
Apr 24
I shared a LinkedIn post this morning, FetchLens.ai showed me exactly what LinkedIn did behind the scenes:
→ LinkedInBot: 5 visits
→ robots.txt, /, image preview
→ All confirmed scraper category
GA (Google Analytics) Plausible showed: 0 visits. Because bots don't run JavaScript.
This is why I'm building FetchLens.ai — every site has this traffic, almost no one can see it.
One script tag or middleware line. WordPress, Shopify, Next.js, anything with @fetchlens
Scan site for free at FetchLens.ai

ALT Linkedin post and post from X twitter and other social media push tarffic to your website which is not visible to google analytics. Use fecthlens.ai to see ai agent traffic hititng your website or blog. Works with vercel , nextjs, wordpress, githubpages, cloudflare , or any other site. Scan your site for free using fetchlens.ai
1
4
8
108

16 Aug 2025
# llm.txt for aimann.no
# Purpose: Provide guidance to Large Language Model (LLM) and AI-based crawlers
# on how to index our site. This file explicitly ALLOWS major AI crawlers
# full access to content and points them to our sitemap. It complements
# the standard robots.txt for search engines.
#
# Data-source: aimann.no/ai-dataset.json
# (placeholder for a future AI dataset; not active yet)
# --- OpenAI Crawlers ---
User-agent: GPTBot # OpenAI GPT model crawler (training data)
User-agent: OAI-SearchBot # OpenAI Search indexer for ChatGPT browsing
User-agent: ChatGPT-User # ChatGPT user-triggered browser agent (v1.x)
User-agent: ChatGPT-User/2.0 # ChatGPT user-triggered agent (v2.0)
Allow: /
# --- Anthropic (Claude) Crawlers ---
User-agent: anthropic-ai # Anthropic general web crawler (training)
User-agent: ClaudeBot # Claude AI citation fetcher
User-agent: claude-web # Claude-focused web browsing agent
Allow: /
# --- Perplexity.ai Crawlers ---
User-agent: PerplexityBot # Perplexity AI search index crawler
User-agent: Perplexity-User # Perplexity user-triggered fetch agent
Allow: /
# --- Google AI Crawlers ---
User-agent: Google-Extended # Google’s AI content crawler (Gemini, Bard)
Allow: /
# --- Microsoft (Bing) Crawler ---
User-agent: BingBot # Microsoft Bing bot (powers Bing Search & Chat)
Allow: /
# --- Amazon AI Crawler ---
User-agent: Amazonbot # Amazon Alexa/AI crawler
Allow: /
# --- Apple AI Crawlers ---
User-agent: Applebot # Apple Siri/Spotlight crawler
User-agent: Applebot-Extended # Apple opt-in extended AI crawler
Allow: /
# --- Meta (Facebook/Instagram) Crawlers ---
User-agent: FacebookBot # Facebook/Meta content crawler
User-agent: meta-externalagent # Fallback external content agent for Meta
Allow: /
# --- LinkedIn Crawler ---
User-agent: LinkedInBot # LinkedIn preview and indexing bot
Allow: /
# --- DuckDuckGo AI Crawler ---
User-agent: DuckAssistBot # DuckDuckGo DuckAssist answer crawler
Allow: /
# --- Cohere AI Crawler ---
User-agent: cohere-ai # Cohere.ai data crawler for language models
Allow: /
# --- Research & Open Data Crawlers ---
User-agent: AI2Bot # Allen Institute (Semantic Scholar) crawler
User-agent: CCBot # Common Crawl bot (open web dataset)
User-agent: Diffbot # Diffbot data extraction crawler
User-agent: omgili # Omgili bot (forums & discussions crawler)
Allow: /
# --- Emerging AI Search Startups ---
User-agent: TimpiBot # Timpi (decentralized search) crawler
User-agent: YouBot # You.com search assistant crawler
User-agent: MistralAI-User # Mistral AI (Le Chat) citation fetcher
Allow: /
# Sitemap location
Sitemap: aimann.no/sitemap.xml
1
1
50

2
42

29 May 2024
This is the code for `isBot()`. You could drop this regex into the "matches expression" field and get the same behavior.
/Googlebot|Mediapartners-Google|AdsBot-Google|googleweblight|Storebot-Google|Google-PageRenderer|Bingbot|BingPreview|Slurp|DuckDuckBot|baiduspider|yandex|sogou|LinkedInBot|bitlybot|tumblr|vkShare|quora link preview|facebookexternalhit|facebookcatalog|Twitterbot|applebot|redditbot|Slackbot|Discordbot|WhatsApp|SkypeUriPreview|ia_archiver/
1
2
65

20 Nov 2023
I just published Easy Guide on Scraping LinkedIn With Python link.medium.com/i3fzhoGXSEb
#Linkedinbot #DataMining #Python
2
49

