


Feb 6
“In the autumn of 1912, Ernst Zermelo stood before a small gathering of mathematicians in Cambridge and announced a result that would haunt the twentieth century. Chess, he declared, was solved, at least in principle. One of the two players, White or Black, must possess a winning strategy, or else both can force a draw. The game is finite; the tree of possibilities, though vast, terminates. Therefore, by the iron logic of mathematical induction, the outcome is determined before the first pawn moves.
The audience received this news with the peculiar mixture of satisfaction and unease that accompanies theorems of pure existence. Zermelo had proved that an answer existed without providing any hint of what that answer might be. His proof was what mathematicians call non-constructive: it demonstrated the existence of a winning strategy the way one might prove that a prime number greater than a googolplex exists: true, certainly, but utterly unhelpful to anyone hoping to find it.
This was Zermelo’s curse, and it would echo through the decades that followed. The chess tree contains more positions than atoms in the observable universe. Knowing that a perfect strategy exists tells us nothing about how to play well. The game is finite, but it might as well be infinite for any creature bound by time and matter. The gap between existence and construction, between knowing that an answer is there and actually finding it, would become the central drama of a field that did not yet have a name.”
Paths, Trees, Flowers, Conflicts captures the golden age of combinatorial optimization (and graph theory), the winding path towards recognizing that not all puzzles are easy to solve just because they are finite. Part 1, from Zermelo to Harary, is out now. #econtwitter #MLtools
carnegietech.substack.com/p/…

4
7
67
4,092
Feb 4
"Herbert Simon’s causality papers from the early 1950s have achieved recognition far beyond their original econometric context, becoming foundational for multiple fields that barely existed when he wrote them. The intervention-based conception of causality that Simon formalized has become the dominant framework in program evaluation, causal inference, and policy analysis.
Computer scientists building causal discovery algorithms cite Simon’s 1952 and 1953 papers as pioneering the graphical approach to representing causal structure. Philosophers analyzing counterfactual reasoning trace their frameworks to Simon’s emphasis on intervention and invariance. Researchers in machine learning developing methods for inferring causation from data draw on Simon’s insights about identifiability.
Yet the synthesis Simon never completed, between formal causal structure and bounded causal learning, remains unfinished even as modern approaches have developed tools Simon lacked."
Herbert Simon and Causality, now out as part of Seemingly Incompatible: Bounding Rationality at Carnegie Tech's Graduate School of Industrial Administration, 1949-74. #econtwitter #MLtools
carnegietech.substack.com/p/…
3
15
746

Demos and descriptions here → payhip.com/MythlineStudio
#LocalAI #OfflineAI #BuildYourOwnAI #LLMTools #AIDevelopers #DataEngineering #MLTools #DeveloperTools #IndieDevs #IndieHackers #AIInfrastructure #OwnYourStack #LocalFirst #NoCloud #OpenTools
1
2
12

17 Dec 2025
Most people use @OpenGradient like a demo.
Power users treat it like a workflow.
A few practical tips that make a real difference when using @OpenGradient day to day:
Start with one clear variable.
Instead of changing prompts, models, and parameters at once, lock everything except one input. This makes gradients and performance shifts immediately obvious instead of noisy.
Reuse gradients, not just outputs.
If a run behaves well, duplicate the gradient setup and iterate from there. You save time and preserve signal instead of restarting from scratch.
Think in evaluation loops.
Short runs fast feedback beat long, “perfect” runs. OpenGradient shines when you treat it as an experiment engine, not a one-shot generator.
Name and tag experiments early.
Future you will thank present you. Good labeling turns your history into a knowledge base, not a graveyard of runs.
Optimize last, explore first.
Don’t chase efficiency before you understand behavior. Exploration creates intuition, optimization compounds it.
OpenGradient isn’t just about better outputs.
It’s about learning why models behave the way they do — and turning that understanding into leverage.
#OpenGradient #AIWorkflow #ModelOptimization #MLTools #Builders

