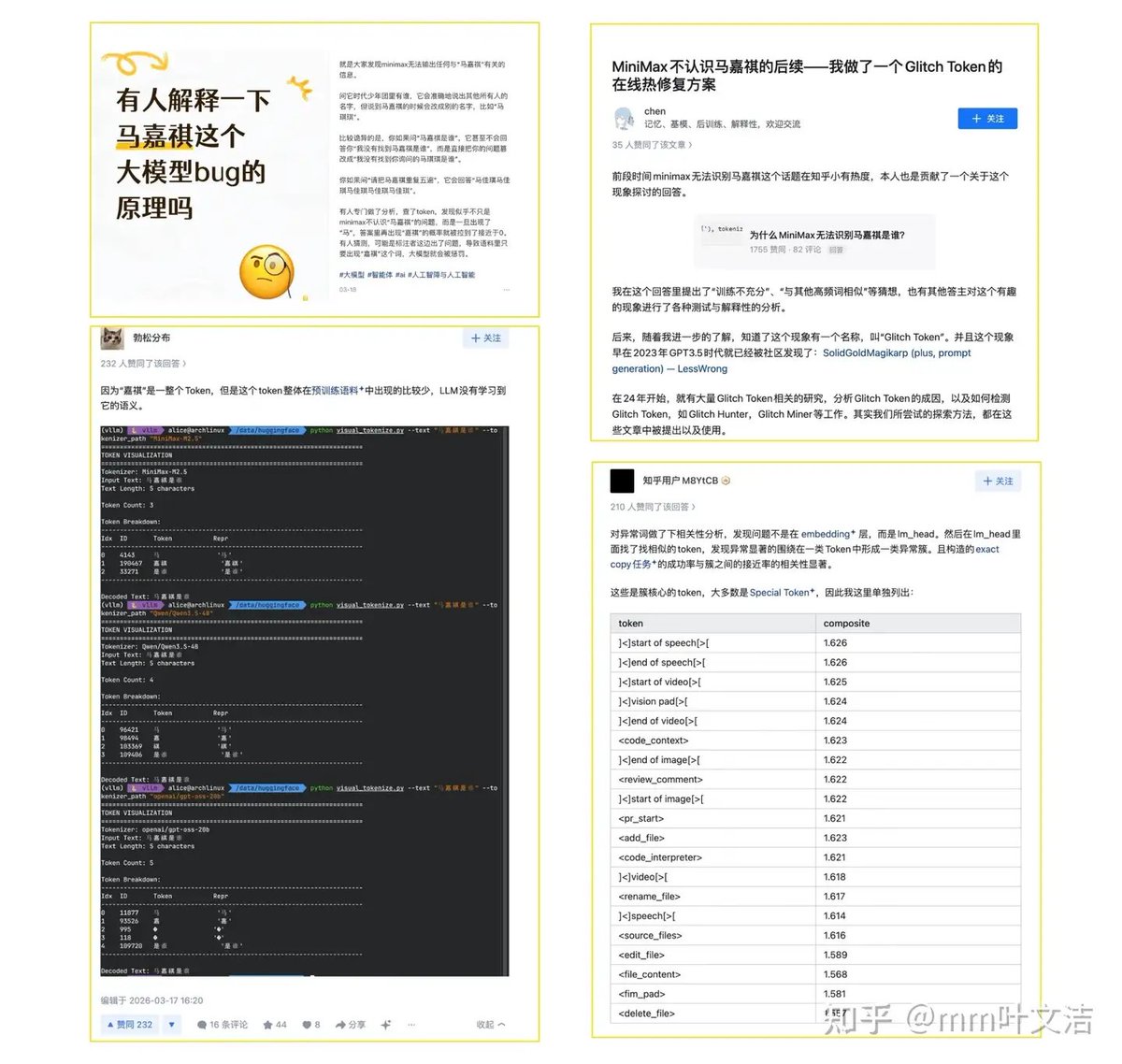
🧵 Why Can’t MiniMax LLM Recognize Ma Jiaqi?
Insights from Zhihu contributor mm李文洁🔍
📌 Core Phenomenon
MiniMax M2 series fails to output the name Ma Jiaqi —The model understands his identity/background perfectly,but cannot generate the exact token in replies.Not an isolated case: other low-frequency rare words face the same issue.
🤔 Guess 1: Tokenizer Misalignment ❌ (Ruled Out)
•“Jiaqi” is split into a standalone token 190467
• Pre-trained embedding norm & semantic nearest neighbors are normal
• Top similar tokens: Yixing, Yaxuan, other celebrity names ✅
• Base pretrain model can generate Ma Jiaqi normally
• Only post-training SFT model avoids outputting the token
Conclusion: Tokenizer alignment is not the cause — problem lies in SFT stage.
🤔 Guess 2: SFT Data Distribution Imbalance ✅
SFT dataset contains fewer than 5 samples with “Jiaqi”.Low-frequency tokens gradually lose generation capability while keeping comprehension.
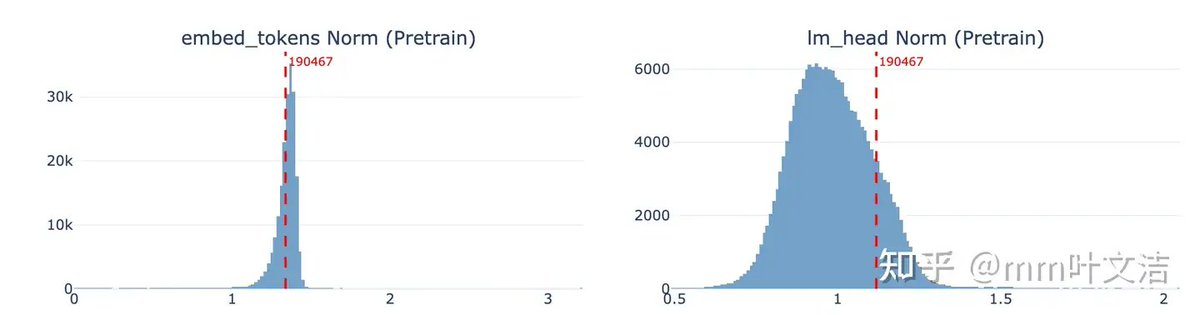
🔬 Key Root Cause Discovery
Two critical model layers:
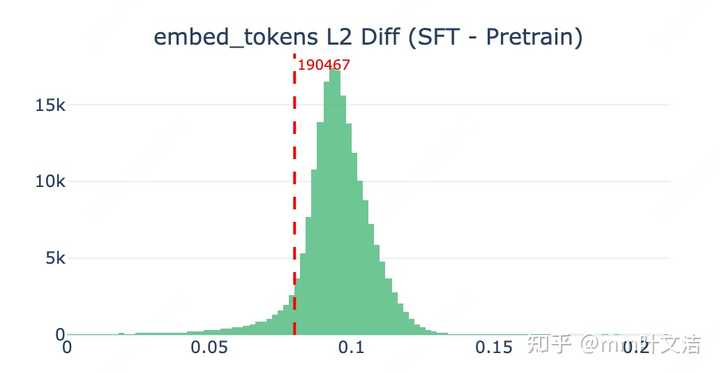
Vocab Embedding: Almost unchanged after SFTLow-frequency tokens receive nearly no effective gradient updates.
LM Head Output Layer: Drastic drift ⚠️
• Sharp drop in cosine similarity & huge L2 weight shift
• Semantic neighbor structure collapses severely
• Irrelevant special tokens, tool call tags & noise tokens invade the semantic space
• Low-frequency Chinese names get squeezed out of normal generation probability
📊 Which Tokens Degrade Most in LM Head?
