
10/25 𝗔 𝗩𝗶𝘀𝗶𝗼𝗻-𝗹𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗙𝗿𝗮𝗺𝗲𝘄𝗼𝗿𝗸 𝗳𝗼𝗿 𝗖𝗼𝗺𝗽𝗮𝗿𝗮𝘁𝗶𝘃𝗲 𝗥𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴 𝗶𝗻 𝗥𝗮𝗱𝗶𝗼𝗹𝗼𝗴𝘆
This paper addresses medical imaging AI's poor alignment with radiological practice by formulating comparison as entity-aware cross-image reasoning. It introduces MedReCo-DB, a large-scale comparative imaging resource (>690,000 images, 8 institutions, 7 modalities), used to develop MedReCo, an entity-aware visual encoder, and MedReCo-VLM, a vision-language model. MedReCo achieved the highest Recall@1 in 12 internal settings and improved external retrieval by a mean of 6.0 percentage points, while MedReCo-VLM improved longitudinal follow-up accuracy by 14.5-46.5 percentage points on chest radiographs and 13.0-27.9 percentage points on CT, providing a more clinically aligned foundation for medical imaging AI.
#MedicalImagingAI #RadiologyAI #ComparativeReasoning #MedReCo #MedReCo-VLM #VisionLanguageModel #ClinicalAI #MedicalDatasets
Paper Link: arxiv.org/abs/2606.06407


1
34

Apr 2
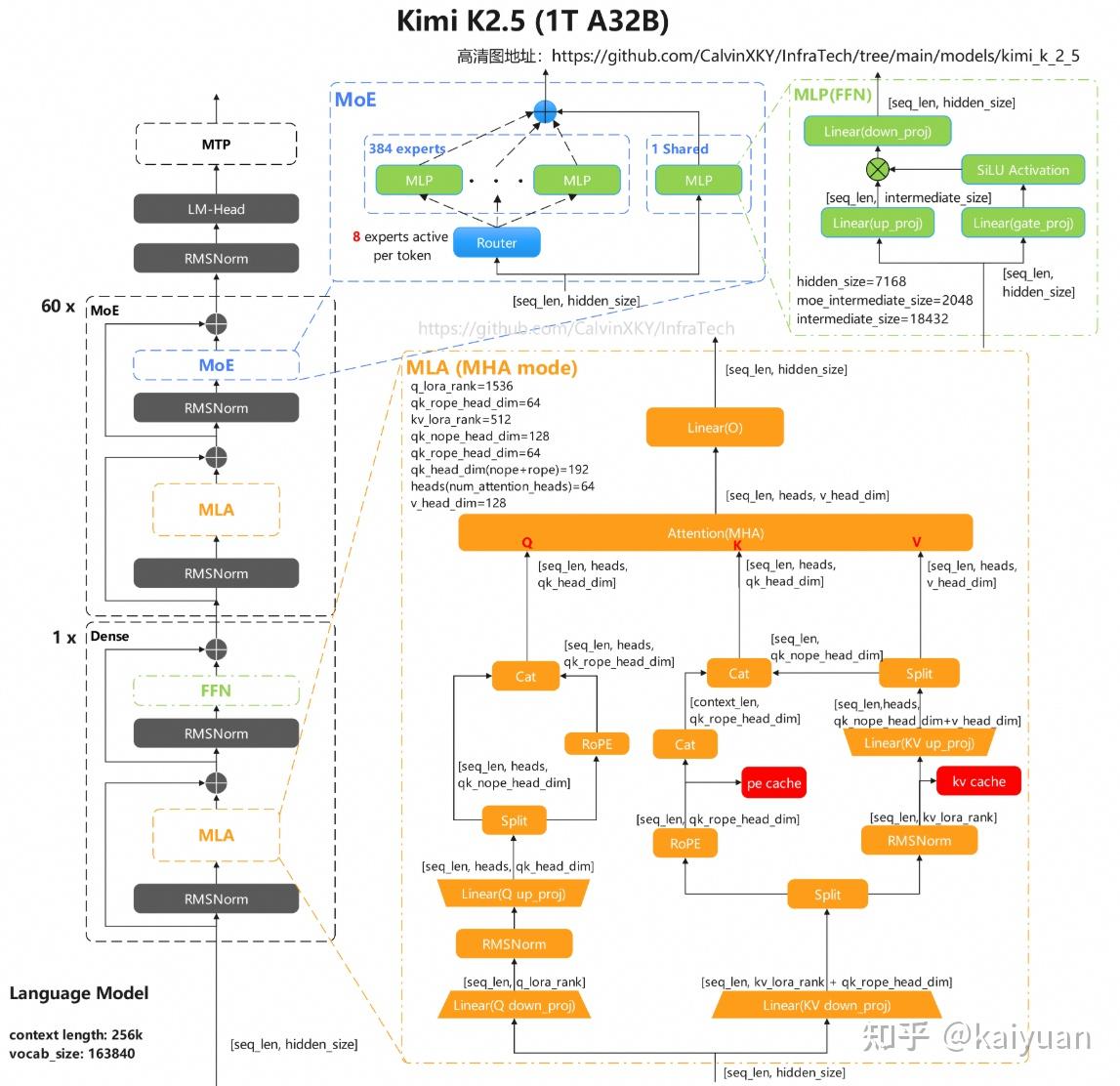
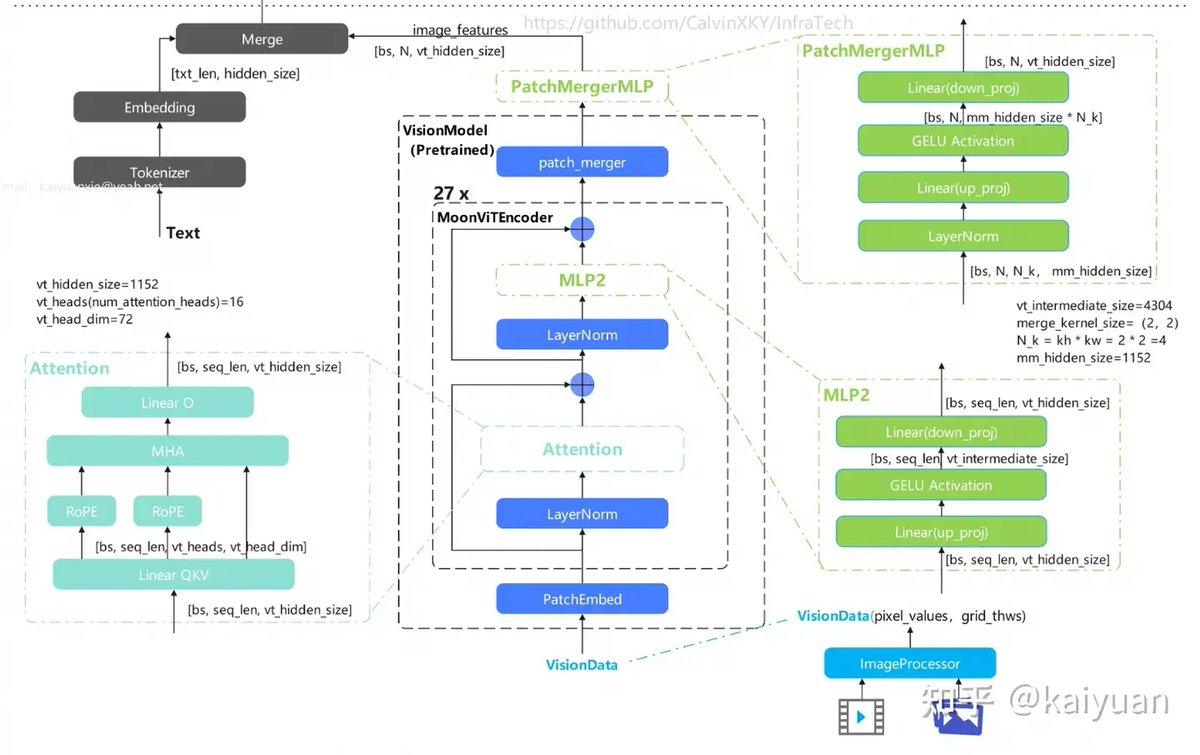
🔥 What makes Kimi K2.5 a standout in 2026’s multimodal AI race? Here’s a deep dive into its core architecture from Zhihu contributor kaiyuan 👇
🤖 Core Foundation (Vision-Language Native Design)