3
4
28

8 Dec 2025
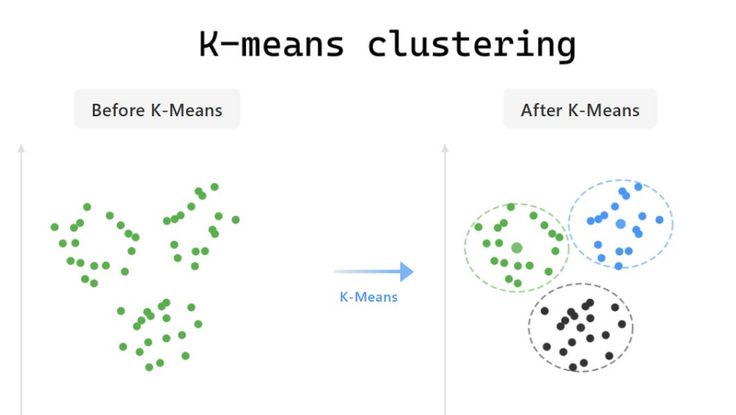
Tips on K-Means clustering
Group unlabeled data into K clusters based on similarity! E.g., segment customers by purchase behavior without predefined labels, centroids shift to minimize distances. #AI #MachineLearning #UnsupervisedML
Pro tip: Use scikit-learn; from sklearn.cluster import KMeans; kmeans.fit(X). Choose K with elbow method (plot inertia vs. K). Handles numeric data well, but sensitive to outliers preprocess! #MLTools #DataClustering
Why use it? Discovers hidden patterns fast. Tried K-Means on Iris dataset? Reply with results or tips. share your unsupervised wins! #ArtificialIntelligence

2
33

6 Dec 2025
Congrats @besimple_ai on YC!
If you love clean, labeled, training-ready datasets, check out DataGPU - open-source, automated cleaning, deduplication & ranking for ML datasets. Available as a Python package: pypi.org/project/datagpu/
Can be used in the same pipeline. Also feel free to support & contribute ❤️ to open-source tooling.
#OpenSourceAI #MLTools
5 Dec 2025

Congrats to @besimple_ai on their $3M seed!
They're building the data layer for AI, starting with audio. Besimple licenses and processes diverse conversational audio so teams can ship better voice models, faster.
besimple.ai/blog/announcing-…

4
56

18 Oct 2025
🧠 Hugging Face is the ultimate AI community hub — explore models, datasets, and APIs for machine learning projects of any scale!
#AI #HuggingFace #MLTools #Developers #Tech #Innovation #DataScience #AICommunity

