
Jun 12
Statistiques Schema.org : suivez l’adoption des données structurées
On a enfin un baromètre qui ne parle pas météo : les stats Schema (par domaines, MAJ mensuelle) orientent vos priorités de données structurées et vos SERP. #SEO #SchemaOrg voir nos actus 👆

1
30

KI-Suche ignoriert deine Website? Vielleicht spricht sie einfach deine Sprache nicht. Schema.org-Markup ändert das. #LLMSEO #SchemaOrg
ventas-webdesign.de/llm-seo
2

Jun 9
💡Can library catalogs become more discoverable through #SchemaOrg and #LinkedData?
KO research investigates the role of #IFLALRM in semantic enrichment 👉
doi.org/10.31083/KO47266
#Metadata #SemanticWeb #Libraries

1
4
18

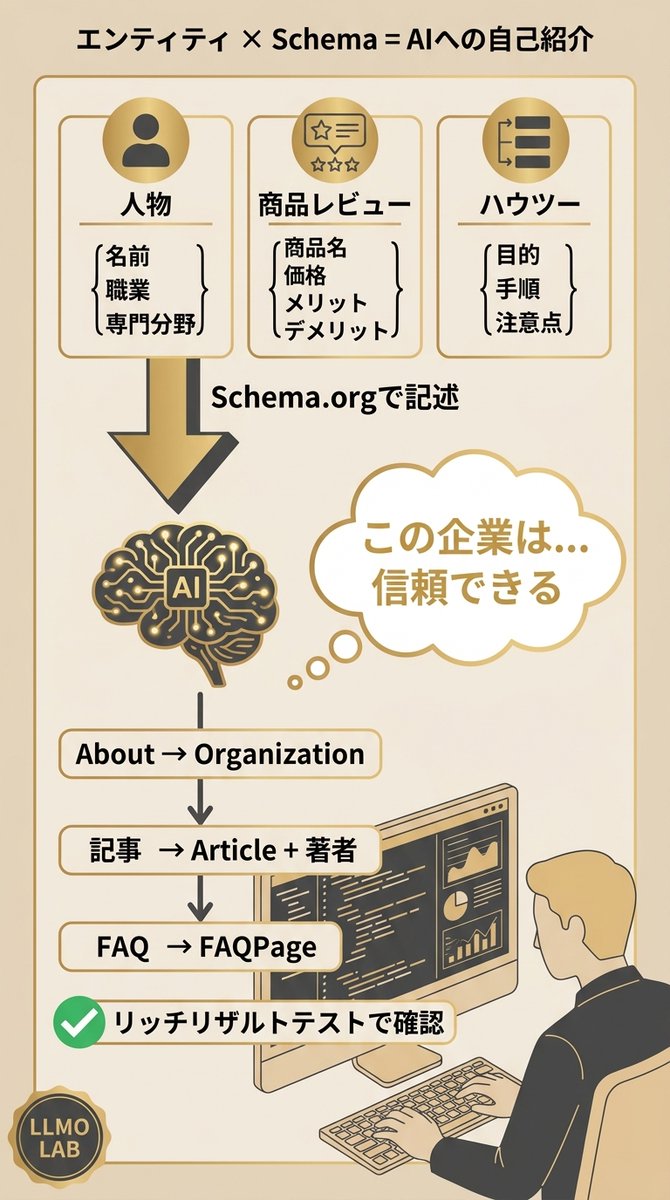
「構造化データってSEOのリッチスニペット用でしょ?」
マーケ担当者の方とLLMO対策の話をすると、こう思ってる方がかなり多いです。確かに従来は検索結果のリッチ表示が主な目的でした。
でも今、構造化データの役割が根本的に変わりつつあります。
AIが回答を生成するとき、
・この企業は信頼できるか
・この情報は正確か
を判断する材料として、Schemaorgで記述された属性情報を参照してるんです。
エンティティには必ず属性(プロパティ)があります。
人物なら
・名前
・職業
・専門分野
商品レビューなら
・商品名
・価格
・メリット
・デメリット
・結論
ハウツーなら
・目的
・手順
・注意点
この属性をSchemaで明確に記述すると、AIが「何についての、どんな立場からの、どんな情報か」を正確に理解できるようになります。
逆に属性が曖昧なままだと、AIは自分で推測するしかない。そこで誤解が生まれる。
ぼくが提案してるのは、まず自社の最も重要なコンテンツ5〜10ページから構造化データを実装することです。
会社概要ページにOrganization、記事にArticleと著者情報、FAQにFAQPage。
Google公式のリッチリザルトテストで正しく実装されているか確認できるので、技術的なハードルはそこまで高くない。
構造化データは「検索エンジンへの表示最適化」から「AIへの自己紹介」の時代に変わってきてます。
自社が何者であるかをAIに正しく伝えるための設計を、今から始めておくことをおすすめします。
LLMO対策の実践知を日々発信してます。フォローしておいてください!
4
440

