🚀 Hey Founders & Builders!
Looking to connect with people building cool things in tech and startups:
🍽️ SaaS Products
🚀 Tech Startups
📲 Automation Tools
🧠 AI Solutions
📱 Mobile & Product Development
🌐 Web Apps
💻 Developers & Indie Builders
Drop your project below 👇
✅ What are you building?
🎯 Who is it for?
🚧 What stage are you at (Idea / MVP / Live / Scaling)?
💡 What problem are you solving?
Let’s connect, share ideas, and support each other in building impactful products. 🚀
#SaaS #Tech #AI #Automation #WebApps #Startups #IndieHackers #BuildInPublic #Developers #Founders #ProductDevelopment
1
1
3
29

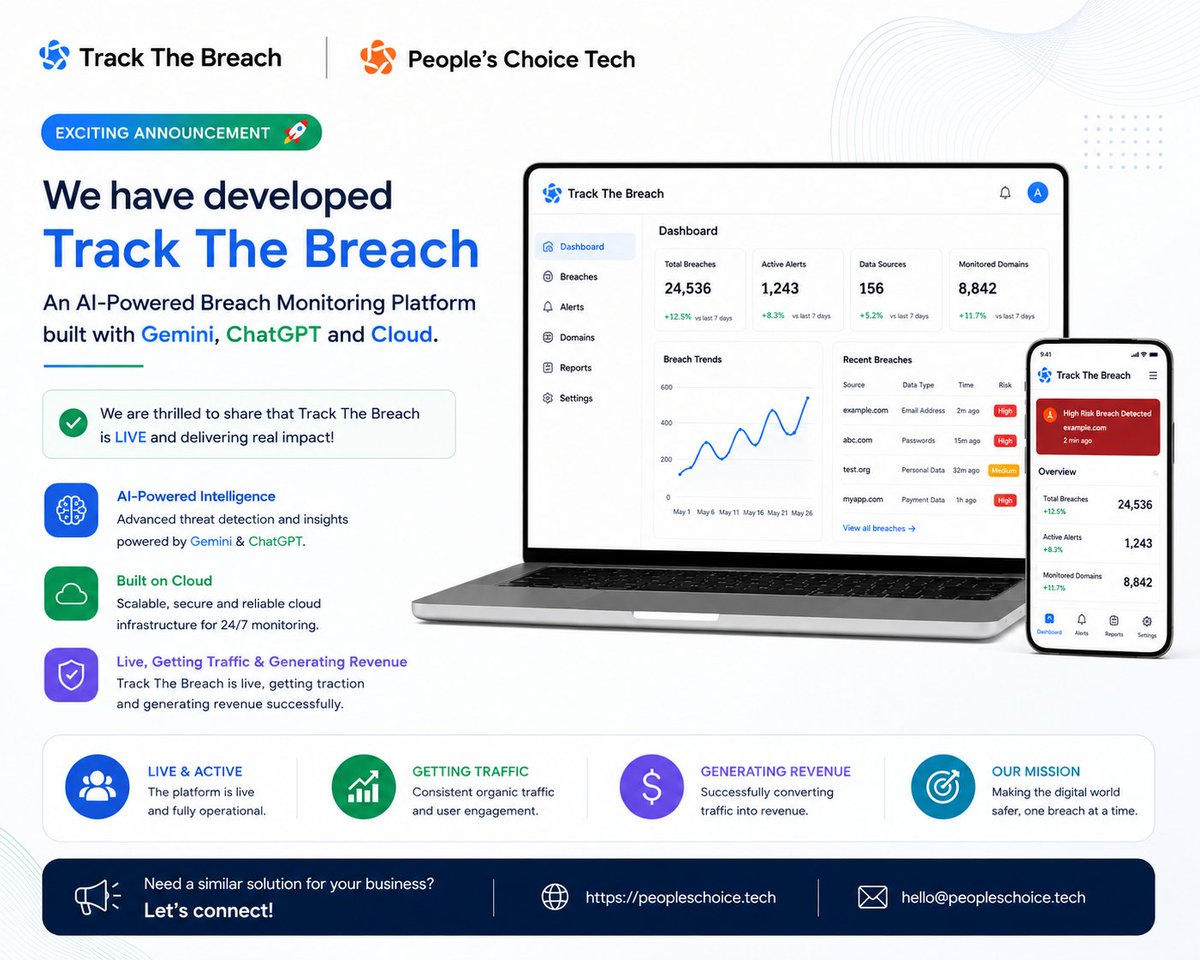
Most people talk about #AI, we decided to #build with it.
Over the last few months, our team at People's Choice Tech has been working on a product called @trackthe_breach an AI-powered platform designed to help individuals understand their digital exposure and online identity risks.
From concept and architecture to development and deployment, the entire platform was built using a combination of modern technologies, including:
#Gemini , #ChatGPT , #Claude ,
#Cloud Infrastructure
#Automation & AI Workflows ,
#Custom Software Engineering
Today, Track The Breach- trackthebreach.com is live.
More importantly:
✔ Real users are using it
✔ Organic traffic is growing
✔ Revenue is being generated
✔ New features are being shipped continuously
Building products teaches lessons that no presentation, course, or meeting can.
You learn how users think.
You learn what works.
You learn what doesn't.
And most importantly, you learn how to turn ideas into real businesses.
Track The Breach is not just a product launch for us.
It's proof that with the right vision, technology, and execution, ideas can become scalable digital products.
If you're planning to build an AI application, SaaS platform, enterprise software, mobile app, or custom technology solution, we'd love to help bring your vision to life.
Building products.
Solving real problems.
Creating long-term value.
Visit us for more info : peopleschoice.tech/
Share your req : hello@peopleschoice.tech
#TrackTheBreach #PeoplesChoiceTech #ArtificialIntelligence #GenerativeAI #ChatGPT #GeminiAI #ClaudeAI #SoftwareDevelopment #CustomSoftwareDevelopment #SaaS #ProductDevelopment #StartupJourney #BuildInPublic #CloudComputing #DigitalTransformation #Technology #Innovation #Entrepreneurship #CyberSecurity #DataPrivacy
1
14

