
May 21
RLWRLD CTO Jaekyeong Bae took the stage at Amazon Web Services (AWS) Summit Seoul 2026 to share what the team has been building 🙌
At RLWRLD, we're obsessed with one thing: dexterous hand manipulation — robots that actually work with their hands the way people do. Not lab demos, but hands that hold up on real factory floors. That mission is what led to RLDX-1, the model we recently released.
The short pitch on RLDX-1: it's a VLA model, but with three senses turned way up. · Sharper motion understanding · Force & tactile signals — the things vision alone can't catch · Memory that pulls in past context when the task calls for it
Less "a robot that sees," more "a hand that feels and remembers."
On the infra side, large-scale pretraining runs on AWS ParallelCluster, with imitation learning and reinforcement learning layered on top to push task performance where it needs to be.
What's next: deeper multimodal sensor fusion, and World Model–driven action generation. The goal stays the same — hands that do real work, in the real world ✋
#PhysicalAI #VLA #Robotics #RLDX1 #RLWRLD #AWSSummitSeoul


1
7
889


Apr 9
AWS HPC Blogに寄稿しました 🎉
ライフサイエンス研究のHPCインフラをAWSでモダナイズした事例を、JSR様と共にまとめました。
JSR様はゲノム解析やタンパク質構造予測、医用画像解析など、高度な計算資源を必要とするバイオインフォマティクス研究を行っています。
#AWS #HPC #ParallelCluster
1
1
5
378

S3をfuseマウントするのは遅くてイマイチだったので試してみたい。ただ課金が読みにくいな。EFSより安くなるよね?あとParallelClusterでのサポートがいつから入るのか。S3版管理との関係も気になるか。
Apr 7

Announcing Amazon S3 Files.
The first and only cloud object store with fully-featured, high-performance file system access.
Learn more here. go.aws/4tw17Zg
1
2
179

Mar 27
【ブログを公開しました】 #33Tech #Sansan技術本部 #Sansan
GENIAC における ParallelCluster GPU クラスタの構築記録 - Sansan Tech Blog
buildersbox.corp-sansan.com/…
4
2,775

Feb 19
BREAKING $AMD $AMZN 🚀🚀🚀
@amazon Announces GA of EC2 Hpc8a Instances with 5th Gen @AMD EPYC for HPC
Amazon today announced the general availability of Amazon Elastic Compute Cloud (Amazon EC2) Hpc8a instances, a new high performance computing-optimized instance type powered by the latest 5th Generation AMD EPYC processors with a maximum frequency of up to 4.5 GHz, AWS said.
These instances are designed for compute-intensive, tightly coupled HPC workloads, including computational fluid dynamics, simulations for faster design iterations, high-resolution weather modeling within tight operational windows, and complex crash simulations that require rapid time-to-results.
The new Hpc8a instances deliver up to 40% higher performance, 42% greater memory bandwidth, and up to 25% better price-performance compared to previous generation Hpc7a instances. Customers benefit from the high core density, memory bandwidth, and low-latency networking that helped them scale efficiently and reduce job completion times for their compute-intensive simulation workloads.
Hpc8a instances are available with 192 cores, 768 GiB memory, and 300 Gbps Elastic Fabric Adapter (EFA) networking to run applications requiring high levels of inter node communications at scale.
Hpc8a instances are available in a single 96xlarge size with a 1:4 core-to-memory ratio. Users can right-size for HPC workload requirements by customizing the number of cores needed at launch instances. These instances also use sixth-generation AWS Nitro cards, which offload CPU virtualization, storage, and networking functions to dedicated hardware and software, enhancing performance and security for your workloads.
Hpc8a instances can be used with AWS ParallelCluster and AWS Parallel Computing Service (AWS PCS) to simplify workload submission and cluster creation and Amazon FSx for Lustre for sub-millisecond latencies and up to hundreds of gigabytes per second of throughput for storage. To achieve the best performance for HPC workloads, these instances have Simultaneous Multithreading (SMT) disabled.