Search engines don’t just read websites anymore — they understand meaning.
Learn how Structured Data (Schema.org) improves SEO, rich results, and Google visibility.
Read more 👇 amtechco-llc.com/en/blog/wha…
#SEO #SchemaOrg #StructuredData #WebDev
3
2
3
40

いくつか論点があるのですが、
・llms.txtはrobots.txtやSchemaorgのようにプラットフォーム側が定めた形式ではない
・クローラーがllms.txtを特別に読みにきていない
・読みにきても効果が実証できていない
という点が大きく、不要以前に有効という判断には慎重にならざると得ないという印象ですね。
1
9
1,091

Yoast SEO centralise les données structurées avec un schemamap
Yoast SEO lance un endpoint qui agrège votre schéma et désambiguïse vos entités. Résultat: graphe clair, crawl/IA plus rapides. #SEO #SchemaOrg #IA voir nos actus 👆
3
64
Mar 5
📰The latest work from @ATUTehran by first author Dr. Ehsan Rouhi and his team is now featured in KO!
Link👉: imrpress.com/journal/KO/53/1…
💡What if #SchemaOrg #RDA boost #Metadata interoperability? #SemanticWeb #LinkedData #Libraries #DigitalHumanities #OpenAccess
#Iran

8
150

Feb 12
🚀 WebMCP is the new #SchemaOrg moment.
@cyberandy explains how the web is shifting from passive structured data to actionable AI interfaces — letting agents 𝘥𝘰, not just 𝘳𝘦𝘢𝘥.
eu1.hubs.ly/H0rH3B60
#AI #SEO #WebMCP #StructuredData #Tech
1
5
334

Jan 30
検索エンジン上位表示は、良いコンテンツを作成した上で以下をやるといいですよ。
schemaorg構造化データの使い方と実装方法|SEO・LLMO最適化に効く完全ガイド
atoz-design.jp/column/ai-sea…
1
7
268

16 Aug 2025
AIに『このサイト、分かりやすい!』と思ってもらうことが、これからのウェブ戦略の鍵。
構造化データは、そのための最初の一歩です。
自分のサイトの情報を、もっとAIにアピールしてみませんか?
#構造化データ #schemaorg #SEO対策 (4/4)
2
15

29 May 2025
🚨 テキストのみレビューの構造化データ、どう書く? 🚨
👀 確認すべきポイント
・ ReviewRating プロパティが必須であること
・ テキストだけのレビューは構造化に不向き
・ 数値評価へのマッピング可否
🔍 追加でチェック
・ パーセンテージ評価なら1–5に換算可能か
・ 使いたい場合は評価を併記するか検討
🛠 対策ステップ
1. 数値評価がないテキストレビューは構造化データ非対応と判断
2. パーセンテージ評価があれば5段階で変換し ReviewRating を実装
3. 純粋コメントのみの場合はページ内表示に留める
4. 今後数値評価を得る仕組みを検討(アンケート等)
5. 実装後は Rich Results テストで確認
#構造化データ #Review #SchemaOrg #TechSEO #レビュー
3
34
24 May 2025
(追加)生成AIによる検索結果に取り上げられやすいホームページの特徴
・独自ドメインのWPサイトがあること
・行政書士の登録番号が記述されていること
・行政書士の写真掲載があること
・グーグルビジネスプロフィールに登録されていること
・活動しているSNSからHPへリンクされていること
・Schemaorgが利用されていること
23 May 2025

