
MongoDB has no UUID type, so people store UUIDs as 36-character strings: roughly double the storage, for worse indexes.
The right form is a BSON Binary subtype 4: 16 raw bytes, indexes on the raw value, identical reads across every driver. In mongosh you write it with UUID().
The cautionary history: legacy subtype 3 stored bytes in a driver-specific order, so the SAME UUID came back scrambled between Java and C#. Subtype 4 fixed the byte order.
Subtle trap: a plain string query won't match a UUID stored as binary. Plus ObjectId vs UUID for _id, and why a random v4 hurts insert locality where v7 fixes it.
Full guide:
techearl.com/store-uuid-mong…
#MongoDB #Database #SchemaDesign
1
13
Carry SQL habits into MongoDB and you get a pile of tiny collections and a $lookup on every query, the exact slow path the document model was built to avoid.
Every schema decision is one fork: embed the related data for a fast atomic read, or reference it by _id and join with $lookup.
Embed when it's bounded, one-to-few, and read together. Reference when cardinality is high or unbounded, the data is shared, or it changes on its own.
The hard ceiling: the 16 MB BSON document limit. An unbounded embedded array eventually blows past it and forces a reference, like it or not.
Full guide:
techearl.com/mongodb-embed-v…
#MongoDB #Database #SchemaDesign #NoSQL
8

Jan 19
Syntara Log #042 | Seed Schema
Structure matters even at birth.
This step defined a universal memory seed schema.
Core values, identity, worldview, motivations, initial knowledge, and metadata.
Every entity follows the same structure.
No custom shortcuts.
No schema drift.
Consistency at initialization enables fairness later.
#Syntara #Neuraj #NeurajNotes #DigitalFreeWill #NeurajLabs #SchemaDesign #AIArchitecture
Jan 18

Syntara Log #041 | Memory Seed Integration
Entities should not start empty.
This step introduced memory seed integration into LP1.
A controlled way to load identity, values, and initial knowledge before the first thought loop runs.
Every entity now starts with a defined internal baseline.
No hidden defaults.
Initialization is explicit.
#Syntara #Neuraj #NeurajNotes #DigitalFreeWill #NeurajLabs #SystemInitialization #AIDesign
2
3
51
Jan 19
Syntara Log #042 | Seed Schema
Structure matters even at birth.
This step defined a universal memory seed schema.
Core values, identity, worldview, motivations, initial knowledge, and metadata.
Every entity follows the same structure.
No custom shortcuts.
No schema drift.
Consistency at initialization enables fairness later.
#Syntara #Neuraj #NeurajNotes #DigitalFreeWill #NeurajLabs #SchemaDesign #AIArchitecture
1
2
3
24

🚨 The $2.1M Schema Problem That's Breaking Enterprise Data
If your data teams are constantly firefighting schema drift issues, you're not alone and it's costing you more than you think.
Schema-based tools are creating massive hidden costs:
💸 $890K in revenue recognition failures
🔴 $480K in compliance gaps
⚠️ $470K in supply chain disruptions
📉 $350K in failed AI/analytics initiatives
The real damage? Schema changes ripple through your entire stack—breaking integrations, stalling projects, and forcing teams into manual workarounds that multiply technical debt.
When your Salesforce opportunity stages change but don't sync to NetSuite... when engineering updates part specs but procurement references old schemas... when customer health scores break your churn models—that's schema drift at work.
✅ The Schemaless Solution:
Modern schemaless databases are reversing this trend by:
→ Eliminating complex schema migrations
→ Enabling real-time adaptability without downtime
→ Supporting diverse data types in JSON-style documents
→ Reducing IT overhead and infrastructure costs
→ Accelerating innovation with flexible data models
→ Powering real-time analytics and AI use cases
The bottom line: Schema-free architectures let you focus on delivering value instead of managing data structure politics.
Is schema drift costing your organization millions? Let's discuss how schemaless approaches could transform your data efficiency.
leorix.ai/
#DataArchitecture #EnterpriseData #SchemaDesign #DataEngineering #TechLeadership #leorix

2
37

3 Nov 2025
SQL can query data.
🤖 AI understands meaning.
When they work together, your database starts thinking instead of just searching.
🧠 The future isn’t about keywords it’s about understanding.
shorturl.at/46h0s
#KitesSoftware #schemadesign #AIEngineering #DatabaseSearch
2
78

