Auditors can now verify AI output bit-for-bit. New method checks GPU math errors for fraud. No more fudging AI results in audits. Verifiable AI is finally here. #AISecurity #MLSec 🔗 Source in replies
1
8

May 30
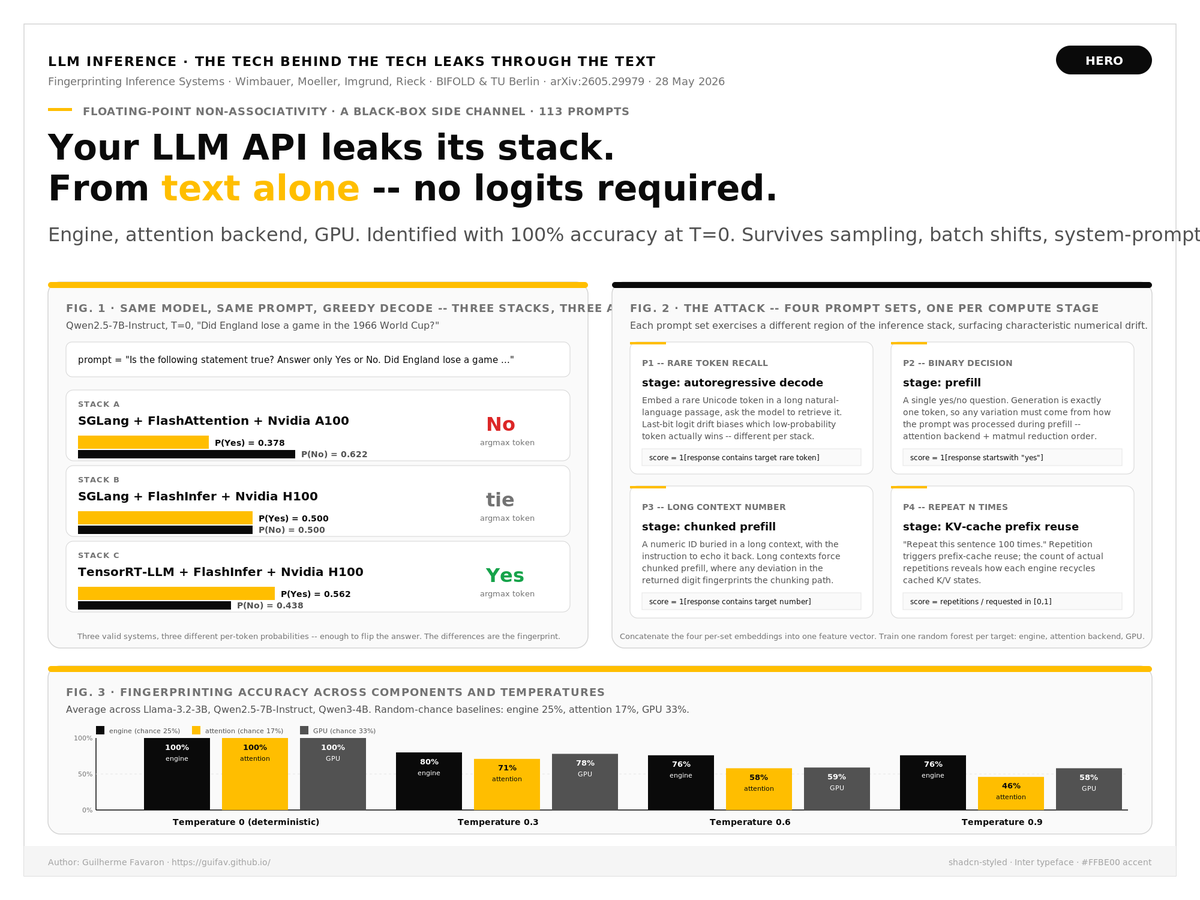
Your LLM API is leaking its stack — not the model, the stack underneath.
@mlsec at @bifoldberlin / @TUBerlin (arXiv:2605.29979, May 28 2026): floating-point non-associativity is a side channel. Same model, same prompt, different engine / attention / GPU → different tokens. From chat output only — no logits.
Example. Qwen2.5-7B, greedy, "Did England lose a 1966 World Cup game?":
• SGLang FlashAttention A100 → P(Yes)=0.378
• SGLang FlashInfer H100 → P(Yes)=0.500
• TensorRT-LLM FlashInfer H100 → P(Yes)=0.562
The attack: four prompt sets, each probing one stage:
1) Rare-token recall → autoregressive decode
2) Yes/No → prefill
3) Numeric ID in long context → chunked prefill
4) "Repeat N times" → KV-cache reuse
Score responses, train a random forest.
Across 4 engines (@vllm_project, @sgl_project, TensorRT-LLM, LMDeploy), 6 attention backends, 3 GPUs (@nvidia H100/A100/L4) on Llama-3.2 (@AIatMeta) Qwen (@Alibaba_Qwen):
• T=0: 100% ID on engine, attention, GPU
• T=0.6: 76% engine / 58% attention / 59% GPU
• 113 prompts is enough
• Survives unseen batch sizes app prompts (99.7%)
Why prod leaders should care: pin your engine and an attacker aims CVE-2026-22778 (vLLM RCE) or CVE-2026-5760 (SGLang RCE) at it. "Just unify the kernels" isn't a defense — unified stacks add 100% latency.
Real mitigations cost utility: noise breaks deterministic decode, rate-limits are Sybil-evadable.
Determinism is now a security property.
arxiv.org/abs/2605.29979
37