👨🎓 Open to Students, Faculty & Industry Professionals
📌 Limited Registrations Available
#TCE #TSSCAR #SystemsThinking #BusinessManagement #ProductDevelopment #StartupDevelopment #ProfessionalDevelopment
1
6

⚠️ Is Your Product Ready for Mass Production? 📦
Success starts before production. Reduce risks, choose better suppliers, and scale with confidence.
👉 Read the Guide
blog.widq.com/how-custom-pro…
#WIDQ #CustomProduct #ProductDevelopment #ODM #PrototypeDesign #Manufacturing

1

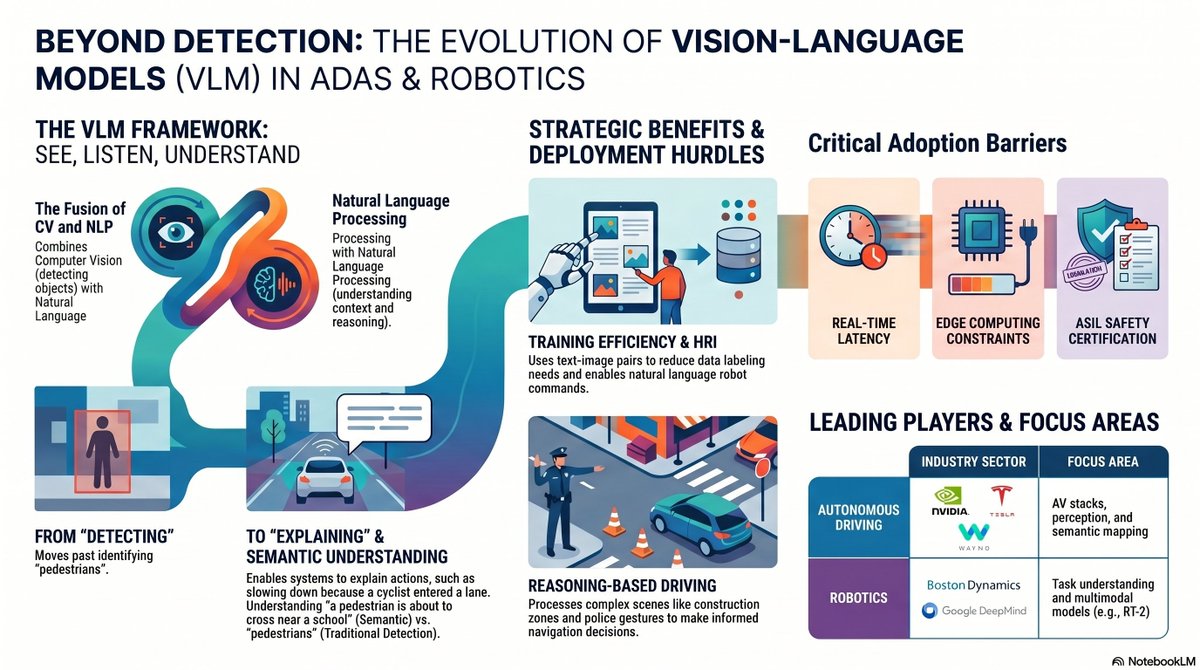
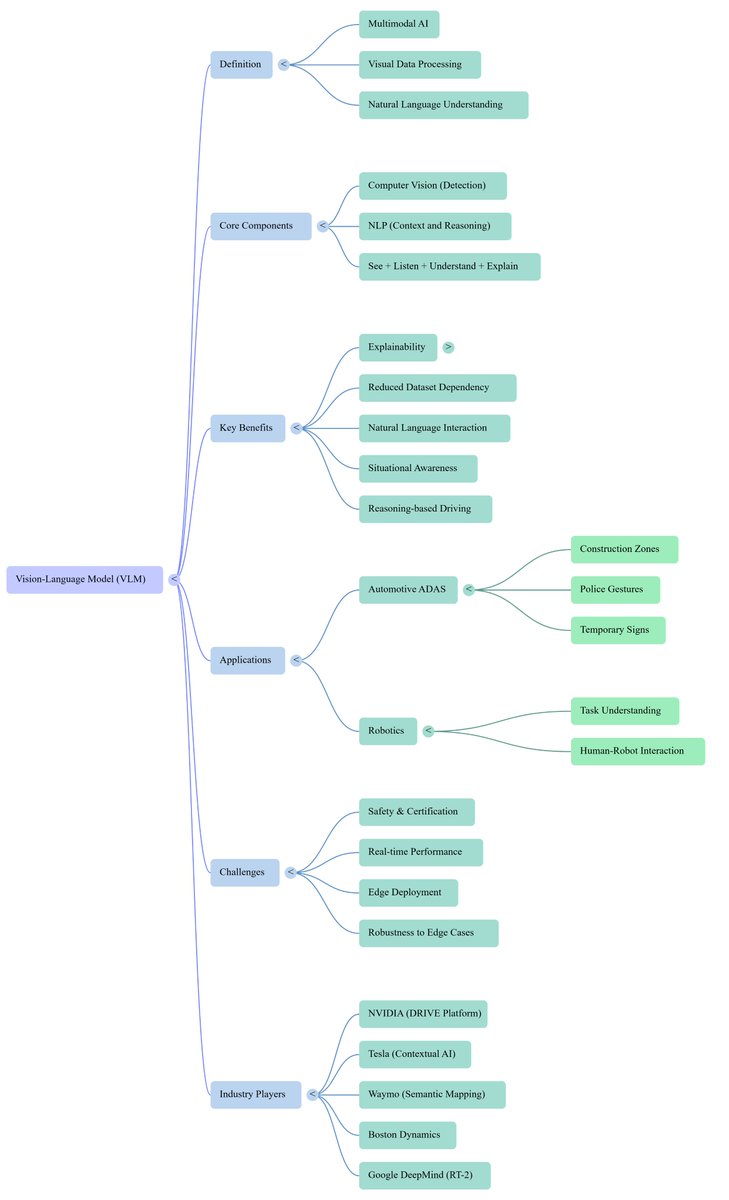
𝐕𝐢𝐬𝐢𝐨𝐧-𝐋𝐚𝐧𝐠𝐮𝐚𝐠𝐞 𝐌𝐨𝐝𝐞𝐥(𝐕𝐋𝐌)
𝐖𝐡𝐚𝐭 𝐢𝐬 𝐕𝐋𝐌?
A Vision-Language Model (VLM) is an AI model that understands both visual data (images/video) and natural language (text/commands).
𝐖𝐡𝐞𝐫𝐞 𝐰𝐢𝐥𝐥 𝐕𝐋𝐌 𝐛𝐞 𝐮𝐬𝐞𝐝?
It will be useful in the Automotive ADAS and Robotics systems and product development.
𝐖𝐡𝐚𝐭 𝐝𝐨𝐞𝐬 𝐚 𝐕𝐋𝐌 𝐚𝐜𝐭𝐮𝐚𝐥𝐥𝐲 𝐝𝐨?
A Vision-Language Model combines:
* 𝐂𝐨𝐦𝐩𝐮𝐭𝐞𝐫 𝐕𝐢𝐬𝐢𝐨𝐧 (𝐂𝐕) → Detects objects, lanes, pedestrians, traffic signs
* 𝐍𝐚𝐭𝐮𝐫𝐚𝐥 𝐋𝐚𝐧𝐠𝐮𝐚𝐠𝐞 𝐏𝐫𝐨𝐜𝐞𝐬𝐬𝐢𝐧𝐠 (𝐍𝐋𝐏) → Understands instructions, context, reasoning
