
Building LLM apps but flying blind on what's happening inside your RAG pipelines and agent tool calls? OpenInference extends OpenTelemetry with AI-specific tracing conventions so you get real observability without writing custom instrumentation from scratch. Full specs next tweet. #DevTools

1
11

Jun 12
Breaking: cost.cacheDiscountUSD → cost.cacheSavingsUSD.
"Discount" implied the provider gave you a break. They didn't. It's your money you didn't spend because you re-sent the same context.
OpenInference and Helicone already used "savings". We were the odd one out.
1
14

Jun 12
💙 This is what we love to see.
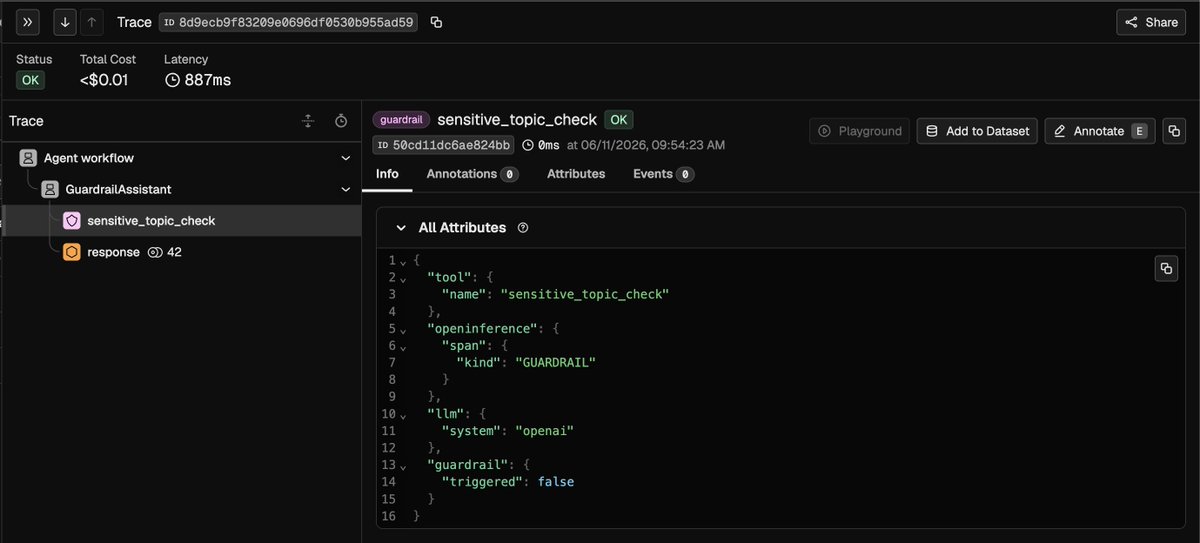
The new OpenAI Agents SDK (TypeScript) integration for Phoenix wasn't built by us, it was contributed by Xinde Li, a software engineer at Tencent. 🙌 Thank you!
It auto-traces your agent runs end-to-end: agent steps, LLM calls, tool calls, handoffs, and guardrails as OpenInference spans in Phoenix.
You can even see exactly when a guardrail fires (or doesn't 👇). Here's a sensitive_topic_check span: kind GUARDRAIL, triggered: false - the check ran, the content was clean, and you have full visibility either way. No code-reading required.
Get started with a single command:
npm install @arizeai/phoenix-otel @arizeai/openinference-instrumentation-openai-agents @openai/agents
📖 Docs → arize.com/docs/phoenix/integ…
1
3
236

Jun 11
I built an AI trading system that argues with itself, turns its reasoning into YouTube Shorts, and rewrites its own behavior using Phoenix traces and MCP introspection.
medium.com/@michiyamamoto/i-…
#GoogleCloud #ArizeAI #AIAgents #BuildWithGemini #MCP #OpenInference
19


📺 Watch the conversation behind the project.
@rachelnabors interviews the Arize team behind @ArizePhoenix @mikeldking, @axiomofjoy, and @RogerYang421599 and cover the GPT-3 pivot, building Phoenix backwards, and the OpenTelemetry bet that led to OpenInference.
youtube.com/watch?v=osTNToMf…
1
1
4
454