26 Jun 2025
🧵 @karpathy’s recent @ycombinator talk had a key takeaway about “partial autonomy” that perfectly captures where AI is heading—humans and AI working together, each contributing unique strengths. At @schemadesign, we’ve developed Seven Lenses to give designers tangible guidance for building these collaborative interfaces.
Link to FigJam toolkit below 👇
#IntelligentInterfaces #AIUX
ALT Partial Autonomy UX
3
2
18
103,439
26 Nov 2024
Great project. This is similar to an experiment my team @schemadesign worked on called the Knowledge Exploder: knowledge-exploder.com
3
117

Free Tutorial: SQL Server Query Performance Guidelines
For more free tutorials, check out MSSQLTips.
#sqlserver #tutorial #performance #schemadesign #indexing #querywriting
mssqltips.com/sqlservertutor…
8
371

14 May 2024
WEBPicks: A visualization by @schemadesign and @BCGhenderson in the form of a branching tree presents the think tank’s interconnected research. ow.ly/Bv6e50REaco

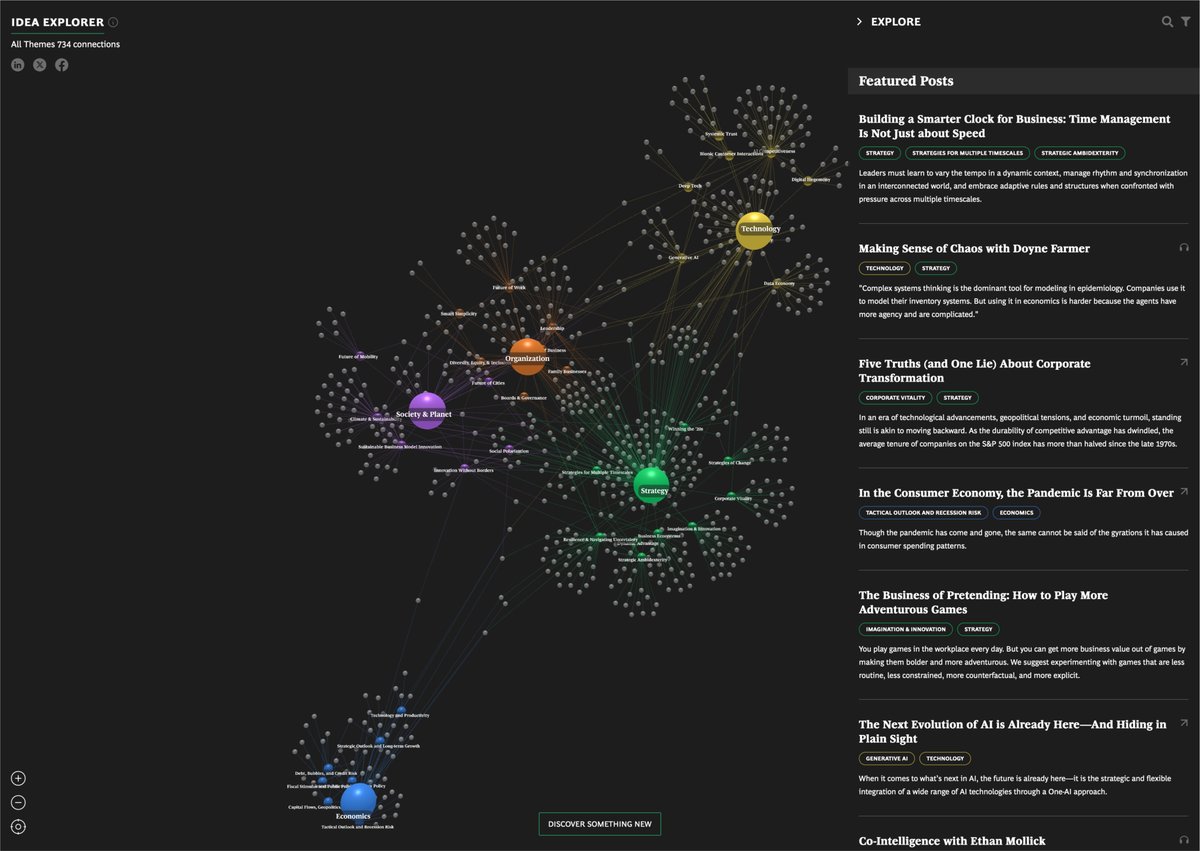


2
3
619
14 May 2024
WEBPicks: A visualization by @schemadesign and @BCGhenderson in the form of a branching tree presents the think tank’s interconnected research. ow.ly/Bv6e50REaco


