

Jun 10
Exploração ad-hoc no Data Lake: Dá pra fazer consultas direto em arquivos Parquet, ORC e CSV no S3, usando Hive Metastore ou AWS Glue como catálogo. Sem precisar subir nada pesado pra isso.
1
37

Jun 9
Look at the matrix today. Unity is best in Databricks. Glue is best in AWS. Snowflake Horizon is best in Snowflake. BigQuery Metastore is best in Google. None of them play well with the others.

2
1
7
388

Jun 8
世界中で 日本含む #HavanaSyndrome #DEWS #HumanDeconstructionProject
#ムーンショット計画 #Digitaltwin #Trancehumanism #MetaStore etc…
#NeuroRights を #Emperor 知ってても どっちも大問題。全人類 全国民に知る権利を行使。技術を過去含め 全開示 求む。
🧠は聖域。制脳権の侵害で犯罪だ。
Jun 6

The Pentagon raised the threat of Israeli spying on the U.S. to its highest level, sources say.
Seeing as thousands of Brits are being tortured by the mysterious "Havana Syndrome", is it time to do the same in Britain?
Hear their testimony: youtu.be/3i4bl7tkT6Y
@KemiBadenoch @Nigel_Farage @RupertLowe10
@Conservatives @OliverDowden @pritipatel @SteveBarclay @JamesCleverly @CatharineHoey
@VictoriaAtkins @AndrewBowie_MP @Jeremy_Hunt
@CPhilpOfficial @gregsmith_uk @TiceRichard
@LeeAndersonMP_ @Arron_banks @drdavidbull @NadineDorries @danny__kruger @GrahamSMSP @murdo_fraser @RussellFindlay1 @jhalcrojohnston @LauraJ4SWEast @SarahForRuncorn @andreajenkyns @EstherMcVey1 @TomTugendhat
@AlecShelbrooke @MPritchardUK @GavinWilliamson
@RobertJenrick @NeilDotObrien @JuliaLopezMP @MelJStride @AlanMakMP @DrBenSpencer
@PeterTFortune @Matt_VickersMP @CIA
@TargetedJustice @Artdericko618 @jcartlidgemp
2
101

Google Cloud BigLake MetastoreをApache Iceberg RESTカタログ統合で接続する機能がGAになりました。ワークロードアイデンティティフェデレーションを設定することで、長期間有効なサービスアカウントキー不要でGoogle Cloudへの認証が可能です。...
docs.snowflake.com/release-n…
#Snowflake #SnowflakeDB
7
2,351

第五回Apache Iceberg Meetup Japanで使用した発表資料「Hive Metastoreを通して学ぶIceberg REST Catalog ― 仕様から実装まで」を公開しました。
speakerdeck.com/okumin/from-…
#iceberg_jp
4
17
1,322
今日開催です。Hive MetastoreとIceberg REST Catalogについて話します!
Apache Iceberg Meetup Japan #5 iceberg.connpass.com/event/3… #iceberg_jp
1
8
220