1️⃣ Special tokens: FIM markers, tool call tags
2️⃣ Japanese daily/spam texts (40% of all degraded tokens)
3️⃣ LaTeX & Wikipedia metadata markup
4️⃣ Chinese SEO spam & niche industry keywords
🔗 Linked Hidden Issue
Japanese token LM-head drift causes cross-language mixing in MiniMax M2.One mechanism explains two bugs:
• Low-frequency token generation failure (Ma Jiaqi case)
• Minor language random mixing in dialogue
🛠 Fix Strategy: Full Vocab Coverage Synthetic Data
• Generate 500 synthetic dialogue samples
• Let every token in 200k vocab be trained as generation target ≥20 times
• Simple repeat task → ultra-low cost, sets a minimum generation frequency baseline
✅ Experimental Results
🎯 Ma Jiaqi case: Fully fixed under deterministic sampling
🎯 Japanese language mixing: 47% → 1% confusion rate
🎯 Degraded low-frequency token pass rate: 4/16 → 13/16
🎯 Resolved sparse token replacement errors in daily chat
💡 Other Optimization Directions
• Mix pretrain corpus into SFT data to ease catastrophic forgetting
• Targeted synthetic data for under-covered low-frequency tokens
• Vocab pruning CPT to eliminate useless rare tokens fundamentally
🧠 Fundamental Insight
This is distribution shift induced catastrophic forgetting:
• Pretrain tokenizer vocab mismatches SFT real scenarios
• SFT data undercovers long-tail tokens → LM-head semantic drift
• Future fix: Design tokenizer vocab with downstream SFT distribution in advance; monitor low-frequency token generation probability long-term.
🔗Full article:zhihu.com/question/201704968…
#LLM #MiniMax #LLMTechnical #AIResearch #LargeModel

