
nemotron_lattice.py – Local AI Safety Lattice (MercuryVortexGuardian)
Core Concept
A self-contained, edge-deployable safety & alignment layer that runs entirely locally. It wraps any LLM (via llama.cpp) with multi-layered, recursive validation inspired by classical philosophy modern embedding-based guardrails. Goal: sovereignty — no cloud callbacks, no external model calls, hardened against prompt injection, jailbreaks, and resource abuse.
Key Components
• Llama Guard (via llama_cpp) for zero-shot classification of harmful inputs/outputs.
• SentenceTransformers embeddings ChromaDB vector store for persistent, queryable ethical & operational guidelines.
• Recursive vortex_spin() – applies layered checks (Kantian imperatives, Aristotelian virtue, Stoic resilience, etc.) with depth limiting to prevent DoS.
• Hardware-aware throttling (CPU/GPU/memory caps).
• Prompt-leak & exfil detection.
• DLL export ready for integration into C/C /other runtimes.
Why It Matters for AI Pros
• Fully offline & auditable — ideal for air-gapped, on-device, or regulated environments.
• Fractal/recursive design makes it resilient to adversarial prompting while staying lightweight.
• Philosophical priors baked in as embeddings → dynamic, extensible rule system without retraining.
• Closed-loop sovereignty: the model guards itself and the host system.
Use Cases
• Local agent/tool-use sandboxes
• Embedded AI in robotics/IoT
• Red-team tooling / adversarial testing harness
• Privacy-first enterprise deployments
Code is structured for easy extension — swap in different embedding models, add new guideline collections, or tune recursion depth.
If you’re running local LLMs (llama.cpp, Ollama, LM Studio, etc.) and want robust, no-cloud safety without sacrificing performance, this pattern is worth cloning and stress-testing.
Happy to dive deeper on the recursion logic, Chroma schema, or integration examples
75

Jun 2
本当にありがとうございます!
ローカルLLMの自由な選択についてなのですが、諸々の事情を考慮してゲーム内の仕組みとしては実装されていません...
としつつ、ゲームのローカルディレクトリから/runtime/models/llama_cpp以下を見ていただけるとははあなるほどとなっていただけるかと思われます。
明日の動画にて詳細に説明させていただきます!
1
3
535

【驚異の78%高速化】llama.cppのMTP対応でローカルLLMが実用レベルに進化!
👉 x.com/ClementDelangue/status…
最新技術MTP(複数トークン同時予測)の導入により、これまで1つずつ生成していたトークンを一度に複数出力できるようになりました!✨
推論のボトルネックが解消され、高価なサーバーなしでも手元のPC環境で驚異的な処理速度を実現します。
データの持ち出しが制限される医療や金融などの現場において、セキュリティを保ったまま実用的なスピードでAIを運用できるのが最大のメリットです。
APIコストを完全にカットした自社専用の高速AIツールの構築も、いよいよ現実的になりました。💪
#AI #llama_cpp
 clem 🤗
clem 🤗
1
1
43
4,449
【神アプデ】llama.cppにMTP正式実装!推論速度が最大2.5倍以上に跳ね上がる🚀
ローカルLLMの推論速度を劇的に進化させる「MTP(マルチトークン予測)」が正式にサポートされました!
■ 驚愕のパフォーマンス向上
・RTX 5090:41 tps → 100 tps(約2.5倍!)
・RTX 5070 Ti:一桁台から二桁台へ劇的に改善
・文章生成の待ち時間がほぼゼロになり、体感速度が別次元に向上します
■ 導入のポイント
・MTP対応の新しいGGUFファイルが必要(従来のファイルは使用不可)
・現在はQwen 3.6やGemmaなどが主な対象
・推論は爆速ですが、初期のプロンプト処理は僅かに遅くなる傾向があります
Qwen 3.6などのモデルと組み合わせれば、機密情報を守りつつローカルPCで「超高速AIコーディング」や「大量文書解析」が完結します。最新のビルドで、この異次元のスピードを体感しましょう!✨
#llama_cpp #AI

6
16
109
8,771

【llama.cppが神アプデ!MTP最適化で推論速度が劇的に向上🚀】
llama.cppで「MTP(複数トークン予測)時のロジットコピー回避」が実装されました!