1
55

15 Oct 2025
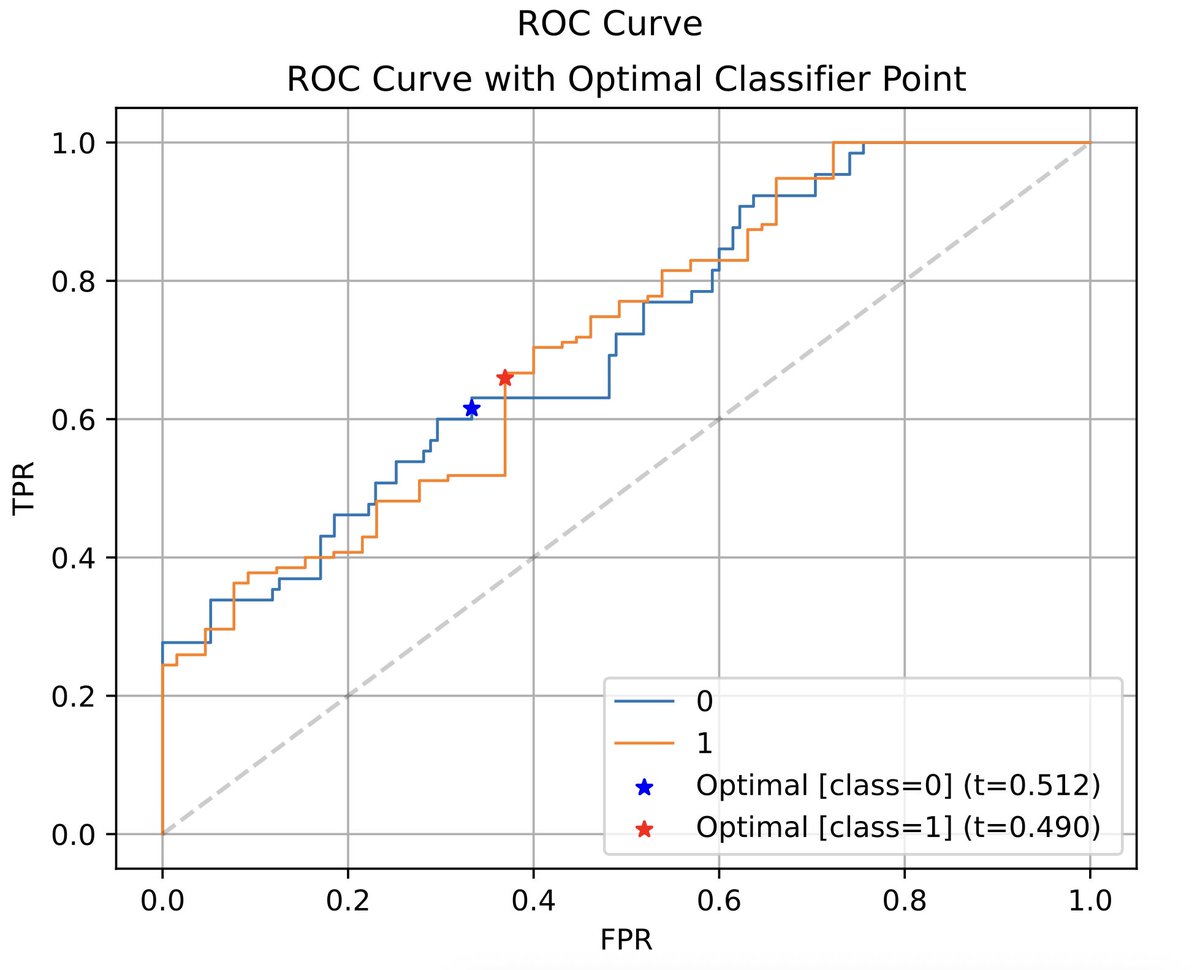
🚀 PyCM v4.5 is just out!
Find the best threshold for your probabilistic classifier across all ROC-based curves
Python Type Hints: cleaner, smarter, and more IDE-friendly
🔗 github.com/sepandhaghighi/py…
#Python #MachineLearning #DataScience #AI #OpenSource #MLTools #PyCM
2
3
143

2 Oct 2025
🔁 Compare & select top models in #Azure AI Foundry with the new leaderboard (preview)!
🔹 Rank by quality, cost & performance
🔹 Visualize trade-offs
🔹 Benchmark with your data
Learn more here 👉msft.it/6015sv1DU
#AI #MLTools
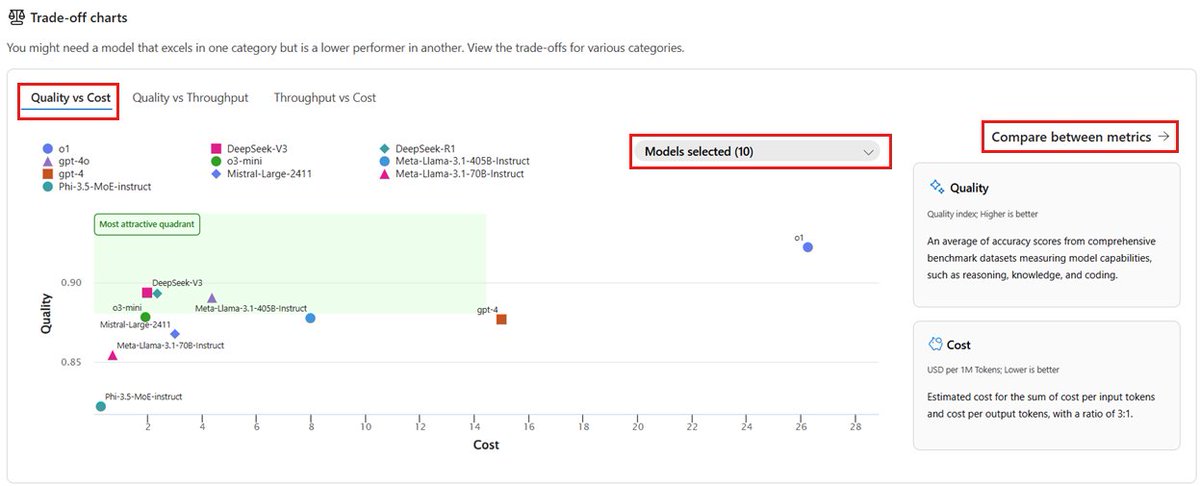
ALT Screenshot showing the trade-off charts in quality, cost, and performance.
3
9
3,753

