
I just wrapped up an intensive project with WorldQuant University, where I built an end-to-end predictive pipeline to forecast air quality (PM2.5 levels) in Nairobi.
Unlike standard tabular datasets, time-series data requires an entirely different engineering and modeling mindset. Here is a breakdown of the technical milestones and core takeaways from this project:
1. The Data Pipeline (NoSQL to Pandas)
Before modeling, you have to ingest the data. I worked with semi-structured air quality metadata stored in a MongoDB database.
Connected via Python drivers to query specific collection metrics.
Processed and flattened nested JSON structures into a structured Pandas DataFrame.
Handled irregular sensor frequencies by resampling data into a fixed hourly index and addressing missing values to maintain continuity.
2. Feature Engineering Through "Lags"
In time-series, you often do not have external features. The past becomes your input. By shifting the timestamp index, I engineered "lag features" (using the prior hour's air quality to predict the next hour). This self-supervision transforms raw sequences into a supervised learning matrix.
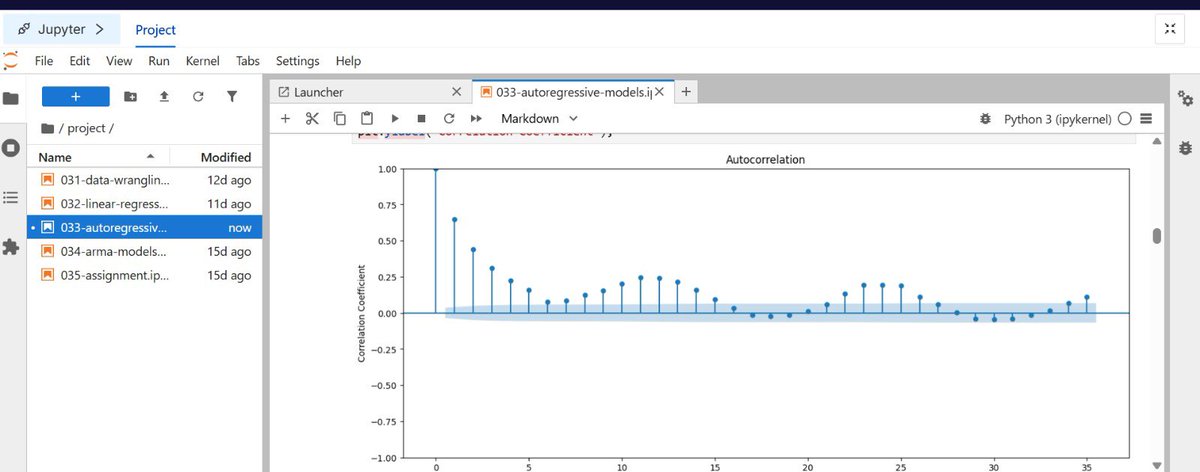
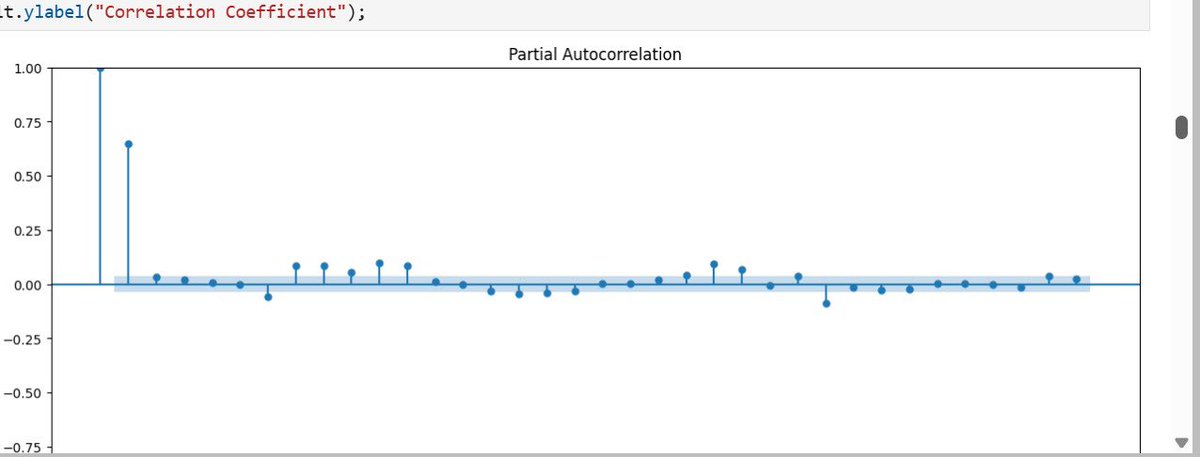
3. Deciphering the Math (ACF and PACF)
To determine how many historical lags our Autoregressive (AR) model actually needed, I utilized:
Autocorrelation Function (ACF): To measure the total correlation between current and past data points.
Partial Autocorrelation Function (PACF): To strip away the "noise" of intermediate steps and isolate the direct impact of a specific past hour on the present.
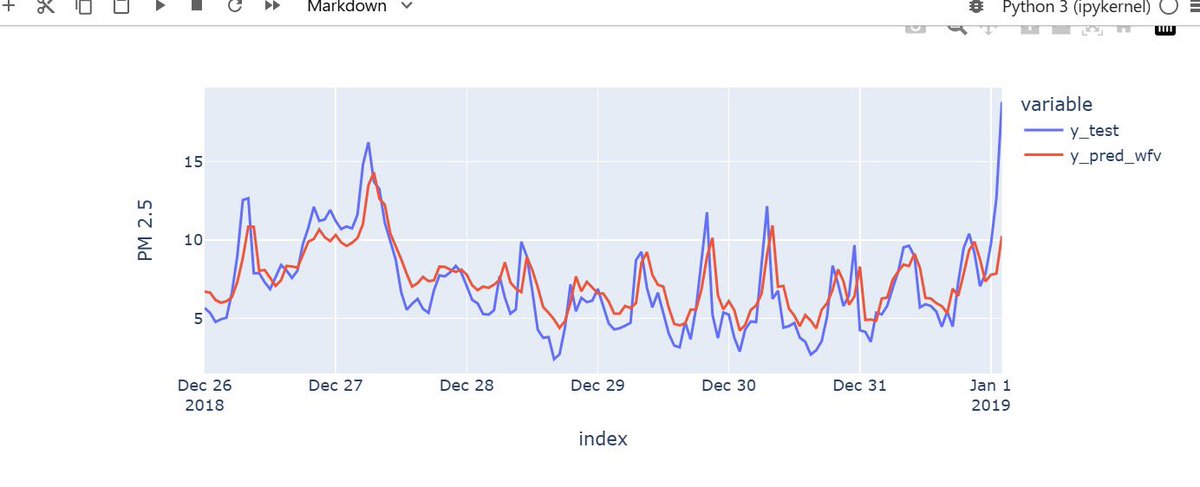
4. Why Traditional Validation Fails (Enter WFV)
One of my biggest takeaways was why we cannot use standard random train-test splits or K-Fold Cross-Validation for time-series. Doing so causes "data leakage" because a model cannot look into the future to predict the past.
Instead, I implemented Walk-Forward Validation (WFV). This mimics real-world deployment: the model predicts the next time step, tests against the actual result, folds that real result into its training history, and moves forward one step at a time.
Building this with statsmodels, pymongo, and scikit-learn has completely reshaped how I approach chronological data.