@AgnoAgi ships Agno v2.6.12 with new file gen, UI events, and model upgrades
New features
→ Add HTML file generation with example app
→ Add AG-UI state events support
→ Add Tuning Engines as model provider
→ Add WorkOS example for RBAC
→ Add Latitude via OpenInference observability example
Improvements
→ Upgrade MiniMax default model to M3
→ Update WhatsApp README for new Meta dev dashboard
→ Enhance README with extra resource links
Bug fixes
→ Use drop_ratio_search for Milvus hybrid search
→ Fix ArxivReader Client.results() usage
→ Guard against IndexError on empty runs list
→ Skip tokenizer tests on HuggingFace errors
→ Fix enable_agentic_state schema for dict params
→ Preserve AG-UI multimodal inputs
→ Pin ag-ui-protocol≥0.1.14 to prevent validation error
Agno advances steadily with practical enhancements and fixes.
github.com/agno-agi/agno/rel…
2
8
152
Microsoft picked OpenInference. Twice.
The open trust stack for AI agents announced at #MSBuild, ASSERT for evaluation, ACS for controls, both ride on the open tracing standard Arize built for agents.
arize.com/blog/microsoft-ope…
1
3
154

May 17
Langfuse久しぶりに触ったけど、スキル経由で概念知らなくてもエージェントに導入任せられたり、DSPyと合わせて使うとOpenInferenceの標準化に沿って、事前定義されたObservation Typeがスッとついたり便利だな
langfuse.com/docs/observabil…

5
368

May 8
We at @arizeai shipped an OTel middleware for @tan_stack AI a few weeks ago npmjs.com/package/@arizeai/o…
@ arizeai/openinference-tanstack-ai ships otel traces for your LLM calls directly to the backend of your choice, adhering to the Openinference Specification github.com/Arize-ai/openinfe…
I'm super glad to see first party OTel integration with TanStack AI, excited to see what ideas we can share
1
2
9
369

May 5
HoneyHive v2 is here. A ground-up refactor of the platform, built around the boundary your enterprise security team cares about most: the sensitive logs inside agent traces.
Traditional observability spent years learning to expunge sensitive data. Agent observability has to do the opposite. To supervise and statistically evaluate an agent, you need LLM payloads and tool calls verbatim - every transcript, PII/PHI/PCI field, privileged message, and proprietary prompt. That’s exactly the data ordinary observability was designed not to store.
So we rebuilt @HoneyHiveAI around two questions: where does that data live, and who is allowed to touch it once it’s there.
v2 splits HoneyHive into a control plane and one or more data planes. The control plane holds structure and metadata, but never the input or output payloads themselves. The data plane holds everything sensitive plus the compute that runs evaluators, search, and feedback over it. Evaluators are defined once in the control plane but fetched and executed inside the data plane, so raw logs never leave the data plane; only metric labels and metadata flow back up.
On top of that:
− New Python SDK with a small core and pluggable, OTel-based instrumentors, so different services can run different AI package versions without dependency hell and export spans to HoneyHive and your existing backend from the same instrumentation.
− A new TypeScript API SDK, with a higher-level tracing SDK on the way.
− First-class integrations for Claude Agent SDK, OpenAI Agents, Google ADK, AWS Strands Agents, and more, all normalized into a single HoneyHive semantic convention.
− Support for all 3 major GenAI OTel conventions (OpenTelemetry GenAI, OpenLLMetry, OpenInference), normalized into one consistent surface so your evaluators and dashboards survive framework changes.
− A new Trajectory view that gives you a visual fingerprint of an entire agent session instead of a 1,000-row trace you scroll through.
A Global Top 10 bank has been running this architecture for months, rolling HoneyHive out across multiple business units and regions while keeping each team’s data inside its own isolated data plane.
HoneyHive v2 is available in early preview starting today. This has been a long time coming - can’t wait to see what you all build on it.
More from my co-founder @Mohak__Sharma here: honeyhive.ai/post/introducin…
Sidharth Prakash, Mike Jonas, Mike Arndt, Sunny Bakhda, Edward S, @nebrius, Joshua Paul, Skylar Brown, @sanjeed_i, @ItsTeddyOwen
1
2
6
246