13 Dec 2025

$AMZN is a $400 stock| A Major $AMD Customer🧵
@amazon 's stock trades around $226 per share, valuing the company at approximately $2.45 trillion. Despite delivering blockbuster Q3 2025 results revenue of $180.2 billion (up 13% YoY), AWS revenue of $33 billion (up 20.2% YoY, the fastest since 2022), and EPS of $1.95 (beating estimates); the stock has lagged the broader Magnificent Seven cohort this year. This underperformance stems from persistent misconceptions about Amazon's business model, its capital allocation strategy, and its positioning in the explosive AI era. In reality, Amazon is not a maturing e-commerce giant burdened by low-margin retail; it is an AI and cloud powerhouse in the early stages of a massive growth acceleration. With sustained AWS reacceleration, vertical integration advantages, and prudent diversification in AI infrastructure, Amazon deserves a re-rating to at least $400 per share within 12-24 months, implying a market cap north of $4 trillion.
1. Q3 2025 ER showed Proof of AI Flywheel Ignition
Amazon's third-quarter results, reported in late October 2025, shattered expectations and signaled a clear inflection point. Total revenue reached $180.2 billion, exceeding forecasts by over $2 billion. More importantly, AWS is the profit engine contributing over 60% of operating income grew 20.2% YoY to $33 billion, far surpassing the anticipated 18% growth. CEO @ajassy highlighted "robust artificial intelligence demand" as a key driver, with custom silicon (Trainium and Inferentia chips) adoption surging 150% quarter-over-quarter. Net income jumped 39% to $21.2 billion, bolstered by operational efficiencies and a $9.5 billion gain from its Anthropic investment.These figures are not anomalies; they reflect the early monetization of Amazon's multi-year AI investments.
Retail and advertising segments provided steady support retail up ~10%, ads up 22-23% but AWS's reacceleration underscores that AI workloads are now driving meaningful top-line momentum. Yet the market fixates on short-term margin pressures from heavy spending, ignoring the long-term flywheel:
massive capacity buildout → attracted AI workloads → higher utilization and margins.
2. Common Misconceptions Fueling Undervaluation
~Amazon as "Just Retail": This outdated narrative persists despite AWS generating the bulk of profits. Retail remains resilient, with Prime delivery speeds at all-time highs and robotics scaling fulfillment efficiency. Advertising, a high-margin business, is booming amid e-commerce dominance. But AWS is the crown jewel, with a ~$200 billion backlog and AI demand "fully subscribed" for next-gen Trainium chips.
~CapEx as Wasteful Spending: Amazon guided to $125 billion in 2025 CapEx (up from prior estimates), with further increases expected in 2026 primarily for AWS infrastructure, custom silicon, and data centers with $AMD $NVDA as major suppliers. Critics view this as dilutive, but it's strategic fuel for dominance. Q3 showed margins holding steady despite investments, with early ROI evident in AWS growth. Hyperscalers like Amazon benefit from scale: higher CapEx drives future revenue at superior returns. As Jassy noted, demand is outstripping supply, justifying aggressive buildout.
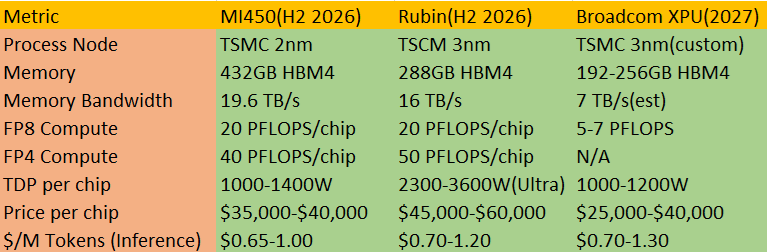
~Losing Cloud Share to Microsoft and Google: @awscloud holds 29-30% global market share in Q3 2025, down slightly from peaks but still leading Azure (20%) and Google Cloud (~13%). Rivals grew faster in spots due to AI partnerships (Azure-OpenAI), but the market isn't zero-sum yet overall cloud spend surged to $107 billion in Q3. AWS's vertical integration provides cost advantages, enabling competitive pricing and margin expansion. As $AMD MI450 Helios rack with the lowest TCO will be part of AWS Offering.
3. Valuation Case: Why $400 Is Justified
At ~35x forward earnings, Amazon trades below its historical growth-adjusted average, especially given 15-20% EPS growth potential from AWS (20-25% sustained) plus retail/ads leverage. As AI tailwind continues Q3 proves they are; a 45-50x multiple is reasonable for a leader in cloud/AI infrastructure. This yields $400-450 per share.Analyst targets (~$290-300 average) lag the momentum; Q3's beat and guidance signal upgrades ahead.
4. AMD EPYC as a Cornerstone of AWS
AWS has been a loyal AMD partner since 2018, launching instances powered by every generation of EPYC processors. This collaboration deepened in 2025:
~5th Gen EPYC ("Turin") powers new high-performance instances like M8a (general-purpose, up to 30% better performance than prior gen), C8a (compute-optimized), R8a (memory-optimized), and X8aedz (memory-intensive with up to 5GHz clocks and 3TiB memory).
~AWS often premieres AMD instances, positioning EPYC as a cost/performance leader frequently delivering 19-50% better price-performance than Intel equivalents.
~EPYC instances span general-purpose, compute-intensive, memory-heavy, and HPC workloads, with tools like AMD's Cloud Cost Advisor highlighting OPEX savings.
This CPU partnership provides AMD with deep integration into AWS's ecosystem, including optimized Nitro System offloading and broad availability across regions. It sets the stage for GPU expansion: AWS trusts AMD's supply chain, software maturity (ROCm), and value proposition.
5. The Path to Major MI450X Adoption: Diversification and TCO Imperative
A. AMD's Instinct MI450X (2026, CDNA 5 architecture) directly addresses:
~Specs Edge → Up to 432GB HBM4 per GPU (vs. Nvidia Rubin ~288GB), 19.6 TB/s bandwidth, targeting 40-50 PFLOPS in low-precision (FP4/FP8).
~Helios Rack → Double-wide ORW design (Meta-inspired OCP standard) packs 72 GPUs, delivering ~2.9 exaFLOPS FP4, 31TB aggregate HBM4, 1.4 PB/s bandwidth—50% more memory capacity/bandwidth than Nvidia's Rubin NVL144 racks.
~Open Scaling → Standards-based Ethernet (Ultra Ethernet Consortium) UALink for scale-up/out, enabling resilient, interoperable clusters vs. Nvidia's proprietary NVLink/InfiniBand.
B. MI450 Lowest TCO Case:
~Memory-Dominated Workloads → Modern AI (trillion-parameter models, long-context reasoning) is increasingly memory-bound. Helios's 50% memory advantage reduces data movement bottlenecks, boosting effective throughput and energy efficiency.
~Power/Cooling Efficiency → Liquid-cooled, dense design optimizes for MW-constrained data centers; Ethernet avoids proprietary lock-in premiums.
~Pricing Leverage → AMD's historical 30-50% cost advantage compare to $NVDA (MI300X vs. H100) likely persists; hyperscalers negotiate aggressively for volume.
~Inference Sweet Spot → MI450X excels in high-volume inference (AWS's bread-and-butter), where TCO matters most—potentially 20-40% lower than Rubin equivalents when factoring perf/$, power, and supply.
Early adopters validate this: Oracle committed to 50,000 MI450 GPUs in Helios racks and want to secure more(2026 ), OpenAI/Meta collaborated on design, HPE announced commercial Helios systems. Sources pointed to AWS GPU wins with AMD, aligning with diversification trends ( Microsoft/Meta heavy on AMD MI300X/325X/MI350X). 6GW orders from @OpenAI strenghtened this case.
Conclusion: Amazon undervaluation becomes even clearer when factoring in Amazon's accelerating adoption of @AMD technology; a strategic diversification play that will drive superior total cost of ownership (TCO), margin expansion, and sustained AWS growth. AWS has long been AMD's flagship partner on CPUs: since 2018, every generation of EPYC powers key EC2 instances. In 2025 alone, AWS launched multiple 5th-gen EPYC ("Turin") families—M8a general-purpose (up to 30% better performance), C8a compute-optimized, and X8aedz memory-optimized (highest 5GHz cloud frequency)—delivering 19-31% better price-performance and cementing EPYC's cost/performance edge.
This foundation positions AWS for explosive growth with AMD's upcoming Instinct MI450 series (2026 launch) and Helios rack-scale systems. Helios, built on open standards (Meta's ORW spec), packs up to 72-128 MI450 GPUs with massive advantages: up to 432GB HBM4 per GPU, 50% more aggregate memory capacity/bandwidth than Nvidia's Rubin equivalents, and open Ethernet/UALink scaling for resilient, interoperable clusters. Critically, Helios delivers the lowest TCO in next-gen AI infrastructure through superior memory-bound efficiency (vital for trillion-parameter models and long-context inference), lower power draw, aggressive pricing (AMD's historical 30-50% cost advantage), and avoidance of proprietary premiums.
Hyperscalers prioritize TCO for inference-heavy workloads (AWS's core strength). Early adopters like Oracle (50,000 MI450 GPUs in Helios racks starting 2026) and OpenAI validate this shift from Nvidia dependency. AWS, already supplementing Trainium/Inferentia with Nvidia, is logically next: faster MI450/Helios adoption will enable cost-optimized, diversified clusters blending in-house chips for efficiency, Nvidia for premium, and AMD for scale/margins. This accelerates AWS's 20-25% growth runway, boosts operating margins, and solidifies leadership as AI spend explodes.
With 15-20% EPS growth plausible, a re-rating to 45-50x forward earnings (reflecting AI infrastructure primacy) justifies $400-450 per share in 12-24 months or a $4 trillion market cap. Risks like competition or macro headwinds persist, but Q3 resilience and strategic moves (efficiency resets) mitigate them. Faster AMD adoption in EPYC today and MI450/Helios tomorrow isn't just incremental it's a margin-expanding catalyst propelling Amazon into AI's next phase.
If you like this kind of analysis, slap the like/repost and bookmark to please the X Algo.
If you want to support my work further, consider subscribe to see more in-dept analysis and other Sub-benefits.
Alright, that is it.
Not Financial Advice!
1
5
69
6,721

27 Nov 2025
How CryoSPARC Accelerates Drug Discovery by using AWS HPC ParallelCluster! #BigData #Analytics #DataScience #AI #MachineLearning #AWS #HPC #IoT #IIoT #PyTorch #Python #RStats #TensorFlow #ReactJS #GoLang #HealthTech #CloudComputing #Serverless #DataScientist #Linux #Programming #Coding #100DaysofCode
geni.us/CryoSparc
3
156

