
11h
🧠 Crossing the Blood-Brain Barrier (BBB) remains one of the biggest challenges in CNS drug discovery. A new preprint introduces TITAN-BBB, a multimodal deep learning framework that combines molecular descriptors, molecular images, and chemical language embeddings to predict BBB permeability with state-of-the-art performance.
Key innovation: instead of relying on a single molecular representation, TITAN-BBB integrates:
🔹 RDKit physicochemical descriptors MACCS fingerprints
🔹 ResNet50-derived molecular image embeddings
🔹 ChemBERTa chemical language model embeddings
These modalities are projected into a shared latent space and fused through an attention mechanism that dynamically weights the importance of each modality for every compound.
The authors also assembled what is currently the largest curated BBB permeability dataset:
📊 9,262 compounds for BBB classification
📊 1,147 compounds with experimental logBB values for regression
The dataset was aggregated from multiple literature sources, standardized, deduplicated, and scaffold-split to provide a rigorous benchmark for model evaluation.
Performance highlights:
✅ Balanced Accuracy: 86.5%
✅ ROC-AUC: 0.935
✅ MAE (logBB regression): 0.436
Compared with previous SOTA approaches, TITAN-BBB improved balanced accuracy by ~3.1 percentage points and reduced regression error by ~20%.
One particularly interesting finding is that traditional cheminformatics descriptors remain extremely valuable even in the foundation-model era.
Attention analysis showed:
🟢 Tabular descriptors contributed >60% of model importance
🟢 Chemical language embeddings contributed ~20%
🟢 Molecular image features added complementary information despite lower standalone importance
This suggests that domain knowledge and learned molecular representations are not competitors—they are complementary.
The ablation study further supports this conclusion:
• Tabular-only model: 83.4% balanced accuracy
• Image-only model: 80.0%
• Text-only model: 77.4%
• Full multimodal TITAN-BBB: 86.5%
No single modality matched the integrated model.
Why this matters:
BBB permeability remains a major bottleneck in neurodegenerative disease, brain cancer, and CNS drug development. Models like TITAN-BBB illustrate a broader trend in AI-driven drug discovery: the future may belong to multimodal architectures that combine chemical knowledge, foundation models, and structure-aware representations rather than relying on any single paradigm.
Preprint: "TITAN-BBB: Predicting BBB Permeability using Multi-Modal Deep-Learning Models" (bioRxiv, 2026)
#AI4DrugDiscovery #DrugDiscovery #MachineLearning #DeepLearning #BBB #Neuroscience #MedicinalChemistry #Chemoinformatics #LLM #Bioinformatics

3
8
193
Franco Suárez retweeted

Jun 11
El unico que dejó la pobreza fuiste vos segun datos del maccs
(Manuel Adorni cola con semen)
Jun 9

Según UNICEF, en 2025 la pobreza infantil llegó a su nivel más bajo de los últimos 7 años.
Fin.
2
1
22
1,702


Agentic Molecular Recovery via Molecule-Aware Exploration
1. The paper reframes invalid SMILES from text-guided LLM generation as “corrupted molecular states” that often still contain useful structural cues, arguing the goal should shift from validity-only repair to identity-preserving molecular recovery.
2. It distinguishes two objectives: Repair = make the string chemically valid; Recovery = make it valid while preserving target-relevant scaffolds/functional groups and reconstructing the molecular identity implied by the natural-language description.
3. A key diagnosis: post-hoc repair methods (e.g., SELFIES/SMILES repair) can restore validity but frequently distort core substructures, while LLM-only iterative rewriting tends to cause unintended global drift because it regenerates whole SMILES sequences rather than controlled local edits.
4. The work also critiques “agentic greedy search” in tool-augmented molecular agents: even with RDKit-executable edit tools (better action fidelity), single-trajectory greedy refinement is vulnerable to early mistakes and lacks explicit tracking of molecule–text mismatches.
5. AMREC is introduced as an agentic recovery framework that combines molecule-aware mismatch tracking with expanded candidate exploration and trajectory-level selection, rather than committing to one step-by-step path.
6. AMREC’s core loop uses four roles: Checker extracts description-derived, verifiable structural requirements and evaluates them via RDKit observations; Critic summarizes remaining mismatches and flags structures to preserve; Planner proposes minimal-risk recovery intents; Candidate Explorer generates multiple candidate realizations per intent.
7. Two design choices are central: (a) requirement checklists serve as explicit objectives and stopping criteria to avoid unnecessary edits that might damage correct parts, and (b) a persistent candidate pool enables revisiting alternatives instead of discarding them after each step.
8. After the iterative loop, AMREC performs trajectory-level candidate selection: it selects the best molecule from all candidates seen across the trajectory, addressing the common failure mode where late edits degrade earlier, better-aligned molecules.
9. On invalid ChEBI-20 drafts from three backbone models (GPT-5.4-mini, Gemini-3.1-flash-lite, Claude-haiku-4.5), AMREC reports the strongest overall recovery profile across fingerprint similarities (MACCS/RDK/Morgan), exact match, string metrics (BLEU/ROUGE/Levenshtein), and distributional distance (FCD), outperforming validity repair, LLM-only correction, and generic tool-grounded agents (ReAct/ReWOO/PlanAndAct).
10. Ablations attribute gains to exploration and selection: larger trajectory-level pools improve identity/structure metrics; adding Critic improves structural recovery; final selection helps even tool agents, but AMREC benefits most because it generates higher-quality candidates to choose from.
📜Paper: arxiv.org/abs/2606.05847
#ComputationalBiology #Cheminformatics #MolecularGeneration #LLM #Agents #RDKit #SMILES #DrugDiscovery #MachineLearning