This allows systems to “see listen understand explain” instead of just detecting.
𝐖𝐡𝐲 𝐕𝐋𝐌𝐬 𝐦𝐚𝐭𝐭𝐞𝐫 𝐢𝐧 𝐀𝐃𝐀𝐒& 𝐑𝐨𝐛𝐨𝐭𝐢𝐜𝐬?
· 𝐄𝐱𝐩𝐥𝐚𝐢𝐧𝐚𝐛𝐢𝐥𝐢𝐭𝐲(very important for safety): VLMs can generate explanations:
“Vehicle slowed down because a cyclist entered the lane.”
It will be helpful for:
o Debugging ADAS systems
o Regulatory compliance
o Safety validation
· 𝐓𝐫𝐚𝐢𝐧𝐢𝐧𝐠 𝐞𝐟𝐟𝐢𝐜𝐢𝐞𝐧𝐜𝐲(less labeled data): Instead of thousands of manually labeled datasets, VLMs can use text-image pairs and learn general concepts like “slippery road” or “crowded intersection”. Basically, it reduces dataset dependency.
· 𝐍𝐚𝐭𝐮𝐫𝐚𝐥 𝐥𝐚𝐧𝐠𝐮𝐚𝐠𝐞 𝐢𝐧𝐭𝐞𝐫𝐚𝐜𝐭𝐢𝐨𝐧:Take an example, if you ask a robot “pick up the blue toolbox kit near the car”, then it will detect/identify the blue toolbox kit, estimate the special relation with it, and execute it correctly. It will be helpful for human-robot interaction (HRI).
· 𝐁𝐞𝐲𝐨𝐧𝐝 𝐨𝐛𝐣𝐞𝐜𝐭 𝐝𝐞𝐭𝐞𝐜𝐭𝐢𝐨𝐧: Traditional computer vision-based models detect objects like pedestrians, vehicles, traffic signs, etc. But VLM has a functionality like “A pedestrian is about to cross the road near a school zone”. VLM has the benefits of semantic understanding situational awareness.