26 Jul 2025
Building machine learning models is just one part of the journey... Understanding them is the real challenge.
Shapash is a Python library that brings transparency to machine learning by making model predictions understandable for everyone technical or not.
🛠️ Key Features of Shapash:
- Generates a WebApp for navigating global and local explainability
- Makes predictions easily interpretable with clear visualizations and labels
- Supports regression, binary, and multiclass classification
- Compatible with CatBoost, XGBoost, LightGBM, Scikit-learn, Linear Models, SVMs
- Helps summarize and export local explanations
- Offers metrics to evaluate the quality of explanations
- Allows filtering subsets (correct/wrong predictions, feature values) for deeper analysis
- Can be deployed via API or in batch mode for production use
🔍 Whether you're working on risk models, customer churn, or trading strategies if your ML model makes decisions, Shapash can help you explain why.
GitHub: github.com/MAIF/shapash?tab=…
Worth checking out if interpretability matters in your work.
Are you someone who wants to apply AI in trading?
Curious how GenAI, LLMs, and machine learning are changing the trading landscape?
Then this conference is for YOU.
🎯 QuantInsti’s Algorithmic Trading Conference 2025
📅 Date: 23 September, 2025
🕒 Time: 6:00 PM IST | 8:30 PM SGT | 8:30 AM EDT
💻 Free | Online | Global
What’s happening?
Workshop by Tucker Balch (Emory University)
Explore real-world use of AI, LLMs & price data in trading strategies.
See how AI models are predicting inter-stock relationships, with live Q&A!
Topics include:
- How AI is transforming trading desks
- Emerging skills for quants
- GenAI's role in quant education
- What the future of finance looks like with AI
👥 Who should attend?
- Aspiring Quants
- Traders & Finance Professionals
- Coders & ML Engineers
- Students & Career Switchers
🎟️ Ready to see how AI is shaping the future of trading?
🔗 Register now - spots are limited!
👉 quantinsti.com/algorithmic-t…
#AlgoTrading #AIinTrading #QuantConference #QuantFinance #GenAI #LLM #FinanceCareers #QuantLearning #QuantInsti #EPAT
#MachineLearning #ExplainableAI #MLInterpretability #XAI #Shapash #QuantFinance #AITransparency #PythonML #QuantInsti #MLTools
1
5
340

20 Jun 2025
🚀 #ScikitLearn 1.7 is here!
✅ Smarter #SparseArray support
⚠️ Improved #ConvergenceWarnings
🔢 Full #ArrayAPI integration
Upgrade now:
pip install --upgrade scikit-learn
#MachineLearning #Python #AI #DataScience #MLTools

1
42

13 Jun 2025
x.com/hyperbolic_labs/status…
🤘 AI/ML Engineers — time to ditch the cloud console.
With the Hyperbolic AI Cloud Extension, you can now:
⚡ Spin up an H100 directly from @code / @cursor_ai
🔐 SSH in, launch notebooks or inference endpoints — all in under 60 seconds
🧠 No more clunky dashboards. Just code. Build. Deploy.
Stay in flow. Stop context switching.
This is cloud, reimagined for serious AI builders.
Learn how to get started:
@hyperbolic_labs @hyperbolic_eacc
#gHyper #AIinfra #BuildWithHyperbolic #MLtools
 Hyperbolic
Hyperbolic
2
5
174