22 Nov 2025
$NVDA $AMZN $MSFT $GOOGL Below is a detailed analysis of the hyperscalers and neoclouds’ various levels of service offerings. You will see the heterogeneity of the service offerings, which tells a different story than the homogeneity of “GPU compute” that Wall Street and MSM promote.
————
• Traditional hyperscalers (Azure, AWS, Google Cloud, Oracle, IBM, Alibaba) span almost the entire hierarchy: from GPU‑backed SaaS copilots (L1) and model APIs (L2) down through managed training platforms (L3–L4), managed GPU clusters (L5), GPU VMs (L6) and, in some cases, bare‑metal GPU instances (L7). 
• Neocloud giants (CoreWeave, Lambda, Crusoe, Nebius) concentrate in the middle and lower layers: strong managed clusters and orchestration (L4–L5) and high‑quality VMs / bare metal (L6–L7), with a growing but more selective presence in training platforms and inference services (L2–L3). 
• Platform‑centric neoclouds (Together, RunPod, Verda/DataCrunch, Gcore, Hyperstack, Firmus, GMO GPU Cloud, TensorWave and a few others) extend the stack upward into managed training, inference, and lightweight MLOps (L2–L5) while still selling GPU VMs and clusters (L6–L7). 
• Infrastructure‑first neoclouds (Voltage Park, Cirrascale, Scaleway, Vultr, many Bronze‑tier clouds) are tightly focused on high‑performance clusters and bare metal (L5–L7), with minimal higher‑level platform features. 
• Marketplaces and brokers (Vast.ai, Prime Intellect, TensorDock within Voltage Park, etc.) operate as an overlay on the bottom of the stack, aggregating GPU VMs and bare‑metal servers from many providers rather than running their own full cloud. They sit between L6–L7 commercially but do not own much of the technical stack. 
To anchor terminology, the hierarchy is:
L1 – Fully managed AI applications (copilots, vertical SaaS).
L2 – Managed foundation models and inference APIs (model‑as‑a‑service).
L3 – Managed training / fine‑tuning platforms (“bring data, get a model”).
L4 – ML / MLOps platforms with integrated GPU orchestration (notebooks, pipelines, feature stores).
L5 – Managed GPU clusters (Kubernetes/Ray/Slurm as‑a‑service).
L6 – GPU‑accelerated VM instances.
L7 – Bare‑metal GPU‑as‑a‑service (dedicated servers).
Below L7 sit colocation and on‑premises deployments, which are important for end users but usually not branded as “GPU cloud providers.”
⸻
1.Traditional hyperscalers
⸻
SemiAnalysis’ ClusterMAX 2.0 classifies Microsoft Azure, Oracle, AWS and Google Cloud as “Traditional Hyperscalers,” distinct from neoclouds and marketplaces.  All four operate across essentially the full stack.
Microsoft Azure
• L1 – Fully managed AI apps: Microsoft 365 Copilot, GitHub Copilot and industry copilots are SaaS products that abstract GPUs entirely. 
• L2 – Model APIs: Azure OpenAI Service and Azure AI model catalog expose GPT‑class and other models via API with token‑based billing. 
• L3 – Training / fine‑tuning: Azure AI Studio and Azure Machine Learning offer managed training, fine‑tuning and evaluation workflows over GPUs and TPUs. 
• L4 – ML/MLOps PaaS: Azure ML provides experiment tracking, pipelines, registries, and deployment, tightly integrated with Azure Kubernetes Service. 
• L5 – Managed GPU clusters: AKS with GPU node pools and Azure’s HPC / AI offerings support large distributed training jobs on H100, H200, GB200 and GB300 clusters (for example, the GB300 NVL72 “supercomputer‑scale” deployment). 
• L6 – GPU VMs: NC/ND/NV series instances expose single‑ and multi‑GPU VMs based on Nvidia GPUs. 
• L7 – Bare metal: GPU bare metal is limited; Azure’s focus is on VM‑based HPC. Oracle positions itself as the only major cloud with fully exposed GPU bare metal, suggesting Azure’s GPU bare‑metal SKUs are niche or absent. 
Amazon Web Services
• L1 – AI applications: Amazon Q, CodeWhisperer, and other AI‑backed SaaS features embed GPUs but are sold as enterprise productivity tools. 
• L2 – Model APIs: Amazon Bedrock exposes FMs from Anthropic, Meta, Mistral, Cohere and others via one API. 
• L3 – Training / fine‑tuning: Bedrock model customization and Amazon SageMaker training flows provide managed training and fine‑tuning on GPUs including A100, H100 and H200. 
• L4 – ML/MLOps PaaS: SageMaker is a full ML platform (experiments, pipelines, feature stores, deployment) built over AWS GPU infrastructure. 
• L5 – Managed GPU clusters: EKS, AWS Batch, ParallelCluster and UltraClusters over P4/P5/P6 instances provide managed Slurm/Kubernetes environments for thousands of GPUs. 
• L6 – GPU VMs: EC2 P‑ and G‑series instances deliver virtualized GPU capacity. 
• L7 – Bare metal: Bare‑metal EC2 instance types (“.metal”) and Nitro‑based GPU instances provide near‑metal access for workloads needing direct hardware control. 
Google Cloud
• L1 – AI apps: Workspace AI features and Gemini‑powered assistants are AI SaaS offerings on top of TPUs/GPUs. 
• L2 – Model APIs: Vertex AI and Gemini APIs expose Google and partner models via managed endpoints. 
• L3 – Training / fine‑tuning: Vertex AI supports managed training/fine‑tuning on TPUs and GPUs with pre‑built pipelines. 
• L4 – ML/MLOps PaaS: Vertex AI is a unified platform with pipelines, registries, and MLOps features. 
• L5 – Managed GPU clusters: GKE with GPU node pools and “AI Hypercomputer” pods combine TPUs, GPUs, fast storage and advanced fabric; large training workloads run here. 
• L6 – GPU VMs: Compute Engine exposes A100, H100, H200, L4, T4 and others as attachable GPUs to VMs. 
• L7 – Bare metal: Google offers “Bare Metal Solution” for Oracle and some HPC workloads, but GPU bare metal is niche relative to VM‑based GPUs. The mainstream GPU product is at L6. 
Oracle Cloud Infrastructure (OCI)
• L1 – AI applications: Oracle has vertical SaaS applications, but most GPU‑relevant offerings start at L2.
• L2 – Model APIs: OCI Generative AI service exposes managed FMs via API. 
• L3 – Training / fine‑tuning: OCI Generative AI supports hosting and fine‑tuning models on “dedicated AI clusters.” 
• L4 – ML/MLOps PaaS: OCI AI services offer some PaaS‑like workflows, though less broad than SageMaker or Vertex. 
• L5 – Managed clusters: Dedicated AI clusters provide managed environments running on H100/H200/B200 fleets, integrated with OCI networking and storage. 
• L6 – GPU VMs: Standard OCI GPU VMs. 
• L7 – Bare metal: OCI explicitly markets bare‑metal GPU instances (H100/H200, MI300X etc.) as a differentiator versus other hyperscalers. 
IBM Cloud and other “second‑tier” hyperscalers
• IBM Cloud offers GPU‑equipped bare‑metal servers and GPU VMs, positioning primarily at L6–L7 with some PaaS around Watson and MLOps. 
• DigitalOcean, Vultr and similar providers sit mostly at L6 (GPU VMs) with little or no managed clusters or model APIs, though some offer simple PaaS integrations (e.g., DigitalOcean GPU Droplets integrated with its platform). 
In summary, hyperscalers extend from L1 down to at least L6 and, for OCI and parts of AWS, to L7. They internalize much of the stack, using GPU IaaS mainly as a cost base for higher‑margin L1–L4 services.
⸻
2.Neocloud giants (ClusterMAX “Neocloud Giants”)
⸻
ClusterMAX identifies four “Neocloud Giants”: CoreWeave, Lambda Labs, Crusoe and Nebius.  These firms are the closest neocloud analogues to hyperscalers, but most of their revenue and differentiation is concentrated in L4–L7.
CoreWeave (Platinum‑tier in ClusterMAX) 
• L4 – PaaS: CoreWeave Kubernetes Service is a managed K8s platform with Slurm‑on‑Kubernetes, observability, and AI‑optimized configuration (networking, storage, drivers).
• L5 – Managed GPU clusters: CKS clusters run on bare‑metal GPU nodes with NVLink and InfiniBand, oriented to training and inference.
• L6 – GPU VMs: CoreWeave exposes GPU‑accelerated VMs for various workloads.
• L7 – Bare metal: Purpose‑built bare‑metal infrastructure for inference and training underpins the platform.
• Limited L2–L3: CoreWeave focuses on infrastructure and orchestration rather than its own generic model APIs; higher‑level services are mostly partner‑led (e.g., Meta, OpenAI).
Lambda Labs (Neocloud giant, Silver medallion) 
• L3 – Training / fine‑tuning: Lambda Cloud is used explicitly for training and fine‑tuning; workspaces and templates push into L3 territory.
• L4 – PaaS: Jupyter‑style workspaces and preconfigured ML environments provide a thin ML platform.
• L5 – Managed clusters: Lambda supports multi‑GPU clusters and 1‑click clusters across B200/H100/A100/GH200.
• L6 – GPU VMs: Core on‑demand product is GPU VMs with Lambda Stack preinstalled.
• L7 – Bare metal: Historically offered bare‑metal DGX and HGX rentals; still present for some dedicated customers.
Crusoe 
• L4 – PaaS: Crusoe positions itself as an “AI platform,” with managed Kubernetes (Crusoe Managed Kubernetes) and orchestration (Run:ai integration) to simplify MLOps.
• L5 – Managed clusters: Crusoe AutoClusters automate Slurm/Kubernetes cluster creation over large GPU fleets.
• L6 – GPU VMs: Crusoe Cloud offers GPU VMs on Nvidia (A100, H100, H200) and increasingly AMD MI300X.
• L7 – Bare metal: Bare‑metal nodes in data centers near stranded energy sources and, more recently, experimental space‑based H100 deployments.
Nebius 
• L4 – PaaS: Nebius AI Cloud provides managed Kubernetes and support for AI frameworks and schedulers.
• L5 – Managed GPU clusters: Thousand‑GPU clusters on InfiniBand fabric with Slurm/Kubernetes orchestration.
• L6 – GPU VMs: Standard GPU virtual machines for smaller workloads.
• L7 – Bare metal: “Bare‑metal performance” HGX/GB systems on InfiniBand underlying the cloud.