· 𝐒𝐜𝐞𝐧𝐞 𝐫𝐞𝐚𝐬𝐨𝐧𝐢𝐧𝐠& 𝐝𝐞𝐜𝐢𝐬𝐢𝐨𝐧 𝐬𝐮𝐩𝐩𝐨𝐫𝐭:In autonomous driving, VLM understands complex scenes like Construction zones, Temporary signs, and Police gestures, then decides on the next action. It helps to move from rule-based → reasoning-based driving
𝐂𝐡𝐚𝐥𝐥𝐞𝐧𝐠𝐞𝐬 𝐢𝐧 𝐀𝐃𝐀𝐒/𝐑𝐨𝐛𝐨𝐭𝐢𝐜𝐬 𝐚𝐝𝐨𝐩𝐭𝐢𝐨𝐧:
* Safety & certification (ASIL compliance, ISO 26262)
* Real-time performance (latency constraints in vehicles)
* Robustness (handling rare edge cases)
* Edge deployment (limited compute in ECUs)
𝐑𝐞𝐚𝐥-𝐰𝐨𝐫𝐥𝐝 𝐞𝐱𝐚𝐦𝐩𝐥𝐞𝐬:
𝐀𝐮𝐭𝐨𝐧𝐨𝐦𝐨𝐮𝐬 𝐃𝐫𝐢𝐯𝐢𝐧𝐠
* NVIDIA: Developing VLM-enabled AV stacks (e.g., DRIVE platform)
* Tesla: Vision-based AI with contextual understanding
* Waymo: integrates perception semantic mapping
𝐑𝐨𝐛𝐨𝐭𝐢𝐜𝐬
*Boston Dynamics: Combining vision task understanding
* Google DeepMind: robotics multimodal models (e.g., RT-2)
#VLM
#VisionLanguageModel
#ProductDevelopment
#AI
#ADAS
#Automotive
#Autonomous
#Autonomy
#Robotics
#Production
15