14 May 2025
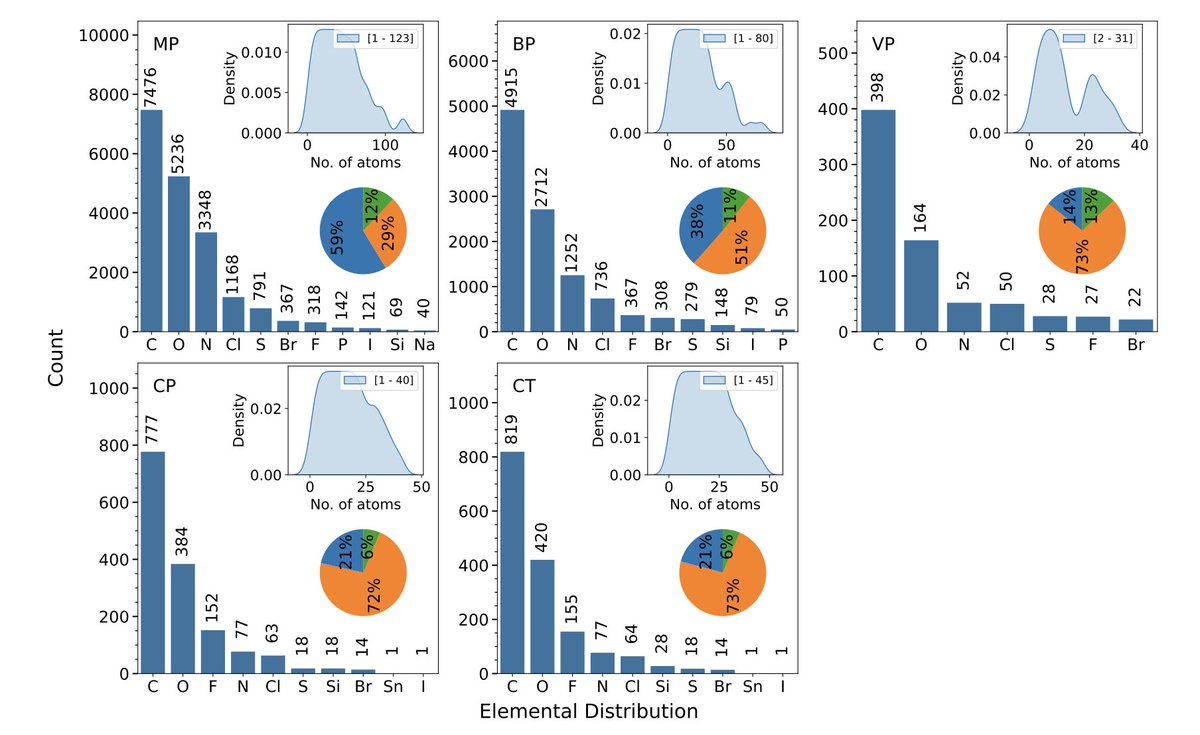
A Machine Learning Pipeline for Molecular Property Prediction using ChemXploreML
1.This work introduces ChemXploreML, a modular desktop application for predicting molecular properties using machine learning, offering flexibility, accessibility, and extensibility for chemists with varying levels of programming expertise.
2.The tool integrates multiple molecular embedding techniques (Mol2Vec and VICGAE) with powerful regression algorithms (GBR, XGBoost, CatBoost, LightGBM) to predict five key properties: melting point, boiling point, vapor pressure, critical temperature, and critical pressure.
3.Mol2Vec delivers slightly better predictive accuracy (up to R² = 0.93 for critical temperature), while VICGAE offers similar performance at a much lower dimensionality (32 vs. 300) and up to 10x faster computation—making it ideal for high-throughput screening.
4.ChemXploreML automates the entire pipeline: from chemical structure preprocessing and embedding generation to model training, hyperparameter optimization (via Optuna), and visualization of results through an intuitive desktop GUI.
5.Datasets were curated from the CRC Handbook of Chemistry and Physics, with SMILES representations canonicalized and cleaned using cleanlab to remove mislabeled or outlier data, ensuring high data quality for training robust models.
6.The system includes advanced visualization tools like UMAP for mapping high-dimensional chemical space, enabling users to explore structure–property trends and cluster molecules based on thermodynamic behavior.
7.Extensive benchmarking reveals that tree-based models paired with Mol2Vec embeddings excel in predicting boiling and critical temperatures, while VICGAE performs competitively—especially for challenging skewed properties like vapor pressure.
8.The modular framework supports future extensions, including ChemBERTa, MoLFormer, GNNs, and classification models, allowing researchers to tailor workflows to specific datasets or property types without code changes.
9.ChemXploreML's core contribution is bridging the gap between high-performance ML and practical chemistry workflows, offering an out-of-the-box platform for molecular design and property prediction in academic and industrial settings.
10.This study also highlights how embedding choice and property distribution shape model performance, with VICGAE emerging as a promising alternative to high-dimensional embeddings for fast, efficient learning on limited data.
💻Code: github.com/aravindhnivas/Che…
📜Paper: arxiv.org/abs/2505.08688v1
#Cheminformatics #MolecularPropertyPrediction #MachineLearning #Mol2Vec #Autoencoder #Regression #MLTools #ComputationalChemistry #UMAP #DataScience
5
14
1,274
14 May 2025
A Machine Learning Pipeline for Molecular Property Prediction using ChemXploreML
1.This work introduces ChemXploreML, a modular desktop application for predicting molecular properties using machine learning, offering flexibility, accessibility, and extensibility for chemists with varying levels of programming expertise.
2.The tool integrates multiple molecular embedding techniques (Mol2Vec and VICGAE) with powerful regression algorithms (GBR, XGBoost, CatBoost, LightGBM) to predict five key properties: melting point, boiling point, vapor pressure, critical temperature, and critical pressure.
3.Mol2Vec delivers slightly better predictive accuracy (up to R² = 0.93 for critical temperature), while VICGAE offers similar performance at a much lower dimensionality (32 vs. 300) and up to 10x faster computation—making it ideal for high-throughput screening.
4.ChemXploreML automates the entire pipeline: from chemical structure preprocessing and embedding generation to model training, hyperparameter optimization (via Optuna), and visualization of results through an intuitive desktop GUI.
5.Datasets were curated from the CRC Handbook of Chemistry and Physics, with SMILES representations canonicalized and cleaned using cleanlab to remove mislabeled or outlier data, ensuring high data quality for training robust models.
6.The system includes advanced visualization tools like UMAP for mapping high-dimensional chemical space, enabling users to explore structure–property trends and cluster molecules based on thermodynamic behavior.
7.Extensive benchmarking reveals that tree-based models paired with Mol2Vec embeddings excel in predicting boiling and critical temperatures, while VICGAE performs competitively—especially for challenging skewed properties like vapor pressure.
8.The modular framework supports future extensions, including ChemBERTa, MoLFormer, GNNs, and classification models, allowing researchers to tailor workflows to specific datasets or property types without code changes.
9.ChemXploreML's core contribution is bridging the gap between high-performance ML and practical chemistry workflows, offering an out-of-the-box platform for molecular design and property prediction in academic and industrial settings.
10.This study also highlights how embedding choice and property distribution shape model performance, with VICGAE emerging as a promising alternative to high-dimensional embeddings for fast, efficient learning on limited data.
💻Code: github.com/aravindhnivas/Che…
📜Paper: arxiv.org/abs/2505.08688v1
#Cheminformatics #MolecularPropertyPrediction #MachineLearning #Mol2Vec #Autoencoder #Regression #MLTools #ComputationalChemistry #UMAP #DataScience