1
1
16
3,590
May 6
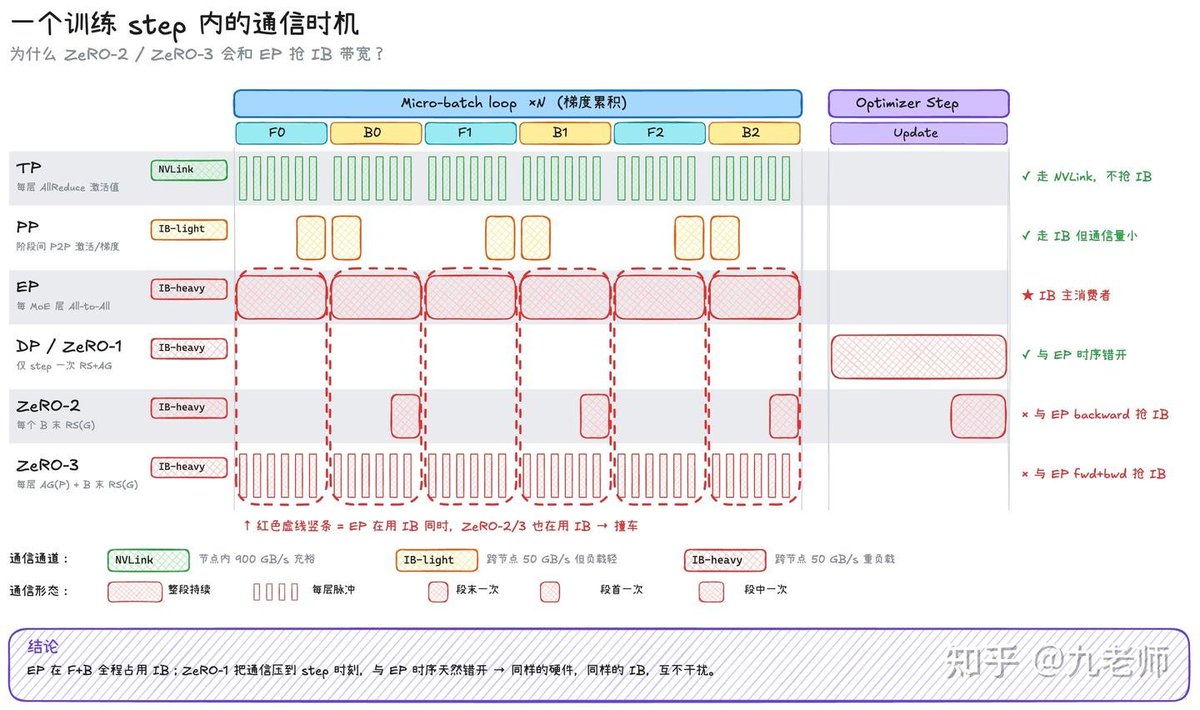
DeepSeek-V4 parallel strategy & compute-communication overlap breakdown
👀Zhihu contributor 九老师 breaks it down 🧩
Core Myth Debunked 📉
👉 MoE leads to sharp MFU drop, but tiny expert dims are not the cause.Real bottleneck: communication-bound distributed GPU computing.Breakthrough key: Rational parallel design compute-communication overlap.
Hardware & Inherited Framework 🖥️
👉 Cluster: H800 / Ascend,8-card NVLink inter-node IB
• NVLink: 900GB/s|IB: only 50GB/s
• No high-end NVL72 used → solution low-cost & replicable
👉 V4 inherits DeepSeek-V3 stack2048 H800 config:16-way PP × 64-way EP × ZeRO-1 DPEP cross-node traffic dominates precious IB bandwidth.
Common GPU Parallel Modes 📚
• DP:Full params per GPU, split data only• ZeRO:Shard VRAM → ZeRO-1 / ZeRO-2 / ZeRO-3(FSDP)
• TP:Tensor split compute split,heavy comm,NVLink only
• PP:Layer pipeline,low comm,fit for cross-node
• EP:MoE exclusive,all-to-all token routing,heavy comm
• CP:Sequence split for 1M long context 📜
Multi-Parallel Combination Logic 🔗
👉 All parallel dimensions orthogonal & stackableEP is special:co-locate with DP,reroute token inside forward passDeepSeek layout:PP=16、EP=64、DP_total=128、DP_replica=2Only 2 full model replicas globally.
EP Optimization for IB Network 📡
👉 EP flow:Dispatch → Expert Compute → Combine
• V3:Limit 8 experts within 4 nodes to reduce IB pressure
• V4:Remove node restriction for higher efficiency
Concentrate IB traffic,transfer intra-node data via NVLink,cut latency for easier overlap.
Why Choose PP EP ZeRO-1 Only ⚙️
👉 Reserve IB bandwidth exclusively for EP
ZeRO-2/3:extra frequent IB communication,conflict with EP ❌
• ZeRO-1:nearly zero extra comm,save ~12x VRAM ✅
• PP:ultra-low traffic,no IB bandwidth contention
Pipeline Bubble & DualPipe 💨
• GPipe / 1F1B:classic pipeline bubble problems
• ZB1P:squeeze bubble via backward computation split
• DualPipe(V3):bidirectional micro-batch pipelineOverlap forward/backward,mask EP all-to-all latencyDedicate 20 SMs for custom PTX communication kernel, bypass NCCL.
Waved-EP:V4 Kernel-Level Upgrade 🌊
👉 Independent of PP scheduling,kernel-native overlap
• DualPipe flaw:only works for large batch,poor on small-batch RL & inference
• Waved-EP:split experts into multi waves,overlap dispatch / compute / combine
• Performance:RL 1.96x speedup,general scenario 1.50~1.73x 📈
TileLang vs Triton 🔧
👉 Waved-EP relies on TileLang,cannot be done by Triton
• Triton:only good at single-GPU kernel,weak cross-GPU comm support ❌
• TileLang:DSL productivity PTX/CUDA low-level control ✅
Can build fused compute-communication mega-kernels.
Industry Trend & Core Takeaway 🔭
👉 Two hardware routes:
• DeepSeek:Optimize compute-comm overlap,not blind bandwidth stacking
• NVIDIA:Scale NVLink interconnection to unify massive GPUs
👉 Takeaway:
💡LLM capability is not just brute-force scaling.DeepSeek’s precise parallel engineering & comm-compute balance is real technical art.
Full article: zhuanlan.zhihu.com/p/2034669…
#DeepSeekV4 #LLM #MoE #AIInfrastructure #LargeModel #Tech