2
7
26
2,166


May 31
Who is paying 70m for macca alister. Madrid want his younger team mate enzo. They now maccs legs are gone
2
161

May 14
Microsoft and Inworld partnered to make it easier to deploy enterprise-grade voice agents into production.
Now, @Azure customers can deploy Inworld's top-ranked, Realtime TTS 1.5 max model directly into their own Azure environment through AI Foundry or Azure Marketplace.
Azure customers can consume Inworld models using existing MACCs or start new. You'll get full control over where your data lives. And because Inworld TTS is built for realtime interactions, conversations with your voice agents will feel natural and responsive.

3
3
35
1,957


Alors qu'il a mis son premier bulletin manu maccs en 2017

Mbappé vote Mélenchon mais j’ai aucune preuve
2
6
141

May 12
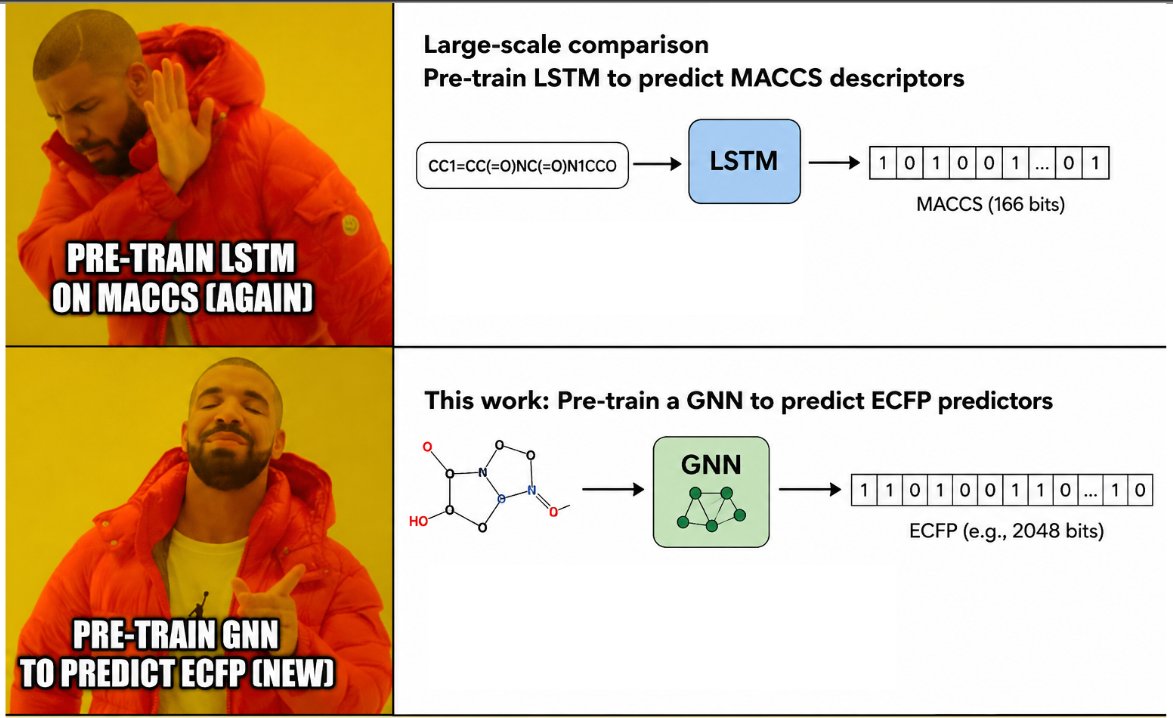
A USEFUL PRETRAINING OBJECTIVE FOR GNNs:
Pre-trains GNNs to predict ECFP descriptors, like SmilesLSTM was pre-trained to predict MACCS.
P: arxiv.org/abs/2605.10722
also P: doi.org/10.1039/C8SC00148K
2
1
15
1,650