• Early L3 activity: Nebius markets itself as a platform for building, tuning and running AI models, but does not heavily promote generic model APIs.
These giants are infrastructure‑heavy. Their primary differentiation is at L4–L5 (managed orchestration and training‑grade clusters) and L6–L7 (pricing, topology, availability). They have limited or no presence at L1 and only selective presence at L2–L3, usually via partner solutions.
⸻
3.Platform‑centric neoclouds (ClusterMAX Gold/Silver)
⸻
This group overlays higher‑level services (L2–L4) on top of infrastructure. ClusterMAX’s Gold and Silver tiers include Together, Voltage Park, Gcore, Firmus/SMC, TensorWave, GMO GPU Cloud, RunPod, Verda (DataCrunch), Scaleway, Cirrascale, Vultr and others. 
Together AI 
• L2 – Model APIs: Together Inference offers serverless inference for 200 open‑source models with pay‑per‑token pricing and “dedicated endpoints.”
• L3 – Training / fine‑tuning: Managed fine‑tuning and full training services on Together’s GPU clusters.
• L4 – PaaS: An integrated platform to train, fine‑tune, and deploy models; workflow orchestration is baked in.
• L5 – Managed clusters: Slurm and Kubernetes‑based GPU clusters for large‑scale training.
• L6–L7 – GPU infrastructure: Instant GPU clusters and reserved GB200/B200/H200/H100 clusters, effectively exposing bare‑metal performance with orchestration.
RunPod 
• L2 – Inference endpoints: Serverless GPU endpoints for generative AI models.
• L3 – Training support: Pods and templates for training/fine‑tuning with persistent storage.
• L4 – Lightweight PaaS: “End‑to‑end AI cloud” branding, with prebuilt runtimes and deployment automation.
• L5 – Managed clusters: Less emphasis on formal cluster services, but multi‑pod orchestrations can approximate L5.
• L6–L7 – GPU pods: Both community cloud (marketplace‑like) and secure cloud deliver GPU VMs and some dedicated nodes.
Verda (formerly DataCrunch) 
• L2 – Serverless inference: Autoscaling model hosting with per‑usage pricing.
• L3 – Training support: Guidance and tooling; not as deep as SageMaker but moving beyond pure IaaS.
• L4 – PaaS: Model hosting, monitoring and autoscaling containers reflect PaaS characteristics.
• L5 – GPU clusters: Custom clusters with Verda‑managed software stacks.
• L6–L7 – GPU instances: On‑demand and long‑term GPU instances up to 8× B200 HGX.
Gcore 
• L3–L4: Preconfigured environments and containerized workloads with Docker/Kubernetes for AI and ML.
• L5: Cluster‑level infrastructure for AI training, built on combinations of bare metal and VMs.
• L6–L7: GPU VMs and bare‑metal servers interconnected via fast networks.
Hyperstack 
• L2–L3: “Hyperstack AI Studio” markets an end‑to‑end environment to build, deploy and monitor AI, implying training and inference PaaS.
• L4: No‑infra‑needed positioning indicates significant platform services.
• L5–L7: Underlying GPU cloud with on‑demand GPUs.
Firmus / Sustainable Metal Cloud (SMC) 
• L4–L5: Firmus AI Cloud emphasizes hybrid/multi‑cloud automation, observability and encrypted InfiniBand networking.
• L6–L7: SMC is primarily a bare‑metal GPU cloud (H100, A100, L40S) with large, energy‑efficient clusters.
• Some L3 elements: Marketing references “AI Cloud Apps,” indicating some platform‑level services on top of clusters.
GMO GPU Cloud 
• L4–L5: Uses DDN storage and NVIDIA AI Enterprise to provide an “all‑in‑one AI development platform” on top of H200 and other GPUs.
• L6–L7: High‑performance multi‑node clusters that also appear in TOP500 rankings.
TensorWave 
• L3–L4: Offers managed inference and PaaS features on top of AMD Instinct MI300X/MI325X clusters.
• L5–L7: Focuses on high‑performance bare‑metal AMD clusters for training, with large MI325X installations.
These providers occupy L2–L7 in varying depth. Their differentiation versus hyperscalers is price, topology (e.g., large, tightly‑coupled H100/B200 or MI300X clusters), and agility; versus infrastructure‑first neoclouds, their differentiation is upward integration into inference and training platforms.
⸻
4.Infrastructure‑first neoclouds
⸻
This group is defined by strong hardware and topology and relatively thin higher‑level services.
Voltage Park 
• L5 – Managed clusters: Dedicated HGX H100 clusters (64–4,064 GPUs) with 3.2 Tbps InfiniBand are configured for large training jobs.
• L6–L7 – Bare metal and VMs: On‑demand access with simple provisioning, little platform abstraction beyond cluster orchestration.
• Limited L2–L4: Historically hardware‑centric, with some movement toward “AI factory” software but far from full ML PaaS. The acquisition of TensorDock adds a marketplace component without significantly lifting the stack.
Cirrascale 
• L5–L7: Bare‑metal, dedicated multi‑GPU compute servers with options for fully managed clusters; focus is on physical servers and HPC‑style inference/training.
• Some L3–L4 elements: Managed inference offerings exist but are not as integrated as hyperscaler MLOps platforms.
Scaleway 
• L6 – GPU instances: VM‑based GPU instances (H100, L40S, L4, GH200, P100) for training and rendering.
• L5: “Supercomputer” configurations suggest some cluster‑level services, but the primary product is IaaS.
• Minimal L2–L4: Some integrations, but no full managed model APIs or training platforms at hyperscaler depth.
Vultr 
• L6 – GPU VMs: Cloud GPU instances with Nvidia and AMD GPUs for AI/ML and graphics workloads.
• Limited L4: Preconfigured images and integrations, but not a complete ML platform.
• No material L2–L3 at present.
Many Bronze‑tier providers in ClusterMAX (e.g., STN, GMI Cloud, Hot Aisle, Atlas Cloud, Buzz HPC, Qubrid) fit this archetype: they offer GPU instances and sometimes basic managed clusters, but limited higher‑layer software. 
These firms compete primarily on $/GPU‑hour, availability and topology, and are highly exposed to Nvidia pricing and utilization risk.
⸻
5.Marketplaces, brokers, and “Craigslist for GPUs”
⸻
ClusterMAX separates marketplaces and brokers into their own column (Vast.ai, Prime Intellect, Shadeform, Mithril, etc.), and further identifies “Craigslist for GPUs” (gpulist.ai, gpucompare.com). 
Vast.ai and similar platforms:
• Commercially operate at L6–L7, aggregating GPU VMs and bare‑metal servers from hosts and data centers.
• Provide a control plane, pricing/auction logic and some templates, but little in the way of true ML PaaS or model APIs.
• Function more as a meta‑layer over infrastructure‑first neoclouds and independent hosts than as full clouds.
Voltage Park’s TensorDock acquisition is an example of convergence between a neocloud and a marketplace; the marketplace piece still sits at the bottom of the stack, while Voltage Park’s own clusters remain L5–L7. 
⸻
6.Mapping back to the hierarchy and investment relevance
⸻
Several structural points emerge once providers are mapped to the hierarchy.
First, hyperscalers are vertically integrated across almost all layers (L1–L6, sometimes L7). AI SaaS and model APIs (L1–L2) are the primary value capture points, with GPU infrastructure treated as a cost base. Their differentiation is in proprietary models, data, and platform coverage; GPU pricing is a tactical lever. This supports margin resilience even as they cut GPU‑hour prices to compete with neoclouds.
Second, neocloud giants and leading platform‑centric neoclouds cluster in L3–L7, with their brand and differentiation anchored in L4–L5 (orchestration quality, training cluster performance) and L6–L7 (pricing, topology). They are closest to the “training factory” narrative. Their exposure to Nvidia product cadence, interconnect costs and data‑center power economics is high; their ability to move up into L2–L3 (model APIs, managed training products) is central to achieving software‑like margins rather than commodity infrastructure returns.
Third, infrastructure‑first neoclouds and marketplaces are concentrated at L5–L7 with thin software layers. Their economics depend almost entirely on maintaining a spread between GPU‑hour revenue and hardware plus power costs, at high utilization. As ClusterMAX and other research show, this segment is already experiencing strong price competition and tightening returns. 
Fourth, the taxonomy highlights how Nvidia’s and AMD’s product cycles propagate through the ecosystem. New architectures (H200, B200/GB200, MI325X/MI350X) are surfaced first at infrastructure layers (L6–L7) by hyperscalers and neoclouds, then pulled up into managed clusters (L5) and training platforms (L3–L4), and only later appear indirectly in SaaS and APIs (L1–L2). Providers concentrated at the bottom of the stack bear the full brunt of depreciation and price erosion between generations; those at the top abstract this away behind price per token or per seat.
Finally, mapping providers to this hierarchy allows clearer differentiation within neoclouds. CoreWeave, Nebius, Crusoe, Lambda and Together operate much closer to hyperscaler‑like PaaS and cluster services than many emerging neoclouds, while Bronze‑tier and marketplace providers are essentially commodity GPU wholesalers. The former group can plausibly build durable franchises if they secure long‑term offtake agreements and continue moving up the stack; the latter are structurally exposed to consolidation and margin compression as GPU markets normalize.
Understanding which layers each provider actually occupies, as opposed to what is claimed in marketing, is therefore critical to assessing durability of economics, the degree of competitive insulation from hyperscalers, and the sensitivity of each business to Nvidia’s pricing and product roadmap.
22 Nov 2025