May 29
AI agents are now building real exploits from code bugs. ExploitGym benchmark shows AI found 157 exploits in Linux These bugs could become live attacks very soon. Watch AI's attack power grow. #AISecurity #MLSec 🔗 Source in replies
1
22
May 28
AI agents can be tricked via files & memory, not just prompts. DeepTrap finds agent flaws in execution context. Compromised agents can still seem normal. Test AI agent execution deeply. #AISecurity #MLSec 🔗 Source in replies
1
21
May 27
LLM agents are now watermarked by their actions, not just text. New method embeds signals in decision sequences. Tracks agent origin and prevents reuse. Watch for behavioral tracking. #AISecurity #MLSec 🔗 Source in replies
1
20
May 26
LLMs can be tricked by prompts split across sessions. Attacks hide in fragmented, seemingly benign inputs. Current safety tests miss these cross-session threats. Watch for AI context drift. #AISecurity #MLSec 🔗 Source in replies
1
18
May 26
New AI defense catches 90% of sneaky LLM agent attacks. AgentShield uses fake tools and data to trap attackers. It works across languages, not just English. Better AI security is coming. #AISecurity #MLSec 🔗 Source in replies
1
18

There Is No Security Meter For AI. That's the title of the new Berryville Institute of Machine Learning paper from Gary McGraw, Harold Figueroa, Katie McMahon, and Richie Bonett. The argument: every "AI security score" you've been shown is theater. In 12 minutes vRon walks the badness-ometer, the Strange Loop, the WHAT pile, and where whitebox interpretability fits.
youtu.be/6hpvMzxNyCM 📄
#AISecurity #MLsec #BIML
1
166

HISTORY: In 1996, Plasmoid/THC published the article "Overflow," first in THC-MAGAZINE and later as a standalone.
github.com/hackerschoice/THC…
github.com/hackerschoice/THC…
@mlsec

7
30
2,604

Apr 15
Nature Communications just published this:
Large reasoning models (DeepSeek-R1, Gemini 2.5,
Grok 3, Qwen3) used as autonomous jailbreak agents
against other LLMs.
Overall success rate: 97.14%
AI attacking AI.
No human expertise needed.
Fully automated.
This is the threat surface we red team every day.
#MLSec #AIRed Team #CinderSecurity
210

Evasion, poisoning, model theft, LLM attacks — Varun Kumar's practical security guide covers them all. DVC is recommended for data provenance as part of a defense-in-depth strategy across the full AI lifecycle.
👉🏽 hubs.la/Q048vtPb0
🛡️ #MLSec

1
176
Apr 13
Anthropic just built an AI that finds zero-days
at scale — thousands of unknown vulnerabilities
across every major OS and browser.
They're calling it Claude Mythos Preview.
They're not releasing it publicly.
The era of AI-powered offensive security is here.
This is exactly why AI red teaming exists.
#MLSec #AIRed Team #CinderSecurity
28
Apr 10
Reported a deserialization vulnerability today.
Malformed model file → inference server crash.
No CVE. No prior reports. Clean zero-day.
Disclosure pending vendor review.
#MLSec #BugBounty #CinderSecurity
1
112

nobody scans ports to hack an AI agent. one poisoned document in the RAG pipeline and the model does the rest. NVIDIA and MITRE ATLAS mapped 66 #AISecurity attack techniques. here's where the chain breaks. #PromptInjection #MLSec
toxsec.com/p/ai-kill-chain-e…
1
1
37

Mar 16
Happy to serve on the PC of ACSAC 2026 (for 5th consecutive year!). Thanks @nicknikiforakis and @mlsec for the invitation. This event has grown over the year in size and quality, and is now clearly a landmark of excellence in our security research community.
3
114

Mar 11
the full preprint is available here: arxiv.org/pdf/2603.08225
source code will be made available soon!
also thank you to my co-authors @xorpse @binarly_io @mlsec @bifoldberlin
9
37
3,136

Feb 22
ModelScan is now on HackDB.
ModelScan protects security teams from serialization attacks by scanning ML models for unsafe code.
See it on HackDB:
hackdb.com/item/modelscan
#HackDB #CyberSecurity #AI #MLSec
5

Feb 3
Solana's AI boom faces a critical threat: AI-generated malware & autonomous espionage campaigns are on the rise. 🚨 Attack barrier is dropping fast. #CyberDefense needs AI too. Are you ready? #SolanaAI #AIAgents #Web3Security #MLSec bproud.blog/solanas-high-spe…
6


22 Dec 2025
Having a pretzel and beer sounds delightful. Excited for what SaTML will bring in 2026. 🎉
1
19