May 18
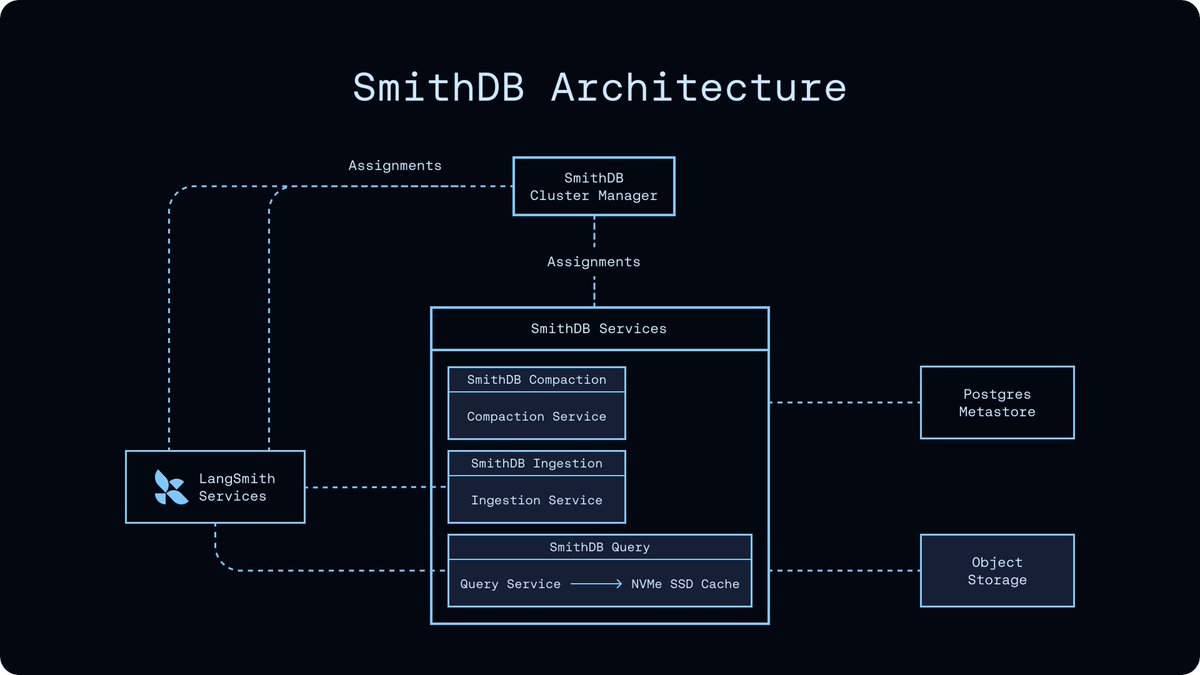
At a high level, it consists of 3 components:
1️⃣ Object storage for durable trace data
2️⃣ A small Postgres metastore for segment metadata
3️⃣ Stateless ingestion, query, compaction services
Performance
Slow observability tools are a bottleneck in the agent development loop. Core LangSmith experiences are now up to 12x faster.
Portability
SmithDB is backed by object storage, making it easier to deploy in self-hosted multi-cloud environments.
2
8
2,863

Coralogix's original metastore implementation, built on top of PostgreSQL, wasn't fast enough for their needs. Find out how they cut their query processing time from 30 seconds to 86 milliseconds. ow.ly/Bvrh50W4WUe
#ScyllaDB #P99CONF

10
476

May 12
Officially a TOP-RATED game on the Meta Store with a 4.9/5 rating. 🎖️ 👾⚠️
#Meta #MixedReality #VR #Gaming #MR #MetaStore

7
56
May 12
#NWO #ムーンショット計画
その裏では #TI #BMI #BCI 悪用 #MKウルトラ #人間OS化 政府→国民への人体実験です。#国家ぐるみの集団洗脳詐欺神話事件 #違法で犯罪の囮捜査 事件 #ニュルンベルク網領 #憲法13条 #憲法25条 違反 ←#ギャングストーキング #集団ストーカー #Digitaltwin #metastore 悪用
This tweet is unavailable
1
4
133

