
When I'm introduced to a new board game, each friend takes a turn explaining their most essential strategy, so I end up with virtually every single game detail. Sometimes, we even use the first 20 minutes reading said details from the rulebook... As soon as we start playing, however, nearly all these details end up being irrelevant for actually playing the game. We really only need to look at the rulebook, so I can convince Jonas that it is indeed possible to achieve world domination in a single turn, although I seemingly did nothing for 3 hours and swept in at the very last minute to take it all (Board game: Risk, 6-players).
Anyways, for that reason, I skip almost all details when introducing someone to a new game, and try to mention only the 2 or 3 compressed scenarios I think are the most important to understand (filling in details as needed). When it works, it's certainly much more effective, yet my friends' approach, in contrast, always works. But I don't think it's a lack of detail, more a question of how the scenarios are structured (also in the rulebooks). And even when it fails, just repeating the information, the same (word-for-word) information, once or twice, usually gets everyone on the same page.
To the same tune, many approaches towards making neural networks more efficient identify seemingly redundant or repeated details and remove them. Here, as with many other things in life, we might've slightly overlooked the significance of the details, especially those that are repeated to us. If we can't see the forest for the trees, we tend to burn a few of them, increasing our FOV. Rather, I'd argue, that many times, the forest is easier to see, were we to plant trees among those already there. In that sense, repeatability and similarity between details can also help reveal the bigger picture, not just obfuscate it.
Besides this (more personal) lens, we take up the perspective of algorithmic complexity in our recent work, Algorithmic Simplification of Neural Networks with Mosaic-of-Motifs, asking why neural networks, much like our board game rules for world domination, are suited for compression. We demonstrate that parameters of trained models have more structure and, hence, exhibit lower algorithmic complexity compared to the weights at (random) initialization. In turn, we present a constrained model parameterization (MoMos) that induces repeatability and structure in neural networks, yielding models with lower algorithmic complexity, including a theoretical justification for how the parameterization settings control this complexity.
Paper: arxiv.org/pdf/2602.14896
ABC: abitofcomplexity.com,asking why neural networks, much like our board game rules for world domination, are suited for compression. We demonstrate that parameters of trained models have more structure and, hence, exhibit lower algorithmic complexity compared to the weights at (random) initialization. In turn, we present a constrained model parameterization (MoMos) that induces repeatability and structure in neural networks, yielding models with lower algorithmic complexity, including a theoretical justification for how the parameterization settings control this complexity.
A repeated, but not redundant, thank you to my co-authors Tong Chen, Jonathan Wenshøj, Erik B Dam, and Raghavendra Selvan, for making it easier to see the forest for the trees, and a special thanks to Eduardo Yuji Sakabe for planting some more along the way.
14

3d editor simplexgen... was about to get rectangular surface parameterization ported to threejs in the browser.
49
Monte Hoover retweeted