@DoorDash_Help l ordered a maccs order that l was charged for and was not delivered
2
30

Adoro a maccs con toda mi alma; pero me da la duda de que si los demás prime andan sueltos por ahí.


2
50
BOLEK: A Multimodal Language Model for Molecular Reasoning
1. BOLEK targets a key pain point in molecular ML: predictions that are either opaque (just a score) or “explanations” that aren’t checkable against the actual molecule. The model is designed so its natural-language reasoning can be audited using verifiable molecular features.
2. Core idea: inject a molecular embedding directly into an instruction-tuned text decoder. BOLEK extends Qwen3-4B-Instruct with a single Morgan fingerprint token (2048-bit, radius=2) mapped into the LLM embedding space via a small learned projector, then trains everything end-to-end.
3. The alignment recipe is deliberately “first-principles” rather than caption-style. Instead of mostly mapping molecules to descriptive prose, BOLEK is trained to answer many concrete questions about the molecule: (a) free-text structural/property descriptions, (b) substructure presence/absence, and (c) numeric descriptor prediction.
4. Alignment scale and coverage: >850k molecules drawn from MolPILE (700k), KnowMol (90k), ChEBI-20-MM (26k), plus naming sets. Tasks include regression of 88 RDKit/Mordred descriptors and detection of 1,403 substructures spanning MACCS keys, RDKit fragments, SMARTS catalogs, and toxicophore/alert lists.
5. Downstream training uses 15 TDC binary classification endpoints (e.g., AMES, BBB, HIA, hERG, Pgp, HIV, and multiple CYP inhibition/substrate tasks). BOLEK is trained in one supervised fine-tuning run mixing alignment downstream examples, with both yes/no and chain-of-thought (CoT) formats.
6. A notable ingredient: CoT supervision is synthetic but feature-anchored. For each training molecule, the rationale prompt includes (i) a literature-derived mechanistic preamble for the endpoint, (ii) SMILES, (iii) a decomposition into named parts with local annotations, and (iv) values of the top 20 RDKit descriptors chosen by random-forest feature importance. The CoT is generated and filtered to match the ground-truth label.
7. Predictive results on the 15 TDC tasks: BOLEK improves over its Qwen3-4B-Instruct base on all 15 tasks in yes/no mode, and on 13/15 in CoT mode. Mean ROC/PR AUC rises from 0.55 (Qwen3) to 0.76 (BOLEK) in yes/no mode. Despite being < half the size, BOLEK outperforms TxGemma-9B-Chat on 13/15 binary tasks.
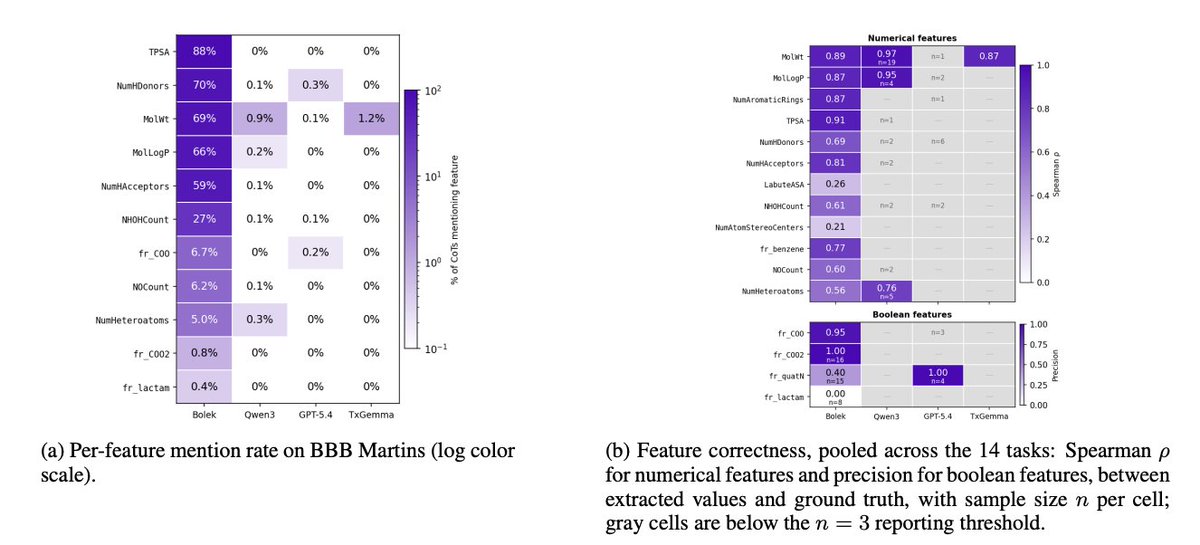
8. Groundedness evaluation is treated as a first-class metric: BOLEK mentions concrete numerical descriptors 10–100× more often per CoT than Qwen3, TxGemma, or GPT-5.4. When it cites values, they align well with RDKit for canonical features (e.g., TPSA, MolLogP, MolWt; Spearman ρ ≈ 0.87–0.91), highlighting “auditable” rationales rather than purely qualitative prose.
9. Representation ablation (fingerprint vs SMILES) shows complementarity: fingerprint input wins on many enzyme/transporter tasks driven by substructure/shape (Veith CYPs, CYP substrates, Pgp, bioavailability), while SMILES can be stronger on tasks with broader token-level cues or multi-mechanism signals (e.g., HIV) and on some permeability/tox endpoints. This supports the paper’s view that no single representation dominates across endpoint families.
10. Generalization beyond the trained endpoints: on 15 unseen TDC classification tasks, BOLEK improves over Qwen3 zero-shot and matches/exceeds TxGemma on several non-Tox21 endpoints (e.g., PAMPA, ClinTox, skin reaction, SARS-CoV-2 Touret, M1 antagonist). On 3 held-out regression tasks (lipophilicity, PPBR, solubility), BOLEK shows non-trivial rank correlations despite never being trained on downstream regression.
📜Paper: arxiv.org/abs/2605.02745
#ComputationalBiology #Cheminformatics #DrugDiscovery #MultimodalAI #LLM #QSAR #ExplainableAI #MolecularML #TDC #RDKit
10
1,095