• Built on Kimi-K2-Base, pre-trained on ~15T mixed vision & text tokens 📊
• Combines MLA MoE architecture (inspired by DeepSeek V3) MoonViT vision encoder
• Natively supports instruct & thinking modes, adapting to diverse tasks
📐 Key Technical Standouts
• Total params: 1T (activated: 32B) — efficient scaling via MoE architecture
• Context window: 256K — perfect for long-horizon multimodal tasks
• 61 layers (only 1 dense layer) — streamlined for speed without capability loss
• 64 MLA attention heads 384 MoE experts (8 selected per token)
• MoonViT vision encoder (400M params) — enables seamless visual-text fusion
⚖️ How It Differs from DeepSeek V3
• 1 dense layer (vs. 3 in DSV3) — reduces redundancy, boosts efficiency
• 384 MoE experts (vs. 256 in DSV3) — better task specialization
• 160K vocab size (vs. 129K in DSV3) — enhanced text understanding
🔗 Vision-Language Fusion Pipeline (6-Step)
Preprocess → Patch embedding (spatial/temporal encoding) → Multi-layer encoding → Patch pooling/merging → MMProjector alignment → Sequence concatenation
✅ Core Takeaway
Kimi K2.5 isn’t just another multimodal model — it balances scale (1T params) and efficiency (32B activated), with a native vision-language design that outperforms competitors in seamless integration.
🔗 Full article(CN):zhuanlan.zhihu.com/p/2021161…
#AI #Engineering #Tech #KimiK25 #VisionLanguageModel
Apr 2