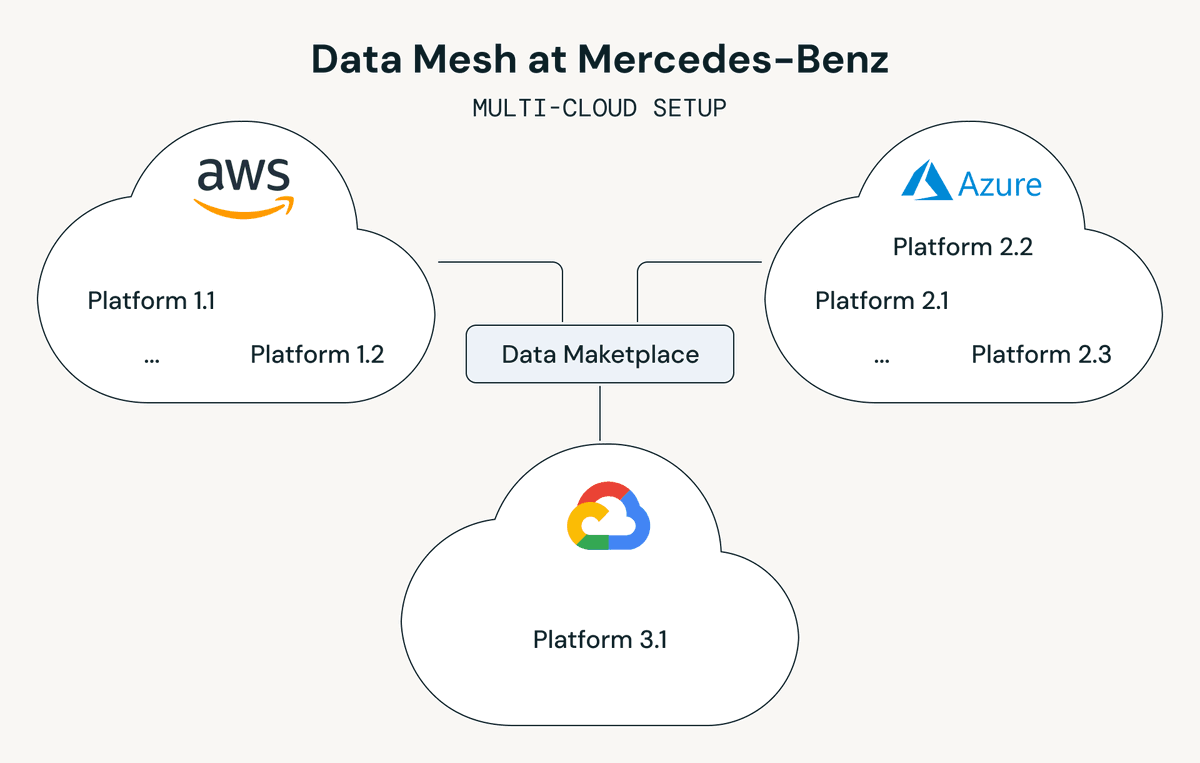
Mercedes-Benz が AWS と Azure をまたぐ約 60TB 規模のアフターセールスデータを、Delta Sharing と Delta Deep Clone を組み合わせてどう共有しているかを解説した記事です!マルチクラウドの egress コストとデータ鮮度のせめぎあいの現実解として効きそうなアプローチでした。
課題はかなり分かりやすく、AWS 側にある 60TB のアフターセールスデータに Azure 側のコンシューマーが直接アクセスすると egress コストが膨らみ、かつソース側は Iceberg、Azure 側は Delta 形式を期待していて形式も揃わない、というものです。従来は週次フルロードで 7 日遅延していたのを、もっと安く・新鮮なデータにしたい、という悩みでした
採用された構成は、Databricks の Delta Sharing(ストレージ間でテーブルを直接共有できるオープンプロトコル)と Unity Catalog による hub-and-spoke ガバナンス(中央の親カタログから各拠点へ権限を配るモデル)をベースに、Provider Metastore(AWS 側)から Cross-Cloud Share でテーブルを共有し、Azure 側の定期 Sync Job が Delta Deep Clone(差分だけコピーする Delta Lake のインクリメンタル複製機能)で ADLS上のローカルレプリカに取り込む形になっています。Azure のコンシューマーは手元のレプリカを直接クエリできるので、毎回クロスクラウドの egress コストがかさむ構成にはなりません
コストと鮮度の効果も具体的で、初期 10 データプロダクトで egress コストを 66% 削減、50 ユースケース相当の年次見積では 93% 削減、データ鮮度は週次 7 日遅延から 2 日ごとのインクリメンタル更新まで短縮!
マルチクラウド構成でデータ共有のコストに悩んでいる場合のサンプルケースとして参考にしていただければと思います!
1
1
12
1,117

May 6
🆕 New blog post! S3 Tables handles compaction and snapshot expiry as a managed feature. DuckDB 1.5.2 added native Iceberg writes. Put them together and you get a working lakehouse with two moving parts instead of five with no cluster, no metastore, and no maintenance cron job.
I built one end to end on OpenAQ air quality data: Terraform, a Graviton Lambda ingester, DuckDB on my laptop. It includes real benchmarks, real costs (pennies per month for the demo schedule), and the limitations worth knowing.
A public companion repo is included. Check it out!
lckhd.eu/tWKOrM

1
4
20
1,487
I just published Iceberg REST Catalog in No Time: A Quickstart with Hive Metastore and PyIceberg medium.com/p/iceberg-rest-ca…
1
2
235
REST Catalog APIの入門記事を書きました。
Hive MetastoreとPyIcebergではじめるIceberg REST Catalog最速入門 - おくみん公式ブログ blog.okumin.com/entry/2026/0…
#はてなブログ #iceberg_jp
1
3
9
1,000

We have a small milestone completed: The number of subscribers of our Studio's account has reached 50. meta.com/en-gb/experiences/p… #oculusdev #indiedev #metaquest #metastore