3
6
74

May 24
🚀 Python Libraries You Should Know 🐍🔥
📊 1. Data Analysis Libraries
✔ Pandas→ Data Cleaning & Analysis
✔ NumPy → Numerical Computing
✔ Polars→ Fast Data Processing
📈 2. Data Visualization Libraries
✔ Matplotlib → Basic Charts & Graphs
✔ Seaborn*→ Statistical Visualization
✔ Plotly → Interactive Dashboards
🤖 3. Machine Learning Libraries
✔ Scikit-learn → ML Algorithms
✔ XGBoost → Boosting Models
✔ LightGBM→ Fast ML Training
🧠 4. Deep Learning Libraries
✔ TensorFlow → AI & Neural Networks
✔PyTorch→ Research & Deep Learning
✔ Keras→ Simplified Deep Learning
🌐 5. Web Development Libraries
✔ Django→ Full Stack Web Apps
✔ Flask → Lightweight APIs
✔ FastAPI→ High-Speed APIs
⚡ 6. Automation & Scraping Libraries
✔ Beautiful Soup→ Web Scraping
✔ Selenium→ Browser Automation
✔ Requests → API Requests & HTTP Calls
💬 7. AI & NLP Libraries
✔ spaCy→ NLP Tasks
✔ Transformers→ Large Language Models
✔ NLTK→ Text Processing
📂 8. Database Libraries
✔ SQLAlchemy→ Database ORM
✔ PyMongo→ MongoDB Integration
✔ sqlite3 → Built-in SQL Database Support
💡 The right Python library can save hours of coding and make development much faster.
💬 Tap ❤️ if this helped you!
BOOKMARK THIS
#Pythonprogramming

8
17
100
2,144


Mar 21
For cloudsim-academy, the tech stack used includes:
- Frontend: React - Build tool: Vite - Routing: react-router-dom - Styling: plain CSS in /E:/codex/cloudsim-academy/src/index.css - Package manager: npm - Language: JavaScript JSX
For the backend it demos against, cloudsim uses:
- Backend framework: Flask - CLI: Python argparse-based CLI - Database layers: - SQLite for local per-VM storage - PostgreSQL via psycopg - MongoDB via pymongo - Packaging: setuptools / PyPI package - Runtime: Python 3.10
5
47

NumPy – 多次元配列・数値計算基盤
SciPy – 科学技術計算(最適化・積分)
SymPy – 記号計算
mpmath – 任意精度演算
statsmodels – 統計モデリング
numba – JIT高速化
Cython – C拡張化
dask – 分散並列計算
joblib – 並列処理
pint – 単位付き計算
pandas – データ解析
polars – 高速データフレーム
vaex – 大規模データ処理
openpyxl – Excel操作
xlrd – Excel読込
pyarrow – Arrow形式処理
modin – 並列pandas
tabulate – 表形式出力
csvkit – CSV操作
great_expectations – データ品質管理
matplotlib – グラフ描画
seaborn – 統計可視化
plotly – インタラクティブ可視化
bokeh – Web可視化
altair – 宣言的可視化
dash – Webダッシュボード
streamlit – データアプリUI
pyvista – 3D可視化
mayavi – 科学3D描画
graphviz – グラフ構造可視化
scikit-learn – 機械学習
xgboost – 勾配ブースティング
lightgbm – 高速GBDT
catboost – カテゴリ特化GBDT
imbalanced-learn – 不均衡データ対策
optuna – ハイパーパラメータ探索
mlflow – 実験管理
shap – モデル解釈
eli5 – モデル説明
river – オンライン学習
torch – 深層学習
torchvision – 画像DL
torchaudio – 音声DL
tensorflow – 深層学習
keras – 高レベルDL API
flax – JAX系DL
jax – 高速数値計算
accelerate – 分散学習支援
deepspeed – 大規模学習
timm – 画像モデル集
opencv-python – 画像処理
scikit-image – 画像解析
pillow – 画像操作
albumentations – データ拡張
imageio – 画像入出力
tifffile – TIFF処理
SimpleITK – 医用画像
nibabel – MRIデータ処理
pydicom – DICOM処理
mediapipe – 姿勢推定
nltk – 自然言語処理基礎
spacy – 高速NLP
gensim – トピックモデル
transformers – LLM・事前学習モデル
sentence-transformers – 文埋め込み
fugashi – 日本語形態素解析
sudachipy – 日本語解析
mecab-python3 – MeCabバインディング
fasttext – 単語ベクトル
textblob – 簡易NLP
flask – 軽量Web開発
django – フルスタックWeb
fastapi – 高速API開発
uvicorn – ASGIサーバ
gunicorn – WSGIサーバ
requests – HTTP通信
httpx – 非同期HTTP
aiohttp – 非同期Web通信
beautifulsoup4 – HTML解析
scrapy – クローリング
sqlalchemy – ORM
psycopg2 – PostgreSQL接続
pymysql – MySQL接続
redis – Redis接続
pymongo – MongoDB接続
click – CLI作成
argparse – CLI標準
typer – 型付きCLI
rich – 高機能ターミナル表示
loguru – ログ管理
pytest – テスト
coverage – テストカバレッジ
black – コード整形
isort – import整理
pydantic – データ検証
celery – 非同期ジョブ管理
airflow – ワークフロー管理
watchdog – ファイル監視
tqdm – 進捗表示
python-dotenv – 環境変数管理
雨後の筍…

