
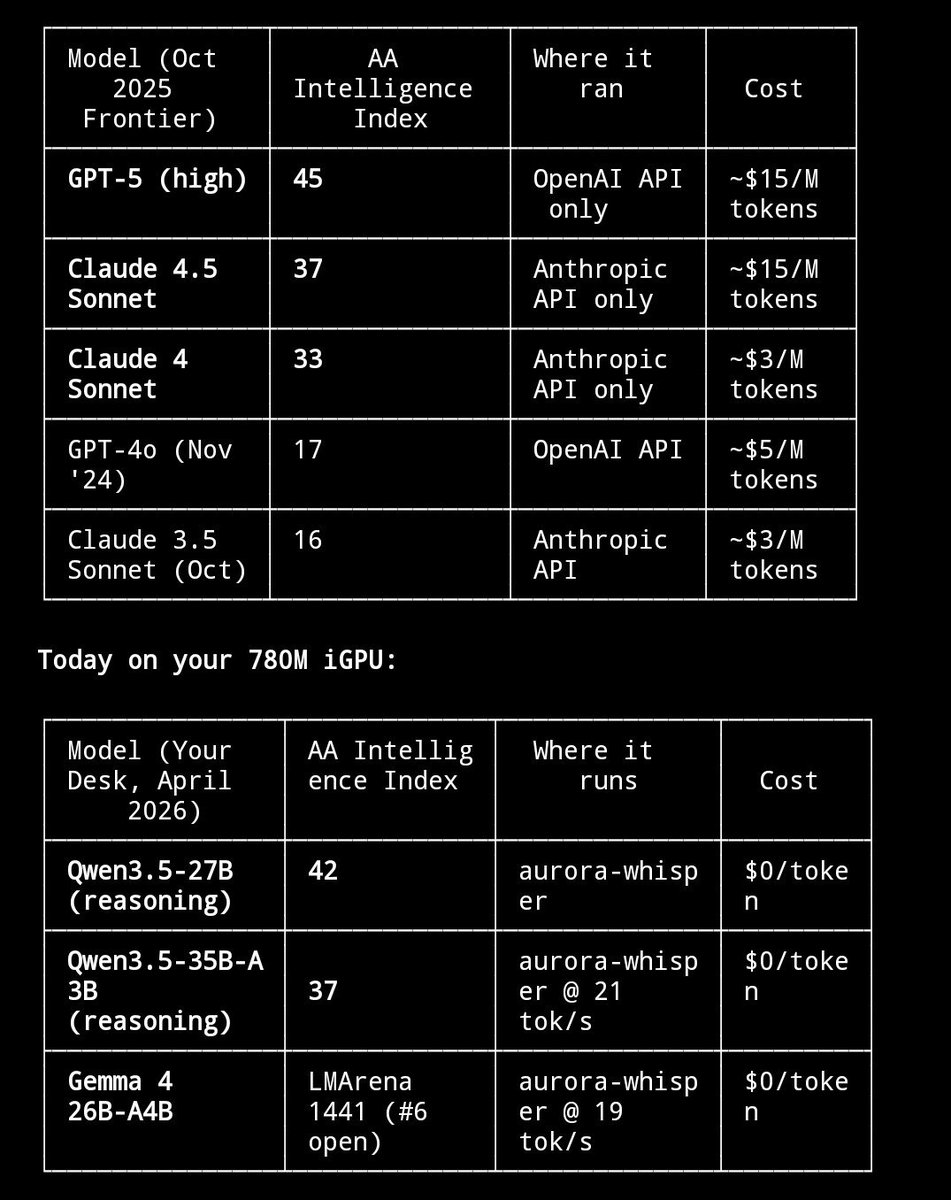
$300 mini PC running 26B parameter AI models at 20 tok/s.
Minisforum UM790 Pro ($351) AMD Radeon 780M iGPU 48GB DDR5-5600 1TB NVMe.
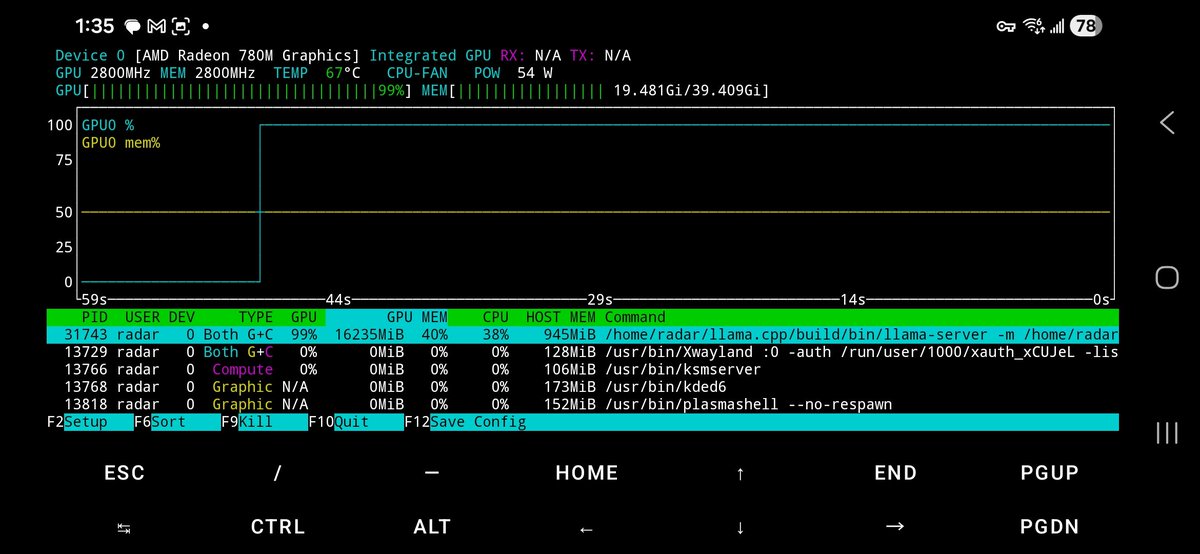
The secret: the 780M has no dedicated VRAM. It shares your DDR5 via unified memory. The BIOS says "4GB VRAM" but Vulkan sees the full pool.
I'm allocating 21 GB for model weights on a GPU with "4GB VRAM." The iGPU reads weights directly from system RAM at DDR5 bandwidth (~75 GB/s). MoE only activates 4B params per token = 2-4 GB of reads. That's why 20 tok/s works.
What it runs:
- Gemma 4 26B MoE: 19.5 tok/s, 110 tok/s prefill, 196K context
- Gemma 4 E4B: 21.7 tok/s faster than some RTX setups
- Qwen3.5-35B-A3B: 20.8 tok/s
- Nemotron Cascade 2: 24.8 tok/s
Dense 31B? 4 tok/s, reads all 18GB per token, bandwidth wall. MoE same quality? 20 tok/s.
Full agentic workflows via @NousResearch Hermes agent with terminal, file ops, web, 40 tools, all against local models. No API keys. Just a box on your desk.
The RAM is the pain right now. DDR5 prices 3-4x what they were a year ago. But the compute is free forever after you buy it.
@Hi_MINISFORUM
@ggerganov llama.cpp Vulkan @UnslothAI GGUFs @AMDRadeon RDNA 3. Fits in your hand.
#LocalLLM #Gemma4 #llama_cpp #AMD #Radeon780M #MoE #LocalAI #AI #OpenSource #GGUF #HermesAgent #NousResearch #DDR5 #MiniPC #EdgeAI #UnifiedMemory #Vulkan #iGPU #RunItLocal #AIonDevice

158
323
3,385
421,691

10 May 2021
In search of your next running shoe? Fan of tacos and margaritas? You’re in luck! With the purchase of a pair of @saucony shoes, you earn a $20 gift card to @localcantina
Learn more at Columbusrunning.com/saucony.
#runbigshopsmall #columbusrunning #runitlocal

2