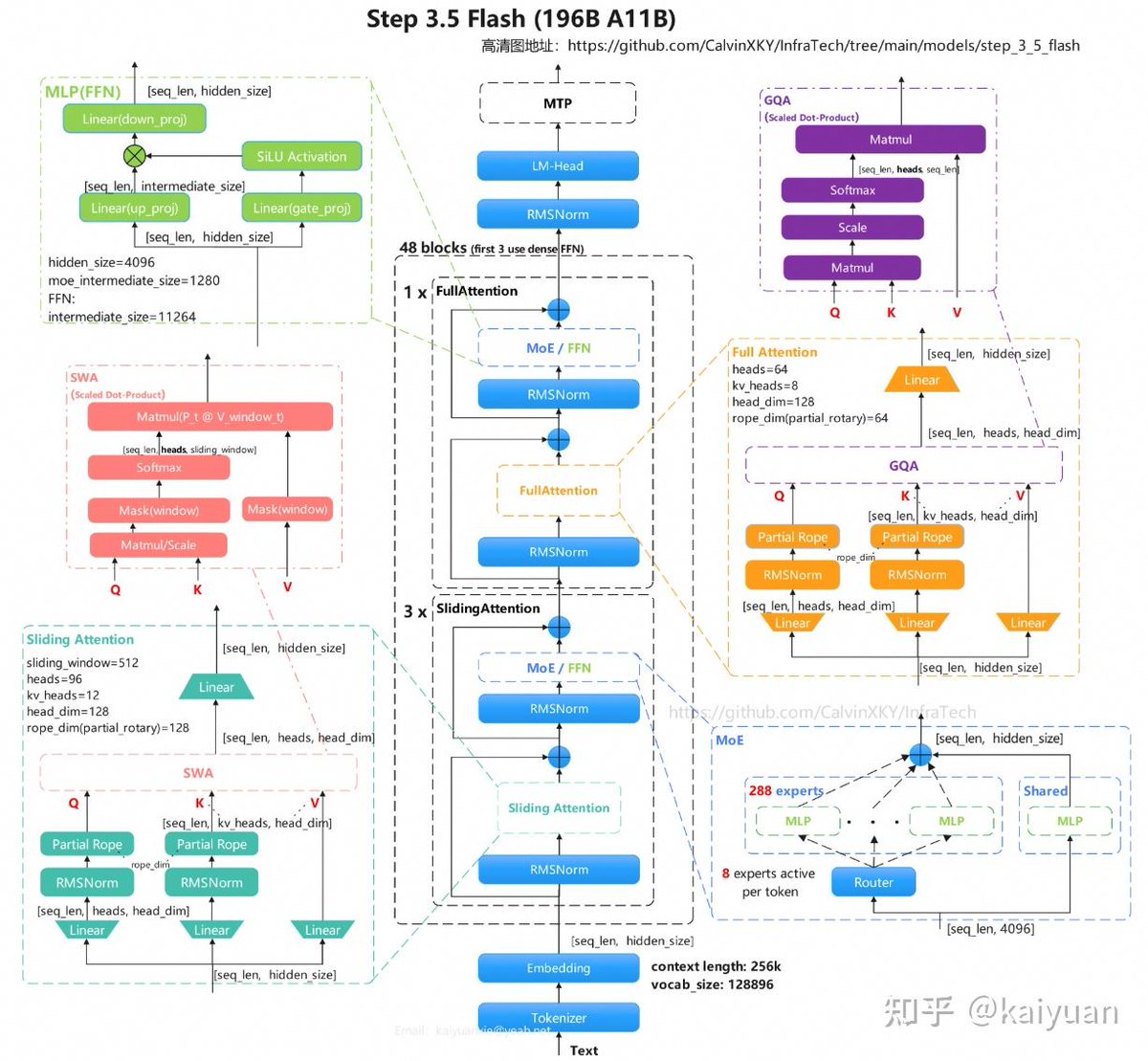
🧵As 2026 unfolds, sparse MoE models are emerging as the new backbone for high-throughput inference and Agent workloads. Step 3.5 Flash from StepFun @StepFun_ai stands out with its efficient attention mixture design.
Here’s a technical deep dive from Zhihu contributor kaiyuan 👇
🤖 Model Overview
• Open-source MoE LLM built for high-throughput inference & Agent scenarios
• Matches or exceeds leading models in reasoning, coding, and Agent benchmarks
• Delivers speed-quality balance via sparse MoE routing Multi-Token Prediction (MTP)
📐 Core Architecture
• Backbone: Transformer MoE | Total params: ~196B | Active params: 11B/token
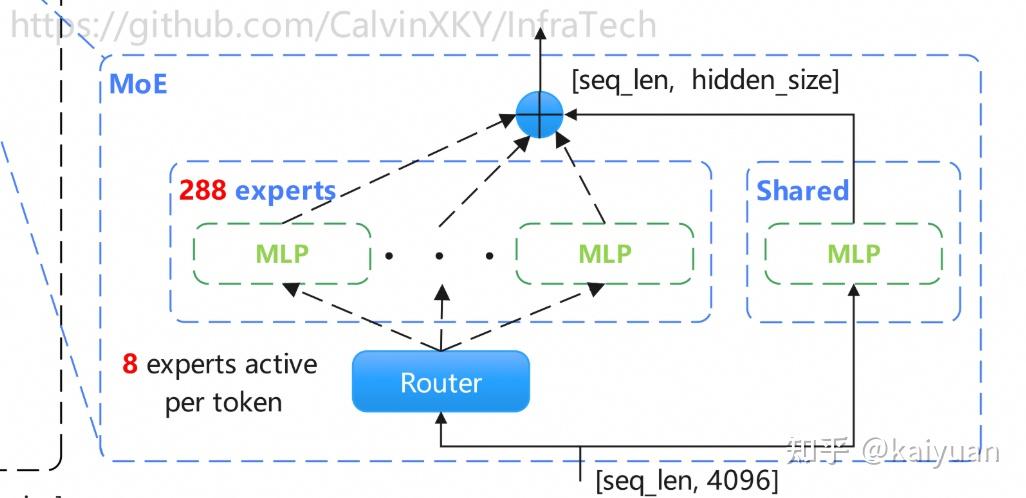
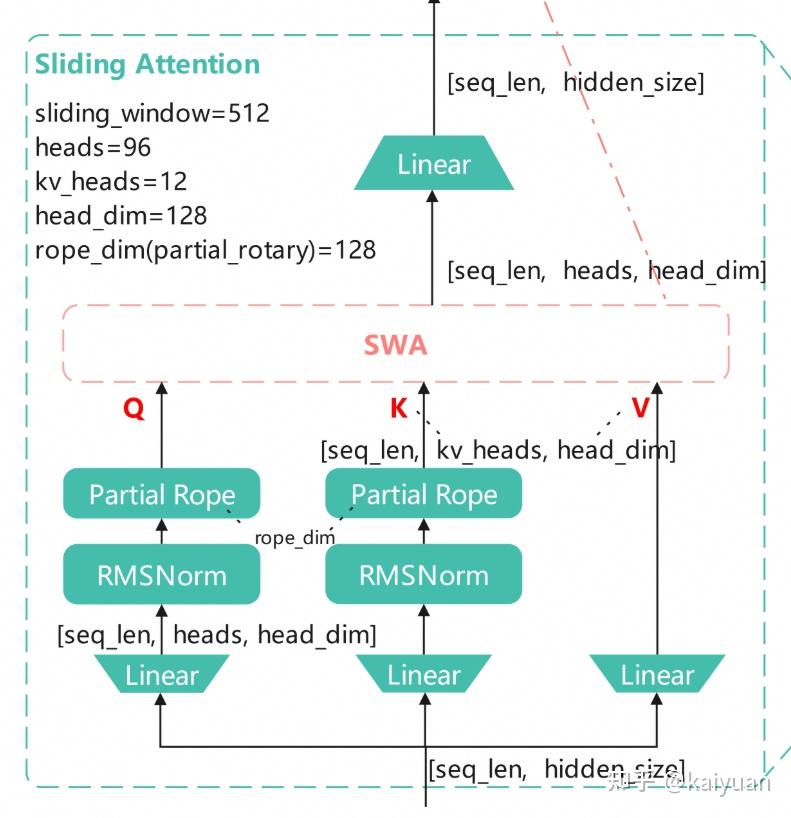
• Attention mix: GQA Sliding Window Attention (SWA) Full Attention
• Routing: 288 experts | Top-8 activation per token
• Context window: 256K (262144 max sequence length)
⚙️ Key Configs (config.json)
• Layers: 45 | Hidden dim: 4096 | Attention heads: 64
• Sliding window: 512 | Max sequence length: 256K
✨ Standout Features
• Sparse MoE Routing: 288 experts with Top-8 selection → cuts compute without losing capacity
• Dual Attention Mechanism: SWA for efficient local modeling (512-window) Full Attention for global context
• MTP Acceleration: Faster decoding for real-world interactive throughput
✅ Final Takeaway
Step 3.5 Flash proves that sparse MoE architectures can deliver enterprise-grade performance for long-context, high-throughput applications without proportional resource growth.
#AI #Engineering #Tech #LLM #Agent #StepFun
🔗 Full article(CN):zhuanlan.zhihu.com/p/2021161…
1
17
1,661