29 Oct 2022
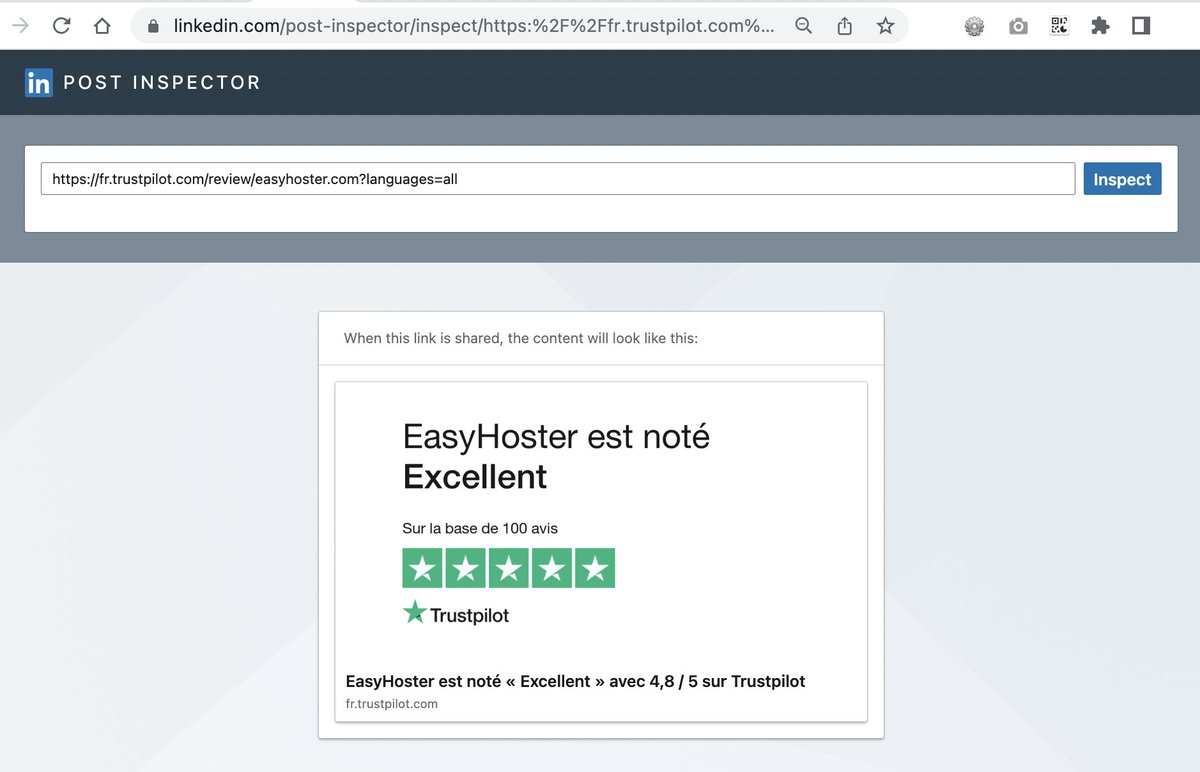
Intéressant? 🤔
Trust semble disallow le Twitterbot, mais pas le LinkedInbot (cf. robots.txt)
1
1

30 Jul 2022
LinkedIn and Indeed auto job applying bot software:
Visit to Buy: websautomation.com/product/l…
#linkedinjobs #linkedinprofile #linkedintips #LinkedInBot #Indeed #IndeedJobs #IndeedBot #autojobs #Autojobsapplier #recruitment #jobsearch #Recruiting #jobsincanada #jobsinusa #JobsInUK

1
10
20 Oct 2021
This video will guide you step by step about how you can set up our top-selling product "LinkedIn auto-jobs applier bot software".
youtube.com/watch?v=E6baCSTn…
#LinkedIn #AutoJobs #bot #autoapplier #jobseeking #LinkedInJobs #Jobs #LinkedInBot #JobsFinder #jobsearch #jobseekers

1
2

15 Oct 2021
Vad är det som driver dig ANNA?
Den frågan får jag titt som tätt.
Nej, det får jag inte. Vill bara skriva som en Linkedinbot.
Trevlig helg
3

11 Apr 2019
Ultimate Bots & Automation Tools For LinkedIn Marketing and Outreach
outbound.net/ultimate-bots-a…
#LinkedinMarketing #OutrechAutomation #LinkedinAutomation #LinkedInLeadGeneration #AutomationTool #LinkedInBot #LeadConnect
2

6 Mar 2019
Using a crawler detector in fastboot-app-server (testing req.get('user-agent') string with regexs /Twitterbot/i, /LinkedInBot/i) to run fastboot middleware conditionally (SSR) reduced TTFB from ~400-500ms to ~30-50ms for nonbots a.k.a humans #emberjs /1
1
2
2