13h
Most platforms let you create.
Very few let you actually own what you create.
That difference becomes real the moment your work starts to matter. When ownership is unclear, control is limited. When ownership is secured, everything changes.
Here is what that unlocks:
• Your product is tied to you, not just an account
• Ownership is verifiable and cannot be altered
• Your work exists beyond a single platform
• You can hold, transfer, and use it as a real asset
• What you build stays yours as it grows in value
This is the shift from saving files to owning products. With IDEEZA, creation comes with control from day one.
Save this if you believe what you build should truly belong to you.
#IDEEZA #Ownership #Blockchain #Web3 #ProductDevelopment #HardwareInnovation #Makers




17

We’re proud to announce BHC Associates now offers technical support for companies in Mexico, strengthening our commitment to global injection molding consulting excellence. bit.ly/36InvKn #InjectionMolding #MoldDesign #ProductDevelopment #ManufacturingConsulting

7

🚀 Building fewer projects, but more products.
Started working on an idea that solves a real problem instead of just adding another project to my portfolio.
Let's build products, not projects. 💻
#BuildInPublic #ProductDevelopment
4
40

Every great product starts with a smart MVP.
We turn ideas into working prototypes that validate concepts and attract investors — fast and lean.
#MVP #StartupGrowth #Innovation #ProductDevelopment #RemahDigital