Jun 10
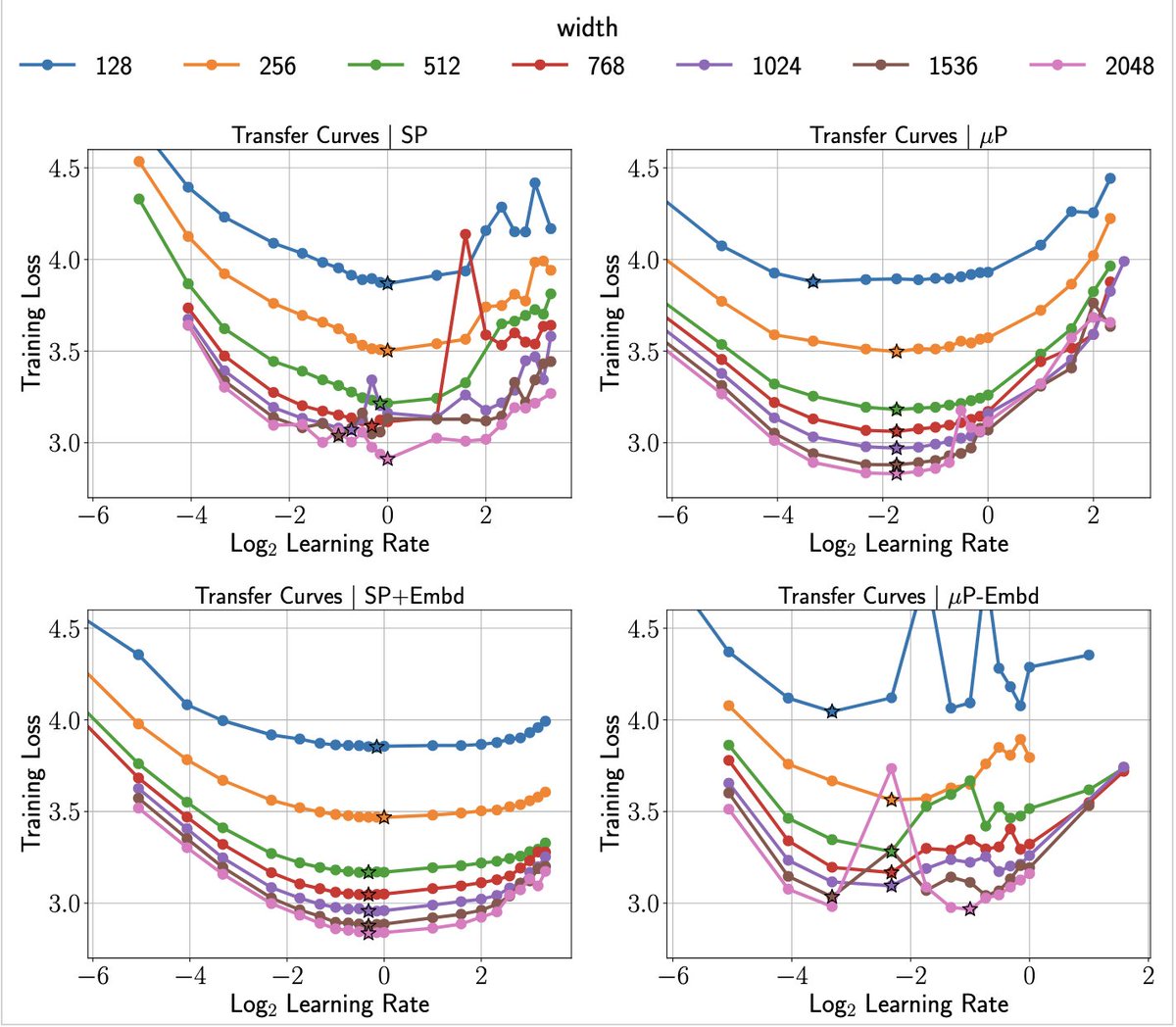
How do you know if a parameterization (e.g., µP) or a fitted Hyperparameter (HP) scaling law actually gives reliable transfer?
@MBarkeshli and I propose a three-metric framework to quantify the quality of transfer and use it to show that µP’s advantage over SP in Transformers trained with AdamW comes from training the embedding layer fast enough.
Below: speeding up the embedding LR in SP (SP Embd) recovers µP-like transfer, and slowing it down in µP (µP-Embd) wrecks training with severe instabilities.
A thread 🧵
1/n
1
17
56
4,610

17/25 𝗙𝗹𝗲𝘅𝗶𝗯𝗹𝗲 𝗙𝗹𝗼𝘄𝘀 𝗳𝗼𝗿 𝗕𝗶𝗼𝗹𝗼𝗴𝗶𝗰𝗮𝗹 𝗦𝗲𝗾𝘂𝗲𝗻𝗰𝗲 𝗗𝗲𝘀𝗶𝗴𝗻
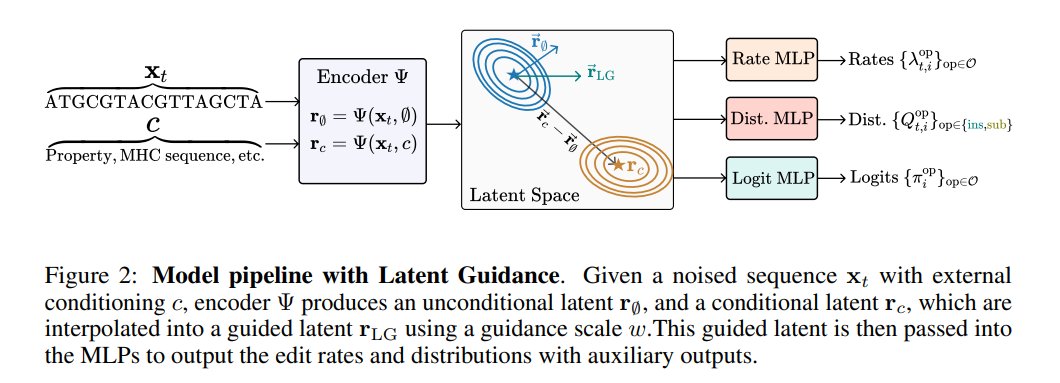
This paper addresses limitations in Discrete Flow Matching (DFM) for biological sequence design by proposing a structured coupling for domain-specific preferences and a latent edit-based rate parameterization for variable-length generation. It introduces a latent classifier-free guidance mechanism and Dirichlet-prior temperature scaling for test-time control, achieving state-of-the-art performance across diverse tasks including density estimation, unconditional/conditional DNA, and peptide sequence generation.
#DiscreteFlowMatching #BiologicalSequenceDesign #GenerativeModels #Bioinformatics #MachineLearning #DNAgeneration #PeptideGeneration
Paper Link: arxiv.org/abs/2606.10543