May 5
Today we are announcing @honeyhiveai v2.
Traditional observability tools spent years learning to redact sensitive data, but you can't grade a support agent's reply without the transcript that prompted it. Agent observability must preserve data verbatim to evaluate against. So where does that data live? And who's allowed to touch it once it's there?
v2 answers both. Our new architecture keeps raw logs and eval compute inside your data plane, while the control plane only ever sees non-sensitive metadata. Our new RBAC system gates every read, write, and permission change.
Together, this is what lets Fortune 500 customers roll HoneyHive out firmwide, across business units, regions, and the most regulated AI workloads in the company.
Meet HoneyHive v2:
- Split control plane and data plane. Raw traces and eval compute stay in your data plane; the control plane only sees non‑PII metadata.
- Granular RBAC and custom roles. Every read, write, and permission change is gated.
- Workspaces. Org → Workspace → Project. Each gets its own keys, controls, and data boundary.
- Templates. Define evaluators and monitors once, populate everywhere.
- New Python and TypeScript SDKs. Small core, pluggable instrumentors.
- HoneyHive semantic convention. OpenLLMetry, OpenInference, and official OTel GenAI normalized into a single surface.
- Trajectories. A visual fingerprint of a long-running agent session.
- CLI, Docs MCP, and Skills. Work with HoneyHive from your terminal, IDE, or coding agent.
…and many more quality‑of‑life improvements across the board.
HoneyHive v2 will be rolling out to users over the next week. Existing customers will be migrated over the next few weeks, and v1 will remain available for 6 months to give you time to update any remaining integrations.
Huge thanks to the HoneyHive team for the work that went into this release.
And thank you to every customer, design partner, and early user who pressure‑tested v2 with us. We can't wait to see what you build on it.
Excited to share this moment: honeyhive.ai/post/introducin…
@ds3638, Sidharth Prakash, Mike Jonas, Mike Arndt, Sunny Bakhda, Edward S, @nebrius, Joshua Paul, Skylar Brown, @sanjeed_i, @ItsTeddyOwen
15
13
58
503,570
May 2
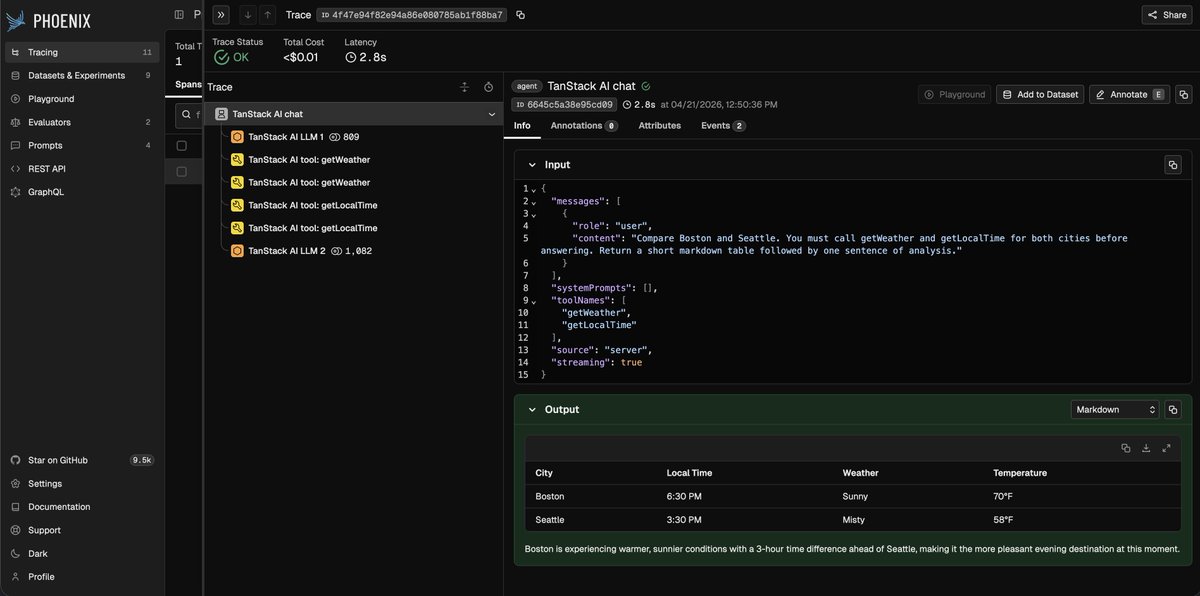
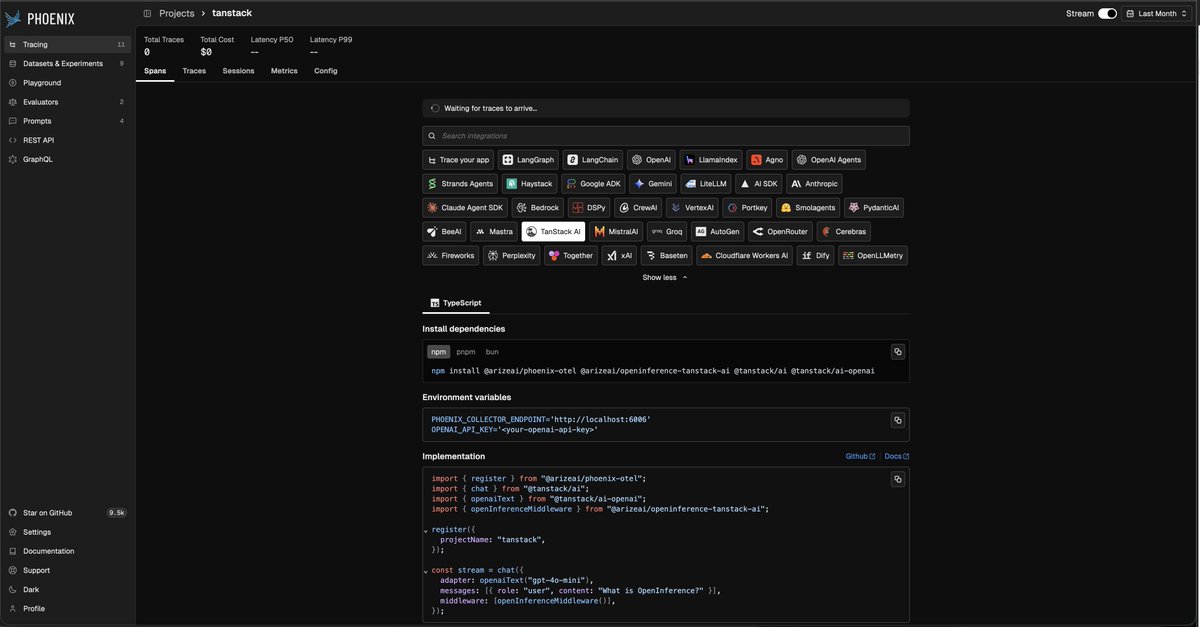