3
8
1,409

Mar 1
Build powerful Python apps with MongoDB using PyMongo. Learn it now.
codewolfy.com/mastering-mong…
#mongodb #python #pymongo #codewolfy
2
10

Jan 5
pymongo
Insert documents, query JSON-like data, handle massive collections — perfect for scrapers, pipelines, and data collection systems.
#DataPipelines #PythonTools #AutomationLife #BuildInPublic #BackendFlow #TechCreator

ALT When systems flow, progress feels effortless.
1
3
39

Jan 4
today I noticed that some api calls on appstoretrends could take 30 secs 😒
so I have researched problems and implemented main fixes:
- removed manual mapping to json
- shifted from mongoengine to pymongo framework
- reduced number of proxies from 100 to 5, because before that downloading of proxies took a lot of cpu time and ram
so right now all api calls take 1-3 secs, so it's okay for now
1
4
62

22 Dec 2025
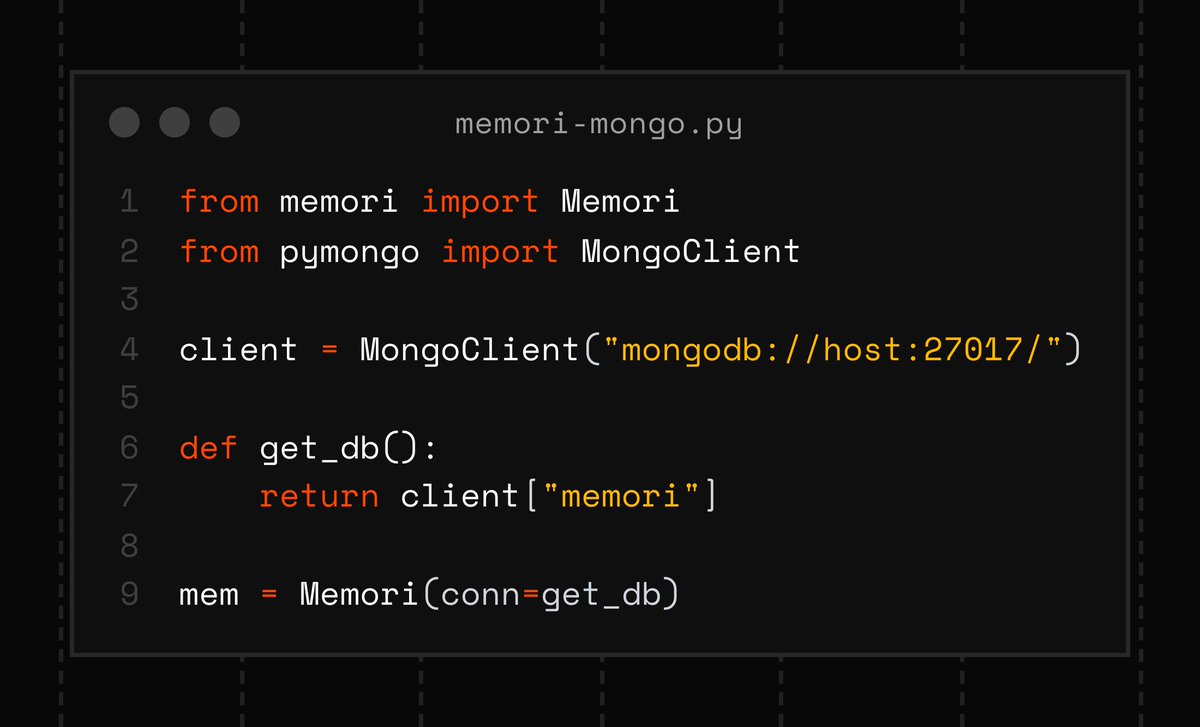
Memory doesn’t always have to be relational.
Memori supports @MongoDB via PyMongo:
- Pass a function that returns your DB
- No global state
- Flexible, document-style memory
Perfect for evolving user context 👇
4
3
16
1,340