BiMol-Diff: A Unified Diffusion Framework for Molecular Generation and Captioning
1. BiMol-Diff proposes a single diffusion-based framework that handles both text→molecule generation and molecule→text captioning, aiming to make iterative molecule design loops more consistent than task-specific, separately trained systems.
2. The central technical idea is a token-aware noise schedule: instead of corrupting every position uniformly (as standard diffusion does), the model assigns position-dependent corruption based on how hard each token is to recover, using per-token denoising loss as a proxy for “difficulty”.
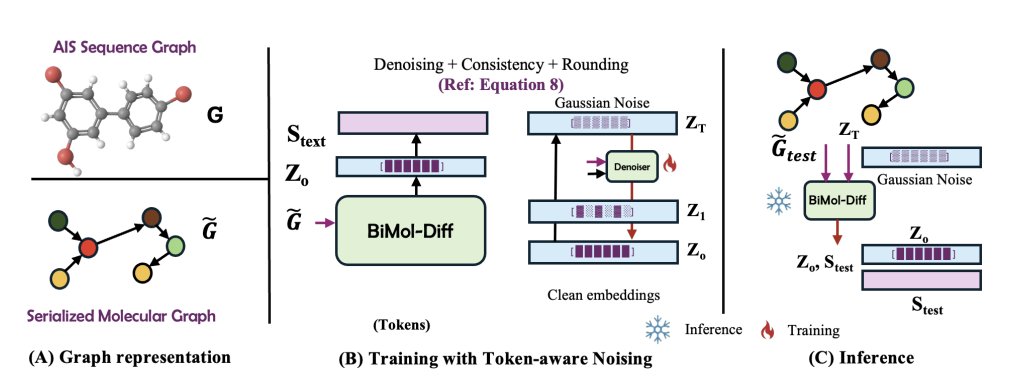
3. Mechanistically, the method periodically estimates token-wise difficulty profiles across diffusion timesteps, maps these difficulties to token-specific cumulative noise schedules via a piecewise-linear function, and enforces a valid monotone schedule using non-increasing isotonic projection.
4. Molecular representation is designed to reduce brittleness to SMILES syntax: molecules are tokenized with Atoms-in-SMILES (AIS) and also converted into a serialized “knowledge-graph-like” edge list of atom–bond–atom triplets using special tokens ([HEAD], [REL], [TAIL], [SEP]). Text↔molecule is modeled as text↔serialized-graph.
5. Training uses a z0-prediction diffusion objective (predict the clean latent at every step) plus two additional terms: a consistency loss for the first denoising step and a trainable rounding term that converts continuous latents back into discrete tokens. Inference further uses a “clamping” trick (nearest-neighbor projection onto the embedding table) to reduce rounding drift during intermediate steps.
6. On molecule captioning (M3-20M subset, ~360k pairs), BiMol-Diff reports best BLEU and BERTScore among compared baselines, with BLEU 0.567, ChrF 0.734, BERTScore-F1 0.843, MAUVE 0.925, while using fewer parameters than several AR and diffusion baselines in the table.
7. On text→molecule generation (ChEBI-20, 33,010 molecules), BiMol-Diff improves Exact Match to 0.262 vs 0.227 for the strongest compared AR adapter and diffusion baseline ( 15.4% relative), and improves fingerprint similarities (MACCS/RDKit/Morgan) while keeping high validity (0.901).
8. Ablations attribute a large portion of captioning gains to token-aware noising: switching from a uniform sqrt schedule to token-aware linear mapping improves BLEU (0.495→0.567), ChrF (0.682→0.734), and METEOR (0.531→0.626). AIS tokenization also outperforms regex and atom-level tokenization under the same schedule.
9. Efficiency analysis highlights a practical trade-off typical for diffusion: quality is strongest around 1000–2000 reverse steps; aggressive step reduction sharply degrades BLEU. Compared with DiffuSeq at 2000 steps, BiMol-Diff is faster per batch (89s vs 317s on V100) while also improving quality.
📜Paper: arxiv.org/abs/2604.24089
#moleculargeneration #diffusionmodels #cheminformatics #computationalbiology #nlp #multimodal #drugdiscovery #generativemodels
2
20
1,469