Every product will have an AI agent by 2027.
Here's why founders can't ignore this anymore 🧵
1/ They don't sleep, forget, or get tired
AI agents execute 24/7 with zero supervision.
No shifts. No errors from fatigue.
2/ They reason — not just respond
Unlike chatbots, agents plan multi-step workflows,
use tools, and make decisions autonomously.
3/ They plug into your existing stack
APIs, CRMs, databases — no need to rebuild
your infrastructure from scratch.
4/ The cost per task keeps dropping
In 2026, running an agent costs less than
a junior hire per month. And it scales instantly.
5/ Your competitors are already shipping them
The early adoption window is closing.
First movers are locking in user loyalty fast.
We build production-grade AI agents at
@ITechSoftSolutions
Building one for your product? Let's talk 👇
itech-softsolutions.com
#AIAgents #AI #Web3 #LLM #Startup #ProductDevelopment

12

The best products aren't built from templates.
They're built around your business, your users, and your goals.
#CustomDevelopment #Techies #ProductDevelopment #SoftwareSolutions

1

22h
James Hollis suggests that most people don’t suffer from lack of effort, but from lack of awareness about the patterns shaping their choices.
In startups and tech, this shows up when teams build features instead of solving real problems, scale systems without clarity, and chase growth without direction.
At Pitrix Technologies, we believe strong engineering only creates impact when it’s guided by clear thinking. The real edge is not just speed—it’s understanding what to build and why it matters.
Execution is common. Clarity is rare.
#tech #startup #entrepreneurship #innovation #ai #softwaredevelopment #founder #buildinpublic #business #growthmindset #futureoftech #digitaltransformation #productdevelopment #engineering #leadership
13

Jun 13
The biggest shift in tech isn't about coding faster anymore.
It's about thinking clearly and directing AI effectively.
Tools like Claude Code don't just answer questions — they 𝗿𝗲𝗮𝗱 𝘆𝗼𝘂𝗿 𝗰𝗼𝗱𝗲𝗯𝗮𝘀𝗲, 𝘂𝗻𝗱𝗲𝗿𝘀𝘁𝗮𝗻𝗱 𝘀𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲, 𝗮𝗻𝗱 𝗲𝘅𝗲𝗰𝘂𝘁𝗲 𝗰𝗵𝗮𝗻𝗴𝗲𝘀 you can review before shipping.
🔓 This unlocks a new type of builder:
Designers. Consultants. Operators. Business owners.
People with 𝗱𝗼𝗺𝗮𝗶𝗻 𝗲𝘅𝗽𝗲𝗿𝘁𝗶𝘀𝗲 𝗯𝘂𝘁 𝗻𝗼 𝗲𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴 𝗯𝗮𝗰𝗸𝗴𝗿𝗼𝘂𝗻𝗱 can now go from idea → prototype → product without a full dev team.
The competitive advantage is shifting from 𝘁𝗲𝗰𝗵𝗻𝗶𝗰𝗮𝗹 𝗲𝘅𝗲𝗰𝘂𝘁𝗶𝗼𝗻 to 𝗰𝗹𝗲𝗮𝗿 𝗰𝗼𝗺𝗺𝘂𝗻𝗶𝗰𝗮𝘁𝗶𝗼𝗻 𝗮𝗻𝗱 𝘀𝘁𝗿𝗮𝘁𝗲𝗴𝗶𝗰 𝗱𝗶𝗿𝗲𝗰𝘁𝗶𝗼𝗻.
That's the real democratization happening right now.
#AI #NoCode #ProductDevelopment #Entrepreneurship #StartupLife #FutureOfWork #AITools #TechTrends #Innovation #BuildInPublic

1
23

The Global Structure Network Limited is redefining how consumers build capability, establishing the architecture through which their everyday decisions translate directly into long‑term economic value.
theglobalstructurenetwork.co…
#CVHealthForAll #CardiovascularHealth #EUHealth #PublicHealth #CVHealthForAll #aldisüd #aldinord #microbiome #longevity #aging #health #genetics #epigenetics #science #biotech #nutrition #probiotics #GetInvestedStayInvested #HealthPolicy #Science #Leadership #PublicHealth #Engineering #EngineerLife #EngineeringCommunity #STEM #DesignThinking #ProductDevelopment #InnovationInEngineering #SmartDesign #EngineeringSolutions #CivilEngineering #StructuralEngineering #MechanicalEngineering #InfrastructureDesign
#SoftwareEngineering #SystemsEngineering #CodeForGood #DevOps #AIEngineering #ElectricalEngineering #RoboticsEngineering #AerospaceEngineering #Mechatronics
2