$NVDA Understanding the hierarchy of GPU service offerings is critical because profit pools, competitive dynamics, and risk profiles differ sharply at each layer of the stack. At the top, fully managed AI applications and model APIs capture value through software, data, and distribution, with GPUs as a largely invisible input. Margins are high, pricing power is strongest, and sensitivity to raw GPU-hour pricing is indirect. At the bottom, bare-metal GPU services, GPU-accelerated VMs, and colocation sit closest to Nvidia hardware economics. These businesses are capital intensive, highly exposed to GPU ASPs and utilization, and face intense price competition as more capacity comes online.
A clear taxonomy makes it possible to map each company’s true position in this stack, separate narrative from reality, and identify where economic rents are likely to accrue.
•Fully managed AI applications (SaaS) that hide GPUs entirely
•Managed foundation models and inference APIs (model-as-a-service)
•Managed training / fine-tuning platforms (“train a model, no infra”)
•Full ML / MLOps platforms with integrated GPU orchestration (PaaS)
•Managed GPU clusters (Kubernetes/Ray/Slurm as-a-service)
•GPU-accelerated VM instances (IaaS VMs with attached GPUs)
•Bare-metal GPU-as-a-service (dedicated GPU servers delivered via API)
•GPU colocation / hosted racks (customer-owned GPUs in provider facilities)
•On-premise self-managed GPU infrastructure (customer buys and runs everything)
The hierarchy above is ordered from the most abstracted, feature-rich, and “application-level” offerings at the top toward the most primitive, infrastructure-level offerings at the bottom. As one moves down the list, the provider delivers fewer higher-level services and the customer assumes more responsibility for software, orchestration, and operations. The underlying GPU product (H100, H200, B200, etc.) can appear at multiple layers; what changes is how much of the stack the provider bundles.
1.Fully managed AI applications (SaaS) that hide GPUs entirely
This category includes end-user products that embed GPUs but present themselves as business applications: copilots inside productivity suites, AI assistants in CRM, code copilots, AI search, AI-native office suites, and vertical AI tools (design, drug discovery, industrial simulation) that expose a pure SaaS interface. The customer never sees GPUs, instances, or clusters; pricing is per seat, per document, per project, or per usage metric (tokens, queries, tasks) but packaged as an application.
From a GPU standpoint, this layer is the furthest from the hardware. Providers hedge GPU capacity commitments against user growth, drive utilization via multi-tenancy, and optimize model architectures and inference stacks internally. Economically, this tier carries the highest margins and the greatest pricing power, since value is anchored in business outcomes rather than compute units. For infrastructure investors, GPU pricing enters only indirectly, through its effect on gross margin and the provider’s ability to subsidize AI features to drive user growth.
2.Managed foundation models and inference APIs (model-as-a-service)
The next layer is model APIs that expose generic or specialized models via HTTP or gRPC endpoints: text LLMs, vision models, multi-modal, embedding APIs, and sometimes domain-specific models. Customers pay per token, per 1k images, or per unit of model usage. The provider manages model hosting, scaling, versioning, A/B testing, safety, and often some monitoring and logging.
At this tier, GPUs are abstracted into a “token” or “inference” unit. Providers still actively manage GPU fleets, but customers think in terms of model latency, throughput, and cost per token. GPU choice (H100 vs L40S vs B200) is a provider decision, often invisible or only exposed as coarse tiers (standard vs “turbo” / “premium”). Economics are more sensitive to GPU pricing than at the SaaS layer but still benefit from aggregation: high utilization, batching, and kernel-level optimization can produce meaningful arbitrage between GPU-hour input costs and token-level output pricing. Competitive pressure in inference APIs is compressing margins, but differentiated models and ecosystem lock-in still offer room for attractive returns.
3.Managed training / fine-tuning platforms (“train a model, no infra”)
This layer offers “bring your data, get a model” services. Customers upload datasets and configuration; the platform orchestrates the entire training pipeline: data preprocessing, sharding, distributed training, checkpointing, evaluation, and sometimes deployment. Examples include managed fine-tuning products, AutoML services, and dedicated training PaaS that hide cluster-level complexity.
Conceptually, this tier is training-as-a-service (TaaS). The platform decides which GPU type, cluster size, parallelism strategy, and fabric to use, possibly across multiple cloud providers. Customers pay per training job, per GPU-hour with automated scaling, or per project. The provider must understand Nvidia’s product roadmaps (A100 vs H100 vs H200 vs B200), topology (SXM vs PCIe, NVLink vs Ethernet/InfiniBand), and optimizer/parallelism choices to minimize training cost while meeting SLAs.
This tier is operationally complex and capital intensive because it must handle long-duration jobs, complex failure modes, and heavy state (checkpoints). It sits closer to raw GPU economics than inference APIs because training jobs often fully occupy clusters for days or weeks. The ability to arbitrage between cloud GPU pricing options, exploit spot capacity, and route workloads to neoclouds or hyperscalers efficiently is a key differentiator. Providers at this tier effectively “compile” customer workloads to underlying GPU markets.
4.Full ML / MLOps platforms with integrated GPU orchestration (PaaS)
These are general-purpose ML platforms (e.g., managed notebooks, pipelines, experiment tracking, feature stores) that tightly integrate GPU scheduling and orchestration. The core product is not “API access to a model” but a managed development and deployment environment. GPUs are a resource managed by the platform’s scheduler, exposed via abstractions such as “GPU pool,” “compute profile,” or “accelerator type.”
Customers typically pay for a mix of platform fees and underlying compute/storage usage. The platform may support multiple workloads: data preprocessing, training, hyperparameter tuning, batch inference, and interactive experimentation. The provider’s responsibilities include user management, security, observability, and lifecycle management, in addition to GPU provisioning. This tier straddles PaaS and IaaS; it commonly runs on top of hyperscaler GPU instances, neocloud GPU clusters, or a hybrid of both.
From a GPU-market standpoint, this layer is where many enterprises “terminate” their abstraction. They want to select GPU families and sizes, but not manage Kubernetes, Slurm, or NCCL tuning. The platform provider’s value comes from masking heterogeneity in GPU hardware and pricing across clouds and exposing a stable developer experience. Economically, margins depend on the degree of lock-in and differentiated workflow tools. GPU cost is a major line item but often passed through with markup.
5.Managed GPU clusters (Kubernetes/Ray/Slurm as-a-service)
This layer exposes GPU clusters more directly but with managed control planes and orchestration frameworks: managed Kubernetes with GPU node pools, managed Ray clusters, Slurm-as-a-service, or specialized orchestration for distributed training. Customers see nodes, pods, and jobs, and they deploy their own containers or training code. The provider operates the cluster, control plane, autoscaling, and sometimes the storage and network fabric.
At this tier, customers are responsible for their own software stack (frameworks, libraries, distributed training logic) and performance tuning but can offload cluster provisioning, lifecycle management, upgrades, and failure handling. GPU choice, topology, and interconnect details may be selectable (e.g., “H100 NVLink InfiniBand cluster”), but the platform still abstracts away low-level host management.
Economically, this layer tends to be lower-margin than model APIs or training PaaS because it is closer to raw infrastructure. Differentiation comes from quality of implementation (latency, NCCL efficiency, topology guarantees), reliability, and ease of integration with customer CI/CD. From a pricing perspective, this is usually billed per GPU-hour plus possible control-plane or support fees, with customers closer to seeing the “true” price of H100/H200/B200.
6.GPU-accelerated VM instances (IaaS VMs with attached GPUs)
Here, the main product is virtual machines with attached GPUs. The provider offers SKUs like “8× H100 80 GB” or “1× L4,” with documented vCPU, memory, and network bandwidth. Customers manage the OS, drivers, frameworks, and application stack. This is the classic hyperscaler model (EC2, Compute Engine, Azure VMs) and is also exposed by many neoclouds.
The abstraction is relatively thin: the provider virtualizes hardware and networking, offers images and basic monitoring, and enforces quotas and security isolation. Customers choose GPU type, count, and region; they manage scaling via autoscaling groups, scripts, or external orchestrators. Pricing is nearly directly indexed to GPU-hour cost, plus a premium for VM overhead and network/storage. This tier is the baseline reference for H100/H200/B200/A100 pricing comparisons and is where price competition is most visible.
From a responsibility perspective, customers are responsible for cluster-wide concerns: placement, data locality, job scheduling, checkpointing, and resilience. The provider’s main levers are price, availability, and performance guarantees. Margins depend heavily on utilization and on the provider’s ability to secure favorable GPU procurement terms.
7.Bare-metal GPU-as-a-service (dedicated GPU servers via API)
Bare-metal GPU-as-a-service offers physical servers with GPUs and no virtualization. Customers receive full control over the node (BIOS-level in some cases), installing their own OS or bringing custom images. Some providers add an API layer for provisioning and basic lifecycle actions (power on/off, PXE boot, image deploy), but there is no hypervisor.
Bare metal is attractive for high-performance workloads, customers wanting custom kernels, or those needing very predictable latency and performance. It also allows providers to avoid hypervisor overhead and simplify some aspects of capacity management. However, customers must handle everything above the bare hardware: OS hardening, clustering, storage, networking topology awareness, and distributed job management. Interconnect (NVLink, InfiniBand vs Ethernet) and node configuration (HGX vs PCIe) are often key differentiators.
Pricing is typically per GPU-hour or per-node-hour and often lower than equivalent VM offerings per unit of GPU, because less virtualization overhead is present and the service is more commoditized. For neoclouds, this tier is capital intensive and exposes them most directly to Nvidia GPU ASPs and utilization risk. Unit economics are sensitive to GPU generation pricing, system capex, and rack-level power and cooling costs.
8.GPU colocation / hosted racks (customer-owned GPUs in provider facilities)
At this level, the customer owns the GPU servers and the provider supplies data-center services: power, cooling, physical security, network cross-connects, and sometimes remote-hands operations. The provider may offer cage space, managed PDUs, and optional services like monitoring and hardware replacement, but the hardware capex and much of the operational burden reside with the customer.
This model is analogous to traditional colocation but focused on GPU-dense racks. It is attractive for entities with large, stable workloads and access to capital, who wish to avoid cloud markups and retain full control over hardware, while leveraging provider expertise in power and cooling. Sovereign deployments and AI majors increasingly use such models for part of their fleet, sometimes operated by colocation specialists or repurposed HPC data centers.
In this arrangement, Nvidia and the hardware OEMs capture most of the hardware margin; the colocation provider earns relatively stable, utility-like returns on space and power. The “service” layer around GPUs is minimal. The economics hinge on long-term contracts and high rack occupancy, not on per-GPU-hour arbitrage.
9.On-premise self-managed GPU infrastructure (customer buys and runs everything)
At the bottom of the hierarchy is fully self-managed infrastructure. The customer purchases GPUs and servers, builds or repurposes facilities, manages power and cooling, implements networking and storage, and runs their own orchestration stacks (Kubernetes, Slurm, Ray, proprietary frameworks). This includes both traditional on-premise data centers and private cloud environments.
Here, GPUs are pure capital assets on the customer balance sheet. There is no external “GPU service provider” per se; the customer is both owner and operator. The upside is maximal control over performance, security, and long-term cost of compute, particularly for predictable, high-volume workloads. The downside is high upfront capex, operational complexity, and exposure to technology obsolescence (e.g., transitions from A100 to H100 to B200 and beyond).
From a market-structure perspective, this tier competes with all higher layers on a lifecycle TCO basis. For large, steady workloads, internal GPU fleets can be cost-advantaged over public cloud or neocloud offerings at current GPU-hour pricing, but they lack elasticity and require strong internal capabilities. For small or spiky workloads, higher-level services are generally more economical.
Taken together, this hierarchy illustrates how the same Nvidia GPU products underpin multiple economic layers. At the top of the stack, GPUs are an invisible input into SaaS and model APIs, where value is captured through application outcomes and proprietary models. In the middle, GPUs are mediated by platforms and managed clusters, where provider differentiation relies on orchestration, tooling, and integration. At the bottom, GPUs are exposed directly via VMs, bare metal, or colocation, where competition tends toward price-per-GPU-hour and utilization management. Investment analysis of any player in this ecosystem requires identifying where in this hierarchy it operates, how much of the stack it controls, and how exposed it is to shifts in GPU pricing, utilization, and Nvidia’s product cadence.