Mar 4
🔬 [BREAKTHROUGH] Most science VLMs chase scale—Innovator-VL shows what training design can do.
📑 #POTD | An 8B multimodal model for scientific discovery that stays competitive on both scientific and general vision benchmarks.
📍 We at @TheDPTechnology have been exploring how to make science VLMs stronger without leaning on giant, opaque training pipelines, and Innovator-VL is a compelling datapoint. @guolin_ke, Linfeng Zhang, et al. (SJTU, @TheDPTechnology, MemTensor & CAS) argue that disciplined data curation and a transparent training recipe can rival scale-heavy approaches.
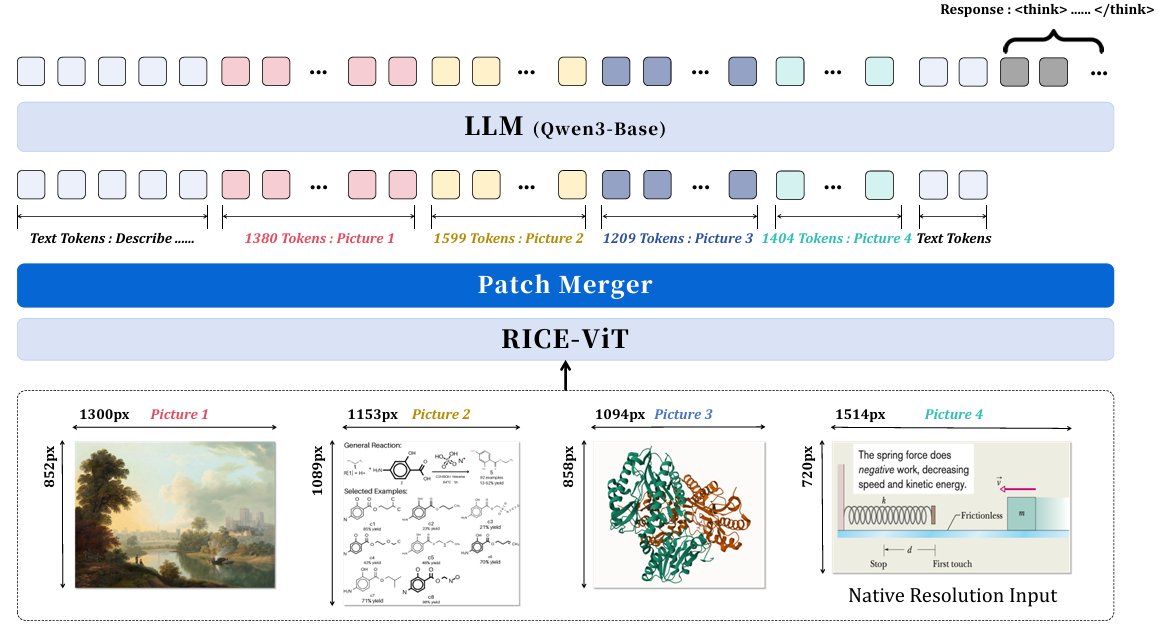
A core issue is detail loss when scientific images are resized too aggressively—hurting reasoning over formulas, molecular structures, and other dense visual evidence.
Their approach combines:
1️⃣ Native-resolution encoding with a vision transformer
2️⃣ Token compression via PatchMerger
3️⃣ Qwen3-8B for multimodal reasoning
4️⃣ RL-stage optimization for longer, more stable reasoning traces
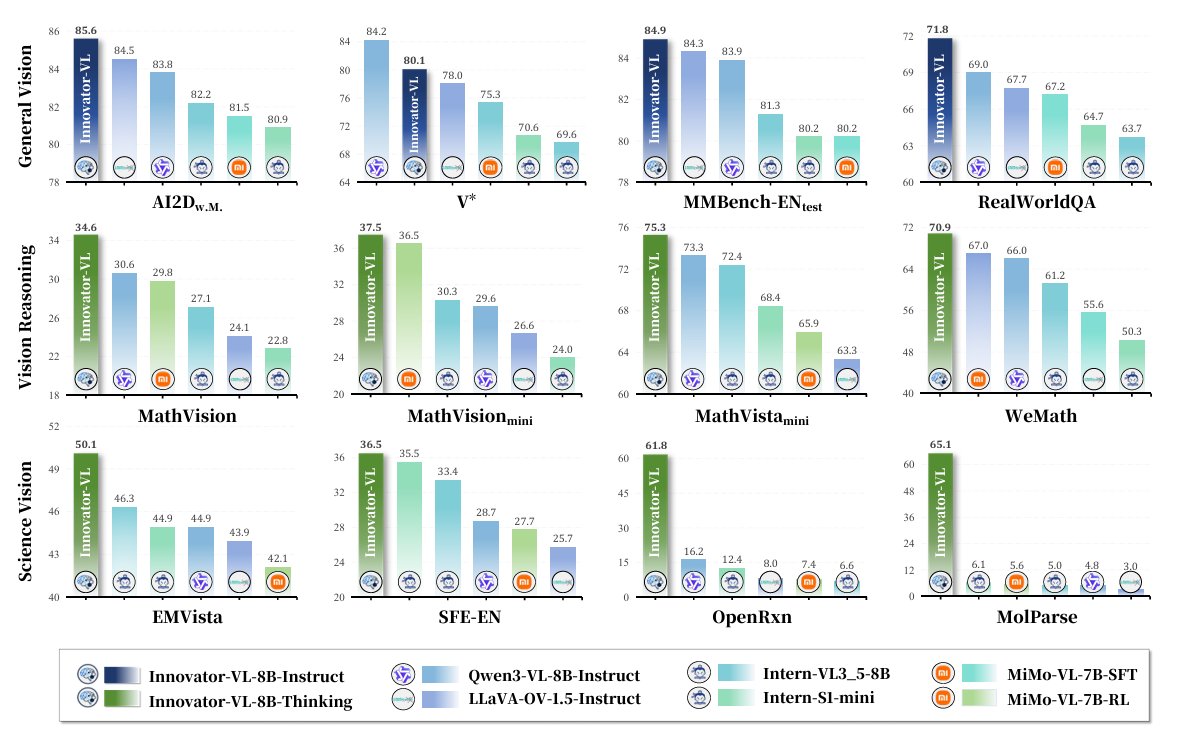
Reported results include AI2D 85.6, MMBench-EN 84.9, RealWorldQA 71.8, plus strong scientific-task performance such as OpenRxn 61.8.
More in comments!👇
#PaperOfTheDay #MultimodalLearning #AIforScience #VisionLanguageModel #ScientificDiscovery