Jun 13
🔥 Lynqas 1.0.7 is live.
We're raising the bar.
✅ Real-time AI, mobile & app news
✅ Community-first onboarding
✅ Weekly featured projects
✅ Builder rankings
✅ Image replies
✅ Stronger project curation
On Lynqas, quality matters.
Before publishing a first project, every builder contributes to the community first.
Less noise.
More builders.
Better projects.
#Lynqas #BuildInPublic #IndieHackers #SaaS #Startup #AI #Founder #Makers #ProductDevelopment #WebDev #MobileDev

ALT lynqas.com
1
2
23

Jun 13
Trend-forward formulation starts with listening. That's how we help brands build products that resonate.
#Vitalpax #SupplementInnovation #ProductDevelopment #WellnessTrends


Jun 13
PopLab Alpha Test Notes 001 || @popdex_
Over the past two weeks, PopDEX invited a selected group of traders into the PopLab Alpha Test, and the feedback was exactly what the team needed.
Built with traders, not just for them, PopDEX has already deployed a new round of optimizations based on real user workflows:
🚀 Faster order placement, response, and position updates
💻 Smoother experience across key trading pages
🛠️ Multiple UI/UX refinements driven by trader feedback
This is more than an Alpha Test. It's a glimpse into how PopDEX is building a trader-first perpetual DEX through continuous iteration and real community input.
More Alpha slots will open gradually.
Trade. Pop. Repeat. 💜
#PopDEX #PopLab #AlphaTest #PerpDEX #TraderFirst #TradePopRepeat #Web3 #DeFi #CryptoTrading #OnchainTrading #TradingCommunity #UX #ProductDevelopment #BuildInPublic #CryptoBuilders


PopLab Alpha Test Notes 001🤖
Over the past two weeks, we invited a selected group of traders into our PopLab Alpha Test.
The feedback was direct, detailed, and exactly what we needed. Based on it, we’ve shipped a new round of optimizations:
- Faster order placement, response, and position updates
- Smoother experience across key trading pages
- Multiple UI/UX refinements based on real trader workflows
PopDEX is being built with traders from day one — not just for them.
More Alpha slots will open gradually. Popping…

1
50

Jun 13
Hey Founders & Builders 👋
Looking to connect with amazing people building in:
🧠 AI Tools
⚙️ Tech Products
🍽️ SaaS
🔥 Product Development
📱 Web Apps
💻 Developer Tools
What are you working on these days? 👇
Drop a comment with:
🚀 Your project name
🔗 Website or demo link
🎯 The problem you're solving
I'm always interested in discovering new products, sharing feedback, and connecting with fellow builders.
Let's support each other and grow together! 🤝
#BuildInPublic #Startup #SaaS #AITools #WebDevelopment #ProductDevelopment #Founders #Tech #Entrepreneurship #IndieHackers 🚀
16
2
6
598

After months of refining my trading journal, I've finally documented every feature and workflow in one guide.
If you're a trader, I'd love your feedback on:
• Features
• Usability
• Missing insights
• Future improvements
stocktrendrider.com/blog/tra…
Your feedback can help make it better for the entire trading community.
#BuildInPublic #TradingJournal #SwingTrading #StockMarket #Fintech #RetailTrader #TradingTools #IndianStockMarket #Investing #ProductDevelopment
1
1
32

Ideas are everywhere. Action is what creates success. 💡
If you're ready to move your invention forward, Inventor Process can help you build a plan, protect your idea, and pursue real opportunities.
#InventorProcess #Innovation #ProductDevelopment #InventorSuccess

2