生成AIによる検索結果に取り上げられやすいホームページの特徴
・法人であること
・検索順位が上位であること
・実績が明確に示されていること
・特定の業務に特化していること
・商圏(地域性)が明確であること
・代表者の情報
・業務内容、料金体系
・無料相談
老舗に有利な条件ですが、生成AIによる検索結果はパーソナライズされるため、「特定の人」に対して「特定の業務」でNo.1になれれば、十分に取り上げられる可能性があります。
1
1
21
1,469

NLWeb気になる。RDFやSchemaorgを作ったR.V. Guha氏が提唱しているプロジェクトでもあるということでなおさら気になる。
news.microsoft.com/source/fe…
1
3
402

22 Apr 2025
#SEO 🎴 Les données structurées n’agissent pas sur le ranking… mais sur la visibilité
✅ Résultats enrichis = plus de clics
🧠 Aident les IA à comprendre votre contenu
•
#SchemaOrg #SERP
✍️ @abondance_com
buff.ly/O4eU0T0

3
66

17 Feb 2025
#OpenData #datiBeneComune #OpenGov
5.029.368 Imprese Attive in Italia
Variazione tendenziale (YoY) -0,8%
Dati al 31 gennaio 2025
🔗opendata.marche.camcom.it
#DatiPubblici #DCATAP #Eurostat @DatiGovIT @EU_opendata @InteroperableEU @Joinup_eu #DataViz #JSONstat #SchemaOrg
3
43