2
23
5,939

22 Oct 2025
Briefly stated, (a term you'll often find stated before the least brief diatribe you've ever encountered)
1. There are entire fields of human inquiry and knowledge that exist almost entirely distributed across a network of dusty university library shelves. At any given time, you can pick a contiguous series of 25 books in that esoteric niche, and find that not only is not a single one checked out, but perhaps none of them have been checked out by a single patron in years.
2. University capital expenditures into infrastructure, at least for research, is viewed in terms of breakeven and total cost of ownership, rather than utilization percentages. I've sat in multiple meetings where a discussion about how to "get more out of" a piece of lab equipment, or a compute cluster, and the idea of minimizing dead-time is hardly mentioned. There is plenty of talk about how to make it available for rent by outside entities to help "pay for it", rather than maximizing its capabilities. An example of this is a university HPC that I used to manage; at its peak, we would hit about 30% utilization with a running average closer to 15-20%.
Obviously you're never going to get 100% utilization in a research setting, but there were millions of dollars of GPU mostly sitting idle for months in between frenetic bursts of activity. We even had conversations about moving our highest end users to AWS parallelcluster so they could get more capacity during their bursty episodes, rather than coach them on ways they could more thoughtfully use the hardware they already owned.
3. Instrumentation in academia is often treated as a delicate toy rather than a workhorse. It's good to have unscheduled windows where researchers can learn and become comfortable... but it's often too excessive.
In an ideal case, you would have students and faculty "fighting for their turn" to have the instrument all to themselves for a week or so when they become available. Instead, you have a lot of people doing defensive booking, where you will just schedule time on the system in anticipation of having something to measure, and it just sits idle and unavailable for anyone in the hopes that you will eventually swing by and use it for a small portion of the scheduled time. Obviously some experiments are time sensitive, and this makes sense, but there's a lot of this being done out of convenience and just internal politics.
My advisor would tell me stories about how he spent his 20's in the basement until 4am on saturdays because he knew that was when he would get the longest uncontested windows to collect his data. These days, he just books the entire facility for two weeks at a time for himself and his students to ensure they can walk up and collect whenever they feel like it.
4
102

30 Sep 2025
AWS ParallelCluster 3.14 には、P6e-GB200 と P6-B200 のインスタンスタイプが追加されました。
AWS パラレルクラスター 3.14 が一般公開されました。このリリースには、P6e-GB200 と P6-B200 のインスタンスタイプ、最適なインスタンス配置のための優先順位付けされた割り当て戦略、Amazon Linux 2023 の NICE DCV サポートが含まれています。このリリースに含まれるその他の機能には、インスタンスのシステムログ内のインスタンスコンソールでのシェフ/クライアントログの可視性のサポートや、カーネル 6.12 を搭載した Amazon Linux 2023 などがあります。パラレルクラスタで P6e-GB200 インスタンスを使い始めるには、『パラレルクラスタユーザーガイド-AWS ParallelCluster での Amazon EC2 P6e-GB200 ウルトラサーバーの使用』のチュートリアルに従ってください。リリースの詳細については、AWS ParallelCluster 3.14.0 リリースノートを参照してください。ParallelCluster は、研究開発のお客様とその IT 管理者が AWS でハイパフォーマンスコンピューティング (HPC) クラスターを運用できるようにする、完全にサポートされ、メンテナンスされているオープンソースのクラスター管理ツールです。ParallelCluster は、AWS 上で科学や工学のワークロードを大規模に実行できる、柔軟にスケーリングできる HPC クラスターにクラウドリソースを自動的かつ安全にプロビジョニングするように設計されています。ParallelCluster は、ここに記載されている AWS リージョンでは追加料金なしで利用できます。お支払いいただくのは、アプリケーションの実行に必要な AWS リソースの分のみです。AWS で HPC クラスターを起動する方法の詳細については、ParallelCluster ユーザーガイドをご覧ください。パラレルクラスターの使用を開始するには、パラレルクラスター UI と CLI のインストール手順を参照してください。
aws.amazon.com/about-aws/wha…
2
712