19 Dec 2025
In my POV, the mongoengine is better than Pymongo
14 Dec 2025

Who else has tried Django MongoDB (either Mengine or PyMongo)?
Share yr testimony
3
83

18 Dec 2025
#Python from #GeeksforGeeks 🚀
⇨ Polymorphism
⇨ Data Abstraction
⇨ MySQL with Python
⇨ MongoDB with Python
⇨ Pymongo Cursor
⇨ Math Module
⇨ Random Module
⇨ DateTime Module
#365DaysOfCode #pythonprogramming #GeeksforGeeks #gfg #nationskillup #Winterarc #LearnInPublic

2
14
90
14 Dec 2025
Who else has tried Django MongoDB (either Mengine or PyMongo)?
Share yr testimony
4
173

We've partnered with @DataCamp on a FREE new course: "Introduction to MongoDB in Python."
Learn to connect Python apps with PyMongo and perform essential CRUD operations in just 3 hours.
No setup needed.
Start learning today 👉mongodb.social/60197Y3bU

1
8
24
4,971

Python’s ecosystem is vast, powering everything from data science to AI and automation.
Tools like Pandas, NumPy, Matplotlib, Seaborn, and SciPy drive analysis and visualization, while Keras, Lasagne, PyBrain support machine learning. For engineering, Airflow, Luigi, Dask excel, and databases rely on SQLAlchemy, PyMySQL, Pymongo. Mastering these tools expands possibilities.
📕 ebokify.com/python
#Python #DataScience #MachineLearning #AI #BigData #Analytics #Programming #Tech

1
2
37

Want a database that works with your data, not against it?
Learn MongoDB PyMongo in our newly updated course—created with @MongoDB.
📄 Query data
🔁 Run CRUD ops
📈 Validate structure
With #FreeAccessWeek, take the course for free until Nov 9!
👉 ow.ly/lqi050Xn13j
4
992

21 Oct 2025
hii everyone, i just published a helper guide on using Pymongo Async driver for your python projects.
in this article you'll learn:
- how to setup
- core operations
- aggregator cursor pattern
- connection mgmt
- prod config
- crud example
- migrating from Motor
@MongoDB @PyMongo