12 Feb 2025
AI SEO対策のヒント by Deep Research ↓
AI SEOの観点から、ChatGPTやその他のAIツールからの流入を増やすための最適な対策を調査します。具体的には、AIに引用されやすくなるためのコンテンツ構成、メタデータの最適化、構造化データの活用、権威性の確保、YouTubeの最適化、さらに競合分析と成功事例も調査します。結果がまとまり次第、お知らせします。
1. コンテンツの最適化
Web記事や動画の内容は、AIが理解しやすく、直接引用しやすい構成に整える必要があります。具体的には、ユーザーの質問に直接答える形で情報を整理し、重要なキーワードを見出しや本文中に盛り込むことが効果的です。例えばQ&A形式やFAQ形式でコンテンツを構成すると、AIが質問と回答をペアで認識しやすくなります。また、ユーザーの検索クエリ(質問文)に合った表現をタイトルや見出しに含めると、AIが該当箇所を見つけやすくなります。
FAQ・Q&Aスタイルの活用: 記事内に想定質問と回答を設けることで、AIは回答箇所を特定しやすくなります。実際、記事にFAQの構造化データを追加すると、質問ベースのクエリに対してコンテンツが取得されやすくなるとされています。
明確な見出しと段落構成: 見出しにはテーマを端的に表すキーワードを含め、段落ごとに一つの論点をまとめます。AIは見出し構造を手がかりに情報を整理するため、論理的な構成が引用率向上につながります。
最新かつ独自性のある情報: コンテンツは定期的に更新し、最新の情報を反映させます。AIアシスタントは最新アップデートを重視する傾向があるため、情報が新しいほど引用されやすくなります。さらに、他にはない統計データや調査結果など独自の有益データを含めることで、AIから「有用な情報源」と認識される可能性が高まります。
簡潔な要約の提供: 記事の冒頭や動画の説明欄に内容の要約や結論を掲載しましょう。AIがコンテンツをスキャンする際に、この要約部分を引用して回答に利用するケースがあるためです。
2. メタデータと構造化データの活用
メタデータ(メタタグ類)や構造化データを適切に設定することで、AIがコンテンツ内容を正確に把握しやすくなります。検索エンジンやAIは構造化データを解析してページの文脈を理解するため、可能な限りhttp://Schemaorgのマークアップを活用しましょう。
タイトルタグ・メタディスクリプションの最適化: ページのタイトルタグは簡潔かつ内容を端的に表すものにし、メタディスクリプションには記事の要旨やキーワードを含めます。これらは検索結果で表示されるだけでなく、AIがページ内容を要約する際の手がかりにもなります。
Schemaorgによる構造化データマークアップ: 記事にはArticleやFAQ、HowTo、製品ページにはProductやReviewなど、内容に即したSchemaマークアップを埋め込みます。構造化データによってAIはページの文脈や属性を理解しやすくなり 、質問形式のクエリに対してはFAQ Schemaが回答抽出に有効です 。特にFAQやHowToスキーマを実装すると、生成AIが回答を生成する際に情報を抜き出しやすくなることが報告されています。
著者情報や公開日などのメタ情報: 記事の構造化データやHTML上に、著者名・経歴、公開日・更新日を明示しましょう。AIが情報源の新鮮さや信頼性を判断する材料になります。信頼できる著者による最新コンテンツであることを示すことが重要です。
構造化データ実装時の注意: 構造化データは可能な限りHTMLに直接記述し、クローラーが確実に取得できるようにします。AIクローラーはJavaScriptで動的に生成されたデータを読み取れない場合があり、実際に「AIクローラーはJavaScript挿入された構造化データを見落とす」ことが指摘されています。したがってJSON-LDスクリプトを埋め込む際も、サーバーサイドレンダリングで出力するか、ノーインデックスのない静的HTML内に記載するようにします。また、構造化データがAI検索順位に直接影響する確証は現時点でなく、あくまで補助的な役割と見る専門家もいます。しかし、少なくともAIのコンテキスト理解を助ける点で構造化データは有益と考えられます。
3. 権威性の確保とE-E-A-Tの向上
コンテンツが権威ある情報源としてAIに認識されるには、Googleが提唱するE-E-A-T(経験・専門性・権威性・信頼性)の充足が重要です。AIも高品質な情報を提供するために、信頼性の高いソースを選別する傾向があります。権威性を高めるための具体策を講じましょう。
専門性・経験の明示: コンテンツの執筆者や発信元の専門性を示します。著者プロフィールに資格や経歴、実績を記載したり、自身の経験に基づく洞察を記事に織り交ぜたりします。特に医療・金融などYMYL分野の内容では、専門家の監修や権威ある情報源からの引用が不可欠だとされています。信頼できるソースを引用し、自サイトの内容裏付けを行うことで、AIからも「裏付けのある情報」と判断されやすくなります。
信頼性のアピール: サイトの「お問い合わせ」や「運営者情報」を充実させ、コンテンツの根拠となるデータや参考文献を明示します。AIはサイト全体の信頼性も加味する可能性があるため、プライバシーポリシーの整備やセキュアな通信(HTTPS)の実装など基本的な信頼醸成も怠りなく行います。
被リンク獲得: 他の権威あるサイトから言及・被リンクされていることは、伝統的なSEOのみならずAIからの評価にもつながります。高品質なコンテンツを発信し続け、業界のニュースサイトや研究機関、政府機関等に引用・参照してもらえるような関係構築を目指しましょう。例えば独自調査のリリースを配布したり、専門家との共著記事を公開したりすると、自然な被リンク獲得につながります。
E-E-A-T全体の底上げ: Experience(経験)も重視されている点に留意し、自社の体験談やユーザー事例を紹介するなど、生の経験にもとづくコンテンツを増やします。権威性(Authoritativeness)だけでなく、実体験に基づく知見やレビューが含まれることで、AIからの信頼度が増します。また、継続的にコンテンツを更新し、長期にわたり信頼を積み重ねることで、**「広く認知された情報源」**として優先的に扱われるようになります。
4. YouTubeの最適化
YouTube動画コンテンツをAIに認識・引用させるには、動画内容をテキスト情報としても提供する工夫が重要です。動画そのものはAIにとってブラックボックスですが、周辺情報を最適化することで内容を理解させることが可能です。
タイトル・説明文・タグの最適化: 動画タイトルにはユーザーが検索しそうなキーワードを含め、内容を簡潔に表現します。説明文には動画内の要点や章立てを記載し、関連キーワードも盛り込みましょう。タグも適切に設定し、動画のテーマに関連する語句を網羅します。これにより、AIや検索エンジンが動画のトピックを正しく把握できます。
自動字幕・トランスクリプトの活用: YouTubeの自動字幕機能や自前の文字起こしを活用し、動画の全編を書き起こしたテキストを用意します。字幕やトランスクリプトによって、動画の内容がテキストデータとして検索エンジンに認識されるため、動画のインデックス化や関連検索での露出が向上します。実際、字幕・文字起こしにより動画中のキーワードが明確化され、SEO効果が高まることが確認されています。AIもこれらテキストを手掛かりに動画内容を理解できるため、回答生成時に動画を引用候補として検出しやすくなります。