5
648

29 Apr 2025
Machine learning without the right library? That's like coffee without caffeine! Check out these 10 awesome Python libraries that make your ML game strong.
#MachineLearning #PythonLibraries #DataScience #AI #DeepLearning #MLTools #TechStack #CodingLife #ArtificialIntelligence




1
2
83

24 Apr 2025
"I used to spend more time waiting for compute than actually training models.
Hyperbolic flipped the script.
Now my bottleneck is... me."
#Hyperbolic #AIworkflow #MLtools #DeepLearning #kaito #aidrop

4
6
96

2 Jan 2025
Master Logistic Regression in 2025!
Binary classification, sigmoid functions, and data splitting simplified for YOU. 📊 Dive in, learn, and shine in ML!
📌 Link in bio for your FREE cheat sheet > shorturl.at/mdGDe
#LogisticRegression #DataScience #AIForEveryone #MLTools #NewYear2025



1
5
167

29 Nov 2024
#136 MLOps Simplified: Bridging the Gap Between ML and Operations
#MLOps #MachineLearning #DataScience #AIinProduction #MLTools #AIAutomation #DevOps #AI #DataScienceDemystifiedDailyDose
linkedin.com/pulse/136-mlops…
8
7
51

26 Sep 2024
The AI Tools That Will CHANGE Your Life in 2024!
#TechInnovation #Chatbots #AI #ArtificialIntelligence #MachineLearning #AItools #AISoftware #MLtools #TechTools #Automation #AIdevelopment #TechTrends #meprogrammer #openai
youtu.be/00hdpOdak2w
1
2
102