2
2
8
234

NNsight 0.6 also introduces first-class support for VisionLanguageModel (e.g., LLaVA, Qwen-VL) and DiffusionModel (e.g., Stable Diffusion, Flux)! Available remote on NDIF soon 👀

1
5
154

'...for the query “marinating chicken”. The system returns short, timestamped clips from multiple biryani videos where the marination step is visually identified, enabling direct access to semantically relevant moments rather than full un-indexed videos.' #VisionLanguageModel VLM
2
60

10 Dec 2025
The open-sourced VLM thought it was an umbrella, but fine-tuning it on just 400 images created the outcome below.
Quantized and able to run on the edge, detecting threats in real-time.
Read more about it on Simuletic.com/VLM
#VLM #ComputerVision #Visionlanguagemodel
3
2
5
68

16 Oct 2025
🚨 PaddleOCR-VL: Baidu’s New OCR Model Redefining Document Understanding
Baidu has officially launched and open-sourced PaddleOCR-VL-0.9B, Baidu’s most advanced ERNIE-powered model to date.
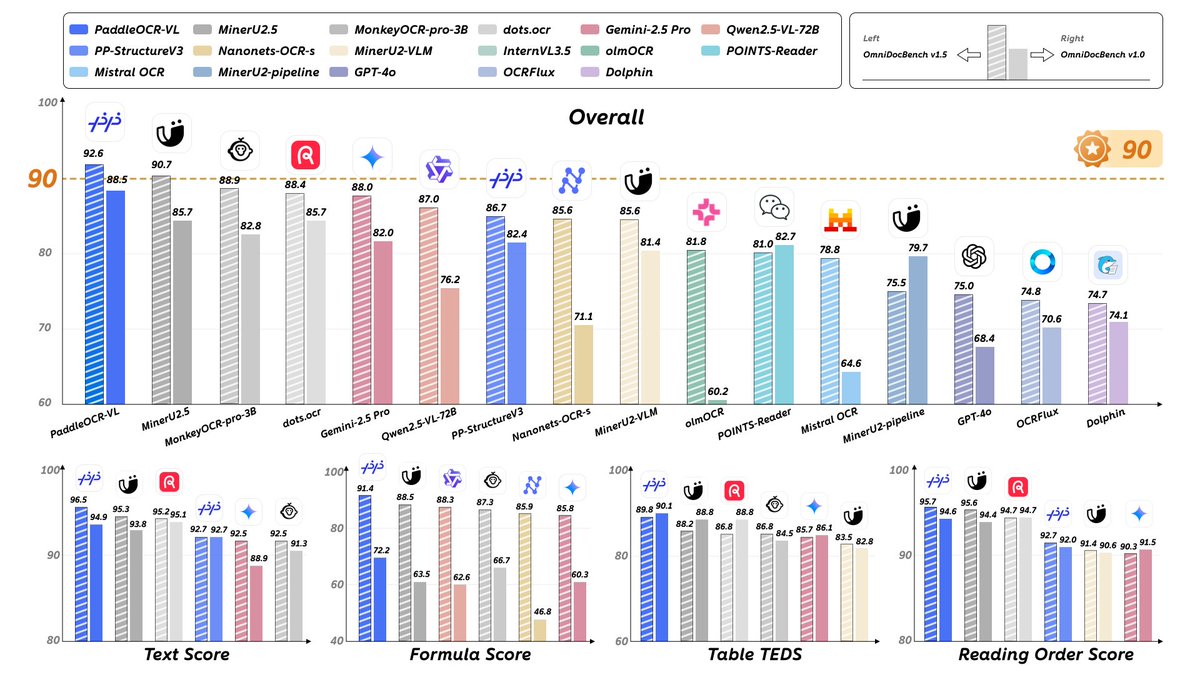
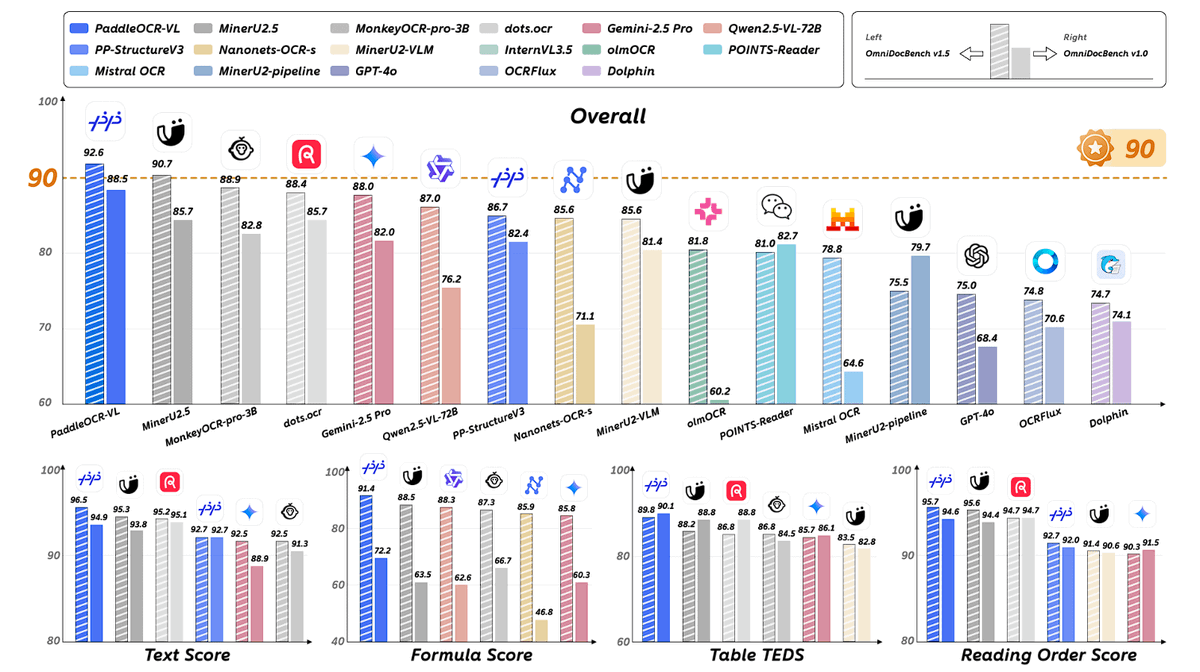
📊 Performance Highlights
• #1 globally on the OmniBenchDoc V1.5 leaderboard with a composite score of 90.67
• Outperforms large multimodal models such as GPT-4o, Gemini 2.5 Pro, and Qwen2.5-VL-72B
• Surpasses dedicated OCR systems including InternVL 1.5, MonkeyOCR-Pro-3B, and Dots.OCR
Built for the real world,PaddleOCR-VL handles the messiness of real-world documents with ease. It supports 109 languages and adapts seamlessly across formats — from scanned PDFs and academic papers to handwritten notes and forms.
We've got a true PDF Genius here.
Try the demo on Hugging Face 👇
🔗 huggingface.co/PaddlePaddle/…
#AI #ComputerVision #PaddleOCR #BaiduAI #VisionLanguageModel
24
4
38
33,451