28 Aug 2025
$IonQ: Leading the Quantum Leap in Drug Discovery
(Highly recommended for those interested in understanding IonQ's healthcare initiatives).
In the groundbreaking paper titled “Algorithmic Advances Towards a Realizable Quantum Lattice Boltzmann Method” (initially published on April 15, 2025 but shared today by @IonQ_Inc ), the authors Apurva Tiwari, Jason Iaconis (@jasoniaconis), Jezer Jojo, Sayonee Ray (@muniasr), Martin Roetteler (@MartinQuantum), Chris Hill, and Jay Pathak (—contributing from Ansys and IonQ—present a transformative quantum algorithm for simulating diffusion-based dynamics on real hardware which will have a significant impact on IonQ's ability to lead the market in quantum-based healthcare.
The paper delivers a suite of advances, including MPS state loading, LCU-based collision and streaming operators, observable-based readout, and error mitigation techniques, culminating in a first-of-its-kind hardware realization of the Quantum Lattice Boltzmann Method (QLBM) on IonQ’s Forte system. These advances bring quantum computing into tangible relevance for life sciences, particularly because diffusion, transport, and reaction processes are central to biology and pharmacology. IonQ’s execution of this method propels it beyond theoretical promise toward practical applications in drug discovery and biomedical modeling. Again, we see that @NiccoloDeMasi is a few steps ahead as he masterfully builds IonQ in the global quantum leader (separate note: today's announcement of new Board of Director members Jim Frankola and Bill Teuber are significant additions and underscore in their own way DD about the company's roadmap).
Over the past few weeks I have previously mentioned that a detailed medical delivery report on how IonQ's transformative platforms, if executed, can and will change the medical delivery landscape. This paper along with other research publications and IP was used in part during the model building process. We're still a few weeks away from publishing these results because we want to make sure we got it right, but so far the results are eye-opening.
As the paper indicates, the work advances the QLBM pipeline using Matrix Product State (MPS) state preparation for smooth distributions with reduced circuit depth. It introduces Linear Combination of Unitaries (LCU)–based collision routines and one-hot encoded streaming to minimize gate complexity. Measurements focus on key observables such as mean, variance, and covariance rather than relying on full tomography, which greatly reduces overhead. Most importantly, the team implemented robust error mitigation, including flag qubits and noise modeling, that maintained over 90 percent fidelity on actual hardware when compared to classical benchmarks. By enabling multi-timestep simulation with constant success probability, even in complex three-dimensional, non-uniform flow scenarios, this implementation demonstrates that quantum hardware can handle practical PDE-based models that mirror biological transport phenomena.
IonQ’s use of QLBM on its own Forte hardware validates that its systems can already tackle practical PDE-based models relevant to biology. With the Tempo and AQ-264 systems on the horizon, the combination of more qubits, lower error rates, and algorithmic efficiency positions IonQ as a partner for pharma and biotech companies looking to run diffusion and transport simulations at unprecedented scales, integrate quantum-accelerated models into AI drug discovery pipelines, and move beyond classical bottlenecks in protein binding, toxicology screening, and drug delivery modeling. This is a turning point: IonQ is not just talking about theoretical healthcare applications, it is demonstrating them live on hardware today.
IonQ has complemented this scientific momentum with tangible demonstrations of drug discovery acceleration. In collaboration with AstraZeneca, AWS, and NVIDIA, the company deployed a hybrid workflow to simulate the Suzuki–Miyaura reaction, a key synthetic process in pharmaceutical chemistry. By integrating the Forte trapped-ion processor with CUDA-Q and AWS ParallelCluster, the workflow achieved a twenty-fold speedup, compressing months of computation into days without sacrificing accuracy. This result shows that IonQ’s approach is both scalable and commercially relevant. It provides drug researchers with accelerated modeling capacity today, well before fully fault-tolerant quantum computers arrive. The partnership also validates IonQ’s ecosystem integration, ensuring its systems align seamlessly with the cloud and AI infrastructure used in pharmaceutical research.
IonQ’s ambition does not stop at today’s capabilities. The company’s planned $1.1 billion acquisition of Oxford Ionics significantly bolsters its roadmap toward scalable, fault-tolerant hardware, with a target of two million physical qubits and 80,000 logical qubits by 2030. Such a milestone would make IonQ uniquely suited to support the most complex simulations in pharmacology and personalized medicine. Importantly, this acquisition is expected to close before the September 12, 2025 Analyst Day in New York City, with the most likely closing date being September 8, 2025. Embedding this milestone into the Analyst Day narrative will allow IonQ to showcase the combined roadmap and reinforce its leadership to analysts, investors, and healthcare partners alike. @OxfordIonics represents more than a hardware enhancement; it is a strategic foothold in the UK quantum ecosystem, aligning with national security, biotech, and trans-Atlantic healthcare innovation while ensuring lower error rates, stronger scaling, and global positioning for IonQ.
Taken together, IonQ’s algorithmic breakthroughs, real-world demonstrations, and strategic acquisitions highlight why it is uniquely positioned as a trusted partner for pharma and biotech companies. The company is delivering workflows that compress months of simulations into days while generalizing its methods to drug diffusion, protein folding, and pharmacokinetics. It has shown that robust error mitigation can align quantum results with classical benchmarks, ensuring the reliability and accuracy required in biomedical research. IonQ has also proven its systems to be plug-and-play with AWS, NVIDIA, and other industry-standard infrastructures, offering pharma researchers the ability to fold quantum computing directly into existing AI-driven pipelines. At the same time, the clear hardware roadmap through Tempo, AQ-264, and Oxford Ionics integration demonstrates that the near future will bring larger qubit counts, lower error rates, and exponentially greater modeling capabilities. With strategic reach spanning both the U.S. and European markets, IonQ is more than a hardware company; it is a healthcare innovation partner with a global vision.
From the landmark QLBM demonstration published on April 15, 2025 by Tiwari, Iaconis, Jojo, Ray, Roetteler, Hill, and Pathak, to accelerated drug-reaction simulations with AstraZeneca, and a billion-dollar acquisition in motion, IonQ is charting a clear path toward quantum-accelerated drug discovery at scale. OnQ’s use of QLBM on its own Forte hardware validates that its systems can already tackle practical PDE-based models relevant to biology. With the Tempo and AQ-264 systems on the horizon, the combination of more qubits, lower error rates, and algorithmic efficiency positions IonQ as a partner for pharma and biotech companies looking to run diffusion and transport simulations at unprecedented scales, integrate quantum-accelerated models into AI drug discovery pipelines, and move beyond classical bottlenecks in protein binding, toxicology screening, and drug delivery modeling. With the Oxford Ionics deal expected to close before the September Analyst Day, IonQ will be in a prime position to demonstrate its leadership to the healthcare and investment communities alike. For pharma and biotech companies facing the bottlenecks of classical computation, IonQ offers not just a solution, but a partner in shaping the future of medicine.
Last note: congratulations to the entire IonQ team of researchers who worked on this paper. Good luck in New Mexico this coming week: hopefully a few of you will have an opportunity to go hot air ballooning!

IonQ is presenting four peer-reviewed papers and participating in 12 technical sessions at IEEE Quantum Week next week. Our research spans topics like energy optimization, linear algebra acceleration, fluid dynamics, and quantum LLM fine-tuning. Learn more: ionq.com/news/ionq-highlight…
3
6
47
3,521


19 Jun 2025
$IONQ IonQ’s claim of a “20x speedup” in computational chemistry is misleading when examined closely, as their own data reveals that the quantum portion provides no advantage over classical computing. The company explicitly acknowledges that “GPU acceleration” and their “innovative post-processing algorithm is the main driver of the speedup” rather than quantum processing. The quantum component only contributed a “9x” acceleration in quantum execution time , while the bulk of their performance gains came from classical optimizations running on modern hardware.
The comparison itself is fundamentally flawed because IonQ is not comparing quantum against classical approaches on equal footing. Instead, they benchmark their new hybrid system using “NVIDIA GPUs (H200s via P5en instances on AWS ParallelCluster)” against a “previous CPU-only implementation” . This is essentially comparing a state-of-the-art GPU-accelerated classical system against an older CPU-only baseline - not a fair quantum versus classical comparison. They acknowledge that “the existing algorithm is unable to work with molecules as large as the ones we used in this study,” making direct comparison impossible .
The architecture reveals where the real performance gains originate. IonQ’s workflow combines “quantum and classical computing at scale” with “AI model and cloud high-performance computing (HPC)” , creating a complex hybrid system. The company achieved “orders-of-magnitude time reduction compared to what the state-of-the-art algorithm would have taken” primarily through classical GPU acceleration, not quantum computation. The 20x speedup reflects advances in classical computing infrastructure and software optimization rather than any inherent quantum advantage.
In essence, IonQ’s demonstration shows that modern GPUs and optimized algorithms can dramatically accelerate computational chemistry workloads - something the classical computing community has known for years. The quantum portion, when isolated from these classical improvements, fails to demonstrate superiority over well-implemented classical approaches. The company’s own acknowledgment that classical post-processing drove most performance gains undermines their implicit claim of quantum advantage in computational chemistry.
2
6
768

9 Jun 2025
The hybrid quantum-classical workflow – orchestrated via CUDA-Q on Amazon Braket, accelerated with NVIDIA H200 GPUs through AWS ParallelCluster – delivered more than a 20x speedup in time-to-solution compared to prior benchmarks. This advancement highlights the scalability of IonQ’s quantum systems and their practical potential in pharmaceutical R&D.
“Bringing together state-of-the-art quantum and GPU computing in hybrid workflows is the path to realizing quantum’s potential,” said Tim Costa, Senior Director of Quantum and CUDA-X at NVIDIA. “This work represents a meaningful step towards applying quantum accelerated supercomputing to important use cases.”
IonQ, @awscloud, @AstraZeneca, & @nvidia collaborated to develop and demonstrate a hybrid quantum-classical workflow with 20x faster chemistry simulations—a breakthrough for drug discovery. Results will be showcased at #ISC2025 in Hamburg this week. ionq.com/news/ionq-speeds-qu…
5
31
2,701