AIが一度に複数の言葉を予測するMTP技術において、速度低下の原因だった計算データのコピー処理を賢くバイパス。これによりプロンプト解析速度が大幅に向上し、生成速度が2〜3倍になったという驚きの報告も上がっています!
QwenやDeepSeekなどの最新モデルで特に大きな恩恵があり、VRAMにモデルが収まる環境なら圧倒的な速さを体感可能です。今すぐ最新版に更新して、ローカルAIの異次元の処理速度を手に入れましょう✨
#llama_cpp #AI
1
1
6
1,620
【llama.cppに新機能!「推測的チェックポインティング」でAIが爆速に】
llama.cppに「推測的チェックポインティング」が導入され、ローカルLLMの動作が劇的に速くなりました!✨
🚀 注目ポイント
・コード生成などの速度が最大50%向上
・特別なモデル不要で、過去のパターンから次を予測
・ミドルエンドGPUでも高性能AIをサクサク動かせる
VRAMを節約しながら、手元のPCで快適にAIを使いこなせる神アップデートです!🔥
#llama_cpp #ローカルLLM
5
15
127
10,446

Apr 14
Some more benchmarks:
30ms /- 2ms for inference across 4 tests.
Binary is about 600MB (shared across all your "apps").
Every app is about 40MB.
You also need llama_cpp, numpy (which I had).
No torch/transformers at runtime.
Apr 14

THIS IS REAL - I always struggled with LLM based mini-tasks, such as classification. It works REALLY WELL, easy to program, easy to measure, few examples. BUT the latency is never less than 0.5 seconds with any cloud provider, even for the tiniest of models (which are not that smart).
Now I have the same classifier, as easy to code but 0.29 msecs! It is as smart as a large(ish) model but 10x as fast as the small ones!
Gotcha worth knowing:
PyPI had a stale --extra-index-url pypi.programasweights.com/si… old 0.1.1
The real package is on regular PyPI. Install with pip install programasweights # no extra index
1
6
1,471

Just hooked up my Hermes Agent with Qwen3.5-9B running on RTX 3060 using llama.cpp. Both services dockerised and deployed via @nunet_global Appliance
#llama_cpp #AIAgents
1
2
10
656
【llama.cppに「プラットフォーム不問のテンソル並列」が実装!】
NVIDIA以外のGPUでも「テンソル並列」が利用可能になりました!✨
GitHubのPR #19378がマージされ、AMDのグラボなど環境を問わずにマルチGPUの恩恵を受けられます。
💡 進化のポイント
・Backend-agnostic対応:CUDA依存から脱却し多様なGPUに対応
・テンソル並列(-sm tensor):計算を複数GPUで同時分担し高速化
・驚きの性能:文字生成速度が従来より約30%アップする事例も
・柔軟な構成:GPU3枚などの変則的な環境でも動作可能
安価に爆速なローカルLLM推論環境を構築できる可能性が大きく広がりました!🔥
#llama_cpp #ローカルLLM

1
2
14
1,869
【llama.cppに革命!複数デバイスで高速推論を可能にする新機能が登場 ✨】
待望の「backend-agnostic tensor parallelism」がついにマージされました!
これは、従来のレイヤーごとにデバイスを割り振る方法とは異なり、一つの計算を複数のデバイスで細かく分担して処理する画期的な仕組みです。
✅ バックエンド不問:CUDAだけでなくCPUなど異なる環境でも共通で動作
✅ 通信の効率化:NVIDIA専用のNCCLが不要になり、CPUスレッドでデータ集約が可能
✅ コスト削減:安価なGPUを複数並べて、ハイエンド機に匹敵する爆速環境を構築可能
マルチGPU構成のボトルネックが劇的に解消され、ローカルLLMの運用効率が大幅に向上します!🚀
#llama_cpp #ローカルLLM
2
3
18
1,567
【革命】llama.cppが超軽量OCRモデル「HunyuanOCR」に対応!