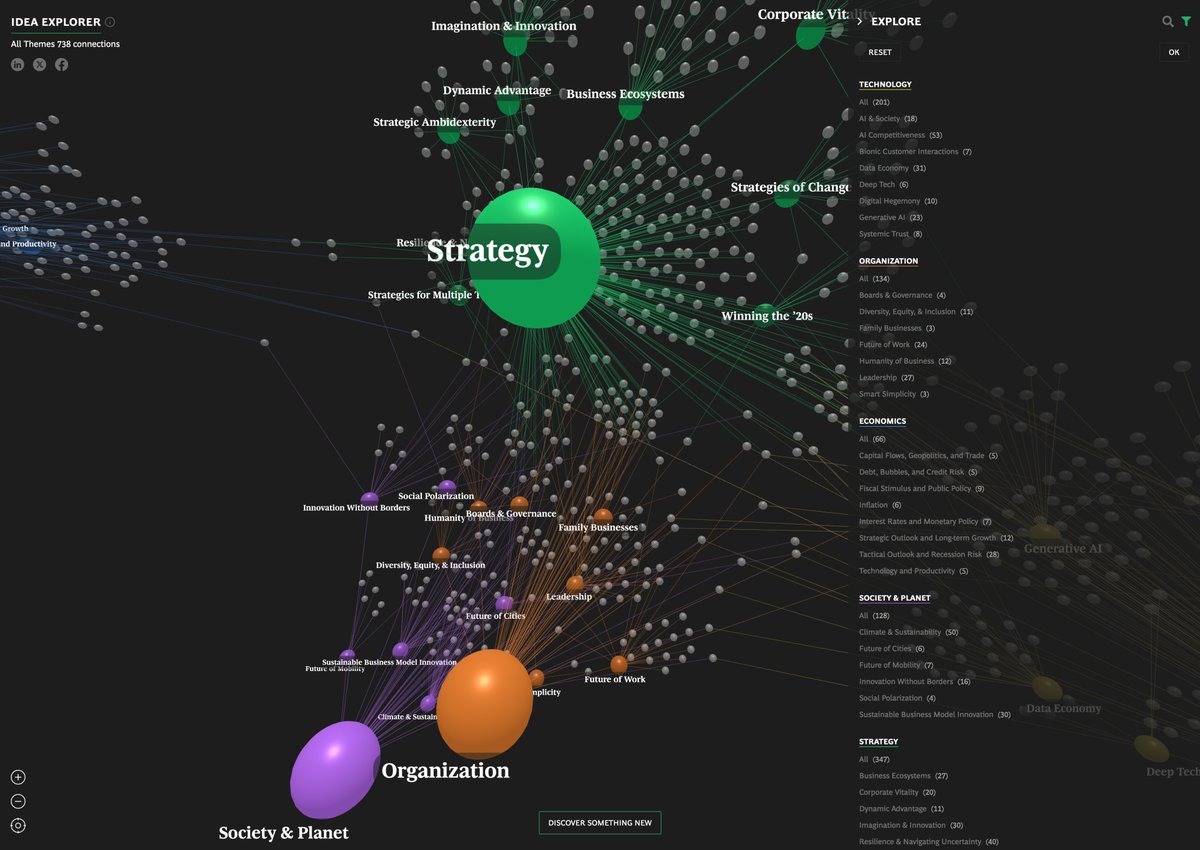
3
11
2,395

15 Feb 2024
🔍💻 Designing a robust database schema in MySQL is crucial for efficient data management and retrieval. Let's dive into some key tips and considerations! #DatabaseDesign #MySQL #SchemaDesign
2
2
87