1
1
5
518

17 Oct 2025
Python Developer: From Basics to Case Studies Specialization.
Python Fundamentals & Core Concepts
├── Python Basics
│ ├── Syntax & Data Types
│ ├── Variables & Operators
│ ├── Control Structures
│ └── Functions & Scope
├── Data Structures
│ ├── Lists, Tuples, Sets, Dictionaries
│ ├── Comprehensions
│ ├── Collections Module
│ └── Memory Management
└── Object-Oriented Programming
├── Classes & Objects
├── Inheritance & Polymorphism
├── Encapsulation & Abstraction
├── Magic Methods
└── Design Patterns
Advanced Python Concepts
├── Functional Programming
│ ├── Lambda Functions
│ ├── Map, Filter, Reduce
│ ├── Decorators
│ └── Generators & Iterators
├── Error Handling & Debugging
│ ├── Exception Handling
│ ├── Logging
│ ├── Debugging Tools
│ └── Testing & Validation
└── Performance Optimization
├── Profiling Code
├── Memory Optimization
├── Concurrent Programming
├── Asynchronous Programming (async/await)
└── Cython & Just-In-Time Compilation
Web Development Frameworks
├── Django Ecosystem
│ ├── Django ORM & Models
│ ├── Views & Templates
│ ├── Django REST Framework
│ ├── Authentication & Authorization
│ └ Django Admin Customization
├── FastAPI & Modern APIs
│ ├── FastAPI Fundamentals
│ ├── Pydantic Models
│ ├── Automatic Documentation
│ ├── Dependency Injection
│ └── WebSocket Support
└── Flask & Microframeworks
├── Flask Applications
├── Jinja2 Templating
├── Flask-RESTful
├── Blueprints & Structure
└── Extensions Ecosystem
Data Science & Analytics
├── Data Manipulation
│ ├── Pandas Library
│ ├── NumPy Arrays
│ ├── Data Cleaning
│ └── Data Transformation
├── Data Visualization
│ ├── Matplotlib
│ ├── Seaborn
│ ├── Plotly
│ └── Bokeh
└── Statistical Analysis
├── SciPy
├── Statistical Testing
├── Hypothesis Testing
└── A/B Testing Implementation
Machine Learning & AI
├── Core ML Libraries
│ ├── Scikit-learn
│ ├── Model Training & Evaluation
│ ├── Feature Engineering
│ └── Hyperparameter Tuning
├── Deep Learning
│ ├── TensorFlow & Keras
│ ├── PyTorch
│ ├── Neural Networks
│ └── Computer Vision
└── Natural Language Processing
├── NLTK
├── spaCy
├── Transformers
├── Text Classification
└── Sentiment Analysis
Database Integration & ORM
├── SQL Databases
│ ├── PostgreSQL with Psycopg2
│ ├── MySQL with MySQL-connector
│ ├── SQLite Integration
│ └── Advanced Query Optimization
├── NoSQL Databases
│ ├── MongoDB with PyMongo
│ ├── Redis for Caching
│ ├── Elasticsearch Integration
│ └── Database Design Patterns
└── ORM & Query Building
├── SQLAlchemy Core & ORM
├── Alembic Migrations
├── Django ORM Advanced
├── Query Optimization
├── Connection Pooling
DevOps & Deployment
├── Containerization
│ ├── Docker & Docker Compose
│ ├── Container Best Practices
│ ├── Multi-stage Builds
│ └── Docker Security
├── Cloud Platforms
│ ├── AWS
│ ├── Google Cloud Platform
│ ├── Microsoft Azure
│ └── Heroku & Python-Friendly Hosting
└── CI/CD & Automation
Testing & Quality Assurance
├── Testing Frameworks
├── Testing Types
└── Quality Tools
Real-World Case Studies
├── E-commerce Platform
├── Data Analytics Dashboard
├── Machine Learning API
└── Microservices Architecture
Career Development & Best Practices
├── Code Quality
├── Project Structure
└── Industry Best Practices
🐍 Become a Job-Ready Python Developer
Start your journey to Python mastery with our complete eBook: codewithdhanian.gumroad.com/…

9
126
732
40,137

10 Sep 2025
Get started with Azure Cosmos DB for MongoDB using Python in minutes.
Follow the quickstart to provision a cluster, use Python libraries, and store/query documents—all with azd and pymongo.
Learn more: msft.it/6017s9dPP
#AzureCosmosDB #Python #MongoDB

ALT Quickstart: Use Azure Cosmos DB for MongoDB (RU) with Python
1
2
440

18 Aug 2025
Hey just made a simple Auth system using pymongo, streamlit, argon2id learn from Chai code Pls pls review and rate Pls I use latest argon2id saksham801-lms-authenction-t…
2
100