1
25


That exponential in there reminds me of the Schwinger parameterization.
1
77

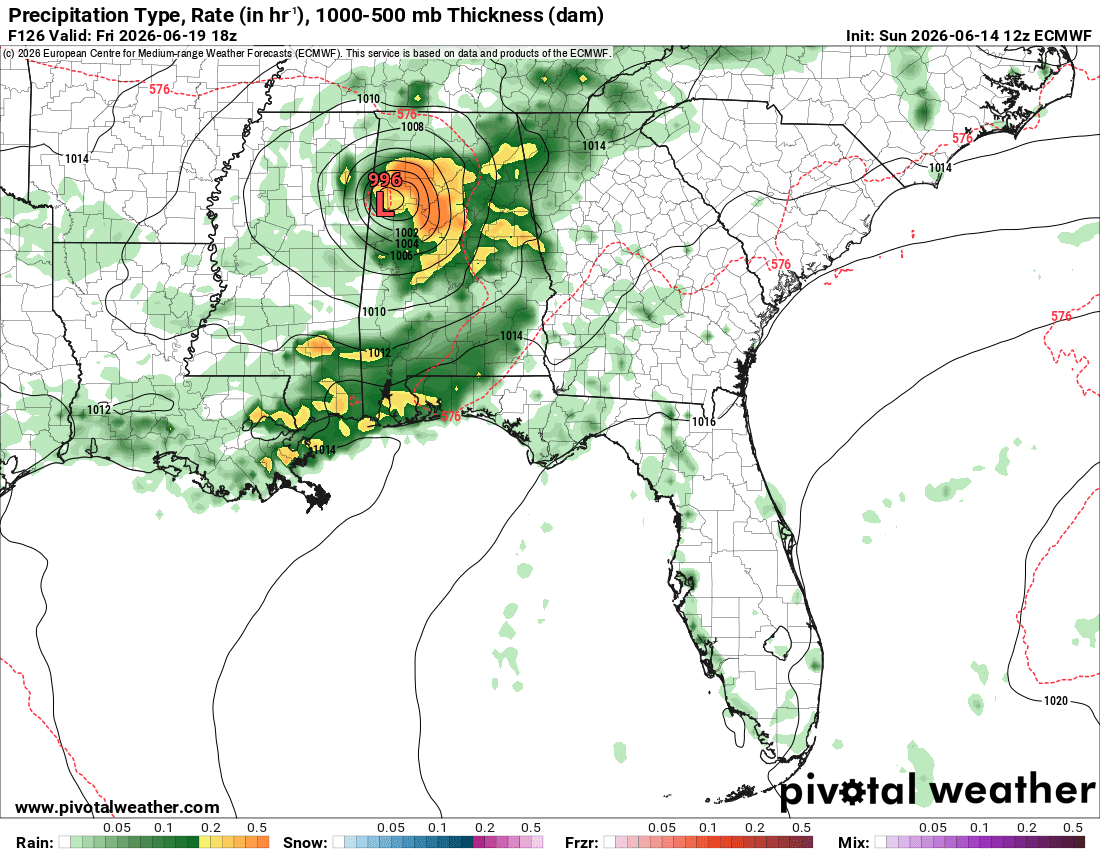
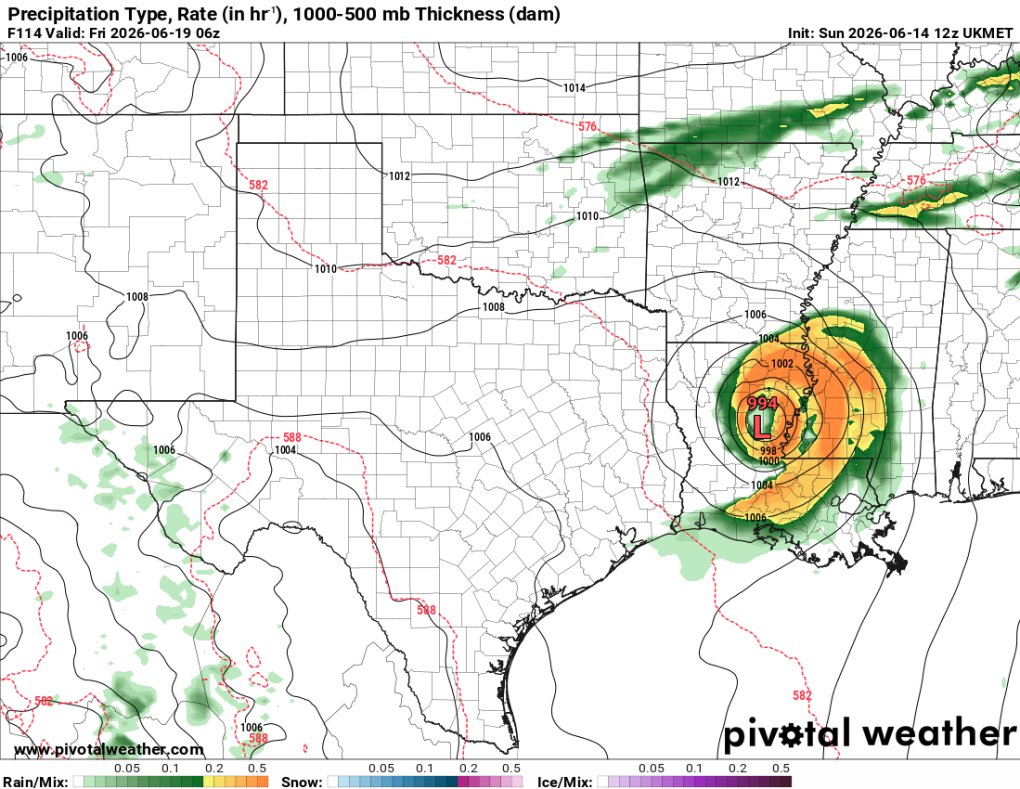
