
Want to move from theory to real‑world data engineering? Dive into open‑source tools, solve practical challenges, and learn how pros build scalable pipelines using #Apache projects. 📚 #BigDataTools #DataPipelines #OpenSourceData #Spark #Flink
🔗 ow.ly/qhgf50YEvvb

1
178

May 18
Open source satellite patterns isolated the IRI ship with consistent tracking precision. This reveals public intel's growing precision advantage in maritime monitoring.
#OpenSourceData #MaritimeIntel #SatelliteTracking #PublicIntelligence

1
5
54
Want to move from theory to real‑world data engineering? Dive into open‑source tools, solve practical challenges, and learn how pros build scalable pipelines using #Apache projects. 📚 #BigDataTools #DataPipelines #OpenSourceData #Spark #Flink
🔗 ow.ly/qhgf50YEvvb

2
93
Want to move from theory to real‑world data engineering? Dive into open‑source tools, solve practical challenges, and learn how pros build scalable pipelines using #Apache projects. 📚 #BigDataTools #DataPipelines #OpenSourceData #Spark #Flink
🔗 ow.ly/qhgf50YEvvb

2
2
93
Want to move from theory to real‑world data engineering? Dive into open‑source tools, solve practical challenges, and learn how pros build scalable pipelines using #Apache projects. 📚 #BigDataTools #DataPipelines #OpenSourceData #Spark #Flink
🔗 ow.ly/qhgf50YEvvb

2
120

17 Oct 2025
Evaluation of machine learning models for condition optimization in diverse amide coupling reactions
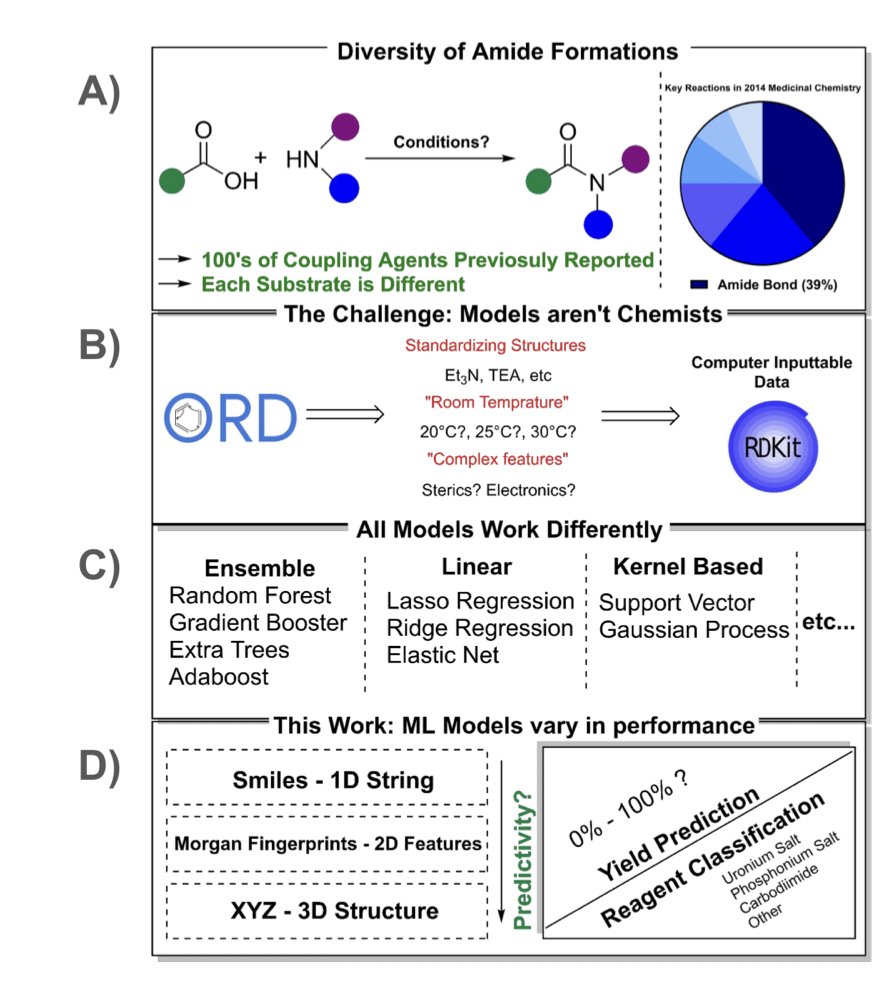
1. This study explores the application of machine learning in optimizing reaction conditions for amide coupling reactions, a crucial process in medicinal chemistry that accounts for over 40% of synthetic transformations. The research leverages the Open Reaction Database (ORD) to standardize and filter reaction data, training 13 different machine learning models to predict optimal reaction conditions and yields.
2. A key innovation is the use of various levels of structural data, from 1D SMILES strings to 2D Morgan Fingerprints and 3D XYZ coordinates, to enhance model performance. The study finds that while higher dimensionality significantly improves classification accuracy for coupling agents, its impact on yield prediction is more model-dependent.
3. The Extra Trees Classifier emerged as the highest-performing model for classifying coupling agents, achieving an accuracy of 0.873. For yield prediction, the Gradient Boosting Regressor showed the best performance with an R2 of 0.801. These results highlight the potential of ensemble-based models in handling complex reaction data.
4. The study also investigates the impact of different molecular properties on model performance. It concludes that local molecular environment features, such as those captured by XYZ coordinates and Morgan Fingerprints, are more relevant for prediction than bulk material properties like molecular weight and logP.
5. Validation on literature-reported data outside the ORD database revealed that the models struggled with substrates containing multiple competing amines and substituted benzoic acids. This suggests that the diversity and availability of data are critical factors affecting model accuracy.
6. The authors propose that increasing the availability of open-source reaction data could further improve model predictivity. They also suggest that this workflow could be scalable to other common reactions, such as Suzuki and Buchwald-Hartwig cross couplings, opening new avenues for machine learning in chemical synthesis.
📜Paper: doi.org/10.26434/chemrxiv-20…
#MachineLearning #ChemicalSynthesis #AmideCoupling #ReactionOptimization #OpenSourceData
4
725