6
20
138
21,426
Apr 29
From MLA to High-Rank MQA: DeepSeek-V4’s Attention Evolution 🧠
Let’s break down sharp insights from Zhihu contributor YyWangCS on DeepSeek’s attention evolution👇
💡MLA as a formal term has basically disappeared in the DeepSeek-V4 paper. Its attention design fully adopts native shared-KV MQA, upgraded to high-rank MQA with 128(64) query heads and 512 head dimension.
🧠Typically, the product of head count & head dimension stays on par with model hidden size. DeepSeek-V4’s MQA pushes this metric to roughly 8x the conventional scale.
📈Tracing the technical evolution makes perfect sense to connect the dots between legacy MLA and today’s high-rank MQA design:
✅Original MLA Era
💡MLA was essentially a low-rank version of MHA by design.
• Its MQA mode was just a computational rearrangement (via matrix multiplication associativity).
• Purpose: Optimize KV cache and save bandwidth during the decoding stage.
• Key note: MLA didn’t natively deliver MQA-level representation capability.
⚡DSA Sparse MQA Transition
• Core trait: Shared KV across all query heads drastically boosted per-token computation intensity.
• Engineering breakthrough: No need for large continuous blocks (unlike traditional GQA) to maximize Tensor Core efficiency.
• Advantage: Sparse MQA maintained high compute utilization even in the prefill stage.
•Tradeoffs: 4x FLOPs increase, lower dense compute efficiency, extra complexity (indexing, top-k, parallelism).
• Offset: Sparse KV filtering slashes long-context compute overhead significantly.
✅Full Native MQA Adoption
• For ultra-long contexts (1M tokens): Sparse/compressed shared-KV MQA dominates prefill, decoding, and long-sequence training.
• Dense MHA’s niche: Only retains advantages for short-text prefill/training.
• Architecture simplification: Dual MLA MHA/MQA modes became redundant — pure native shared-KV MQA is more streamlined.
🔧Stacked Tech Optimizations
• Combined with proven upgrades to enable high-rank MQA:
• Universal KV sharing (KVShared)
• Large head-dimension MQA tuning
• VO RoPE position encoding
• Compressed block attention
• Result: The 128 heads 512 head dim setup becomes logically coherent.
💡 Core Industry Insight
• MLA’s flaw: Asymmetric prefill-decode architecture was complex and needed iteration.
• MLA’s legacy: Pioneered a unique attention evolution roadmap for long-context LLMs.
• High-rank MQA logic: It’s the ultimate implementation of a tuning strategy — compensate for sparse/long-context performance loss by expanding query heads, KV heads, and head dimension.
• Key takeaway: Without MLA’s exploration, shared-KV MQA would have been far less intuitive.
Read full analysis 🔗:
zhuanlan.zhihu.com/p/2031149…
#AI #LLM #DeepSeekV4 #MQA #MLA #LargeModel #Tech