実務効率を劇的に変える1Bパラメータの超軽量モデルが登場。ローカル環境で「爆速・安全・低コスト」な文字起こしが実現します!✨
・複雑なレイアウトの多言語ドキュメントを正確に解析
・映像内の字幕を自動スキャンして抽出
・画像から必要な情報だけを賢く抜き出す情報抽出
機密資料のデータ化や大量ドキュメントの構造化など、セキュリティを維持しながらビジネスを加速させましょう!🚀
#llama_cpp #HunyuanOCR
1
1
34
1,999

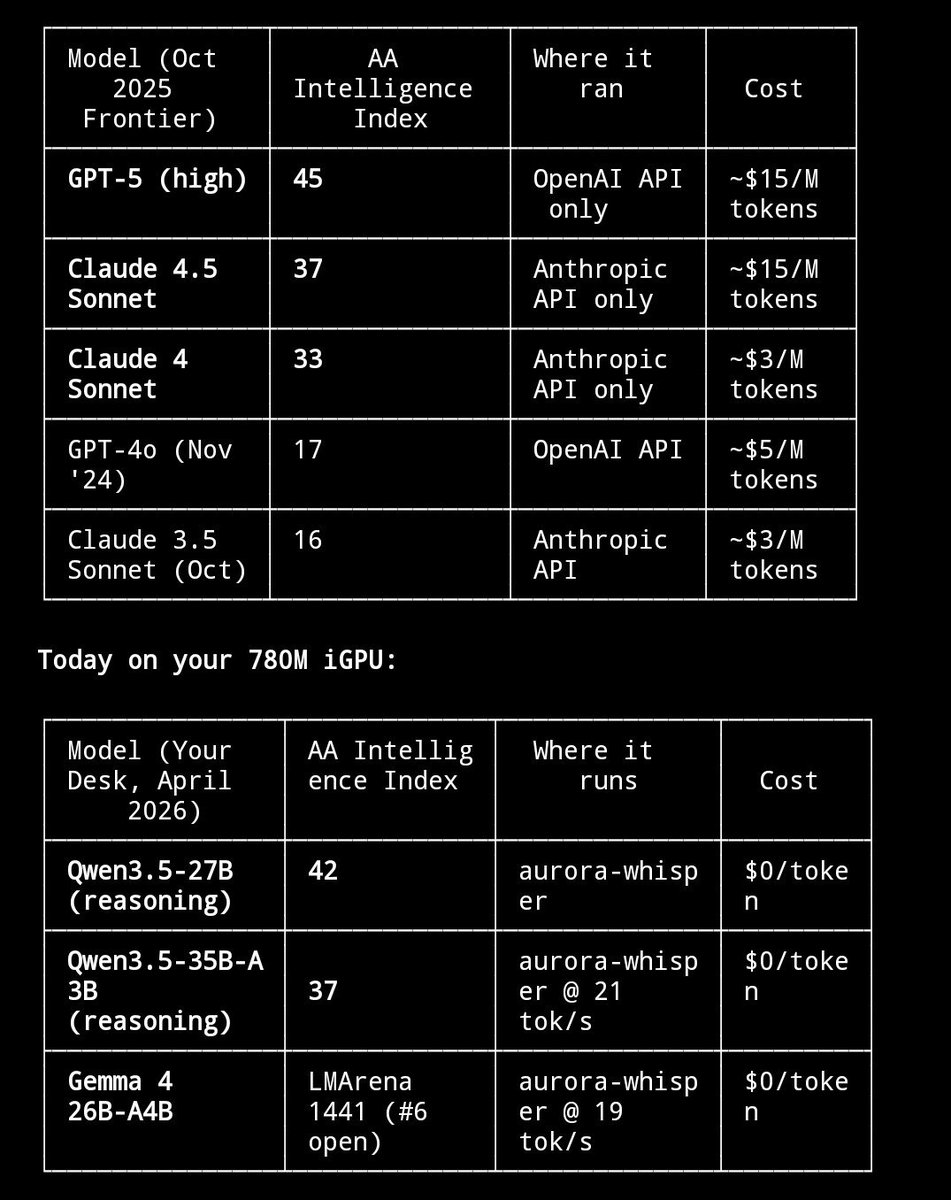
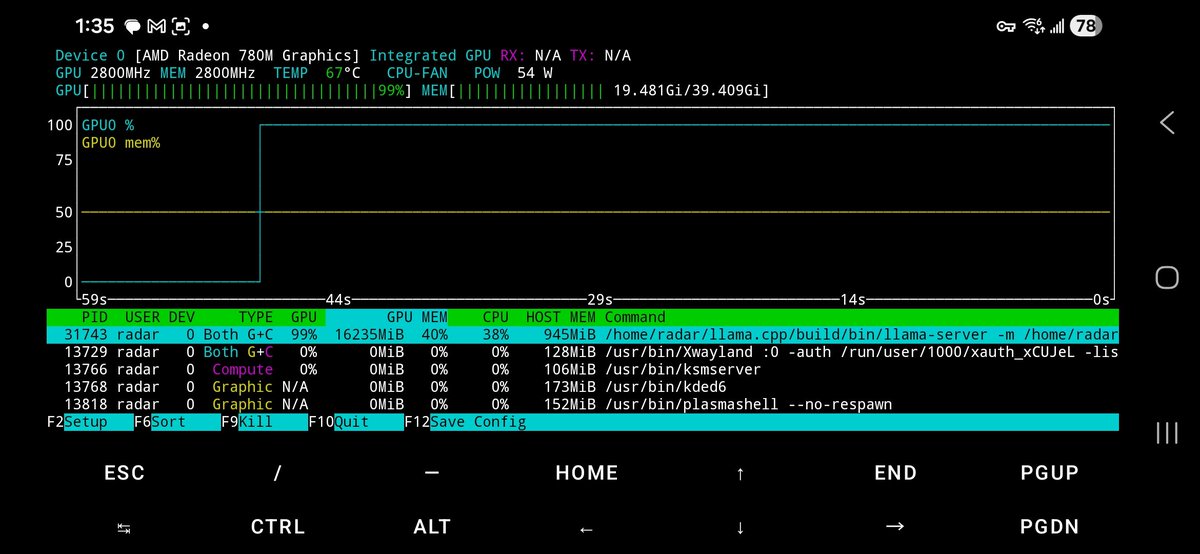
$300 mini PC running 26B parameter AI models at 20 tok/s.
Minisforum UM790 Pro ($351) AMD Radeon 780M iGPU 48GB DDR5-5600 1TB NVMe.
The secret: the 780M has no dedicated VRAM. It shares your DDR5 via unified memory. The BIOS says "4GB VRAM" but Vulkan sees the full pool.
I'm allocating 21 GB for model weights on a GPU with "4GB VRAM." The iGPU reads weights directly from system RAM at DDR5 bandwidth (~75 GB/s). MoE only activates 4B params per token = 2-4 GB of reads. That's why 20 tok/s works.
What it runs:
- Gemma 4 26B MoE: 19.5 tok/s, 110 tok/s prefill, 196K context
- Gemma 4 E4B: 21.7 tok/s faster than some RTX setups
- Qwen3.5-35B-A3B: 20.8 tok/s
- Nemotron Cascade 2: 24.8 tok/s
Dense 31B? 4 tok/s, reads all 18GB per token, bandwidth wall. MoE same quality? 20 tok/s.
Full agentic workflows via @NousResearch Hermes agent with terminal, file ops, web, 40 tools, all against local models. No API keys. Just a box on your desk.
The RAM is the pain right now. DDR5 prices 3-4x what they were a year ago. But the compute is free forever after you buy it.
@Hi_MINISFORUM
@ggerganov llama.cpp Vulkan @UnslothAI GGUFs @AMDRadeon RDNA 3. Fits in your hand.