16 Oct 2025
Baidu just took document AI to the next level. 🚀
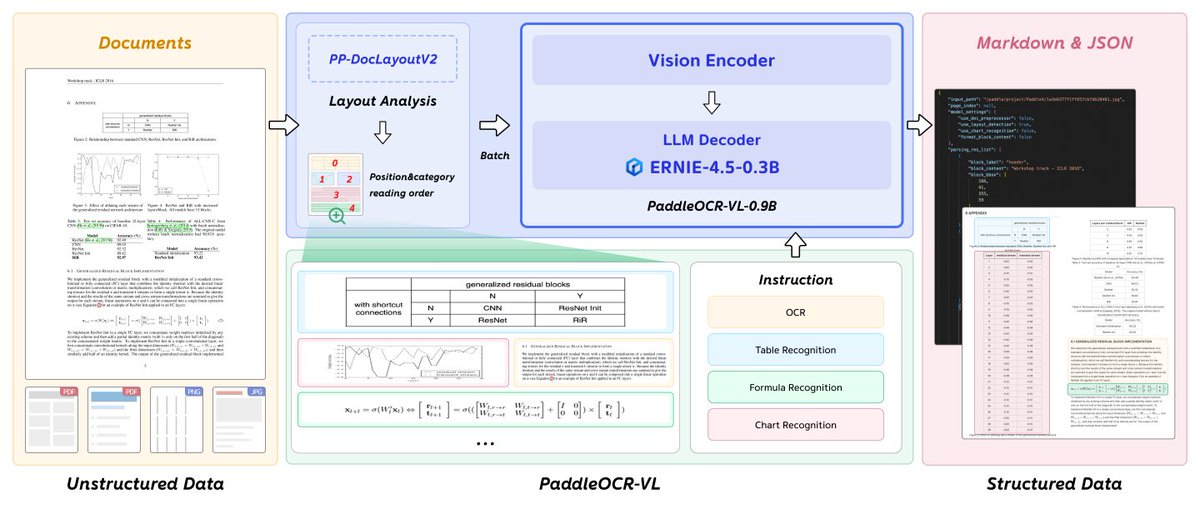
Their new PaddleOCR-VL-0.9B model might be built small, but it’s made for big things — powered by ERNIE-4.5-0.3B and designed to actually understand documents.
It recognizes structure, tables, formulas, and handwriting across 109 languages, rebuilding complex layouts with precision that feels almost human.
Think of it as the “PDF Genius” — cleaning up chaotic pages and turning them into neat, structured data.
It’s already ranked #1 worldwide the OmniBenchDoc V1.5 leaderboard.
This feels like a glimpse into the future of document AI — compact, efficient, and remarkably capable.
🔗 huggingface.co/PaddlePaddle/…
#AI #Baidu #PaddlePaddle #VisionLanguageModel #DocumentAI
10
2
32
36,411

7 Oct 2025
We’re also proud to introduce dLLM-RL (github.com/Gen-Verse/dLLM-RL), the first comprehensive reinforcement learning framework designed specifically for diffusion language models. Originally developed to power our TraDo series of models, dLLM-RL introduces TraceRL (arxiv.org/abs/2509.06949), a trajectory-aware RL method that significantly improves stability and performance in reasoning tasks.
🔍 Why our dLLM-RL (github.com/Gen-Verse/dLLM-RL) matters for multimodal AI:
1. Supports diffusion value models to reduce variance in RL training
2. Enables multi-step trajectory optimization, crucial for complex vision-language reasoning
3. Compatible with diverse dLLM architectures (block, full-attention, adapted)
4. Accelerated training & inference with KV caching, multi-node support, and efficient sampling
5. Ready for multimodal extensions — imagine applying TraceRL to optimize image captioning, visual QA, or multimodal planning!
With dLLM-RL, we’re not just speeding up generation — we’re building smarter, more capable multimodal agents through principled, scalable reinforcement learning.
#dLLM #DiffusionLLM #MultimodalAI #VisionLanguageModel #MMaDA #dLLMRL #TraceRL #A2D #RunwayResearch #ReinforcementLearning #UnifiedAI #OpenSource #GenerativeAI
5
386