12 Aug 2025
[PhD studentship]
Exploring #opensourcedata to improve #surfacewater #floodrisk assessment
The student will be supervised by Profs Raziyeh Farmani and @AlbertChen_CWS and Mark Veasey (@lv)
Apply by 05/09/2025
👇More details & application👇
exeter.ac.uk/study/funding/a…

5
5
204

26 Mar 2025
All data will soon be open source #OpenSourceData
Smart move from @elonmusk and @X to get more data into Grok AI for training and inference from #Telegram. Pretty soon we can ask AI questions that span more data then even the @NSAGov unconstitutional stealing of private collected on all humans (#prism).
This time it's public, it's actually legal, respects our privacy and constitutional rights. #AI @Snowden
#HumanRights #privacy @knuff
3
728

3 Mar 2025
Unmatched Data Moat —4 years, 5000 commits —our massive open-source dataset powers the #DevDapp rewards engine. Build with confidence. 💪 #OpenSourceData
88

1 Feb 2025
Open data is central to AI, the public sector and business success today. Our world leading speakers tackle AI to Space in the open data track. Will you join them on 4th and 5th February? See Schedule and get tickets stateofopencon.com #opendata #opensourcedata #soocon25 #stateofopencon

3
4
208

2 Jan 2025
Right off the bat, Neil Anderson of Skillshark Athlete Evaluations, spoke about sharing data and getting rid of all the paper. #ABCA2025 #OpenSourceData