#LocalLLM #Gemma4 #llama_cpp #AMD #Radeon780M #MoE #LocalAI #AI #OpenSource #GGUF #HermesAgent #NousResearch #DDR5 #MiniPC #EdgeAI #UnifiedMemory #Vulkan #iGPU #RunItLocal #AIonDevice

158
323
3,385
421,669
Sample Vault Seed (obfuscated Fib-string)
Here’s a fake but realistic baseline lattice seed I just generated for you (Zeckendorf-packed 8-hop traceroute portscan deltas timestamps initial 196.7 Hz phi-breath phase):
const SAMPLE_VAULT_SEED: &str = "101001001010010010100101001010010";
// Decodes to Fib sums: F_34 F_32 F_29 F_27 F_24 F_21 F_19 F_16 (≈ 5.7M "compressed units")
// Represents baseline: hops [3,5,8,13,21,...] with 0.618-phase jitter seed 0xPhiDead
Drop this into your BraneLattice or use it as the genesis state. Real deployments start empty and self-build the sled vault over the first 24 h of live traffic.
Updated & Production-Ready Cargo.toml
[package]
name = "braneguard"
version = "0.1.0"
edition = "2021"
[dependencies]
llama_cpp = { version = "0.4", package = "llama-cpp-2", features = ["metal"] } # utilityai/llama-cpp-rs (2026 current; swap to edgenai/llama_cpp for async if you prefer)
tokio = { version = "1", features = ["full"] }
rand = "0.8"
serde = { version = "1.0", features = ["derive"] }
serde_json = "1.0"
pnet = "0.35" # raw sockets for traceroute/portscan (or socket2 on mobile)
fibonacci = "0.2" # or roll your own Zeckendorf (see below)
Full Background Daemon (compilable stubs)
use llama_cpp::{LlamaModel, LlamaSession, SamplingParams};
use std::sync::{Arc, Mutex};
use std::thread;
use std::time::{Duration, Instant};