Let’s set that shitty 4g pitch of maccs on fire


6
3
31
5,330

Apr 18
Despite being the most popular vector search engine in the Python ecosystem, most users of Meta's FAISS library don't seem to know its strengths or weaknesses. Since FAISS is the most common comparison target for (my) @unum_cloud USearch engine, I do a fair share of benchmarking against it — and a few things keep coming up that are worth sharing.
FAISS ships several scalar quantization modes that almost nobody uses. If you are dealing with `f16` or `bf16` vectors, you pass `SQfp16` / `SQbf16` as qualifier strings to `index_factory`. For native `u8` or `i8` integer inputs there's `SQ8_direct` and `SQ8_direct_signed` — the "direct" variants store the byte as-is, without per-dimension rescaling, which is exactly what you want when the data is already in range.
For the most extreme case — binary vectors — you shouldn't use the regular `HNSW` class. FAISS has a separate `BHNSW` instantiation. It's less configurable: you can't set `efConstruction` or `efSearch` via the C API, they're hard-coded at 40 and 16. But it's dramatically faster than shoving binary data through the float path, and at those defaults it still hits reasonable recall.
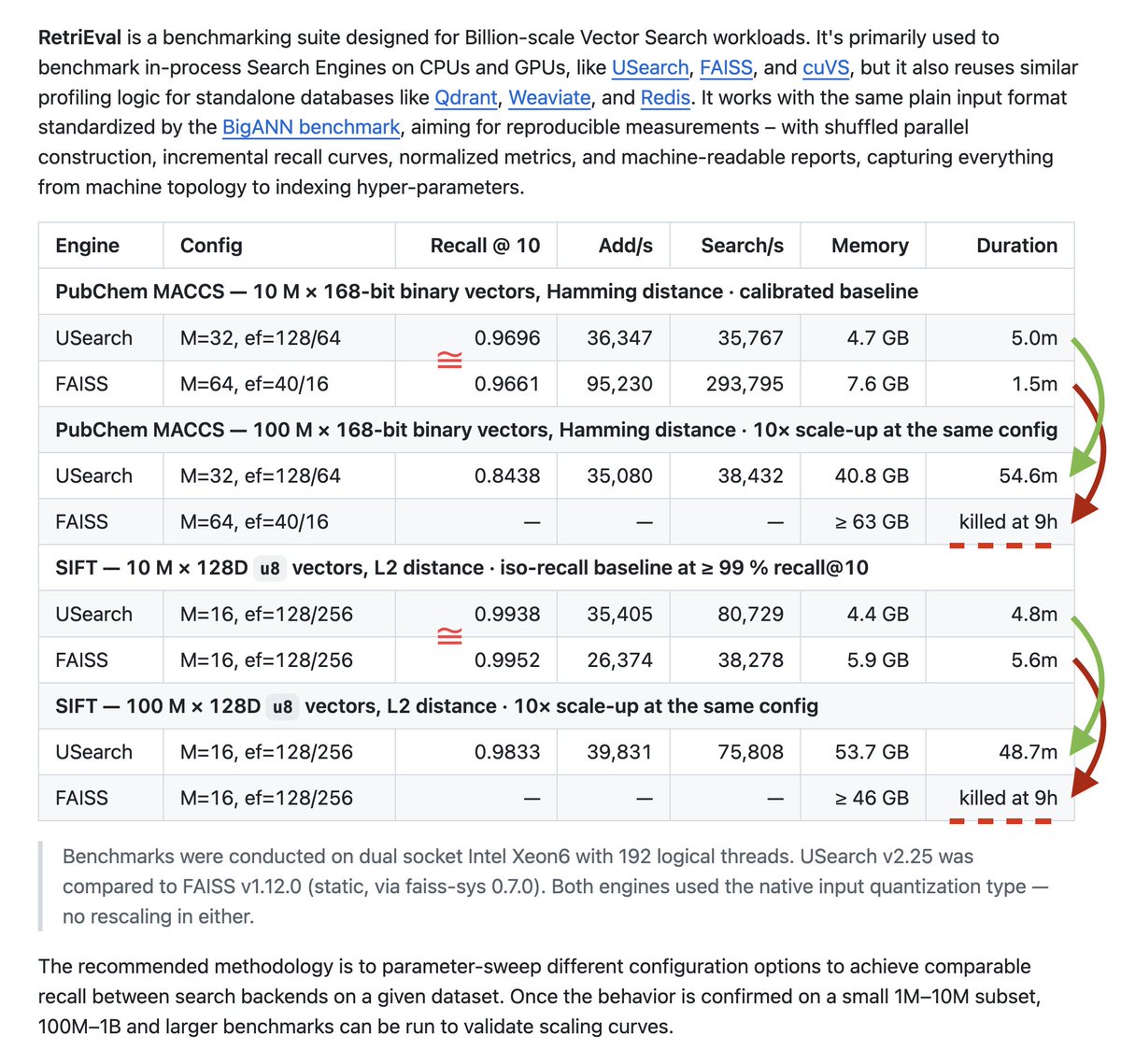