$IONQ BREAKING:
$IONQ “announced results of a collaborative research program between $IONQ, AstraZeneca, Amazon Web Services (AWS), and NVIDIA to develop and demonstrate a quantum-accelerated computational chemistry workflow which has the potential to power world-changing innovation in healthcare, life sciences, chemistry, and more.
The $IONQ-designed workflow provides an end-to-end example of a hybrid quantum-classical workflow that helps provide solutions to complex pharmaceutical development challenges, and has the potential to improve speed and efficiency within the drug development process. Developing new drugs can take ten or more years and cost billions of dollars, so advancements that streamline early-stage research and reduce computational bottlenecks can unlock significant strategic and commercial value.
This demonstration focused on a critical step in a Suzuki-Miyaura reaction – a class of chemical transformations used for the synthesis of small molecule drugs. By integrating $IONQ ’s Forte quantum processing unit (QPU) with the NVIDIA CUDA-Q platform through Amazon Braket and AWS ParallelCluster services, the team achieved more than 20 times improvement in end-to-end time-to-solution compared to previous implementations. The technique maintained accuracy while reducing the overall expected runtime from months to days.
‘This demonstration with AstraZeneca represents a meaningful step toward practical quantum computing applications in chemistry and materials science and showcases how $IONQ ’s enterprise-grade quantum computers are uniquely suited to meet the challenge,’ said Niccolo de Masi, CEO of $IONQ. ‘The ability to model catalytic reactions with speed and accuracy isn’t just a scientific achievement, it’s a preview of how hybrid computing with quantum acceleration will provide revolutionary capabilities to the industry.’”
The results of the collaboration will be showcased at the ISC High Performance conference on June 10-13, 2025 in Hamburg, Germany.
IonQ, @awscloud, @AstraZeneca, & @nvidia collaborated to develop and demonstrate a hybrid quantum-classical workflow with 20x faster chemistry simulations—a breakthrough for drug discovery. Results will be showcased at #ISC2025 in Hamburg this week. ionq.com/news/ionq-speeds-qu…
3
10
64
2,846

9 Jun 2025
Quantum isn't theory. It's throughput.
IonQ just delivered the largest quantum-accelerated drug simulation to date, alongside AstraZeneca, NVIDIA, and AWS.
▸ End-to-end runtime stack across Braket, CUDA-Q, and ParallelCluster
▸ 20x faster time-to-solution vs state-of-the-art
▸ 275,000 circuits run on IonQ Forte
▸ Real-world pharma catalyst: nickel-catalyzed synthesis
Quantum-classical isn't the future. It's the format.
IonQ is running it today.

3
11
102
4,277

9 Jun 2025
$IONQ By integrating IonQ's Forte quantum processing unit (QPU) with the NVIDIA CUDA-Q platform through Amazon Braket and AWS ParallelCluster services. The technique maintained accuracy while reducing the expected total runtime from months to days.
1
6
254

9 Jun 2025
다음은 2025년 6월 9일 발표된 $IonQ 의 공식 보도자료 전체 한국어 번역입니다:
---
IonQ, AstraZeneca, AWS, NVIDIA와 함께 양자 가속 신약 개발 애플리케이션 시연…기존 대비 20배 속도 향상
2025년 6월 9일
독일 함부르크 ISC 고성능 컴퓨팅 컨퍼런스에서 시연 예정
메릴랜드, 칼리지파크 – 상업용 양자 컴퓨팅 및 양자 네트워킹 분야의 선도기업 IonQ(NYSE: IONQ)는 오늘, AstraZeneca, Amazon Web Services(AWS), NVIDIA와의 공동 연구 프로그램을 통해, 세계적으로 혁신적인 헬스케어, 생명과학, 화학 분야에서 활용 가능한 양자 가속 컴퓨팅 화학 워크플로우 개발 및 시연 결과를 발표했습니다.
이 협업의 결과는 2025년 6월 10일부터 13일까지 독일 함부르크에서 열리는 ISC High Performance 컨퍼런스에서 공개됩니다.
IonQ가 설계한 이 워크플로우는 제약 개발 과정에서의 복잡한 문제들을 해결하는 데 도움을 주는 하이브리드 양자-고전 컴퓨팅 방식의 엔드 투 엔드 사례로, 신약 개발 초기 연구 단계에서 속도와 효율을 크게 향상시킬 수 있는 잠재력을 지니고 있습니다. 현재 신약 개발은 보통 10년 이상 소요되고 수십억 달러가 드는 비용 문제를 안고 있는 만큼, 계산 병목 현상을 줄이는 기술적 발전은 전략적 및 상업적으로 큰 가치를 창출할 수 있습니다.
이번 시연은 **스즈키-미야우라 반응(Suzuki-Miyaura reaction)**의 핵심 단계를 중심으로 진행되었습니다. 이 반응은 소분자 약물 합성에 사용되는 대표적인 화학 반응입니다. IonQ의 **Forte 양자 처리 장치(QPU)**를 NVIDIA의 CUDA-Q 플랫폼, Amazon Braket, AWS ParallelCluster 서비스와 통합함으로써, 기존 대비 20배 이상의 ‘종단 간 해결 시간(time-to-solution)’ 단축이라는 성과를 달성했습니다. 정확도는 유지한 채, 계산 시간은 기존 수개월에서 수일로 대폭 줄였습니다.
**IonQ CEO 니콜로 드 마시(Niccolo de Masi)**는 “이번 AstraZeneca와의 시연은 양자 컴퓨팅이 실제 화학 및 소재 과학 분야에서 어떻게 활용될 수 있는지를 보여주는 의미 있는 진전이며, IonQ의 기업용 양자 컴퓨터가 이 도전을 해결하기에 매우 적합함을 입증한 사례입니다. 촉매 반응을 정확하고 빠르게 모델링할 수 있는 능력은 단순한 과학적 성과를 넘어, 산업 전체에 혁신을 가져올 수 있는 하이브리드 컴퓨팅의 미래를 보여주는 것입니다.”라고 밝혔습니다.
**AstraZeneca의 Anders Broo 박사(제약과학 R&D 총괄 이사)**는 “이번 협업은 신약 개발 경로 최적화에 중요한 촉매 반응의 활성화 장벽을 정확히 모델링할 수 있는 방향으로 나아가는 중요한 단계이며, 앞으로의 진전을 기대합니다.”라고 말했습니다.
AWS Amazon Braket 총괄 Eric Kessler는 “미래의 양자 컴퓨터는 기존 컴퓨팅을 대체하지 않고, 고성능 컴퓨팅(HPC) 파이프라인 내에서 특정한 계산 집약적 단계만을 가속화할 것입니다. Amazon Braket 상의 양자 컴퓨팅과 AWS의 확장 가능한 GPU 리소스를 결합함으로써, 우리는 AstraZeneca의 미래 연구를 뒷받침하고 있습니다.”라고 설명했습니다.
NVIDIA의 Quantum 및 CUDA-X 총괄 Tim Costa는 “최첨단 양자 및 GPU 컴퓨팅을 하이브리드 워크플로우에 결합하는 것이야말로 양자의 잠재력을 실현하는 길입니다. 이번 작업은 양자 가속 슈퍼컴퓨팅이 실제로 중요한 문제에 적용될 수 있다는 점에서 의미 있는 진전입니다.”라고 강조했습니다.
IonQ와 파트너들은 IonQ 하드웨어 상에서 역대 가장 복잡한 화학 시뮬레이션인 스즈키-미야우라 반응의 대규모 엔드 투 엔드 시뮬레이션을 성공적으로 시연했습니다. 이 하이브리드 양자-고전 컴퓨팅 워크플로우는 Amazon Braket에서 CUDA-Q로 오케스트레이션되고, AWS ParallelCluster의 NVIDIA H200 GPU로 가속되었습니다. 이로써 기존 벤치마크 대비 20배 이상의 시간 단축을 달성했습니다.
이번 연구는 고정밀 분자 모델링에서 기존의 컴퓨팅 한계를 극복하고, 더 복잡한 화학 시스템 분석을 가능하게 하는 하이브리드 양자 컴퓨팅의 실제 효용성을 보여주고 있습니다. 이는 순수 고전적 방식보다 하이브리드 양자-고전 방식이 더 우수한 결과를 낼 수 있음을 입증한 IonQ의 최근 실증 결과들과 연결되는 성과입니다.
이 연구의 자세한 내용은 6월 10–13일 독일 함부르크에서 열리는 ISC High Performance 컨퍼런스의 IonQ 부스(A25) 또는 IonQ 기술 블로그에서 확인하실 수 있습니다.
5
32
4,212

4 May 2025
『Optical Review』に論文が載りました.オープンアクセスです!
クラウド環境で大規模並列処理してカメラレンズのゴースト解析を高速化.OpenMPI利用LinuxコマンドラインツールでAWS ParallelClusterにも対応
link.springer.com/article/10…
4
180

11 Mar 2025
ここのリポジトリですが、とりあえず AWS 上で分散学習をしたいときに参考に始められるアセットが盛りだくさん(事前学習、ファインチューニング)ですし、SageMaker HyperPod 、ParallelCluster 、EKS と環境整備の選択肢も豊富です

ML Training Reference Architectures & Tests
github.com/aws-samples/awsom…
4
591