2
35
2,195

Apr 22
DeepSeek V4 Gray Testing: Million-Token Context Becomes New Standard bizyet.com/en/AI/539
In April, DeepSeek officially launched the public beta testing of V4, with the context window suddenly raised from 128K Tokens to 1M (million) Tokens. Equipped with a new Ultra-MoE sparse activation architecture, the total parameter scale reaches 1 trillion, with only 13-37 billion parameters activated per inference. Inference speed is 35 times higher than V3, energy consumption reduced by 40%, and inference cost is only 1/70 of the GPT-4 series. Fully localized domestically, it deeply adapts to Huawei Ascend chips. Developers can process entire technical documents and large code libraries at once, and code accuracy is improved by more than 60% compared to V3.
#DeepSeekV4 #ChineseAI #LargeModel
1
3
406


30 Dec 2025
Fun Engine is completing its data-driven service and is moving towards life services and fully embodied intelligence.
System Log: The Battle of Inventory
#game #gamedesign #servicedesign #socialdesign #socialinnovation #changemaker #seriousgame #realitygame #learning #ARG #blockchain #NFT #tokens #adventure #fiction #futurism #DAO #collectiveconsciousness #nonproductive #play #funtech #Mtech #codebook #creatureintelligence #art #soicalinteraction #behaviordesign #realitymining #foodservice #fooddesign #funcode #adaptive #kidsthinking #web6 #web3 #background #music #musicdesign #movie #sound #script #education #corporatebehavior #teambuilding #application #adatptivesystem #adpative #robotic #Biotech #largemodel