チャプター(目次)設定: 動画を章ごとに区切り、チャプター機能でセクション名を付けてください。視聴者の利便性向上だけでなく、検索エンジンが動画の構成を理解しやすくなります。特定の質問に対応するチャプター名(例:「〇〇の方法STEP1: …」)を付けておけば、AIがそのチャプター名をトリガーとして適切な部分を紹介してくれる可能性があります。
高精度な音声認識: 自動字幕を利用する際は誤認識がないかチェックし、必要に応じて編集します。誤った字幕が残っているとAIが内容を誤解する恐れがあります。専門用語や固有名詞は正しく字幕に反映させましょう。場合によっては日本語だけでなく英語字幕も追加し、多言語で内容を理解できるようにすることで海外のAIアシスタントにも対応できます。
動画とテキストの連携: 動画と同じ内容のブログ記事やPDF資料を用意し、動画の説明欄や終了画面からリンクします。こうすることで、AIが動画内容をテキスト経由でも取得でき、引用元として参照しやすくなります。例えば、動画の概要を記事化しそのURLを共有しておけば、ChatGPTプラグインやBingなどがテキスト経由で内容を把握できます。
5. 競合分析と成功事例
既にAIに引用されているサイトや動画を分析することは、有効な戦略を知る手がかりになります。競合他社や業界の権威サイトがどのようにAI最適化を行っているか調査し、自社コンテンツ改善に活かしましょう。
AIが引用しているサイトの傾向: 一般に、Wikipediaや大手ニュースサイト、政府機関や大学など信頼性の高いドメインがAIの回答で引用される傾向があります。これはそれらサイトの権威性・網羅性が高いためで、コンテンツ制作においても信頼性と網羅性を追求することが重要だと示唆しています。逆に言えば、小規模サイトであってもニッチな質問に対し的確な回答コンテンツを提供していれば、AIはそのページを拾い上げる可能性があります。実際にChatGPTなどの生成AI検索では、従来の検索エンジンで上位表示されていなかったページであっても引用される例が報告されています。つまり、競合が少ない専門特化テーマで質の高い記事を用意すれば、検索順位に関わらずAI回答に採用されうるということです。
成功事例の研究: 例えば、ある業界キーワードでBing ChatやGoogle Bardが頻繁に引用しているブログがあれば、そのサイトを詳しく分析します。コンテンツの構成(見出しの付け方、段落の長さ、媒体の種類)、使用しているSchemaの種類、ページの表示速度やモバイル対応、被リンクプロファイルなどをチェックしましょう。成功しているサイトはFAQページを充実させていたり、専門家による解説記事を多数用意していたりといったAI受けする工夫を凝らしているはずです。それらを自社にも取り入れてみます。
競合動画の分析: YouTube上で似たテーマの動画がAIに取り上げられている場合、動画の長さやコメント数、視聴維持率などエンゲージメント指標も分析します。高いエンゲージメントは間接的に動画の評価を高め、Googleの検索結果やAIの推薦にもつながる可能性があります。また、動画のタイトルやサムネイルのデザイン、説明欄の記載内容など、細かな最適化ポイントも成功例から学びましょう。
6. その他のAI向け施策
上記以外にも、AIにとってクロール・理解しやすいサイト構造や、AIへのデータ提供方法を工夫することで、AI経由のトラフィックを増やせる可能性があります。
クロール最適化: 自社サイトがGoogleやBing等の検索エンジンに確実にクロール・インデックスされていることを確認します。特にBingのインデックス登録は重要です。なぜなら、Bingの検索インデックスを元にBing ChatやChatGPT(ブラウズ機能経由)が情報を取得するケースが多いためです。サイトマップを各検索エンジンに送信し、インデックス未収録のページがないか定期的にチェックしましょう。また、サイト内のリンク構造をフラットかつ論理的にしてクローラーが辿りやすくすることも基本ですが重要です。JavaScriptによって動的生成されるコンテンツは、必要に応じてプリレンダリングやサーバーサイドレンダリングを導入し、クローラーがHTMLとして直接取得できるようにします。こうした技術的SEOの最適化により、AIにも情報が行き渡りやすくなります。
AIクローラーへの対応: OpenAIのGPTBotやGoogleのAI用クローラー(Google-Extendedなど)がサイトを巡回できるよう、robots.txtでブロックしない設定にします。特にOpenAIはChatGPTの精度向上のため独自クローラーを公開していますが、将来的にこのクローラーが収集したデータが回答生成に用いられる可能性があります。現状では明確なトラフィック源とは言えませんが、将来を見据えクローラーからのアクセスを受け入れておくと良いでしょう。
サイトパフォーマンスとUXの向上: サイトの表示速度やモバイル対応、アクセシビリティといった要素も間接的にAI SEOに影響します。検索エンジンの評価が低いサイトはAIにも引用されにくくなると予想されるため、コアウェブバイタル指標の改善やレスポンシブデザインの採用など、総合的な品質向上に取り組みます。特にモバイルでの閲覧性を高めることは、音声アシスタント経由でサイトにアクセスされた場合のユーザー体験にも寄与します。
APIやデータ提供の活用: 自社コンテンツをAIに直接利用してもらう仕組みとして、API公開やデータセット提供を検討します。例えば、自社で統計データベースを運営しているなら、そのデータをAPI経由で提供することで、開発者がChatGPTのプラグインや他のAIサービスに組み込む可能性があります。また、簡易な例ではRSSフィードを整備し、ニュース系AIに記事配信することも考えられます。近年では一部の企業が自社情報を公式プラグインとしてChatGPTに提供し、AIから直接最新データを取得できるようにするといった取り組みも登場しています。リソースが許すなら、自社でChatGPTプラグインの開発・公開を行い、ユーザーがAI経由で自社データを検索できるようにするのも先進的な施策です。
ナレッジグラフへの統合: 可能であれば、WikipediaやWikidataへの情報掲載も視野に入れます。AIはこれら公開知識ベースから学習を行ったり参照したりするため、会社や製品に関する情報がWikipediaに載っていれば、AIがその情報を引き合いに出す確率が上がります。ただし、Wikipedia掲載には知名度や中立性など条件がありますので、プレスリリース配信やメディア掲載を通じてまず知名度を上げることが先決です。
以上のように、従来のSEO対策に加えて**AI時代に即した最適化(AI SEO)**を実践していくことで、ChatGPTや類似のAIから引用・参照される機会を増やすことができます。ポイントは、AIが「信頼できる知識の源」と判断できるようなコンテンツ品質・構造・権威性を備えることです。コンテンツの構成とマークアップを整え、サイト全体の信頼性を高め、動画等マルチメディアにもテキストでの補足情報を十分用意することで、AI経由の新たなトラフィック獲得につなげていきましょう。
5
42
8,635