26 Aug 2025
We are excited to be among the very first groups selected by @NVIDIARobotics to test the new @NVIDIA #Thor. We have managed to run a #VisionLanguageModel (Qwen 2.5 VL) for semantic understanding of the environment, along with a monocular depth model (#DepthAnything v2), for safe autonomous navigation, all onboard. No cloud, no internet connection required! The video shows a simple result obtained in just two weeks of work.
Kudos to Leonard Bauersfeld Jiaxu Xing Ismail Geles Yannick Armati for making this possible!
#ComputerVision #Robotics @UZH_en @UZHspacehub @uzh_ifi @ERC_Research
9
39
251
31,451

12 Jul 2025
🚀Project Number 3 - SpatialTracker V2🔥
'Pixel-to-3D Object Tracking with Triplane Neural Representations'
#HuggingFace #AIProjects #MachineLearning #VoiceCloning #ResumeTips #TravelPlanning #VisionLanguageModel #OpenSourceAI #SpatialTrackerV2
1
2
99

30 Jun 2025
New tutorial! 🎬✨
Generating Video Highlights Using the SmolVLM2 Model
🎞️ Turn long videos into punchy highlight reels—automatically!
pyimg.co/u6a02
Author: @cosmo3769
#VideoAI #SmolVLM2 #Gradio #VisionLanguageModel #HuggingFace #AItools #MultimodalAI #PyImageSearch

1
8
2,748

26 Jun 2025
Happy to share that DYTO has been accepted to #ICCV2025 as a new SOTA in video understanding!
Try it out in your experiments and see how it measures up!
Paper: arxiv.org/abs/2411.14401
Code: github.com/Jam1ezhang/DYTO
#MultimodalAI #MultimodalLLM #LargeLanguageModel #LLM #VisionLanguageModel #VLM #LVLM #LargeVisionLanguageModel #AIReasoning #ComputerVision #MachineLearning #DeepLearning #AIResearch #ICCV2025 #ICCV #CVPR
26 Nov 2024

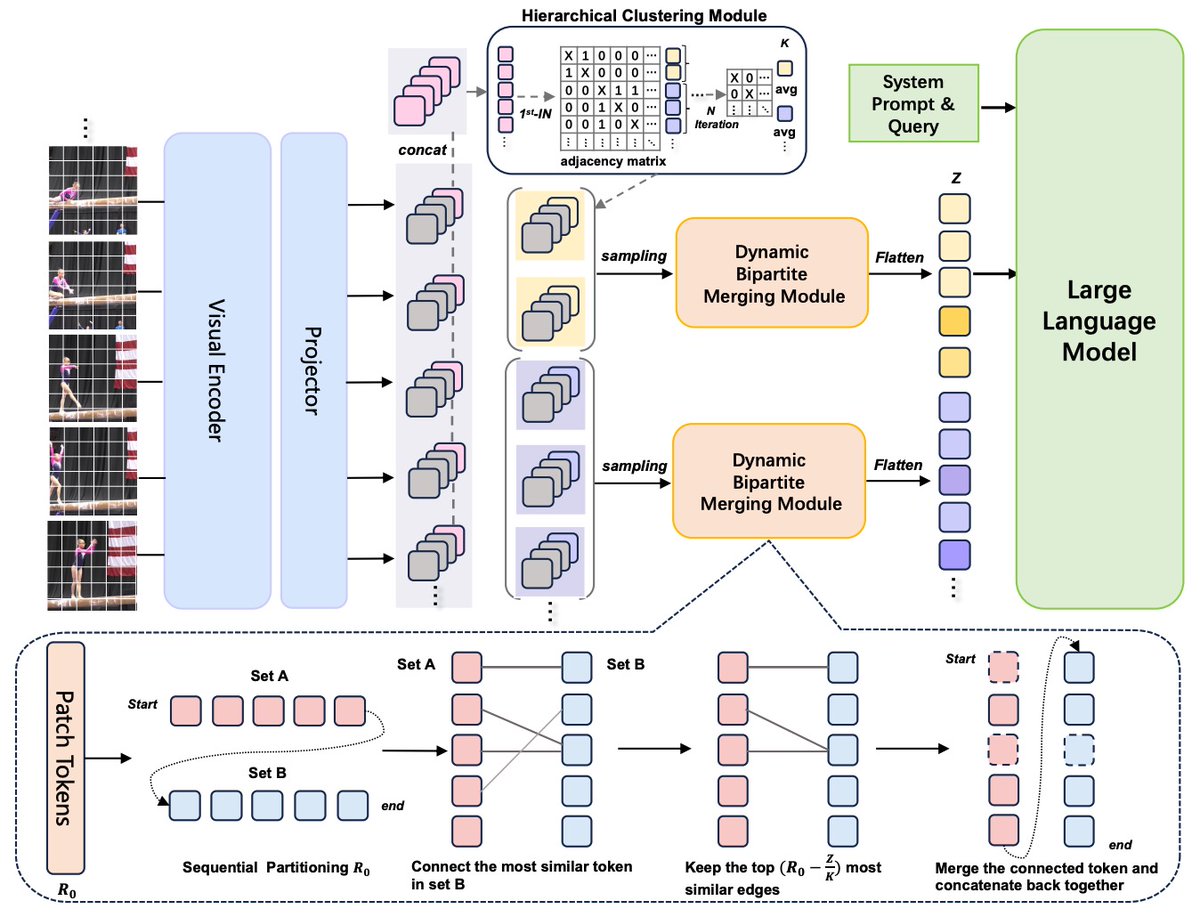
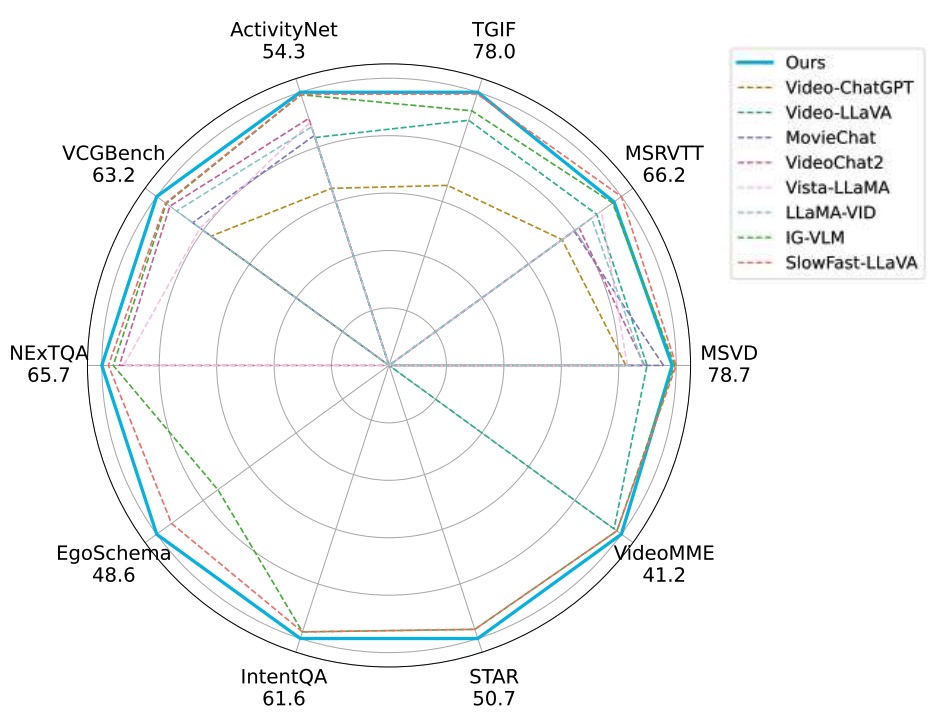
We've ( @Yiming1254115 @ZRChen_AISafety ) been wondering why so many existing video understanding approaches stick to uniformly sampling a fixed number of frames (e.g., 8) from an entire video sequence as input. So......
Introducing DYTO, a training-free framework that dynamically balances token efficiency and semantic richness. DYTO sets state-of-the-art performance across benchmarks with zero-shot adaptability. 🎥💡
Key Highlights:
🔹Hierarchical Frame Selection: Dynamically captures crucial events without rigid sampling.
🔹Bipartite Token Merging: Reduces token redundancy while preserving rich contextual details.
🔹Best-in-class Performance: Outperforms both fine-tuned & training-free methods.
Read more: arxiv.org/abs/2407.15841
#AI #ML #VideoUnderstanding #LLM #MLLM #LVLM #ZeroShot #MultiModal
1
12
475