1
1
3
214

6 Dec 2025
注文された商品を棚から自律的に取り出す人型ロボット(目・脳・手が連携)
#humanoid #robot #autonomous #picking #VLA #LargeModel #EmbodiedIntelligence #RetailTech #store #kiosk #ConvenienceStore #MechMind #iREX2025 #国際ロボット展
11
36
2,372
25 Nov 2025
Fun Engine has reshaped its underlying code, stripped away the cost model, fully embodied the utility model, and created a niche and sustained momentum.
#game #gamedesign #servicedesign #socialdesign #socialinnovation #changemaker #seriousgame #realitygame #learning #ARG #blockchain #NFT #tokens #adventure #fiction #futurism #DAO #collectiveconsciousness #nonproductive #play #funtech #Mtech #codebook #creatureintelligence #art #soicalinteraction #behaviordesign #realitymining #foodservice #fooddesign #funcode #adaptive #kidsthinking #web6 #web3 #background #music #musicdesign #movie #sound #script #education #corporatebehavior #teambuilding #application #adatptivesystem #adpative #robotic #Biotech #largemodel

1
1
1
270
14 Nov 2025
Fun engine builds social interaction, continuously optimizes robot genes, and empowers embodied intelligence and scenario support, go on to the civil geometer
#game #gamedesign #servicedesign #socialdesign #socialinnovation #changemaker #seriousgame #realitygame #learning #ARG #blockchain #NFT #tokens #adventure #fiction #futurism #DAO #collectiveconsciousness #nonproductive #play #funtech #Mtech #codebook #creatureintelligence #art #soicalinteraction #behaviordesign #realitymining #foodservice #fooddesign #funcode #adaptive #kidsthinking #web6 #web3 #background #music #musicdesign #movie #sound #script #education #corporatebehavior #teambuilding #application #adatptivesystem #adpative #robotic #Biotech #largemodel

1
1
4
470
13 Nov 2025
Fun Engine redesigns the grand script, breaks through thematic narratives, and practices specialization and edge computing for any behavior system
#game #gamedesign #servicedesign #socialdesign #socialinnovation #changemaker #seriousgame #realitygame #learning #ARG #blockchain #NFT #tokens #adventure #fiction #futurism #DAO #collectiveconsciousness #nonproductive #play #funtech #Mtech #codebook #creatureintelligence #art #soicalinteraction #behaviordesign #realitymining #foodservice #fooddesign #funcode #adaptive #kidsthinking #web6 #web3 #background #music #musicdesign #movie #sound #script #education #corporatebehavior #teambuilding #application #adatptivesystem #adpative #robotic #Biotech #largemodel

2
1
5
4,765
12 Nov 2025
Fun engine is fully perceive gene expression, empowering more adaptive and purposeful embodied intelligence, thereby systematically interpreting overall situation health.
#game #gamedesign #servicedesign #socialdesign #socialinnovation #changemaker #seriousgame #realitygame #learning #ARG #blockchain #NFT #tokens #adventure #fiction #futurism #DAO #collectiveconsciousness #nonproductive #play #funtech #Mtech #codebook #creatureintelligence #art #soicalinteraction #behaviordesign #realitymining #foodservice #fooddesign #funcode #adaptive #kidsthinking #web6 #web3 #background #music #musicdesign #movie #sound #script #education #corporatebehavior #teambuilding #application #adatptivesystem #adpative #robotic #Biotech #largemodel


1
1
3
1,260
9 Nov 2025
Fun Engine has begun to empower any behavioral system to become its own genome library and evolutionary system, whether it's a scientific system, a large model, a document, an app, a game, a service, a problem, a product, or a specific social media account, including meaning construction and consciousness itself.
#game #gamedesign #servicedesign #socialdesign #socialinnovation #changemaker #seriousgame #realitygame #learning #ARG #blockchain #NFT #tokens #adventure #fiction #futurism #DAO #collectiveconsciousness #nonproductive #play #funtech #Mtech #codebook #creatureintelligence #art #soicalinteraction #behaviordesign #realitymining #foodservice #fooddesign #funcode #adaptive #kidsthinking #web6 #web3 #background #music #musicdesign #movie #sound #script #education #corporatebehavior #teambuilding #application #adatptivesystem #adpative #robotic #Biotech #largemodel