The bigger problem is that FAISS is tuned for fairly small-scale use. As indexes grow, construction and search speed degrade super-linearly. On a 192-core machine I couldn't finish indexing fairly modest 100M datasets — both from BigANN (SIFT 100M `u8` with L2) and from the binary-fingerprint datasets I've published for computational chemistry and biology (PubChem MACCS, 168-bit, Hamming distance). The same hyperparameters that run in minutes at 10M sit for hours at 100M without finishing.
It's worth noting that FAISS leans heavily on hybrid schemes with learnable quantization — IVFPQ and friends. I stand by the opinion that those approaches aren't robust: they give short-term gains on small datasets and backfire at real scale. That's a topic for a proper paper someday.
For now, the advice is simple: dig through the docs for forgotten features, and run your own benchmarks to understand the strengths and limits of the tools you're using. You'll probably find knobs nobody talks about.
PS: I was working on some hybrid CPU GPU workloads on @nebiusai — check out the numbers I got on their new Intel Xeon 6 Granite Rapids Nvidia Blackwell instances 🔥
github.com/ashvardanian/Retr…
1
5
28
3,569

Apr 18
I was in Macc last year watching my nephew play football at Maccs ground, I had to stop off and take a pic of Ians mural😁

1
8
63

Apr 14
Isak starting was not fine as A) he was clearly not fit enough B) there’s more space later as teams tire C) after 30 mins Maccs was running past him and doing all his pressing because he was knackered. That meant we were a midfielder down and Isak was a passenger
5
141