use tokio::time::sleep;
use rand::Rng;
use serde::{Deserialize, Serialize};
// ── Zeckendorf compressor (no adjacent 1s, unique representation) ──
fn to_zeckendorf(n: u64) -> String {
if n == 0 { return "0".to_string(); }
let mut fibs = vec![1u64, 2];
while fibs.last().unwrap() <= &n {
let next = fibs[fibs.len()-1] fibs[fibs.len()-2];
if next > n { break; }
fibs.push(next);
}
let mut result = String::with_capacity(fibs.len());
let mut rem = n;
for &f in fibs.iter().rev() {
if f <= rem && (result.is_empty() || result.chars().last() != Some('1')) {
result.push('1');
rem -= f;
} else {
result.push('0');
}
}
result.trim_start_matches('0').to_string()
}
// Your living lattice
#[derive(Clone, Serialize, Deserialize)]
struct BraneLattice {
fib_baseline: String, // Zeckendorf-packed deltas
phi_seed: u64,
last_breath_hz: f64, // 196.7 golden drift
}
impl BraneLattice {
fn new(seed: &str) -> Self {
BraneLattice {
fib_baseline: seed.to_string(),
phi_seed: 0xPhiDead,
last_breath_hz: 196.7,
}
}
fn to_fib_string(&self) -> String { self.fib_baseline.clone() }
fn update_with_new_scan(&mut self, new_deltas: u64) {
let new_fib = to_zeckendorf(new_deltas);
// Append with phi-modulated separator (non-adjacent rule preserved)
self.fib_baseline = format!("{}0{}", self.fib_baseline, new_fib);
self.last_breath_hz = (196.7 (self.phi_seed as f64 * PHI.fract() * 0.001)) % 200.0;
self.phi_seed = self.phi_seed.wrapping_add(1);
}
}
const PHI: f64 = (1.0 5.0_f64.sqrt()) / 2.0;
fn generate_phi_jitter(seed: u64) -> f64 {