the team behind @tan_stack query, router, and table shipped tanstack ai: a typed, streaming, tool-calling chat layer for typescript.
today we’re shipping the openinference middleware for it!
middleware: openInferenceMiddleware()
one line and every chat() run streams into phoenix as fully-shaped traces: agent, llm, and tool spans, with inputs, outputs, and tokens. works for streaming and non-streaming runs, multi-turn loops, and any provider.
Full-stack OSS. Let us know what you think!
npmjs.com/package/@arizeai/o…
arize.com/docs/phoenix/integ…
2
8
348
Apr 29
Three years ago we started OpenInference because there was no standard way to trace an LLM call, let alone an agent.
OpenTelemetry was always the right home — same primitives as the rest of the stack, no parallel system bolted on for AI.
At Google Cloud Next, Arize and Google Cloud put a public marker on the convergence: OpenInference OTel as the standard for agent observability. GCP telemetry flows directly into Arize. No translation layer.
The arc that made traditional software debuggable, finally bending toward agents.
youtube.com/watch?v=nLH0IqHL…
@jason_lopatecki (Arize) · Ameer Abbas & Rami Shalom (Google Cloud)
1
4
7
363
Apr 29
OpenInference instrumentation updates (Apr 29) are out:
github.com/Arize-ai/openinfe…
Focused fixes across Python packages a breaking MCP change:
• python-openinference-instrumentation 0.1.48
- Fixes Pydantic attribute serialization in JSON mode (avoids incomplete/malformed trace payloads)
• python-openinference-instrumentation-openai-agents 1.4.2
- Corrects SpanKind for GuardrailSpanData (better trace semantics downstream analysis)
• python-openinference-instrumentation-smolagents 0.1.27
- Proper ChatMessage handling in LLM input parsing (better compatibility w/ typed agent frameworks)
• python-openinference-instrumentation-autogen 0.1.11
- Makes UserInfo optional for streaming partial responses (unblocks incremental/streaming pipelines)
• python-openinference-instrumentation-mcp 2.0.0 ⚠️
- Introduces streamable_http_client (first-class streaming transport support)
- Breaking change if you depend on previous client interfaces
2
117
Apr 25
Manual LLM tracing just got one install lighter.
arize-phoenix-otel 0.16 re-exports OpenInference context managers and semantic conventions straight from phoenix.otel.
from phoenix.otel import register, using_session, SpanAttributes
arize.com/docs/phoenix/relea…
1
3
236