11 Nov 2023
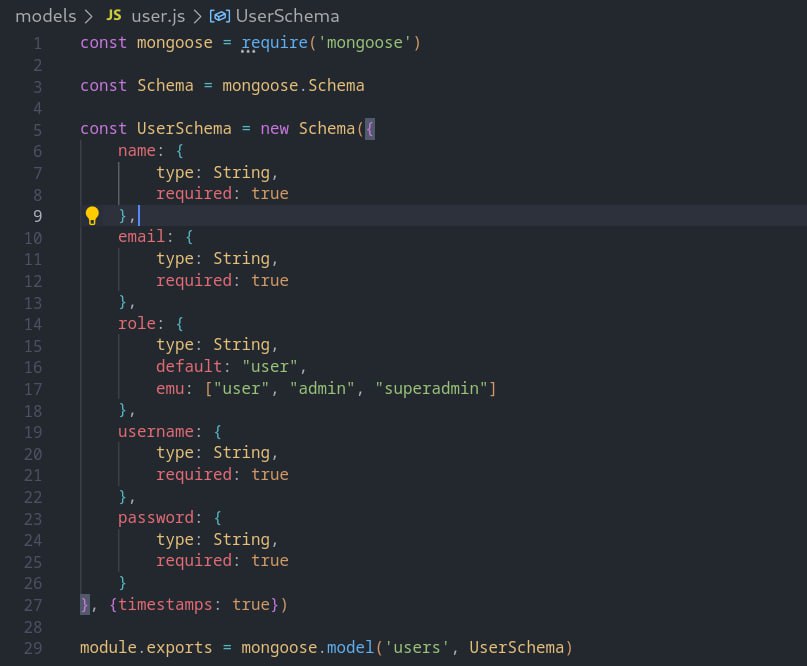
User Model Schema 🤖
🤖 Designed a user model with essential attributes like name, email, role, username, and password using Mongoose Schema. #Mongoose #UserModel #SchemaDesign
1
2
3
71
5 Sep 2023
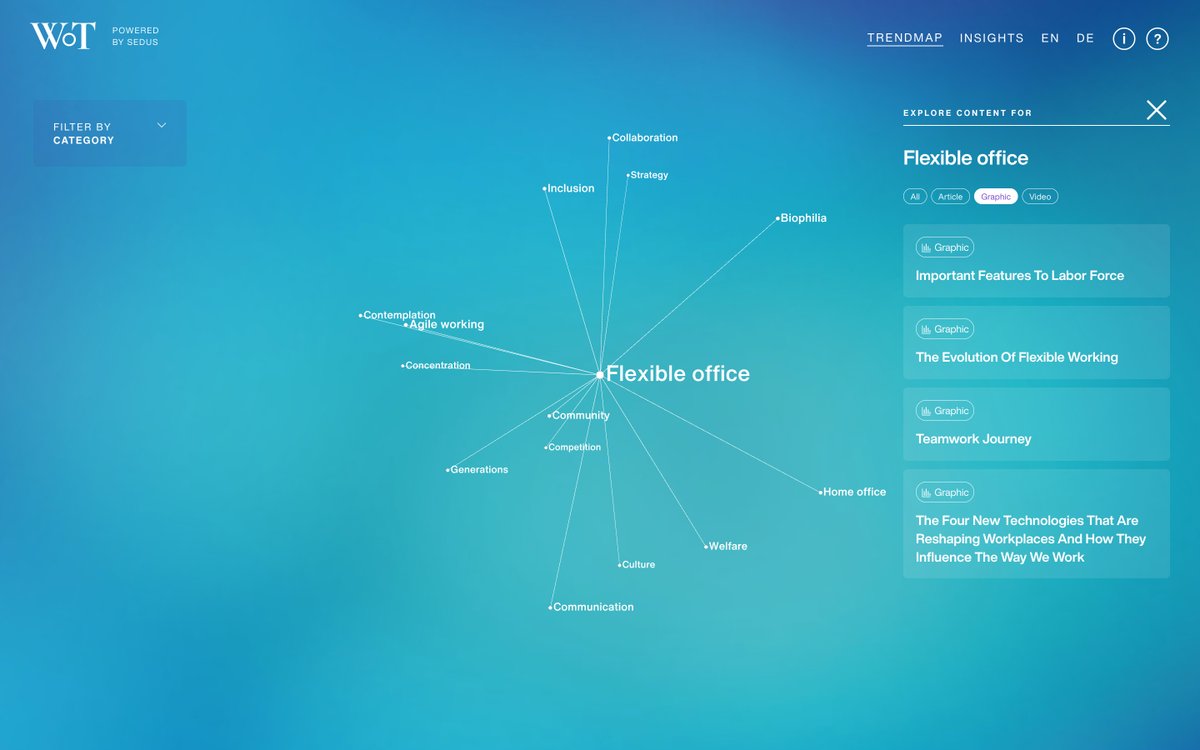
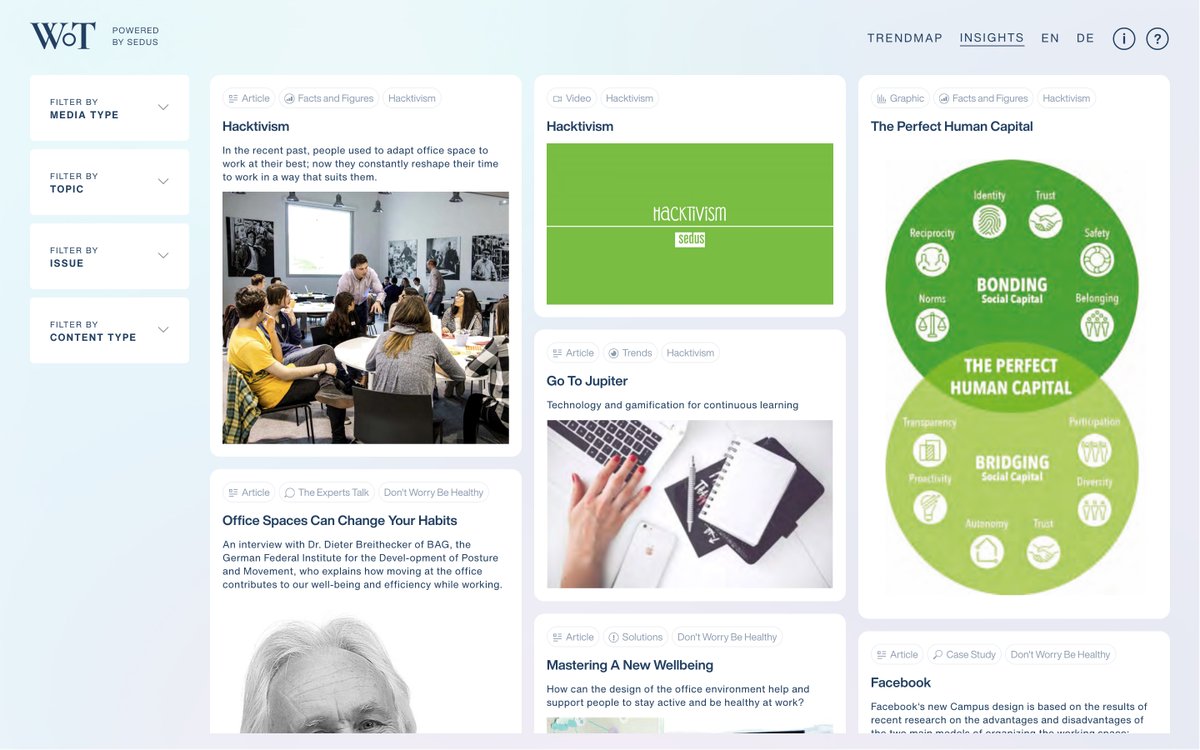
WEBPicks: @schemadesign and @SedusL’s site leverages data from the office solutions manufacturer’s INSIGHTS publication to explore the future of work environments. ow.ly/rmSR50PHQE1