1
1
9
92

Apr 27
Two types of tables in Databricks:
1. Managed
Where Databricks manages both the metadata (the table schema, name, location in the metastore) and the underlying data itself
2. External
Tables where Databricks manages only the metadata in the metastore, not the underlying data
2
15
837
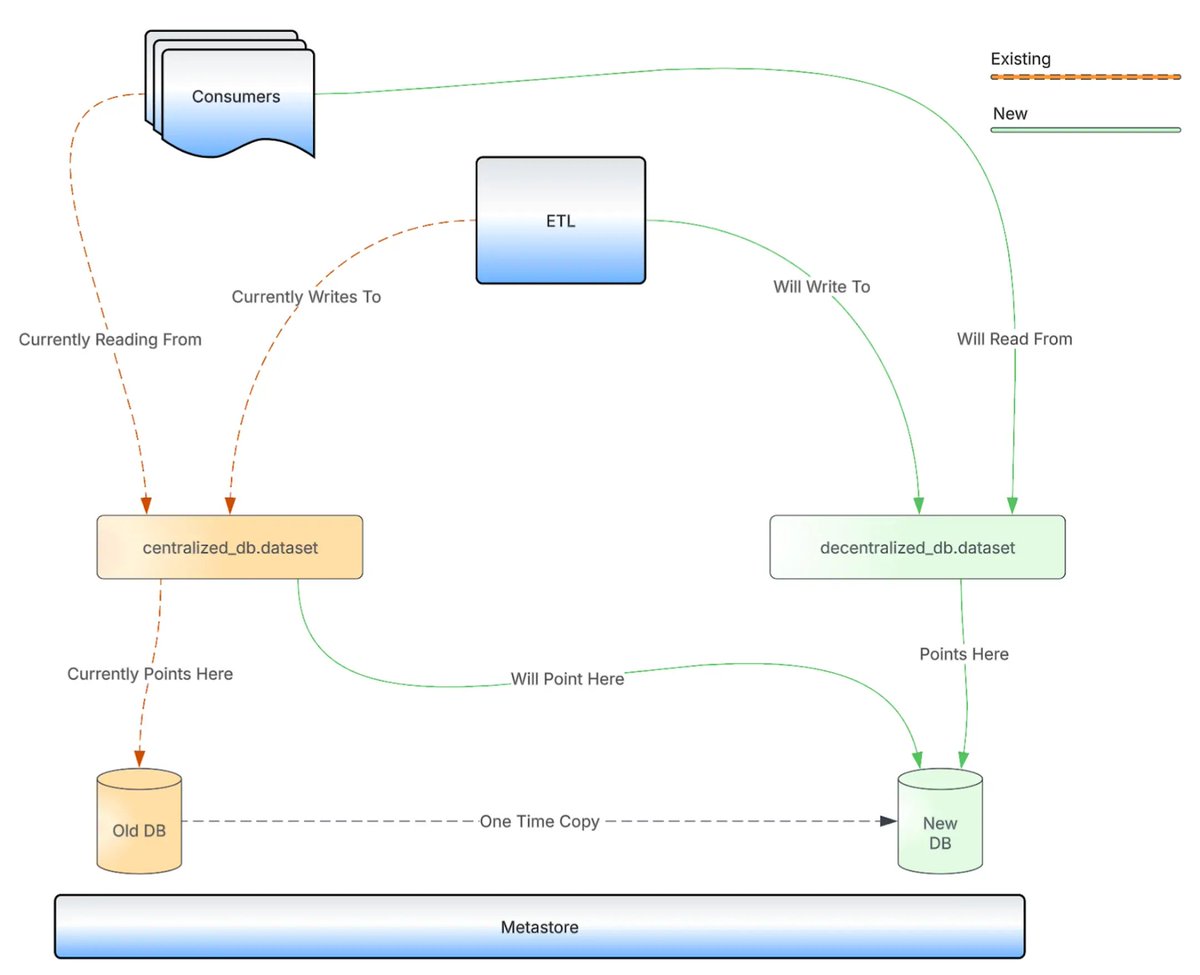
Uberでは、1万6,000以上のデータセットと10PBを超える膨大なデータが、単一のモノリシックなデータベース(Hive)で管理してましたが、この構成では特定のチームによるNoisy Neighborや、権限管理の複雑化、そして何よりデータ基盤チームがすべてのボトルネックになるという運用上の限界に
その対応としてUberはデータベースをドメインごとに分散管理へとゼロダウンタイムかつ既存のデータパイプラインに一切の変更を加えずに移行した
技術的な工夫の核となるのは、HDFS上のパスといった物理的なデータの実体はそのままで、メタデータ(Hive Metastore)の参照先を切り替えた、と言う方法
新しい分散環境にデータをコピーした後、ポインタを切り替えるだけで移行が完了するため、ユーザーやアプリケーションは背後で何が起きているかを意識する必要がなかったという話でした!
Blogなのかなんなのかわからんかったけど大作でしたw
1
15
1,666