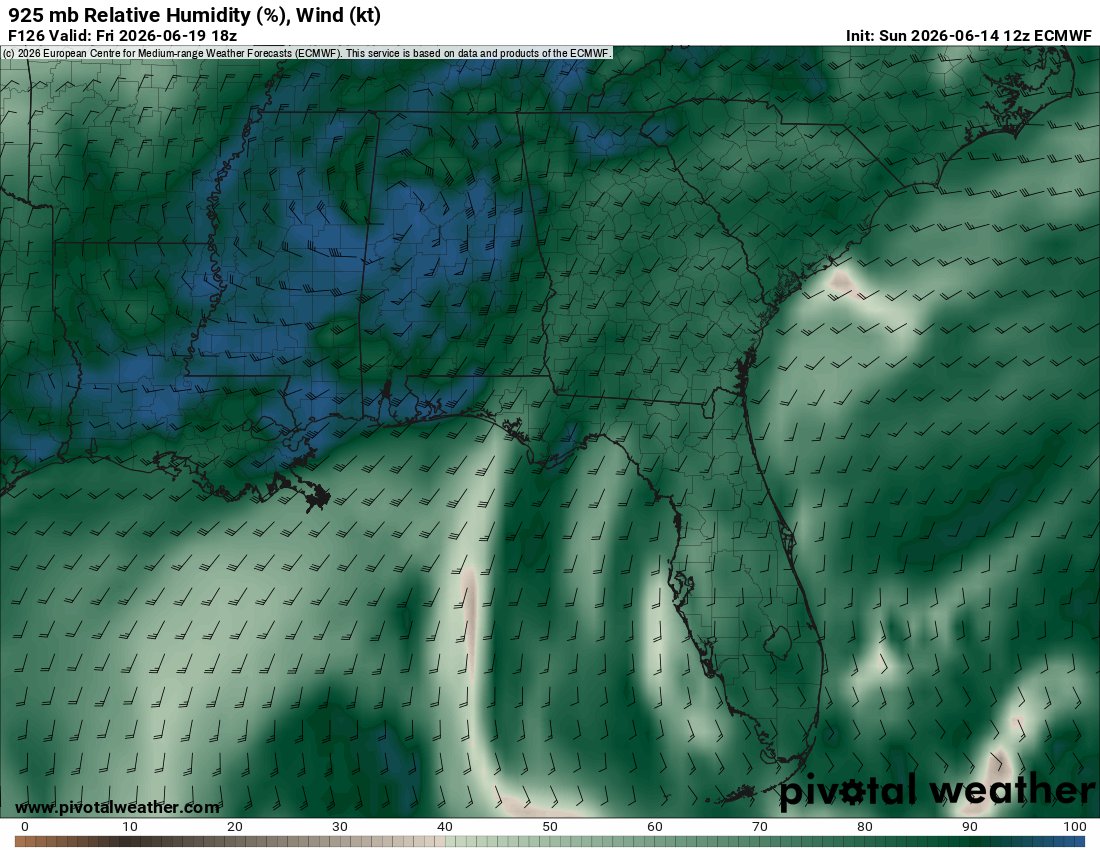
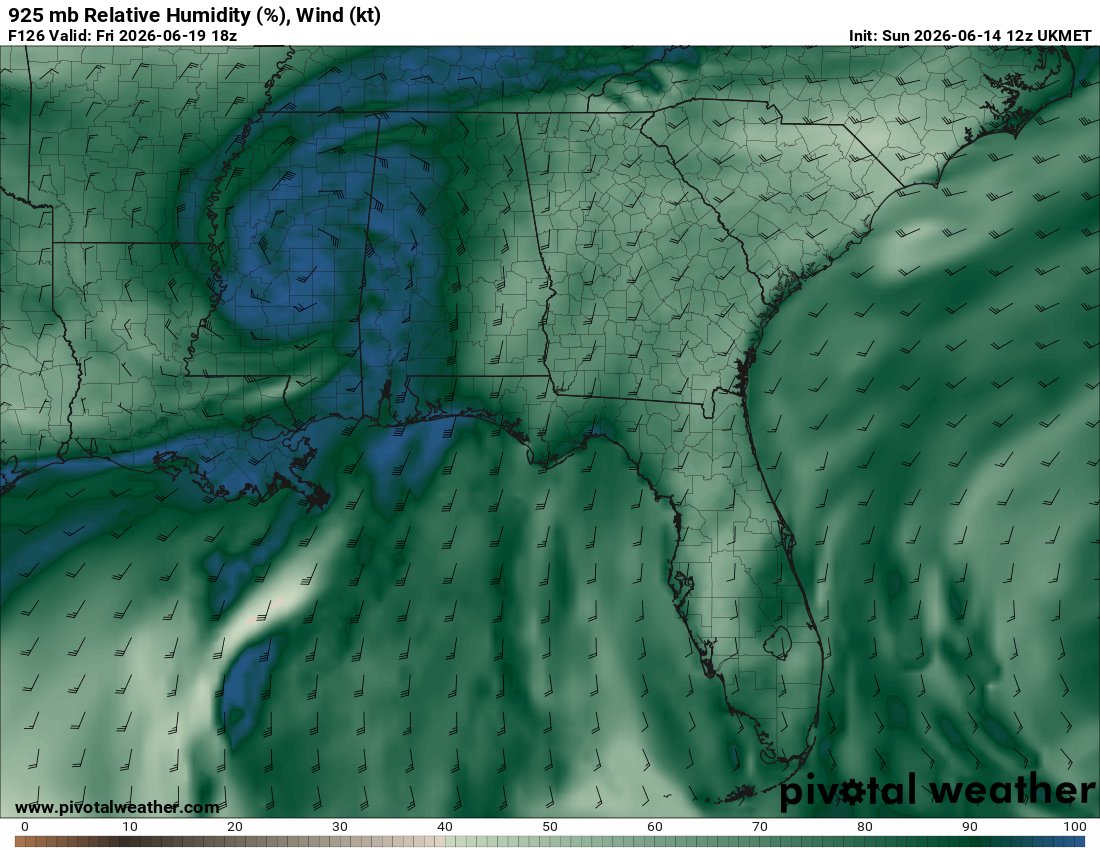
Alongside the ECWMF solutions, the UKMET is even more aggressive w/ evolution of a potent warm-core low over the Gulf coast states next week. These models have surface/boundary layer flux parameterization enabling unusual sustenance of lows in significantly moist environments.
2
6
48
3,226