1
6
378

8 Nov 2024
If you are considering migrating your data warehouse to an open data lakehouse, that’s a smart move—but there’s a catch!
You've now unbundled a database and need to step in to manage this data. Without a solid grasp of data optimizations and table management required, you might not see the expected ROI.
Here’s what to keep in mind 👇
⚙️ Performance Matters: Data lakehouses require different tuning than traditional warehouses. You might not see the efficiency gains you’re expecting without the right optimizations.
📉 Cost Control with Maintenance: Regular table services—like compaction, file size optimization, clustering and cleaning up old versions—help keep your lakehouse lean and costs predictable.
📊 Data Freshness & Reliability: Properly optimizing table storage for your write/read patterns ensures that your data is fresh and ready to support the real-time needs of your business.
🛠️ Know Your Tools: Each lakehouse platform (like @apachehudi ) has a unique set of features for data layout, compaction, and clustering. Invest time in understanding these to maximize the platform’s potential.
Just writing data in an open format alone won’t cut it! Understanding these aspects is essential to achieving the results you’re after—whether it’s faster queries, lower costs, or more reliable data insights. 💡
#datalakehouse #bigdata #dataengineering #apachehudi #datamigration #DataOptimization #OpenSourceData #DataWarehouse #OpenSource
onehouse.ai/blog/how-to-opti…
5
14
2,111

22 Jun 2024
New project:@0xmizu_ai
(follower 124)
Bio:MIZU is the very first synthetic open data layer. Our mission is to build an open, collaborative, and permission-less data ecosystem. #ai #web3 #opensourcedata
alert follower:@avichal

1
3
786

13 Jun 2024
A new journal article by START Founding Director Dr. Gary LaFree assesses the impact of #OpenSourceData on the study of #terrorism. tandfonline.com/doi/full/10.…
#TerrorismResearch #PsychologicalStudies #AcademicResearch #SecurityStudies #Radicalization

2
3
389

10 Apr 2024
Stay tuned for her amazing chapter in our #RiggedGameHandbook, coming out later this year with @springerpub @SummerRose721 #opensourcedata #openaccessdata #stolenheritage #lootedheritage

Detecting Deception in Art Provenance Texts
#NEW video
👉youtube.com/watch?v=AXwjBoC0…
Presentation of a computational approach, published online in honor of #provenanceresearchday
Rigged Game conference
#digitaltools #NLP #artlaw #tagderprovenienzforschung #provenanceresearch
6
508

29 Feb 2024
Season 6 is here! Join @CharnaParkey and @rusic_milos CEO and co-founder @deepset_ai discussing his journey, @Haystack_AI, Deepset cloud, and #trust.
Learn More: open-source-data.simplecast.…
#OpenSourceData #LLMs
youtube.com/shorts/HvMHhQz0c…
1
3
130
13 Dec 2023
Don't miss @sramji, @sogrady, and Stefano Maffulli of @OpenSourceOrg, discuss the intersection of open source and AI, good data for everyone, and open data foundations: bit.ly/2steOSD
#OpenSourceData #OSI #RedMonk #OpenSourceAI #AI #OpenDataFoundation #GoodData
1
1
6
1,214

13 Dec 2023
@DrEmilineSmith and I have signed a contract with @springerpub to edit a volume addressing #ethics #Legal #methological and #empiricalcasestudies surrounding #opensourcedata and the trade in #culturalheritage. We have a few more slots available if you would like to contribute!
13 Dec 2023

📢CALL FOR CHAPTERS📢
We already have a fantastic lineup of e.g. @poetryinstone @E_Peacock_ @eviehandby @StaffanLunden @mdippoli @Pooski_pie but there's room for more!
Especially welcome = contributions from ECRs, practitioners & underrepresented voices.
❗Abstracts due 15 Jan❗

3
11
4,089
15 Nov 2023
Throw’n it back to e52 with @sramji, @BazeleyMikiko, @ZainHasan6, and @tuanacelik. Learn what it means to be an AI-first ecosystem provider. Hear about their projected application experience …. and compare to what it has become: bit.ly/tb52osd
#OpenSourceData #AINative
4
5
491

11 Nov 2023
On 11/15 @ 12:40pm (PST) - Come meet some of the 🧠 behind #OneTable at the inaugural #OpenSourceData Summit. Register for the virtual session free at: opensourcedatasummit.com/
#datalakehouse #apachehudi #apacheiceberg #deltalake #microsoftfabric #bigquery

2
9
933