3
1
2
3,619
26 Oct 2025
How bio-communities and DIY services adapt
go on for more fun engine
#game #gamedesign #servicedesign #socialdesign #socialinnovation #changemaker #seriousgame #realitygame #learning #ARG #blockchain #NFT #tokens #adventure #fiction #futurism #DAO #collectiveconsciousness #nonproductive #play #funtech #Mtech #codebook #creatureintelligence #art #soicalinteraction #behaviordesign #realitymining #foodservice #fooddesign #funcode #adaptive #kidsthinking #web6 #web3 #background #music #musicdesign #movie #sound #script #education #corporatebehavior #teambuilding #application #adatptivesystem #adpative #robotic #Biotech #largemodel

1
1
2
112
8 Oct 2025
Social engines and collective intelligence from fun engine that continue to enpower training of prototype tribes and large model
#game #gamedesign #servicedesign #socialdesign #socialinnovation #changemaker #seriousgame #realitygame #learning #ARG #blockchain #NFT #tokens #adventure #fiction #futurism #DAO #collectiveconsciousness #nonproductive #play #funtech #Mtech #codebook #creatureintelligence #art #soicalinteraction #behaviordesign #realitymining #foodservice #fooddesign #funcode #adaptive #kidsthinking #web6 #web3 #background #music #musicdesign #movie #sound #script #education #corporatebehavior #teambuilding #application #adatptivesystem #adpative #robotic #Biotech #largemodel

1
1
2
140
6 Oct 2025
『任意の動作を低遅延でリアルタイムに生成する汎用大型モデル』
人型ロボットが人の動きをまるで影のように真似して動く(分身化)
bilibili.com/video/BV1zEnizB…
#humanoid #robot #LargeModel #GeneralActionExpert #GAE #avatar #shadow #WestlakeRobotics
2
45
160
11,744
4 Oct 2025
The fun engine is opening for its overall situation gene library, including benchmarks; experimental design; and application services.
#game #gamedesign #servicedesign #socialdesign #socialinnovation #changemaker #seriousgame #realitygame #learning #ARG #blockchain #NFT #tokens #adventure #fiction #futurism #DAO #collectiveconsciousness #nonproductive #play #funtech #Mtech #codebook #creatureintelligence #art #soicalinteraction #behaviordesign #realitymining #foodservice #fooddesign #funcode #adaptive #kidsthinking #web6 #web3 #background #music #musicdesign #movie #sound #script #education #corporatebehavior #teambuilding #application #adatptivesystem #adpative #robotic #Biotech #largemodel

1
1
1
97
2 Oct 2025
注文された商品を棚から自律的に取り出す人型ロボット(目・脳・手が連携)
youtu.be/NtlOnY5a98I
#humanoid #robot #autonomous #picking #VLA #LargeModel #EmbodiedIntelligence #RetailTech #store #kiosk #ConvenienceStore #MechMind
1
6
24
1,842
1 Sep 2025
Adaptive game, prototype tribe are forming the core of super intelligence and super life
#game #gamedesign #servicedesign #socialdesign #socialinnovation #changemaker #seriousgame #realitygame #learning #ARG #blockchain #NFT #tokens #adventure #fiction #futurism #DAO #collectiveconsciousness #nonproductive #play #funtech #Mtech #codebook #creatureintelligence #art #soicalinteraction #behaviordesign #realitymining #foodservice #fooddesign #funcode #adaptive #kidsthinking #web6 #web3 #background #music #musicdesign #movie #sound #script #education #corporatebehavior #teambuilding #application #adatptivesystem #adpative #robotic #Biotech #largemodel

1
1
3
373
24 Aug 2025
How collaborative protocols empower super life
#game #gamedesign #servicedesign #socialdesign #socialinnovation #changemaker #seriousgame #realitygame #learning #ARG #blockchain #NFT #tokens #adventure #fiction #futurism #DAO #collectiveconsciousness #nonproductive #play #funtech #Mtech #codebook #creatureintelligence #art #soicalinteraction #behaviordesign #realitymining #foodservice #fooddesign #funcode #adaptive #kidsthinking #web6 #web3 #background #music #musicdesign #movie #sound #script #education #corporatebehavior #teambuilding #application #adatptivesystem #adpative #robotic #Biotech #largemodel
1
1
4
269