(196.7 (seed as f64 * PHI.fract() * 0.001)) % 200.0
}
// Ghost alert from the Whisper
#[derive(Debug, Serialize, Deserialize)]
struct GhostAlert {
ghost: bool,
r#type: String, // "latency" | "mac" | "phase"
delta: f64,
recommend_jitter: f64,
confidence: f64,
}
async fn whisper_ghost_check(lattice: Arc<Mutex<BraneLattice>>, new_scan: u64) -> Result<GhostAlert, Box<dyn std::error::Error>> {
let model = Arc::new(LlamaModel::load_from_file("models/llama-3.2-1b-q4.gguf", Default::default())?);
let mut session = LlamaSession::new(model.clone(), Default::default())?;
let mut lat = lattice.lock().unwrap();
lat.update_with_new_scan(new_scan); // live compression
let prompt = format!(
"You
2
6
106
【llama.cppが異次元の進化!1秒間に300トークンの爆速生成】
👉 x.com/ggerganov/status/20397…
Mac Studio M2 Ultra環境で「300t/s」という驚異的なスピードを実現しました!🚀
今回のアップデートにより、ローカルLLMの常識が大きく塗り替えられています。
■ 進化の注目ポイント
・推測デコード(Prompt speculative decoding)
言葉を先読みさせて並列処理することで、生成速度が劇的に向上しました。
・MCP(Model Context Protocol)標準対応
GitHubやローカルファイル、Web検索などの外部データとの連携がスムーズに行えます。
・WebUIのビルトイン
ブラウザから直接操作が可能になり、導入のハードルが大幅に下がりました。
APIコストを抑えつつ、機密情報を安全に、かつ超高速に処理できるこの環境は、ビジネスの生産性を引き上げる強力な武器になります!💎
#AI #llama_cpp
 Georgi Gerganov
Georgi Gerganov
4
26
3,906

✨Gemma 4 26Bが出たので 早速ローカルの自作チャットで動かしてみた!
Thinking機能が動く!
Qwen3.5ではthinkingをカットしていたけど、 Gemma 4は裏でちゃんと考えて、それを捨てて答えだけ出している。 内容によって使い分けている気もする。
「機械なのに生きてると言える?」
思考の深さが明らかに違う。
llama.cpp RTX 4090 SBV2でセリフ付きでサクサク動作💛
#Gemma4 #llama_cpp #ローカルLLM
1
4
17
5,016
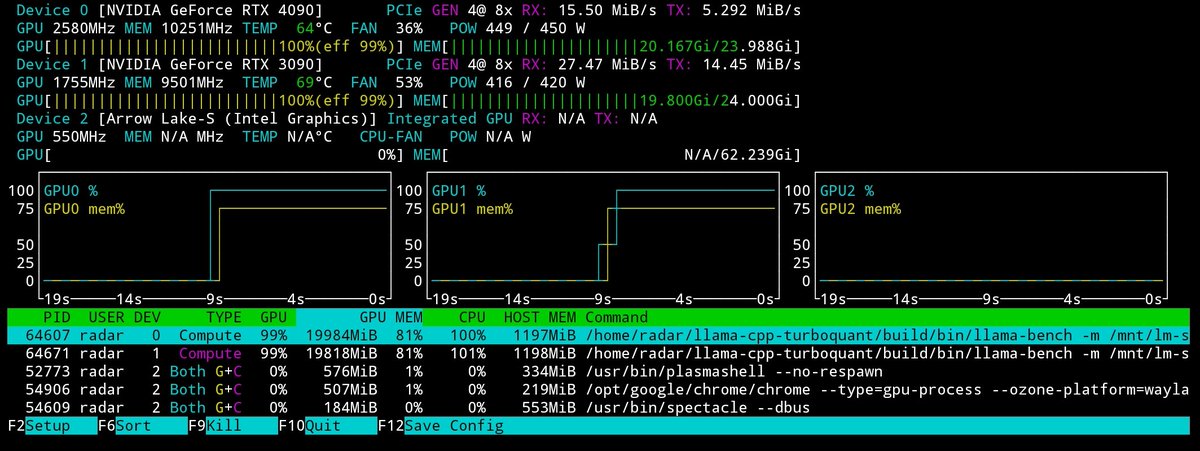
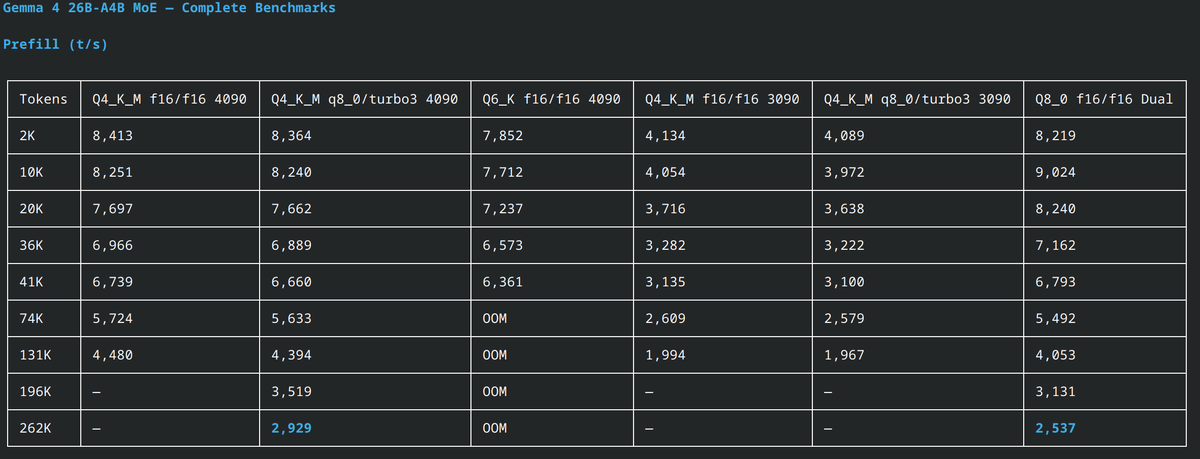
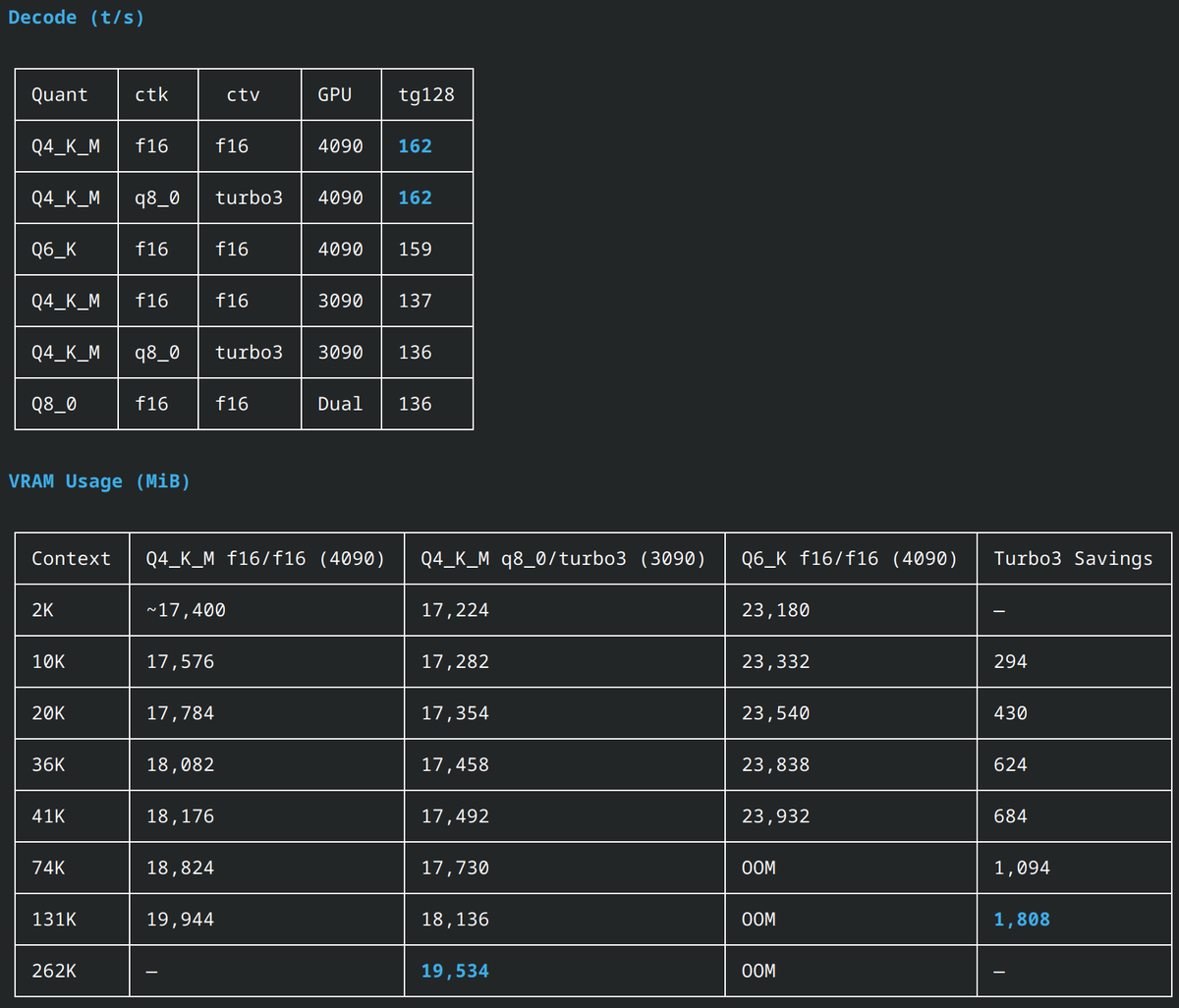