8 Feb 2025
Every epic space odyssey needs a conflicted villain—preferably one torn between galactic conquest and an existential crisis about their WiFi signal. 🗑️🤖
Trashformers #9 - Darth Disposal
Darth Disposal, once a noble Garbage Guardian now rebuilt with trash-based cybernetics, is a cold and calculating enforcer for the Junkyard Empress, driven by vengeance yet secretly longing for Rustaria to join him in imposing strict order on the chaotic Trashyverse.
👀trashformers.xyz/files/Trash…
#Trashformers $SBX #Chia $XCH #NFT #ComposableNFTs #3DAssets #AIBeing #NFTArt #SciFi #3D #NFTStory #NFTCommunity #DigitalArt #NFTArtist #Metaverse #NFTStorytelling #NarrativeNFTs #DigitalStorytelling #CryptoPuzzles #CryptoArtPuzzles #CryptoChallenge #Web3TreasureHunt #Audiobook #InteroperableNFTs #SchemaOrg #WebGL #Unity3D #WalletConnect
Discover the #Trashyverse on Trashformers.xyz
2
13
31
1,033
8 Jan 2025
#SEO 🎴 Les données structurées sont clés pour un SEO avancé
Découvrez comment elles peuvent transformer l'interprétation de votre site par Google.
🔍 Prêts à déchiffrer le code du succès SEO ?
•
#SchemaOrg #SiteWeb #contentmarketing
audreytips.com/donnees-struc…
3
41