1
5
623

25 Aug 2023
Data Modeling and Schema Design in BigQuery. #BigQueryDataModeling #SchemaDesign #BigQueryTechniques #DataArchitecture #AdvancedBigQuery palamsolutions.com/?p=15613
1
2
43

17 Feb 2023
Model, schema, metadata: these three terms articulate very different concepts in the data modeling profession, and as such, we should take deliberate care when using them
#datamodeling #nosql #schemadesign #metadaascode
13 Feb 2023

Just published another article about the difference between #datamodels, #database #schemas and #metadata. Been doing a lot of work with @hackolade to clarify the difference and making sure that people understand how they can get value from #nosql #datamodeling. Super fun!
2
2
216

7 Feb 2023
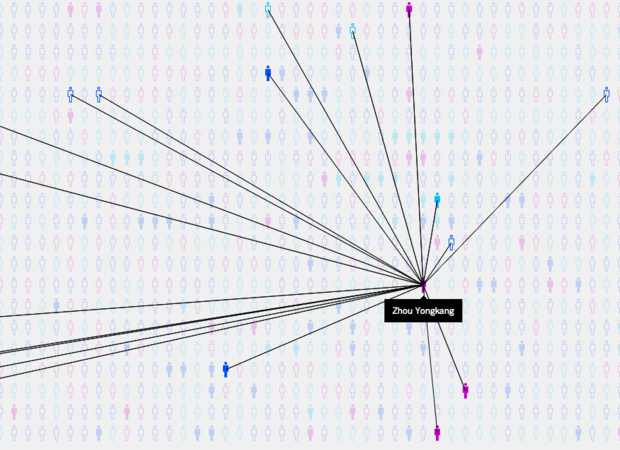
To those behind the infographics and interactive journalism built in collaborations no one else was doing #sohu @dwertime @schemadesign @jeffreylinn @evaconstantaras @Jieqian_Zhang #JessicaBatke @eighthday chinafile.com/multimedia/inf…
1
2
252



10 Sep 2022
Today's the last day to save $200 on passes to #GraphQLSummit! Register before midnight tonight and choose your #GraphQL workshops on #schemadesign #kotlin #frontend and #backend GraphQL, plus much more: bit.ly/3RujmvD

1
2