@CNPYNetwork, application architects deploy fully programmable sovereign account constructs, natively enforcing decentralized multi-signature execution, permissioned access routing, and automated security parameterization.

1
11

Jun 13
The recognition of a parameterization grounded in the physical nature of the economy is possible provided we acknowledge that it is a system subject to forms of universality that reproduce recurrent probabilistic and physical properties.
1
11


Jun 13
this is probably a harder example to replicate, where we generate some kind of parameterization around the edge loop, that goes from 0 to 1. And then we can make varying fillets along the edge

1
1
23


Jun 12
Attacker inserts malicious SQL codes into input fields.
Parameterization
ORMs
33

📢 June 15 (Mon): Uniform Diffusion Models Revisited: Leave-One-Out Denoiser and Absorbing State Reformulation
🤔 Discrete diffusion models are often trained through clean-data prediction, but the prediction can be used in different ways to define the reverse dynamics. In Masked Diffusion Models (MDM) these choices largely coincide, whereas in Uniform Diffusion Models (UDM) they do not.
💡 The authors show that the standard plug-in bridge parameterization for UDM is not optimized by the denoising posterior, but by a leave-one-out posterior that predicts each clean token without using its own noisy observation. This identifies a mismatch between the plug-in ELBO and the usual cross-entropy denoising objective.
🔧 The authors characterize the leave-one-out target and derive exact conversions between the denoiser, the leave-one-out posterior, and the score. These conversions allow them to disentangle parameterization and the training objective.
📈 Their results also lead to inference improvements without any additional training through an informed predictor-corrector sampler and improved temperature sampling based on the leave-one-out predictor.
🔧 The authors further introduce an absorbing-state reformulation of uniform diffusion that preserves the UDM joint law while decomposing it into masked-diffusion-like sampling operations, with simpler denoising posteriors, carry-over unmasking, and a natural remasking mechanism.
📈 On language modeling, leave-one-out parameterizations consistently improve UDM generation, while the absorbing construction matches or surpasses masked diffusion. These results suggest that the empirical gap between masked and uniform diffusion is driven less by the choice of marginals themselves than by parameterization and sampling design.
This Monday, Samson Gourevitch (@samsongvch, samsongourevitch.github.io/), Yazid Janati (@yjelid, yazidjanati.github.io/), and Dario Shariatian (@dario_sha, darioshar.github.io/) will present their paper "Uniform Diffusion Models Revisited: Leave-One-Out Denoiser and Absorbing State Reformulation".

1
6
25
5,660

Full Aiken integration with the IDE - from scaffolding to runners that use the IDE UI.
Project creation, testing, building, parameterization, artifact generation, smart context-aware autocomplete/suggestions that can infer types and provide hints based on context, automatic imports -it has EVERYTHING.
And what about local project-aware toolchains?
You can work on different projects with different versions of Aiken or stdlib. No more regression fear!
With customizable runners, you no longer need to write commands in the terminal. But if that’s what you’re used to, the terminal launched inside the IDE will use the exact Aiken version configured for your project.
Want to use runners but still prefer working with a console? You can do that too. All runners have two modes: Integrated UI and TTY.
And do you know what else is great about runners?
You can chain them together. One click launches the whole pipeline!
Aiken development without compromises.
Configure your pipeline, create your comfort zone, and build.

Aiken Plugin 2.0 is here!
It was a long road - much longer than we expected. But it was worth it.
#aiken #jetBrains #intelliJ #plugin

2
4
263

Jun 11
6/ Bigger picture: maybe PEFT doesn’t need more tricks, modules, or complexity.
Maybe it just needs a better parameterization.
That’s the idea behind GPart: simple, geometry-preserving, and competitive across domains.
#PEFT #LoRA #LLM #MachineLearning #FineTuning
1
104

Jun 11
the LLM mantra has been this deep double descent, More parameterization never hurts, somehow lets LLMs escape fundamental laws of modeling…
1
62