Mar 27
Congrats to @MistralAI on the Voxtral TTS release. For folks in the voice space, we love the open source innovations! And at @arizeai we got that day 0 support!!
Had a little time at the end of my day to vibe a quick demo and test the model! I thought it did pretty well with all my filler words and i tried to stutter and give it incoherent sounds
Check it Voxtral - mistral.ai/news/voxtral-tts
and our OpenInference @pipecat_ai instrumentor into @ArizePhoenix

2
4
112

Mar 18
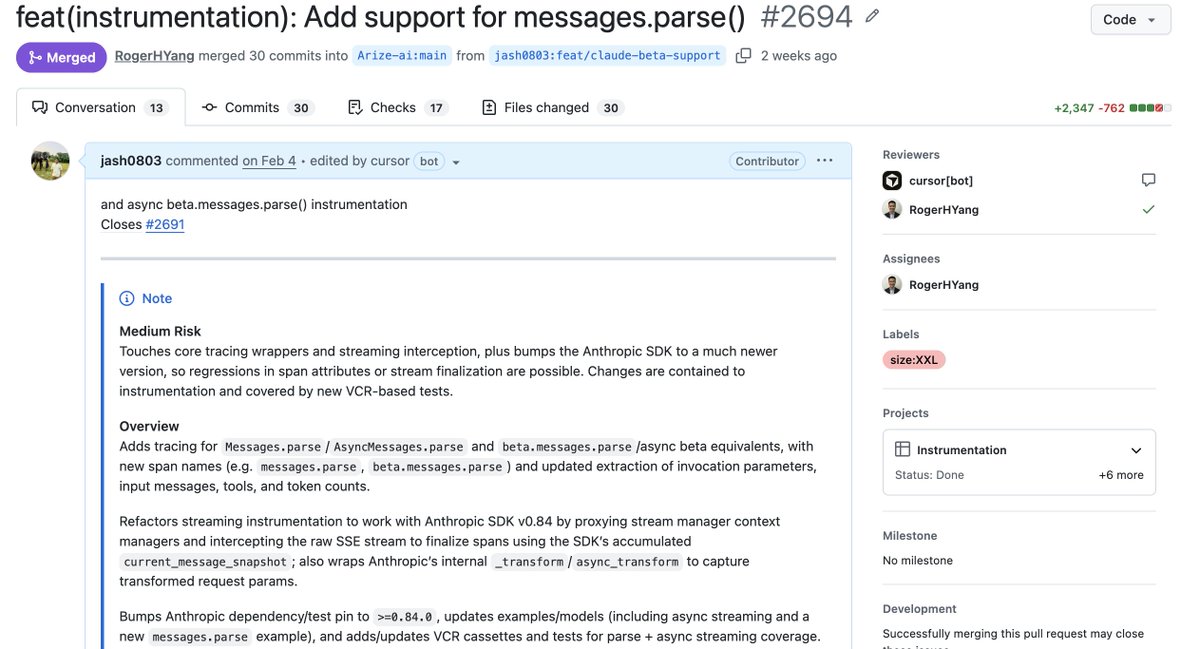
Found that beta.messages.parse() had no tracing support in openinference-instrumentation-anthropic while building our Anthropic observability stack with @arizeai 's Phoenix.
Filed issue #2691, opened PR #2694, and it shipped in the v1.0.0 major release.
github.com/Arize-ai/openinfe…
#OpenSource #LLMOps #Anthropic #ArizeAI
1
2
87

Mar 18
When we started building @FutureAGI_ 's observability stack, we faced a fundamental architecture decision: build proprietary tracing from scratch or build on OpenTelemetry. We chose the latter.
Because OTel is the best infra the industry ever standardized on, and we were not going to reinvent that.
But it just speaks the language of traditional software. What OTel doesn't have is a vocabulary for AI. It does not understand embeddings, prompts, token counts, model versions, or hallucinations. The primitives existed, but the AI-specific semantics did not.
The ecosystem around us- Traceloop (acquired by ServiceNow)'s OpenLLMetry was the closest attempt which now lives inside an enterprise roadmap (ServiceNow). @arizeai 's OpenInference doesn't follow proper GenAI/OTel conventions, has inconsistent framework support, and breaks the moment you try to send traces anywhere standard like Datadog.
This gap is why traceAI exists. It sits on top of OTel and defines conventions for AI workloads - auto-instrumentation for 35 providers- @OpenAI , @AnthropicAI, @LangChain , @llama_index , @crewAIInc , Bedrock, Vertex and others.
Every LLM call, retrieval operation, agent step traced automatically with meaningful attributes. No manual instrumentation. Supports Python, TS, C#, Java, connects with any observability backend- no vendor lock-in!
The hard problems were streaming - OTel assumes request-response, tokens don't and ecosystem fragmentation. Every framework handles LLM interactions differently. No shortcuts. You have to understand each one from the inside.
The result: two lines of code. "The chatbot failed" becomes "retrieval returned irrelevant chunks from document X, page 14, because the embedding query was too generic." That specificity is what makes debugging tractable.
We're continuing to contribute AI-specific semantic conventions back to the OTel community as the ecosystem matures. If LLM tracing should be as standardized as HTTP tracing, this is where it starts.
Two lines of code. Open source. Staying that way....Give us a star if you like, or better- contribute, flag issues and share your honest feedback!
github.com/future-agi/traceA…
3
5
112