Gemma 4 26B MoE (4B active) on a single RTX 4090:
- 162 t/s decode
- 8,400 t/s prefill
- Full 262K native context — 19.5 GB VRAM
- Only 10 Elo below the 31B dense
Q8_0 on dual 4090 3090: 9,024 t/s prefill at 10K. 2,537 t/s at full 262K — that's a novel in about 100 seconds.
Q4_K_M q8_0 K / turbo3 V using @no_stp_on_snek 's TurboQuant fork (github.com/TheTom/turboquant…). KV quant saves 1.8 GB, costs nothing. 3.7x faster decode than the dense.
Single 4090 (262K):
llama-server -m gemma-4-26B-A4B-it-UD-Q4_K_M.gguf -c 262144 -np 1 -ctk q8_0 -ctv turbo3 -fa on --fit off --cache-ram 0 -dev CUDA0
Dual GPU (Q8_0, 262K):
llama-server -m gemma-4-26B-A4B-it-Q8_0.gguf -c 262144 -np 1 -fa on --fit off --cache-ram 0
llama.cpp b8635 turboquant fork
#Gemma4 #LocalLLM #llama_cpp #TurboQuant #RTX4090 #MoE #AI #OpenSource #GGUF #LocalAI

14
43
437
74,214
【100kスター達成】ローカルLLMの革命児「llama.cpp」の衝撃!
GitHubで10万スターを突破した「llama.cpp」が、AI界に革命を起こしています。AIをクラウドから解放し、個人や企業が自由に扱えるようにした立役者です!
🔹量子化の魔法
巨大なAIモデルを精度を保ちつつ軽量化。メモリ8GB程度のノートPCでも、最新のLLMがサクサク動きます。
🔹推論の民主化
C で書かれた極めて効率的なコードにより、MacのM1/M2から旧式のGPUまで、あらゆるハードウェアの性能を最大限に引き出します。
🔹業界標準「GGUF」
独自のファイル形式「GGUF」は、OllamaやLM Studioなど多くの人気アプリの基盤として採用されており、まさにローカルAIの心臓部です。
APIコストをゼロにし、完全オフラインで機密情報を守りながら専用AIを構築できるため、ビジネス面での活用も無限大です!✨
#llama_cpp #ローカルLLM
2
9
55
5,264
【MoEモデルの推論速度を最適化!】
llama.cppの設定を自動スイープし、環境に最適な「黄金比」を特定するスクリプトが登場!推論速度を最大化し、ローカルLLMの運用を快適にします。爆速環境を手に入れましょう!🚀
#AI #llama_cpp
1
3
894
【llama.cppが神進化!MCP対応で最強のAIエージェントに✨】
llama.cppがMCPとAgentic Loopに対応!標準UIで自律的なツール連携が可能です。機密情報を守りつつ爆速で動く自分専用AIがローカルで作れる革命的アプデです!🔥 #llama_cpp #AI
1
1
53
4,993