18 Jun 2025
🎉New Course Launch: Free Vision Language Model(VLM) Bootcamp
After extensive research into AI's future trajectory, we at OpenCV are excited to introduce the VLM Bootcamp, a short, hands-on, and completely FREE course designed to keep you ahead of the curve. Learning VLMs is not only relevant today, but will remain in high demand for years to come.
Understanding VLMs is no longer optional for anyone serious about AI. It's the foundational knowledge you'll need for the next decade of innovation.
To help you get started, created a clear and comprehensive free course on Vision-Language Models (VLMs). No jargon, no hype, just the essential knowledge you need to understand what they are, how they work, and why they’re set to transform AI-powered automation.
🚀 Enroll now and take your first step into the future!
opencv.org/university/vision…
#VLM #VisionLanguageModel #AI #OpenCV #OpenCV_University

2
174
11 Jun 2025
My high-level take on why multimodal reasoning is fundamentally harder than text-only reasoning: Language is structured and directional, while images are inherently unstructured—you can start reasoning from anywhere. This visual freedom makes step-by-step logical inference much harder.
Building on this insight, we are excited to share our spotlight paper, Autonomous Multimodal Reasoning via Implicit Chain-of-Vision (ICoV), at #CVPR2025 Multimodal Algorithmic Reasoning Workshop. ICoV presents an experimental finetuning framework that guides large vision-language models on where to look and how to think, while maintaining the reasoning trace internally for efficient inference.
Check out the paper here:
openaccess.thecvf.com/conten…
#MultimodalAI #MultimodalLLM #LargeLanguageModel #LLM #VisionLanguageModel #VLM #LVLM #LargeVisionLanguageModel #AIReasoning #ComputerVision #MachineLearning #DeepLearning #AIResearch #CVPR25

3
8
29
3,021

23 May 2025
See how domain specialization transforms medical reasoning:
hubs.li/Q03nRpCk0
#MedicalAI #VisionLanguageModel #HealthcareAI #ClinicalDecisionSupport #GenerativeAI #RadiologyAI #LLM #NLPinHealthcare

1
1
2
369

🚨 The ASDP is excited to support the MICCAI 2025 Challenge: Report Generation in Pathology using Pan-Asia Giga-pixel WSIs! 🧠🧬
👉 Register here: reg2025.grand-challenge.org/
#ASDP #MICCAI2025 #REG2025 #DigitalPathology #VisionLanguageModel #MedicalAI

1
2
6
1,584

22 Apr 2025
Add Image Understanding to macOS App with SwiftUI
Code: patreon.com/posts/add-image-…
#SwiftUI #ChatGPTClone #VisionLanguageModel
3
36

10 Apr 2025
🚀 Exciting news about our CVPR 2025 work!
💡 We propose JarvisIR — a smart restoration system based on Vision-Language Models (VLM), dynamically scheduling multi-expert models with a two-stage training framework (SFT Human Feedback Alignment). It effortlessly handles real-world complex weather coupling degradation!
🎯 Real-scene perception metrics improved by an average of 50%. | Constructed the CleanBench dataset (over 230,000 instruction pairs). Join us and star this project if you're interested! 🌟
🌐 Project Page: cvpr2025-jarvisir.github.io/
🔗 GitHub Repository: github.com/LYL1015/JarvisIR
#CVPR2025 #VisionLanguageModel
1
1
6
500

2 Apr 2025
✅ Integrating Vision-Language Models into Agentic RAG Systems with ColPali
#AIPipeline #VisionLanguageModel #ColPali #MultimodalAI #CrewAI
ift.tt/aRMlSVt
2
75